**Machine Learning** focuses on *constructing algorithms for making predictions
from data*. These algorithms are usually established in two canonical settings,
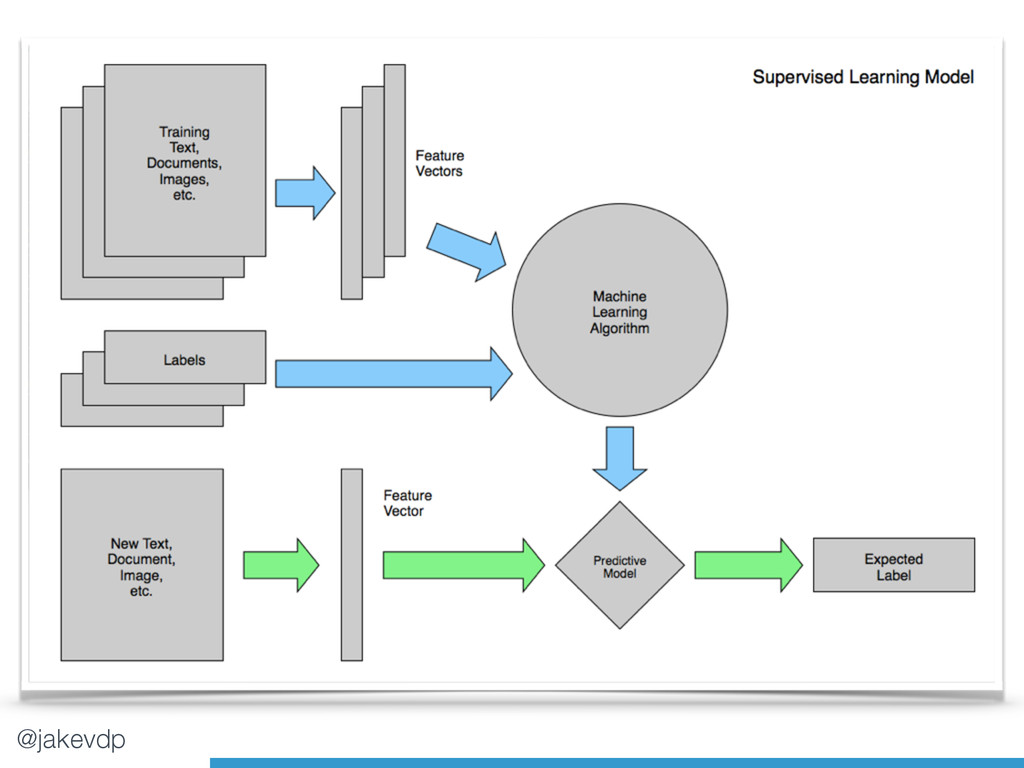
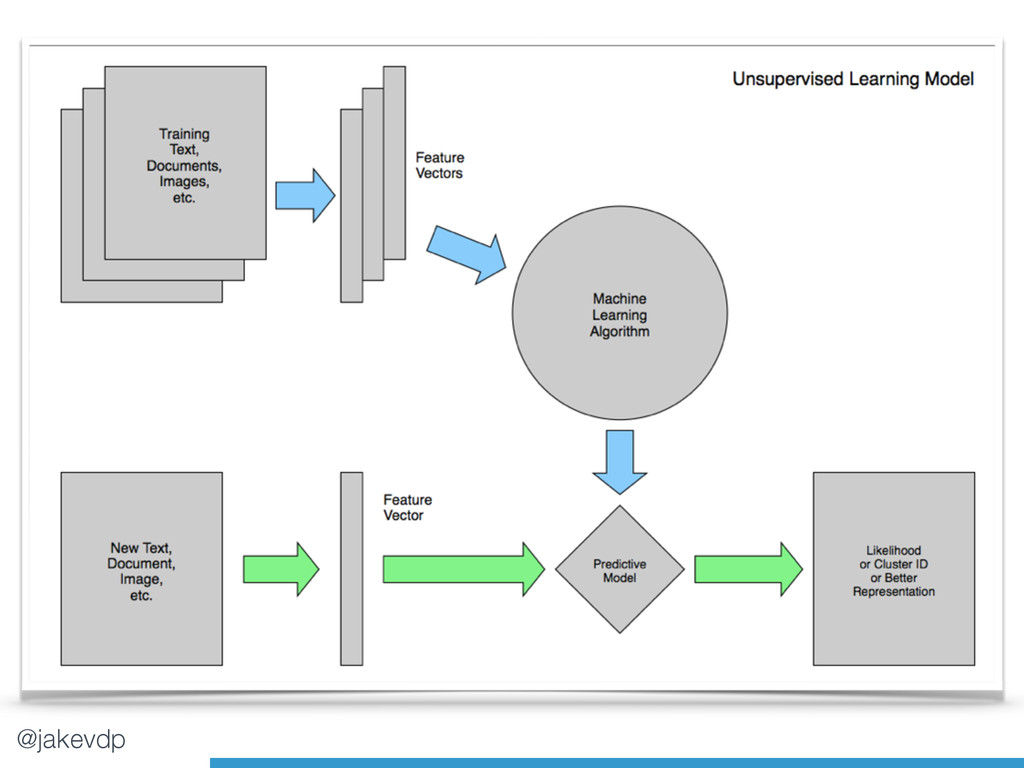
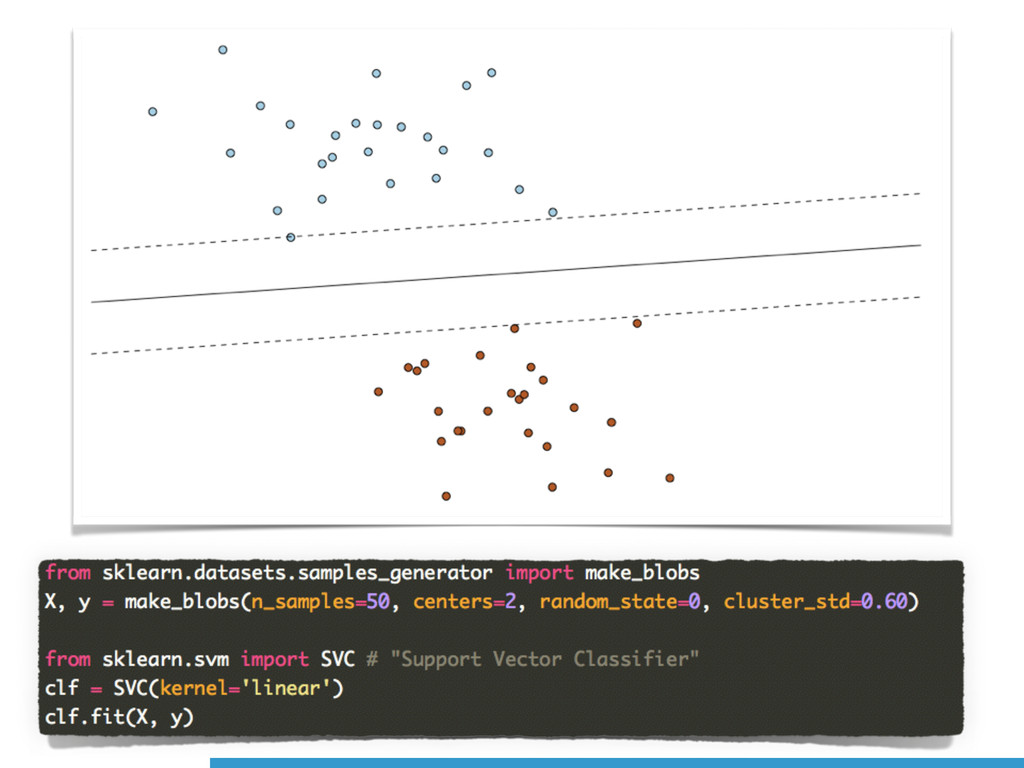
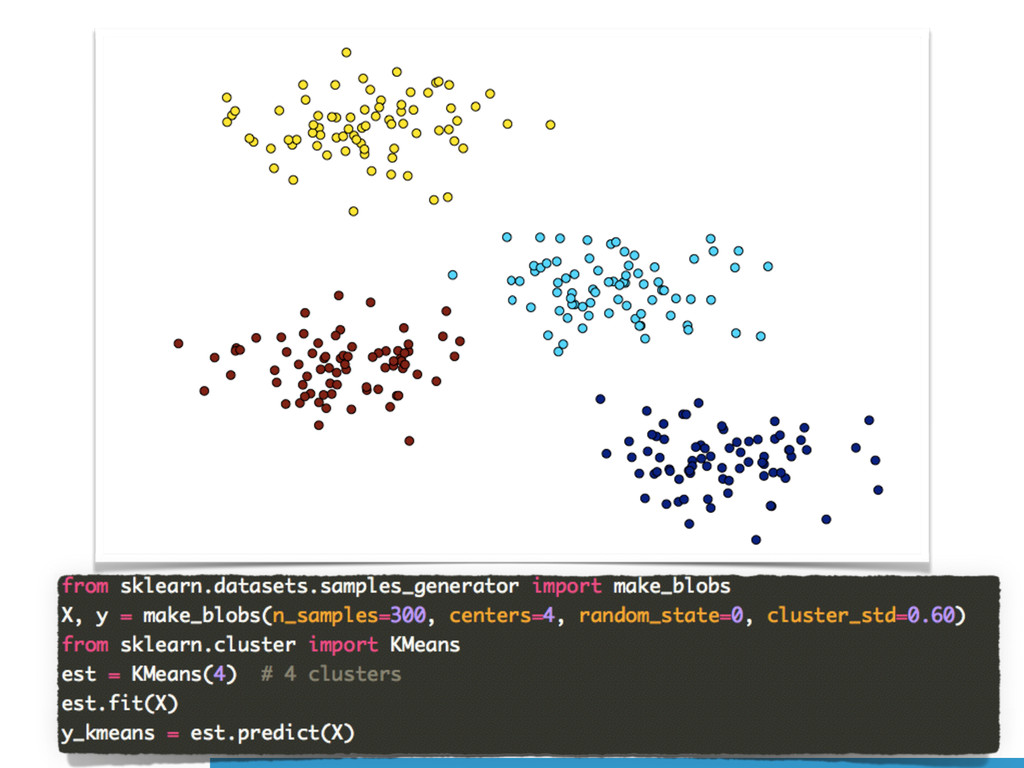
namely *Supervised* and *Unsupervised learning*.
These algorithms usually require to analyze *huge* amount of data, thus demanding
for high computational costs and requiring easily scalable solutions to be
effectively applied.
The **distributed** and **parallel** processing of very large datasets has been employed for
decades in specialized, and high-budget settings.
However, the evolution of hardware architectures, and the advent of the
*cloud* technologies, have brought nowadays dramatic progresses in programming frameworks,
along with a diversity of parallel computing platforms [[Bekkerman et. al.]][0].
These factors favored a more and more increasing interest in *scaling up* machine
learning applications. This increased attention to large scale machine learning
is also due to the spread of very large datasets that are often stored on
distributed storage platforms (a.k.a. *cloud storage*), motivating the
development of learning algorithms that can be properly distributed.
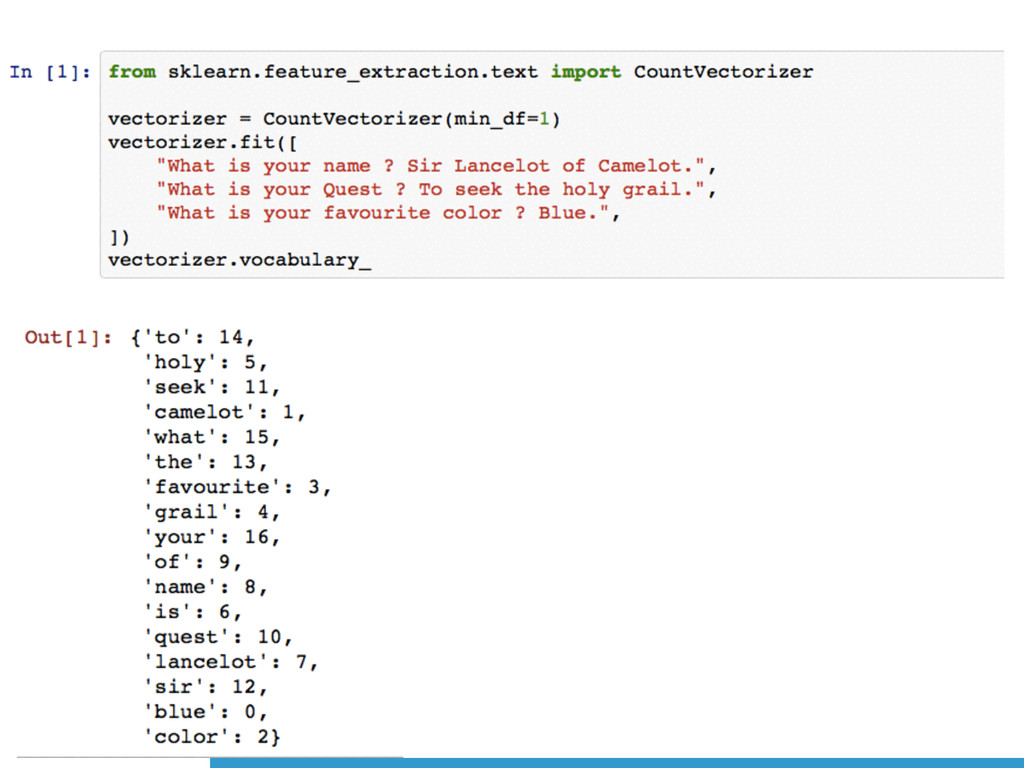
[**Scikit-learn**](http://scikit-learn.org/stable/) is an actively
developing Python library, built on top of the solid `numpy` and `scipy`
packages.
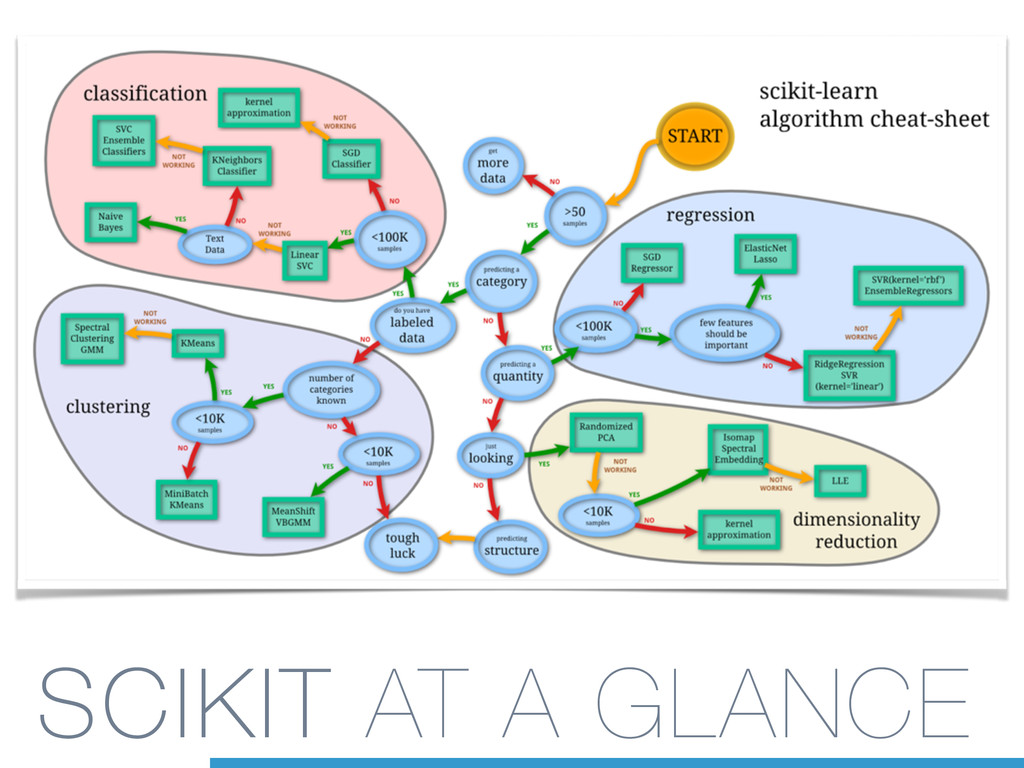
Scikit-learn (`sklearn`) is an *all-in-one* software solution, providing
implementations for several machine learning methods, along with datasets and
(performance) evaluation algorithms.
Thanks to its nice and intuitive API, this library can be easily integrated with
other *Python-powered* solutions for parallel and distributed computations.
In this talk, different solutions to scaling machine learning computations with
scikit-learn will be presented. The *scaling* process will be
described at two different "complexity" levels:
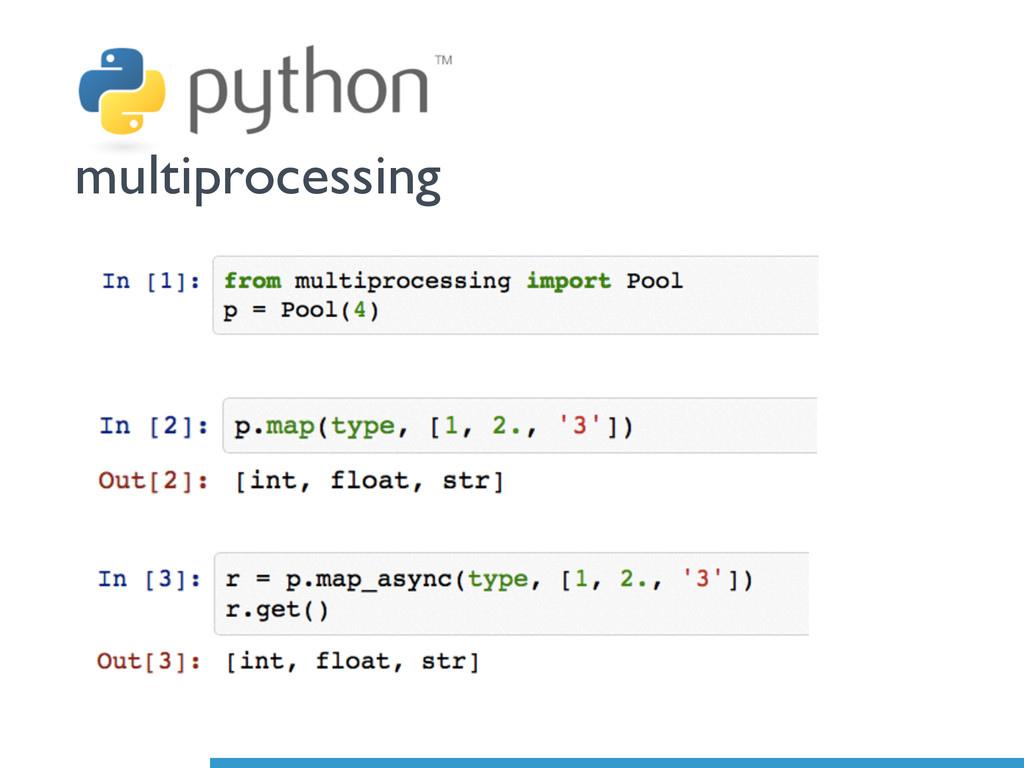
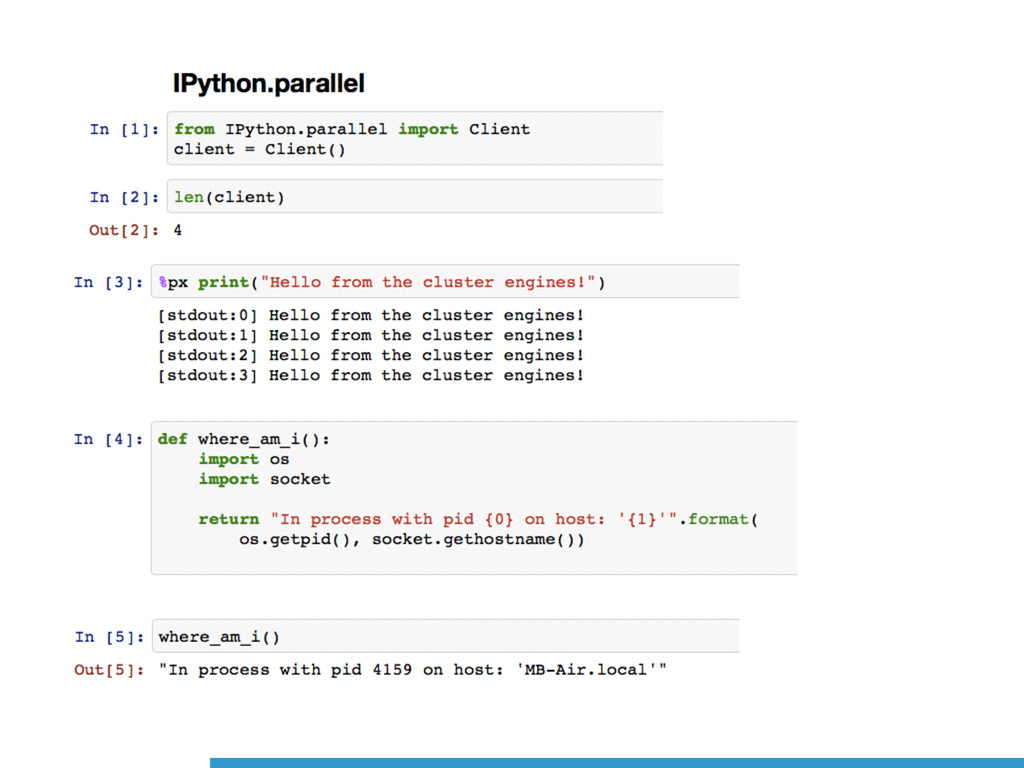
(1) *Single* Machine with Multiple Cores; and (2) *Multiple* Machines with
Multiple Cores.
Working code examples will be discussed during the talk, in order to present solutions
applying the [`multiprocessing`](http://docs.python.org/2/library/multiprocessing.html),
[`joblib`](https://pythonhosted.org/joblib/), and [`mpi4py`](http://mpi4py.scipy.org)
Python libraries (as for the former case). On the other hand,
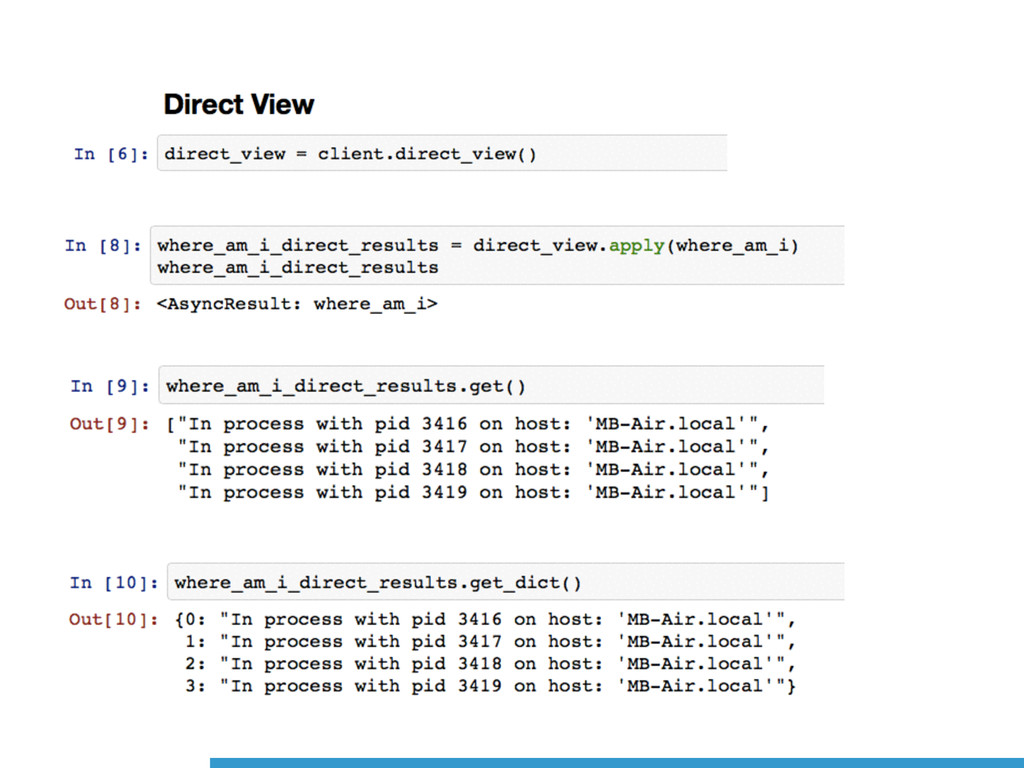
[`iPython.parallel`](http://ipython.org/ipython-doc/dev/parallel/) and
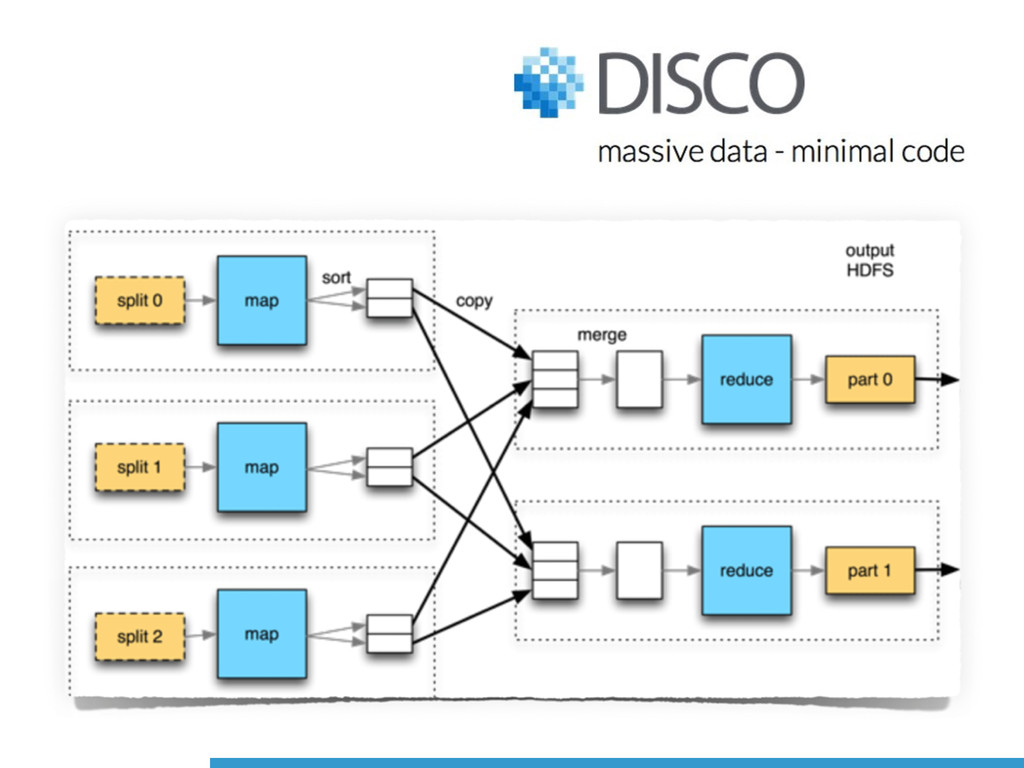
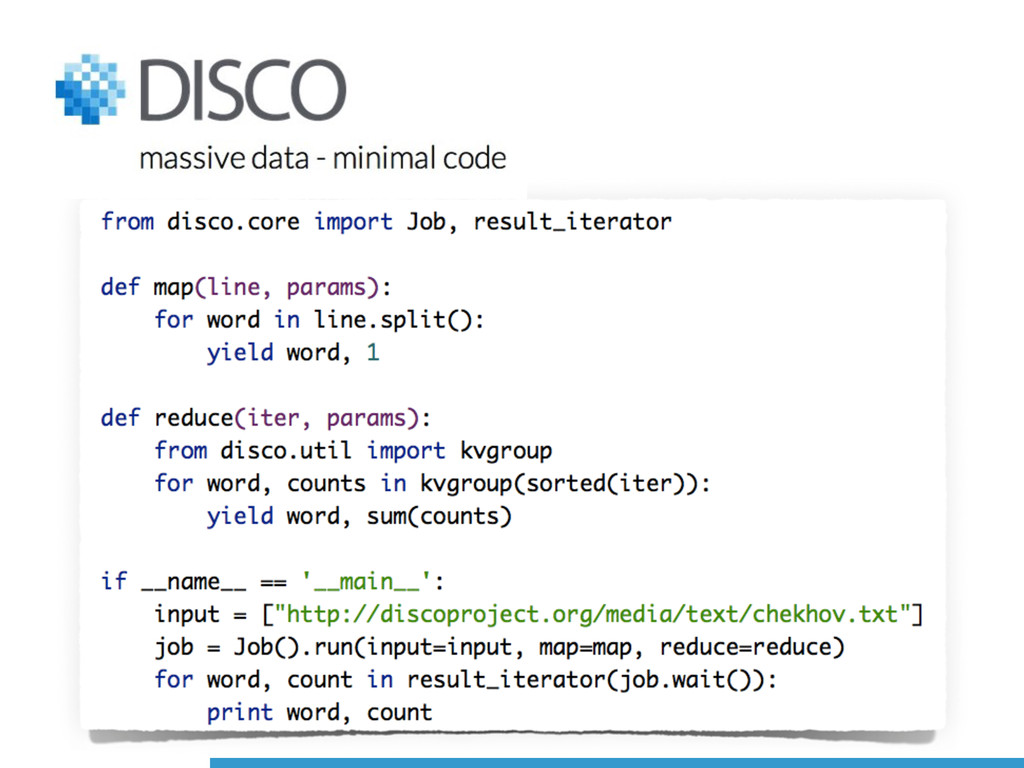
Map-Reduce based solutions (e.g., [Disco](http://discoproject.org)\) will be considered.
The talk is intended for an intermediate level audience (i.e., Advanced).
It requires basic math skills and a good knowledge of the Python language.
Good knowledge of the `numpy` and `scipy` packages is also a plus.
[0]: http://www.amazon.com/dp/B00AKE1ZUU "Scaling Up Machine Learning"
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}