One point usually underestimated or omitted when dealing with machine learning algorithms is how to write *good quality* code. The obvious way to face this issue is to apply automated testing, which aims at implementing (likely) less-buggy and higher quality code.
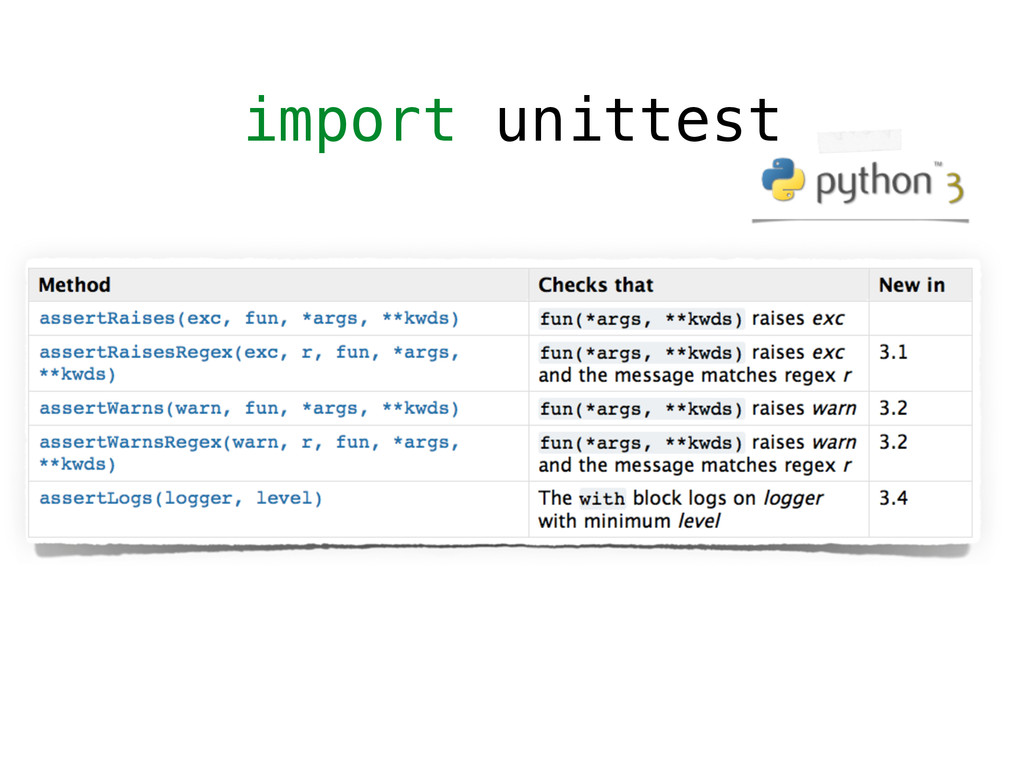
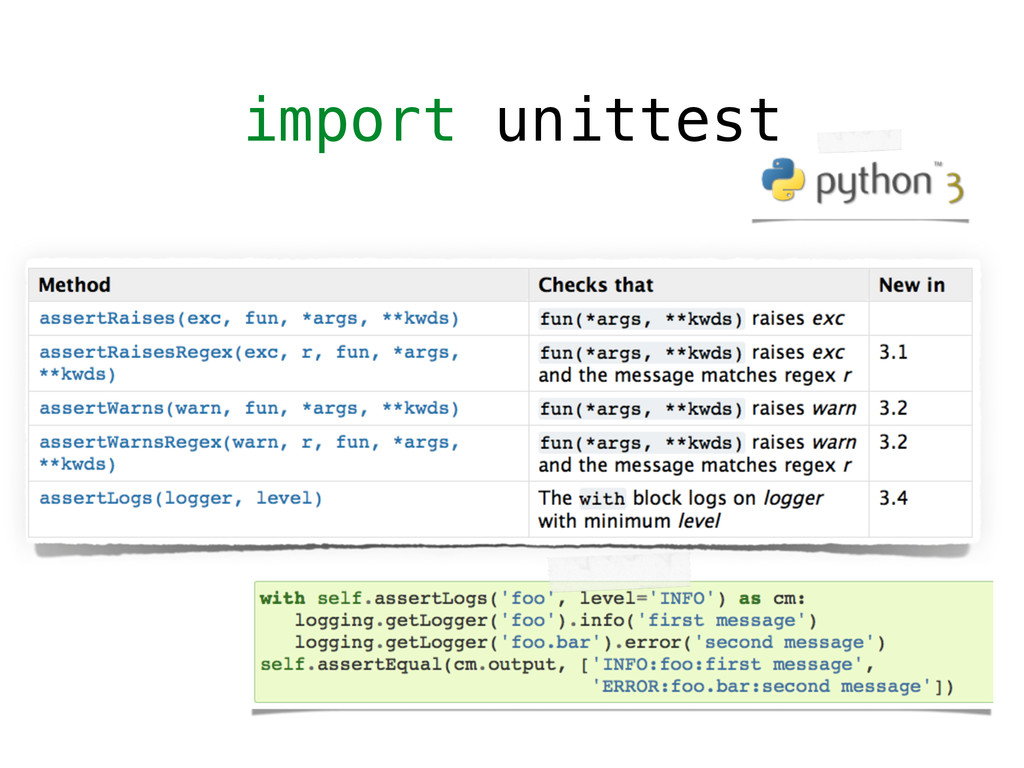
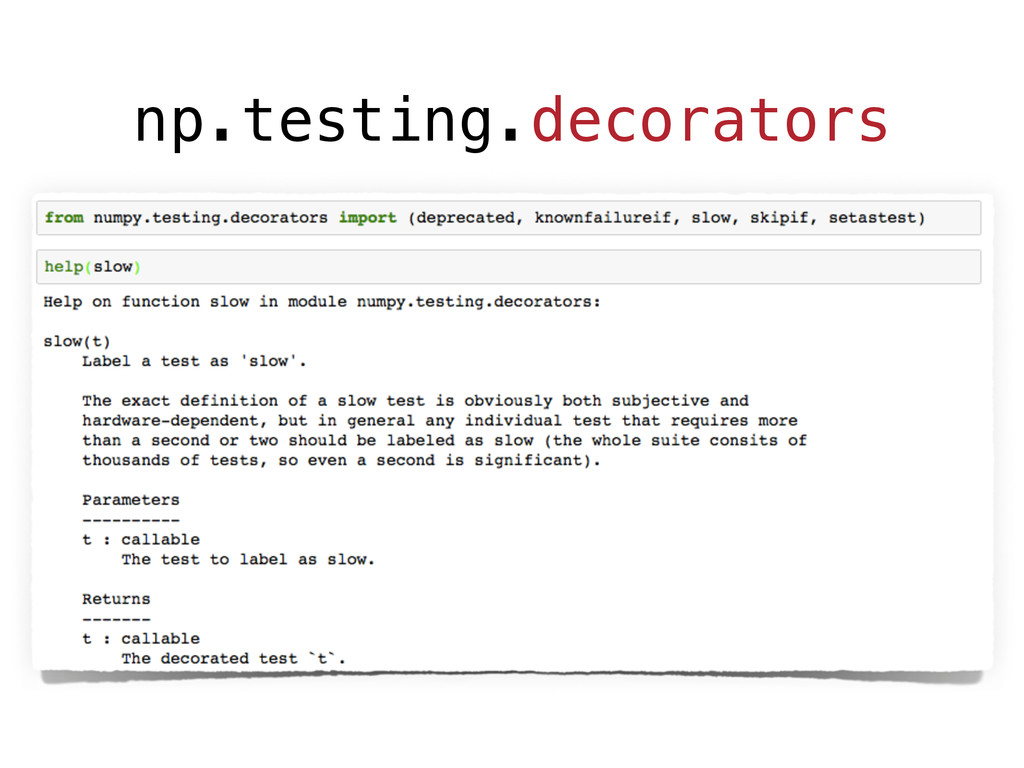
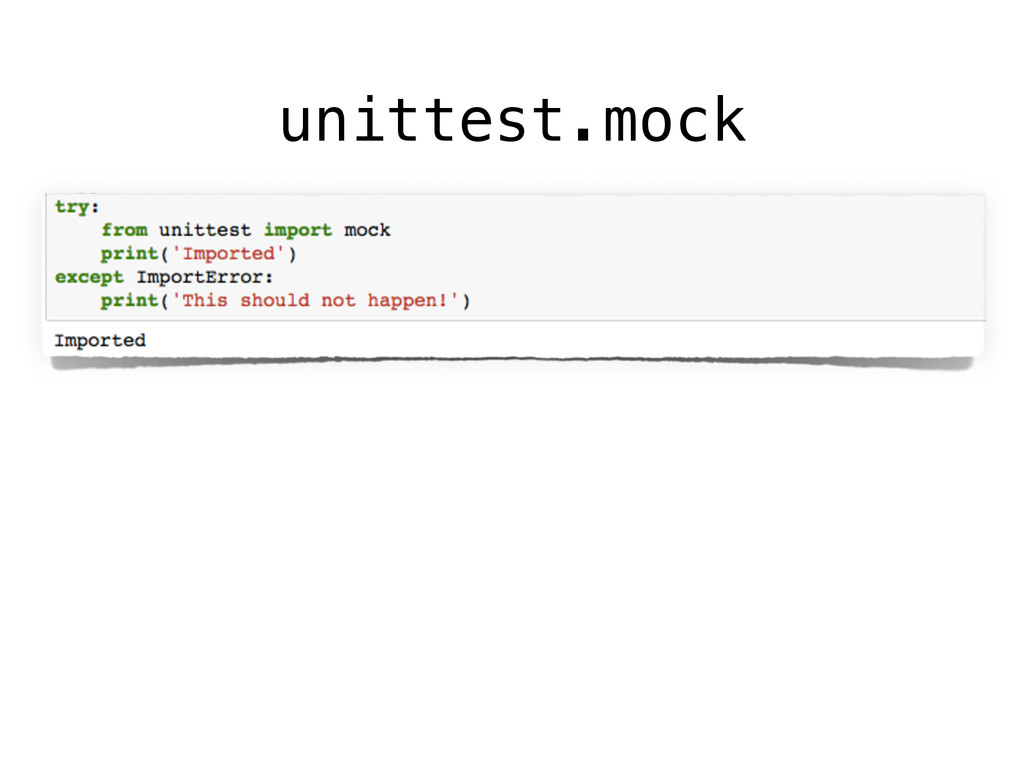
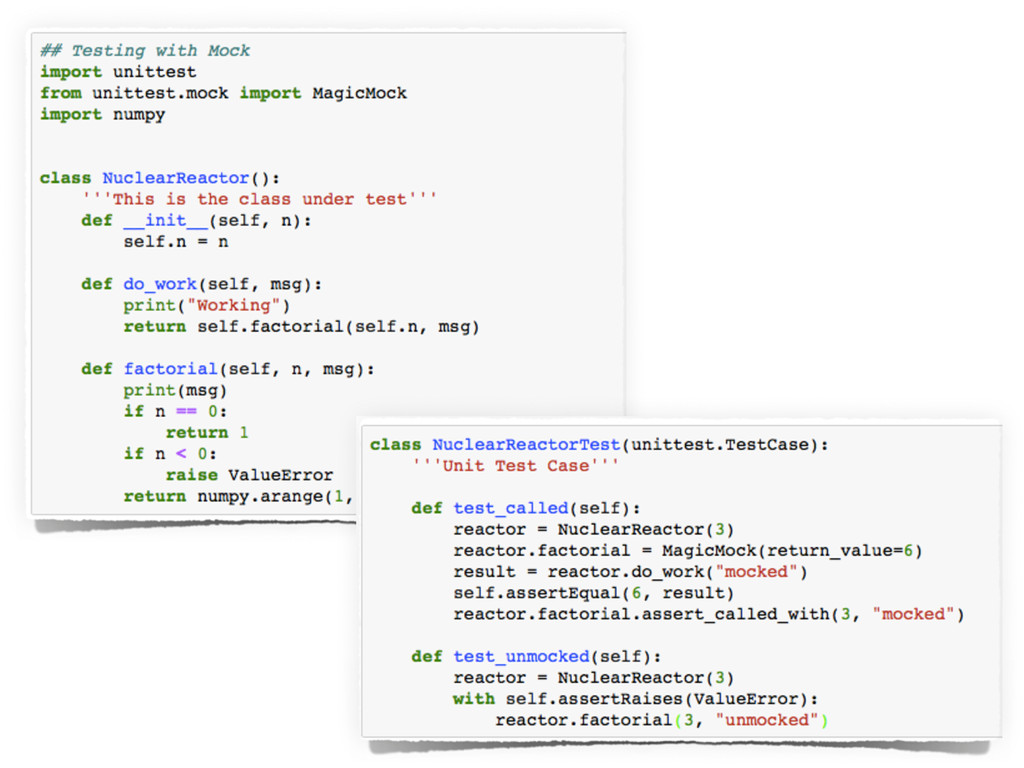
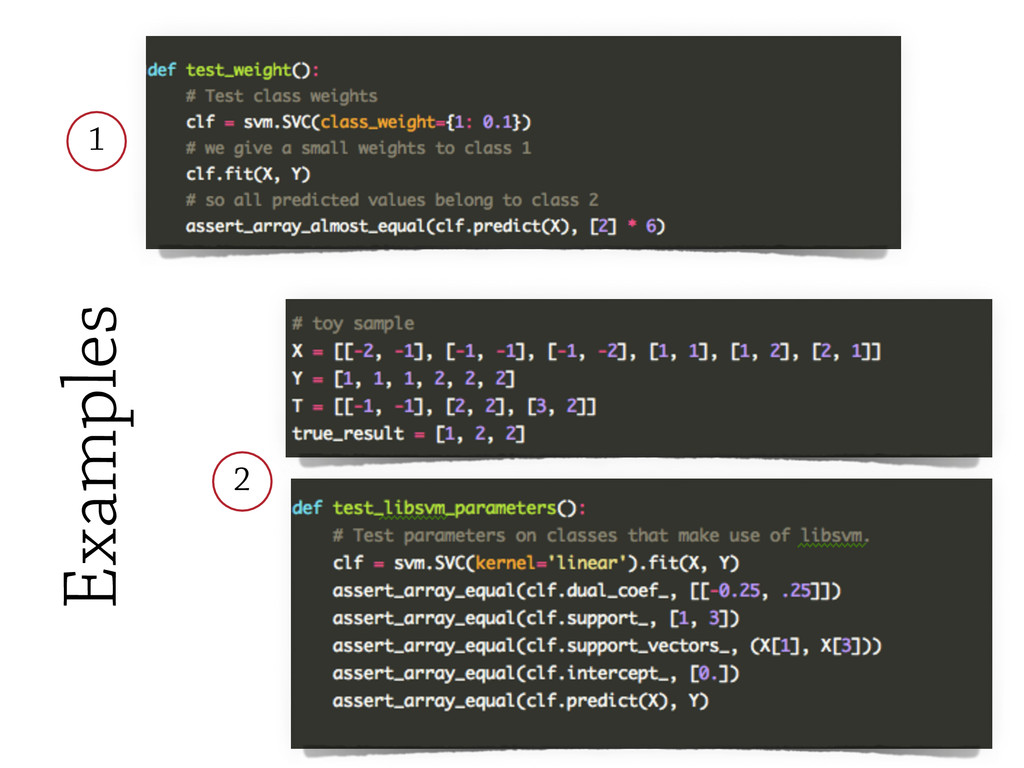
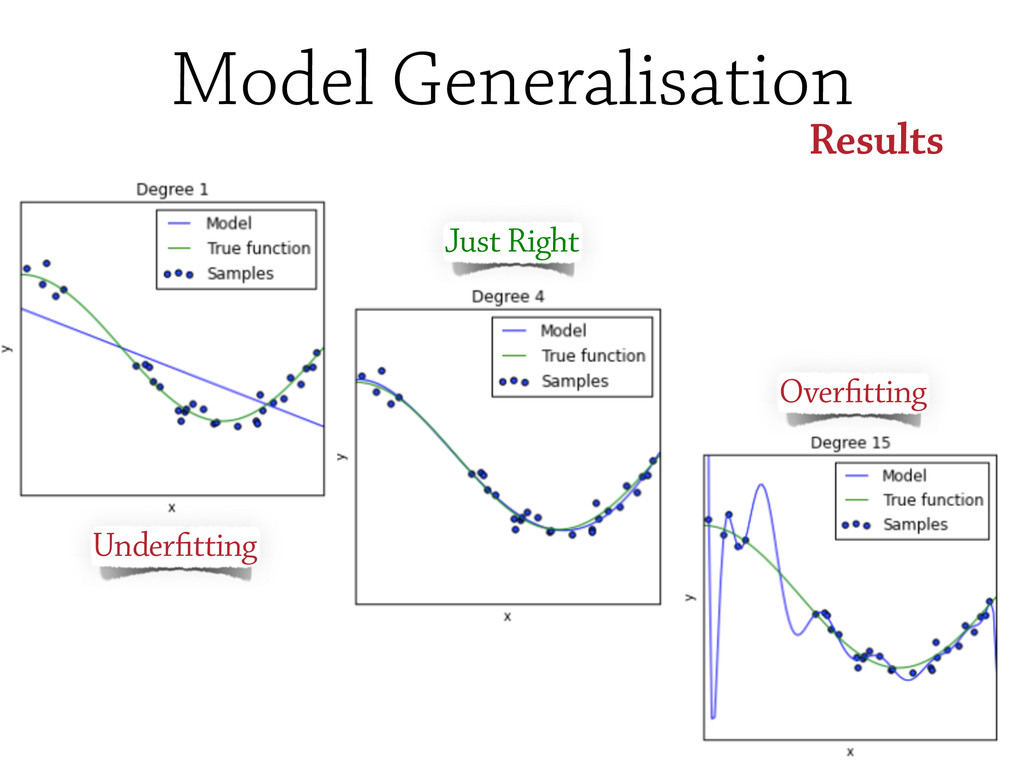
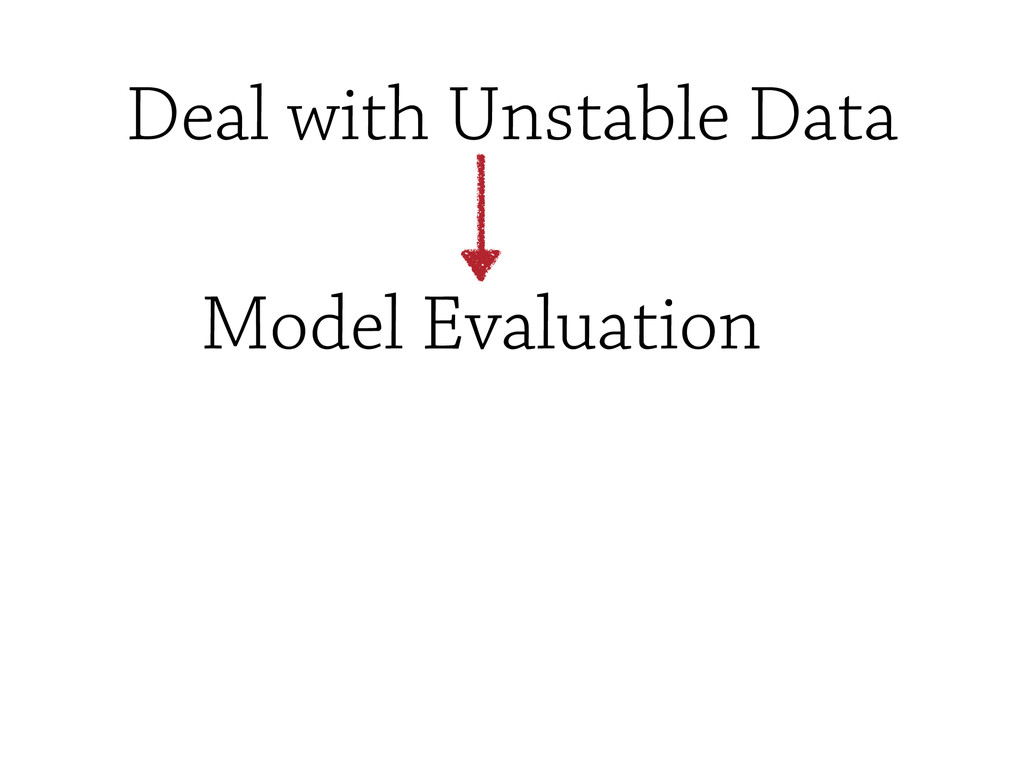
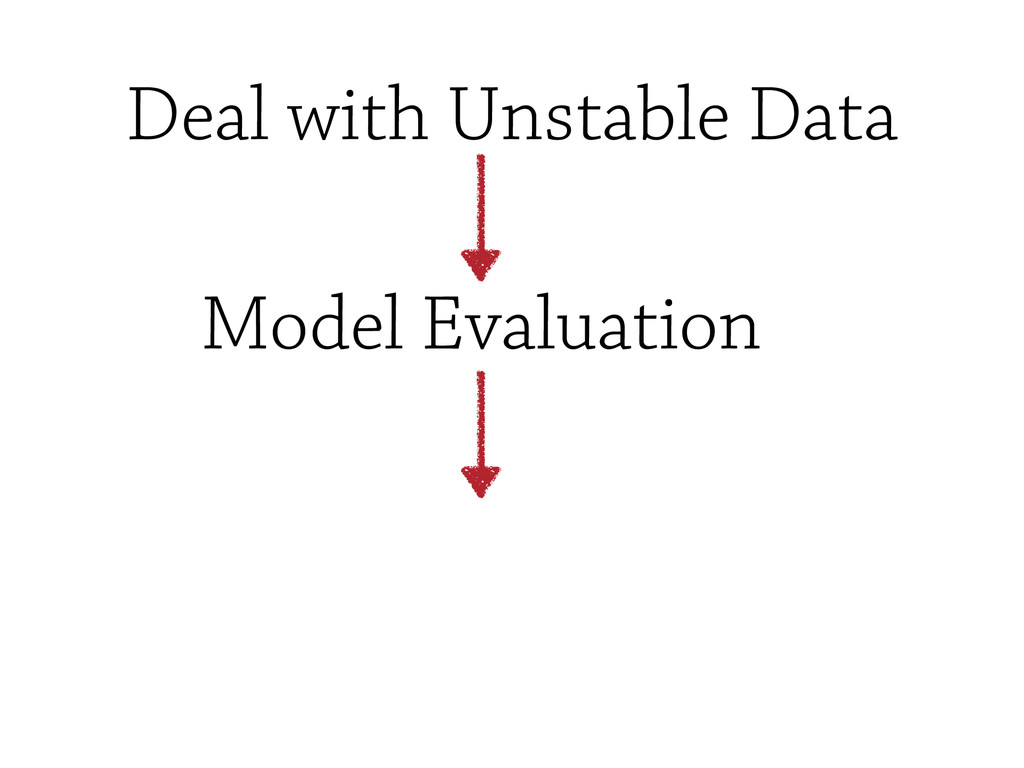
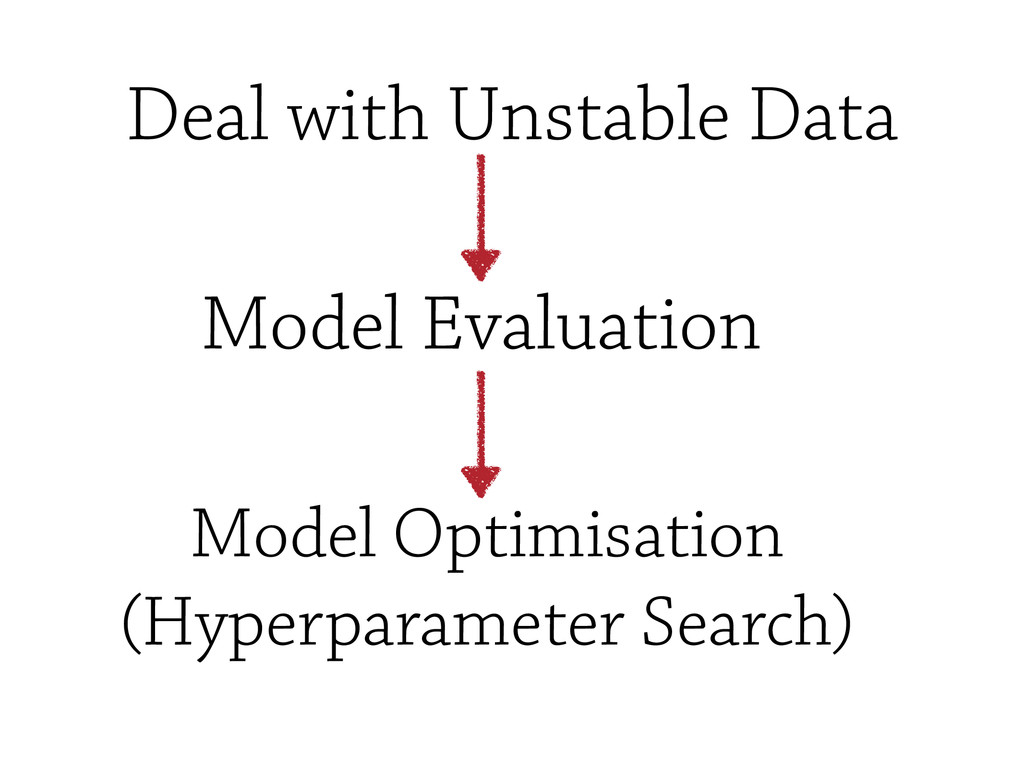
However, testing machine learning code introduces additional concerns that has to be considered. On the one hand, some constraints are imposed by the domain, and the risks intrinsically related to machine learning methods, such as handling unstable data, or avoid under/overfitting. On the other hand, testing scientific code requires additional testing tools (e.g., `numpy.testing`), specifically suited to handle numerical data.
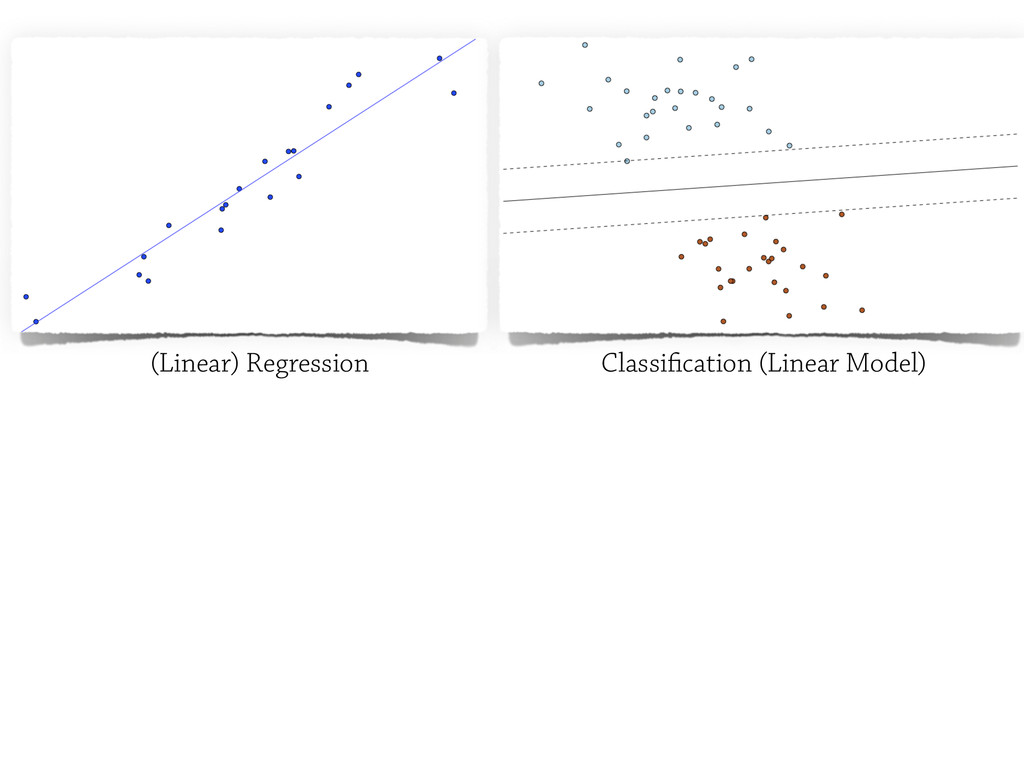
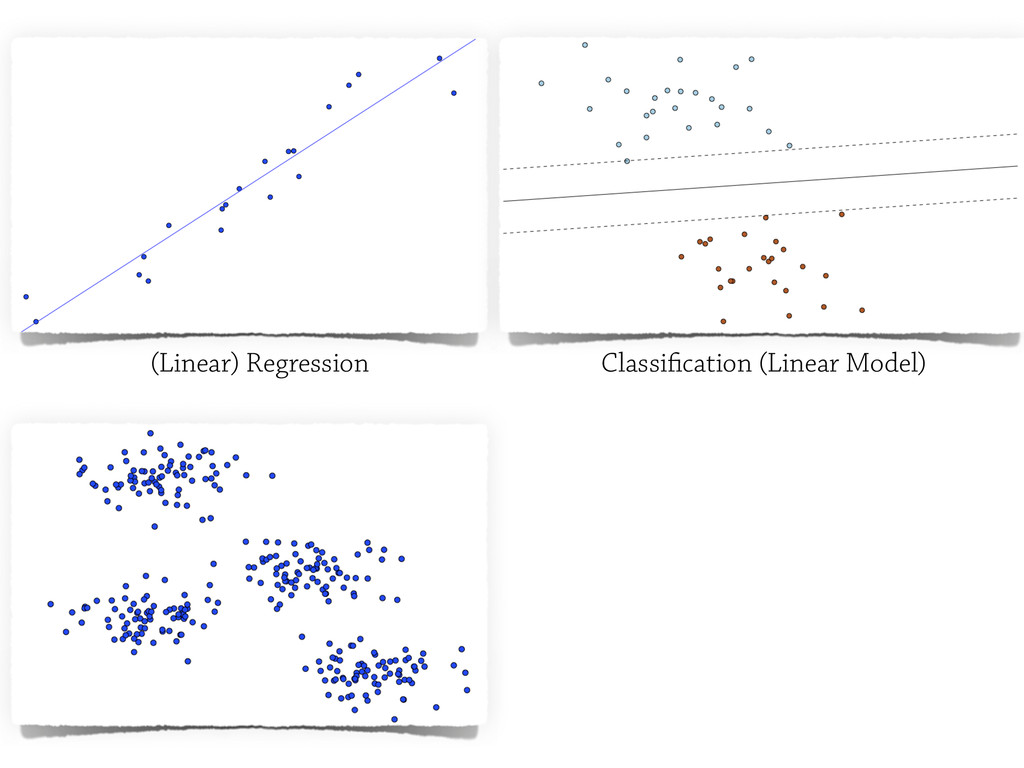
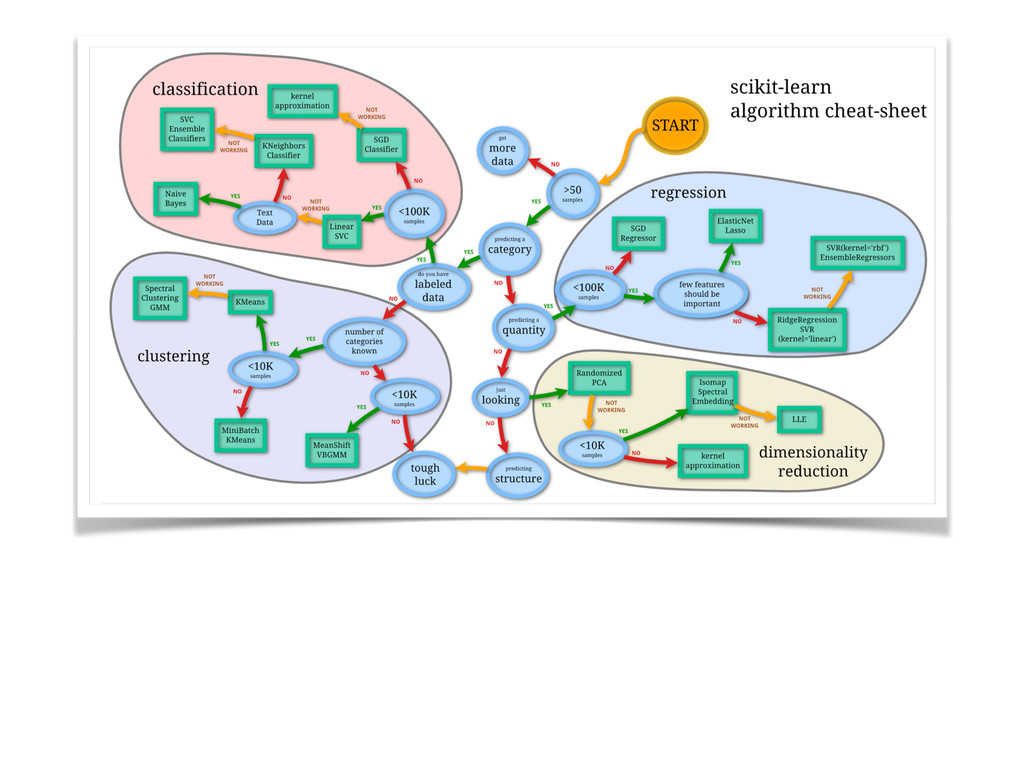
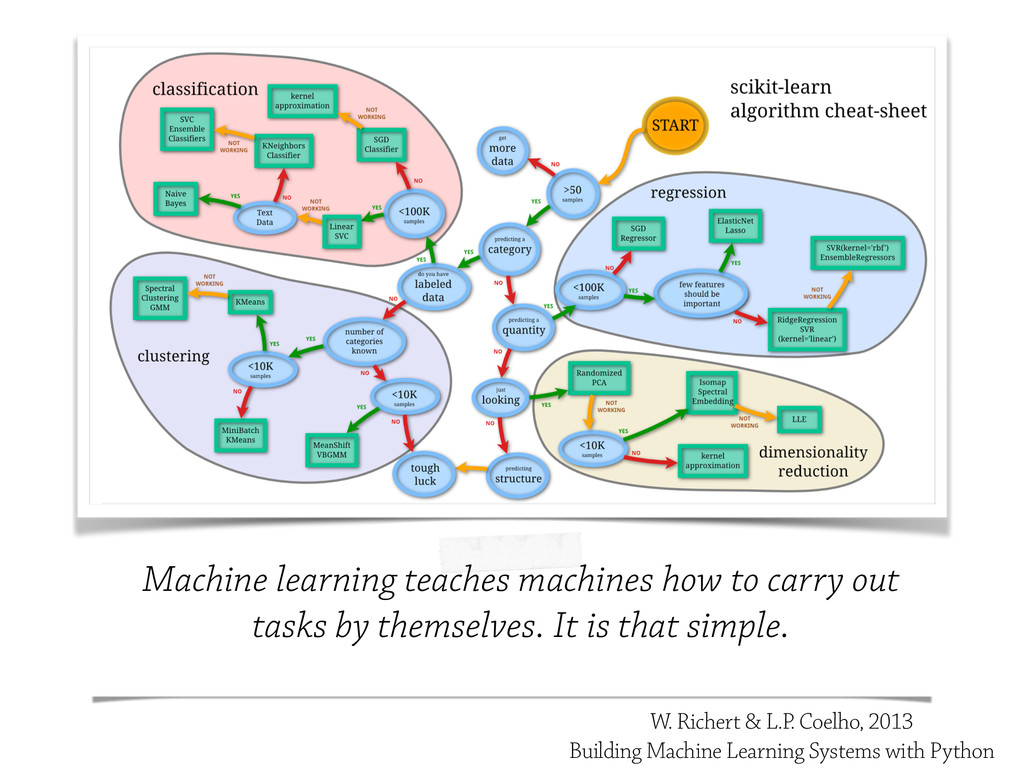
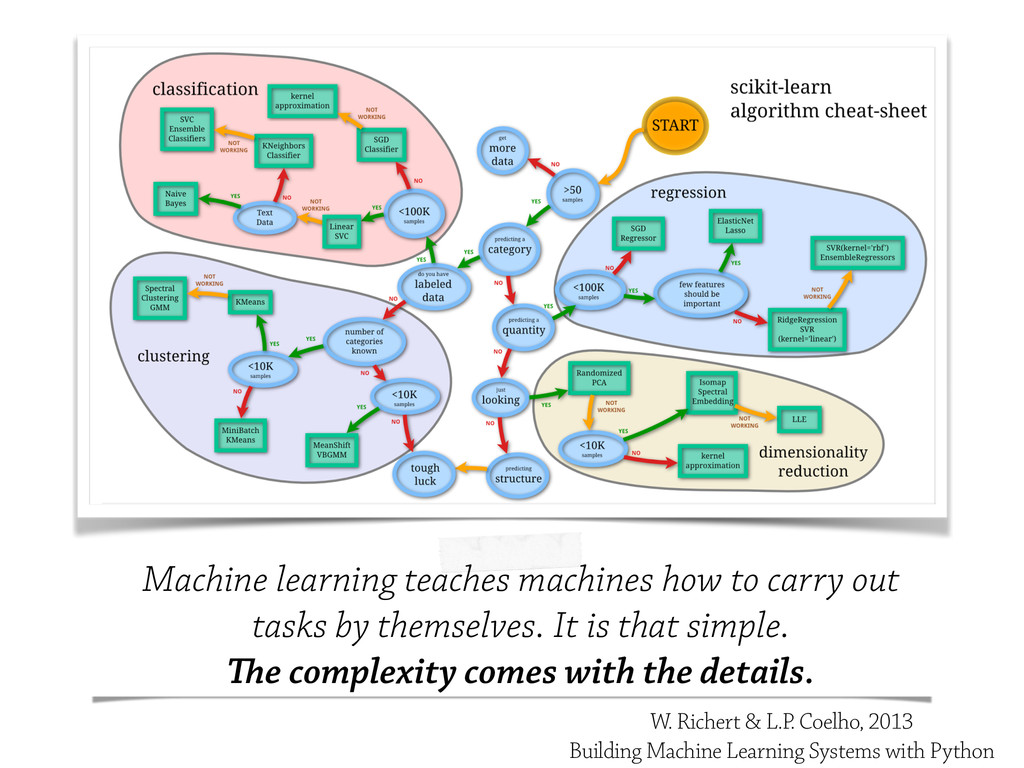
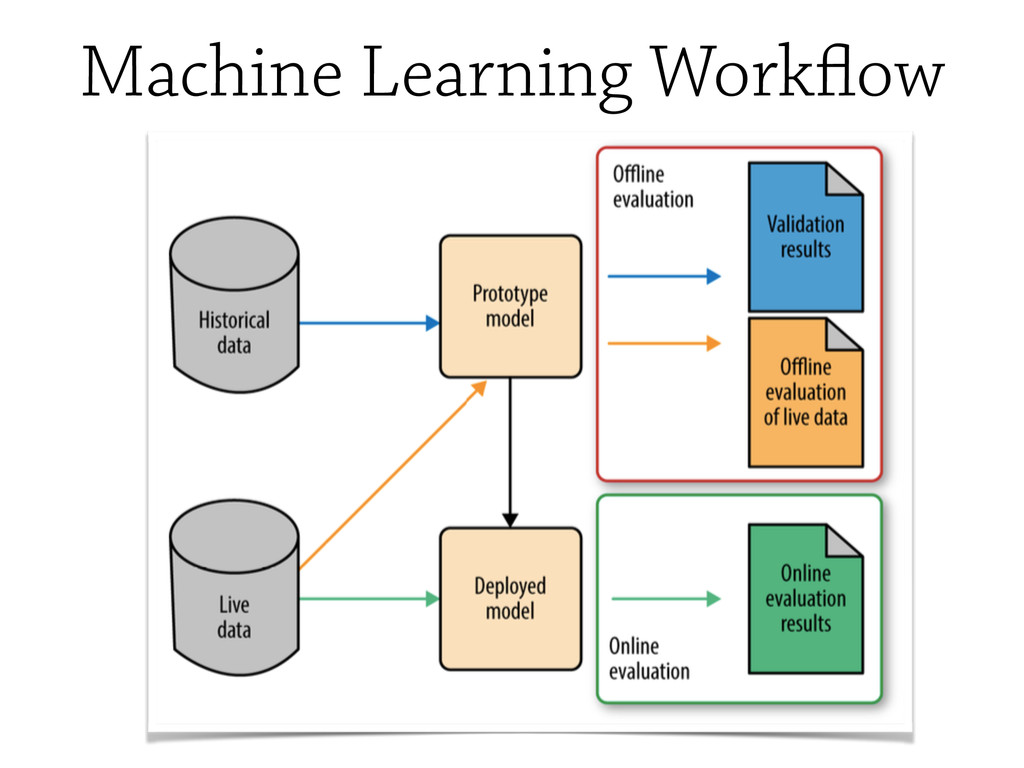
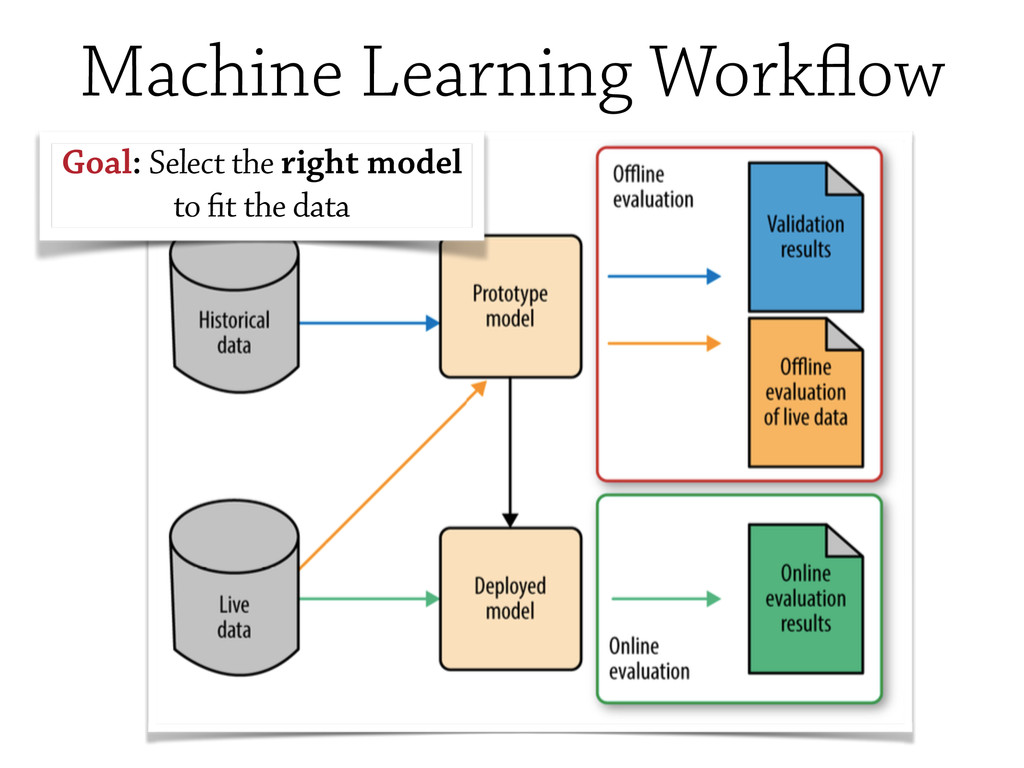
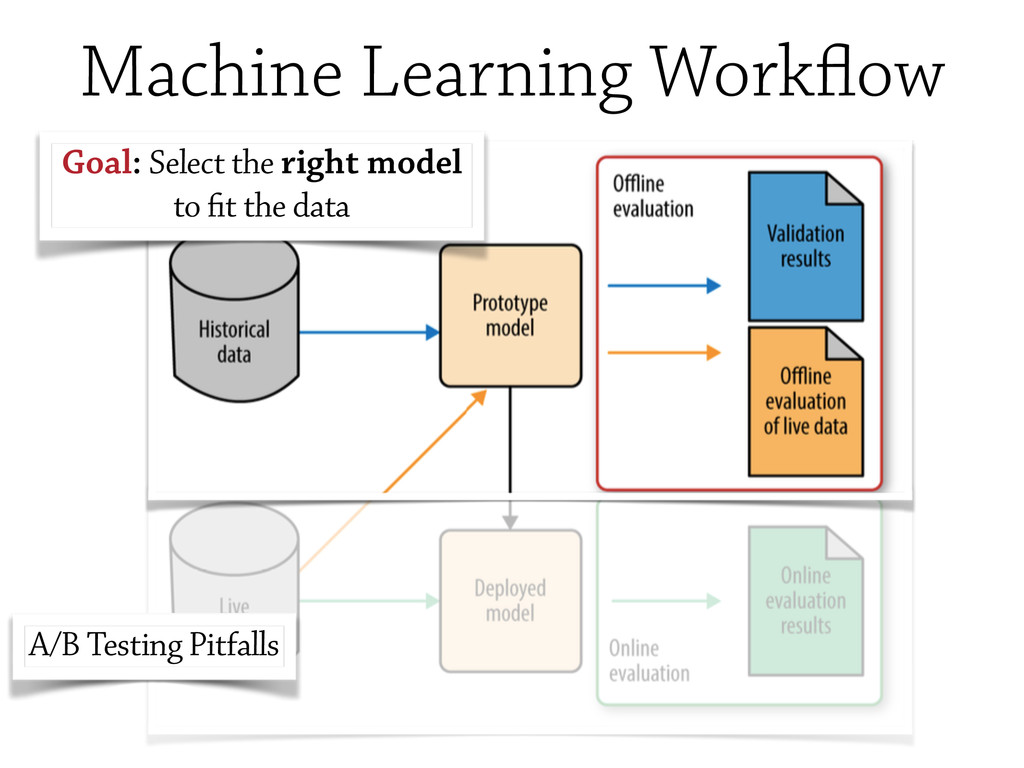
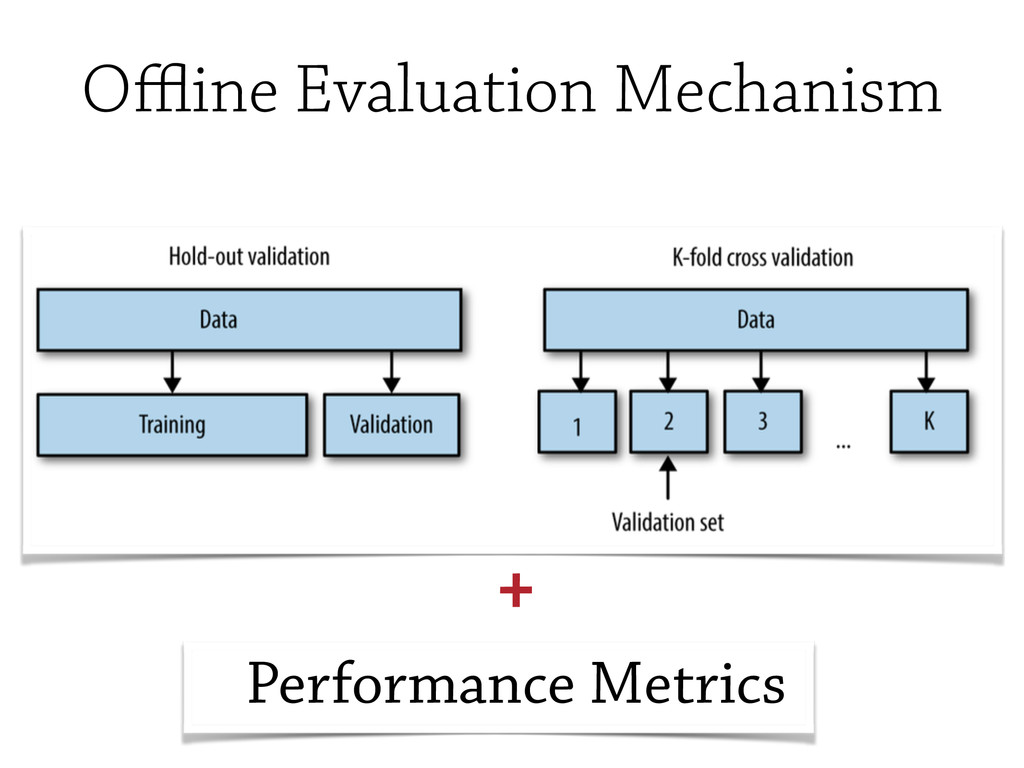
In this talk, some of the most famous machine learning techniques will be discudded and analysed from the `testing` point of view, and some of the most important *Model Evaluation* workflow will be discussed.
The talk is intended for an *intermediate* audience. The content of the talk is intended to be mostly practical, and code oriented. Thus a good proficiency with the Python language is **required**. Conversely, **no prior knowledge** about testing nor Machine Learning algorithms is necessary to attend this talk.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks a lot for your kind attention +ValerioMaggio [email protected] it.linkedin.com/in/](https://files.speakerdeck.com/presentations/d8b31c4286ff4d0793eb65cea6503ed4/slide_84.jpg){kind=link}