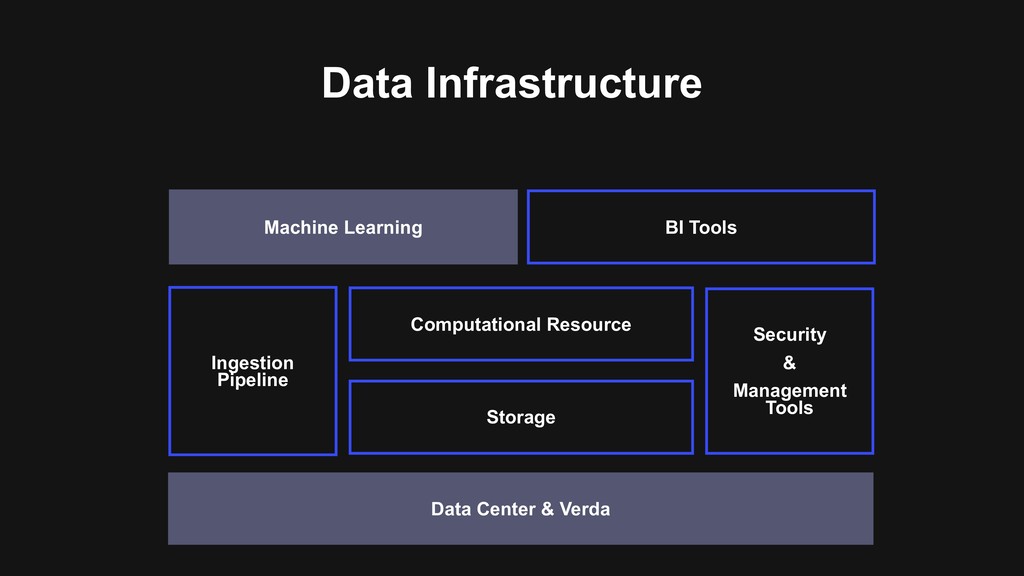
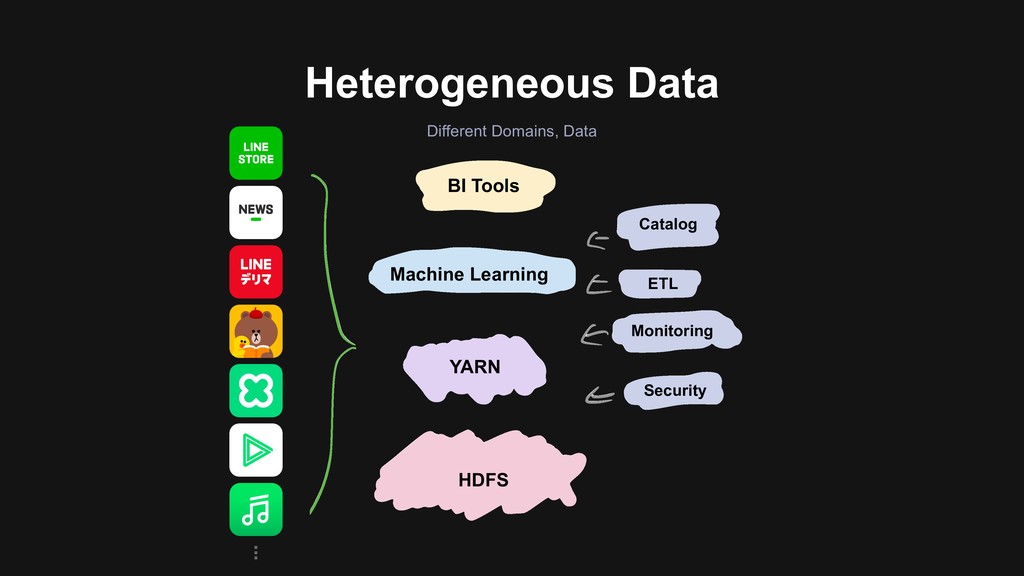
Provide data infrastructure > Manage the whole life cycle of data > Services that we provide > Logging SDK, Ingestion Pipeline, Query Engine, BI Tools > Mission > Provide a governed, self-service data platform > Make Data Driven easy
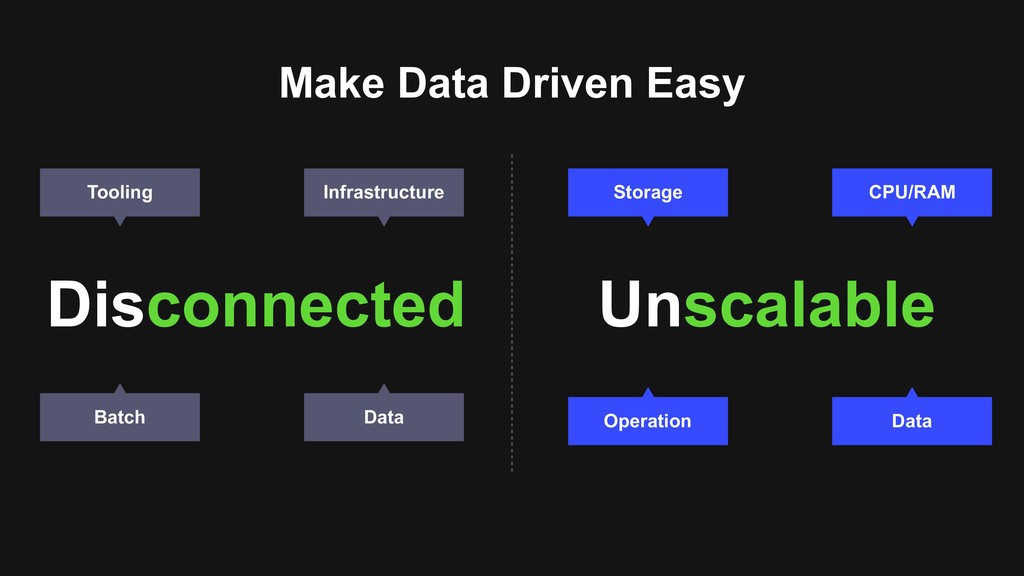
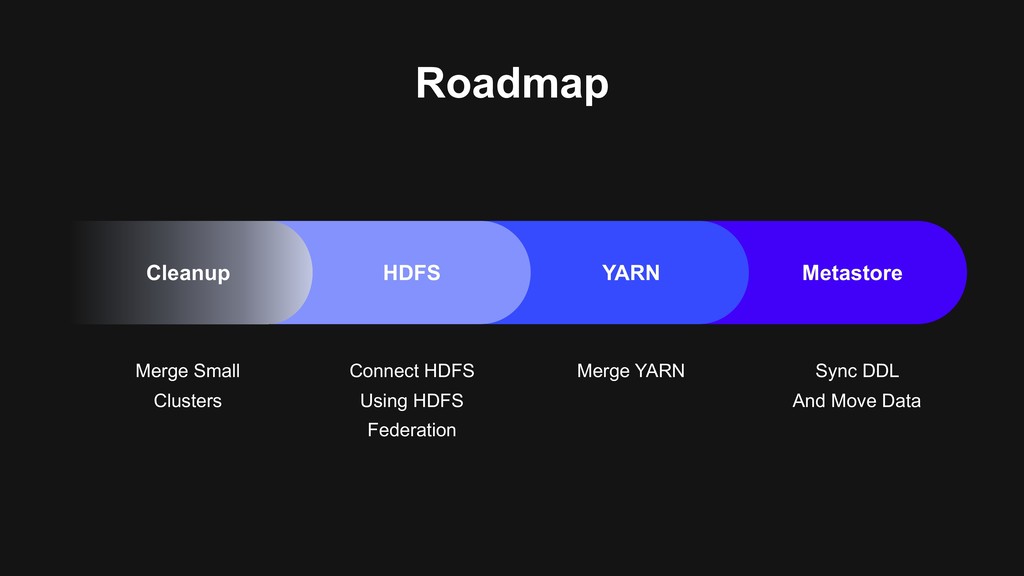
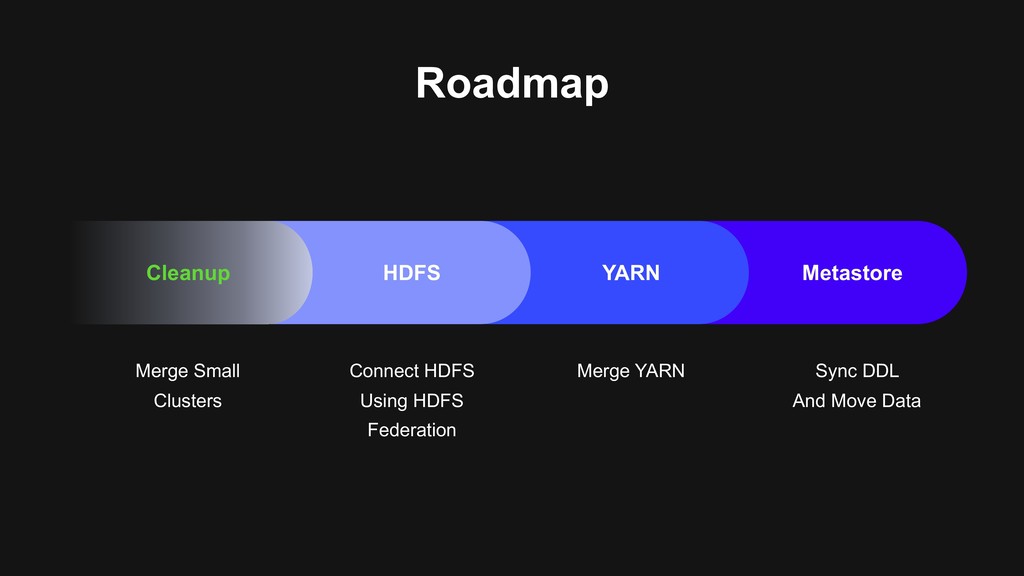
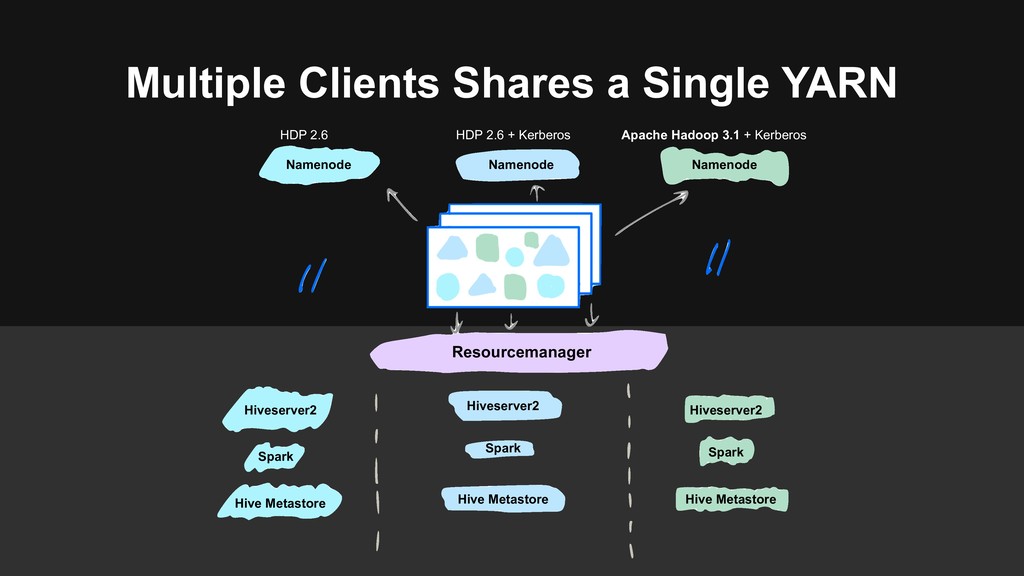
> Determinate API, tooling > No more configuration mess > One cluster > Hadoop 3 is preferred > Reduce operation burden > One standard > Best practice of managing the lifecycle of data
Level > Minimum Risk > No Compulsive Schedule > Incremental Migration Migration à la Carte No Compromise > Cost-Effectiveness > Upgrade Hadoop in Place > Minimum Breaking Changes > Minimum Downtime Minimum User Effects Lean Criteria
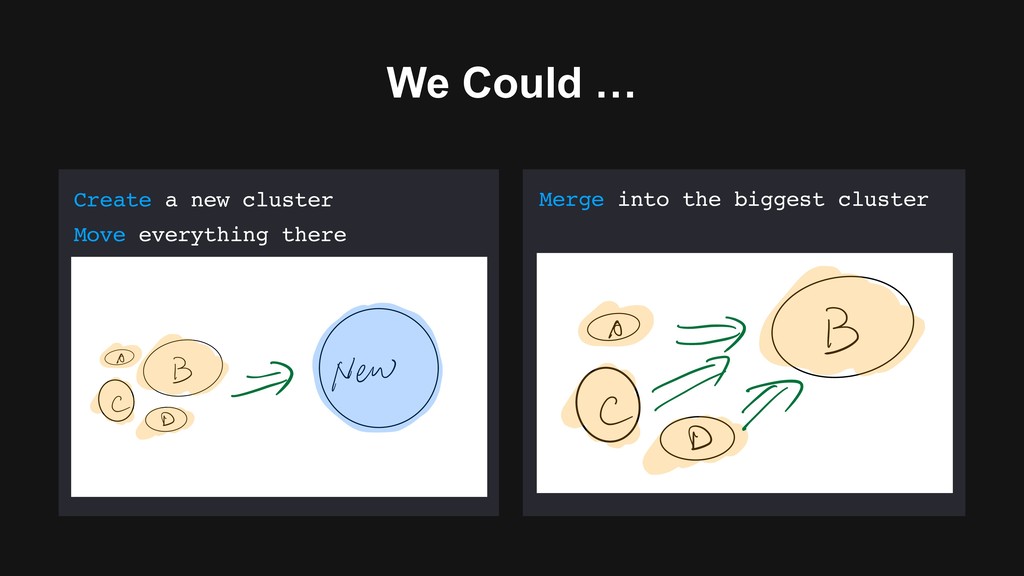
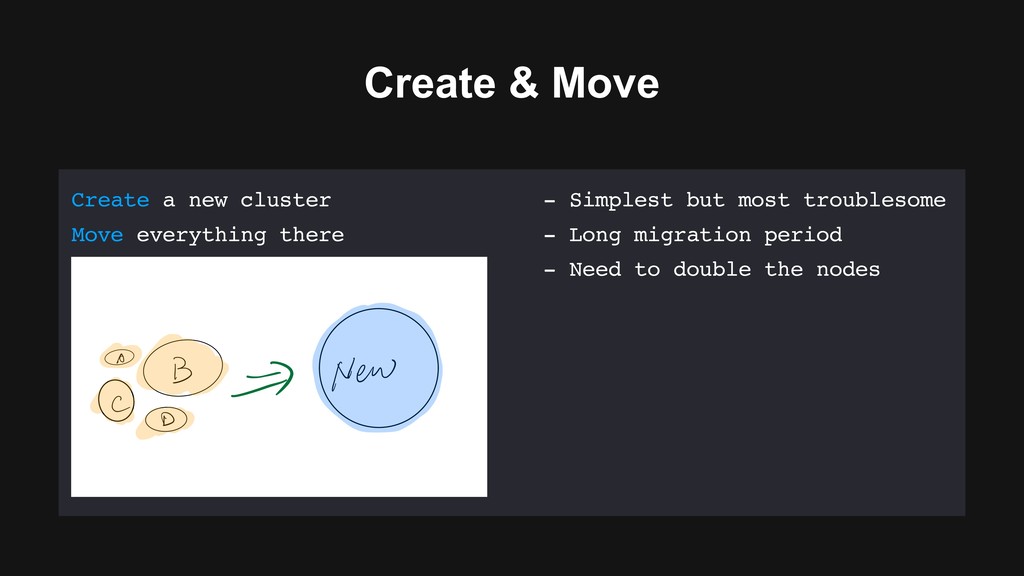
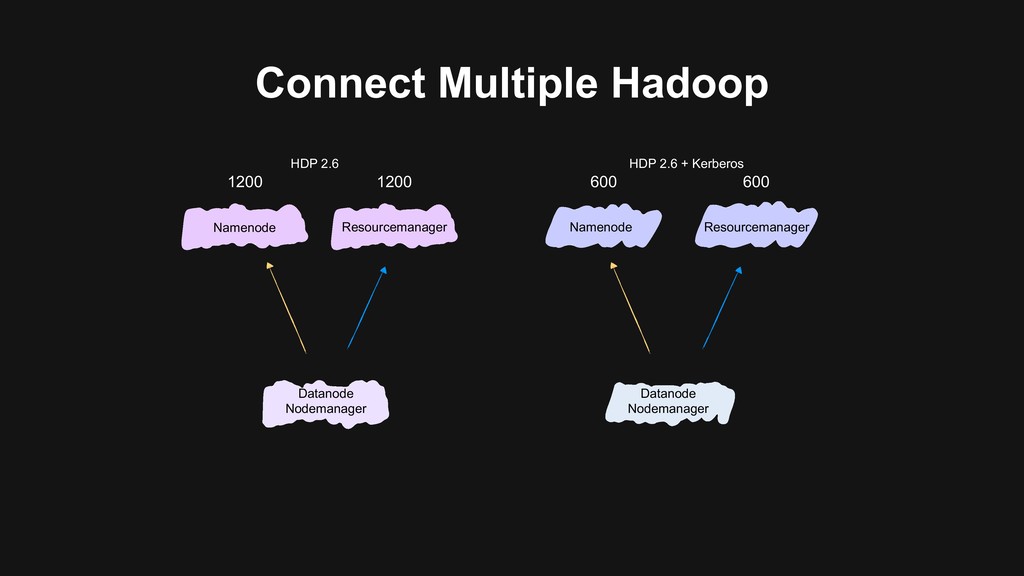
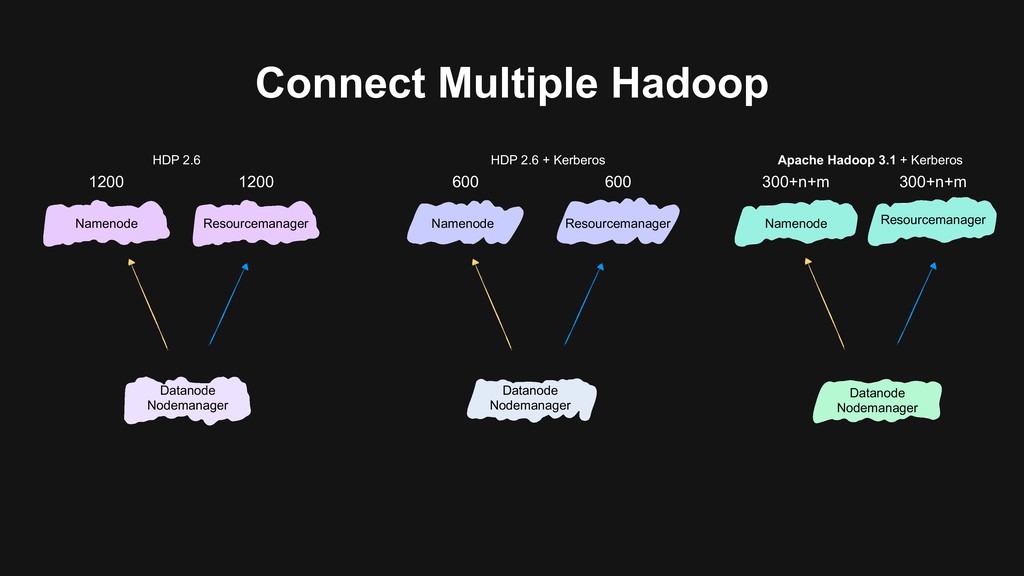
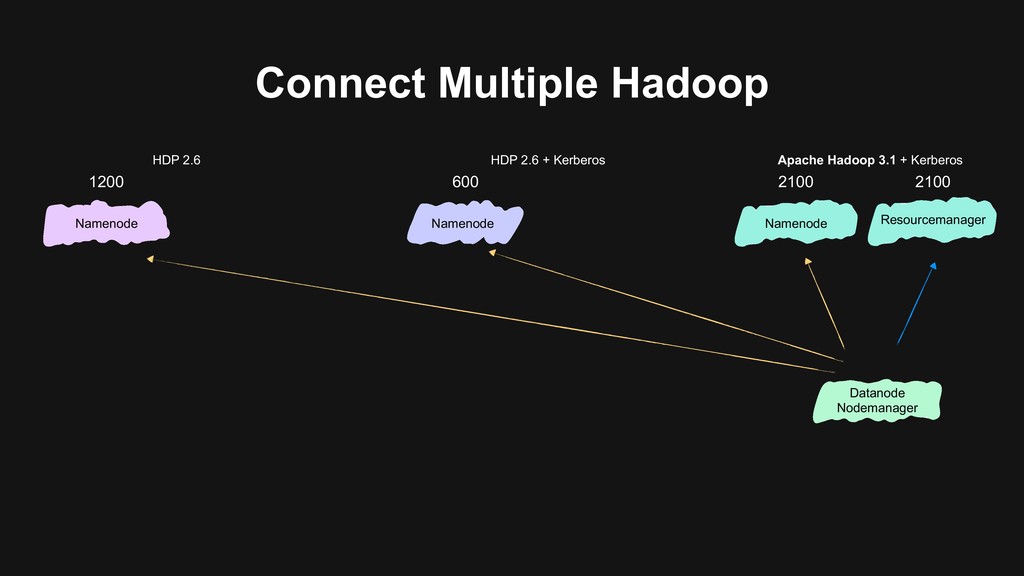
- Simplest but most troublesome - Long transition period - Need to double the nodes Merge into the biggest cluster - // Not fully secured - Major version upgrade remains - i ԫ New in B i ԫ New
secured by Kerberos - We have two big clusters that users use heavily - Still needs to upgrade Hadoop after merging Merge into the biggest cluster - // Not fully secured - Major version upgrade remains - i ԫ New in B
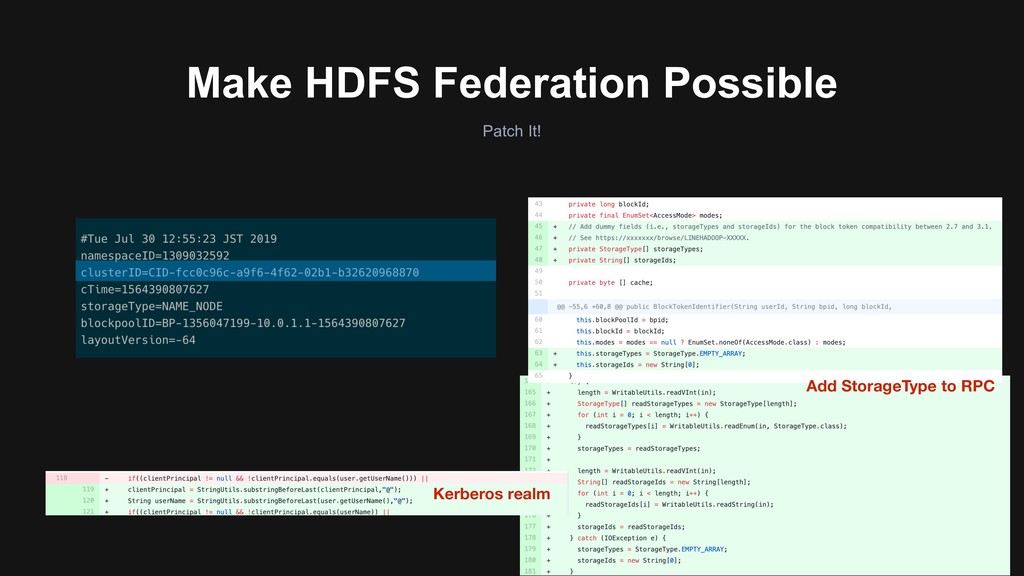
> Fixed by our patches > Fix an order of field numbers for HeartbeatResponseProto > Flink cannot truncate file that have ViewFS path > Allow WebHDFS accesses from insecure NameNodes to secure DataNode > Webhdfs backward compatibility (HDFS-14466 reported by LINER) > Support Hive metastore impersonation(Presto#1441 by LINER) > File Merge tasks fail when containers are reused (HIVE-22373 by LINER) > Backporting 10+ community patches
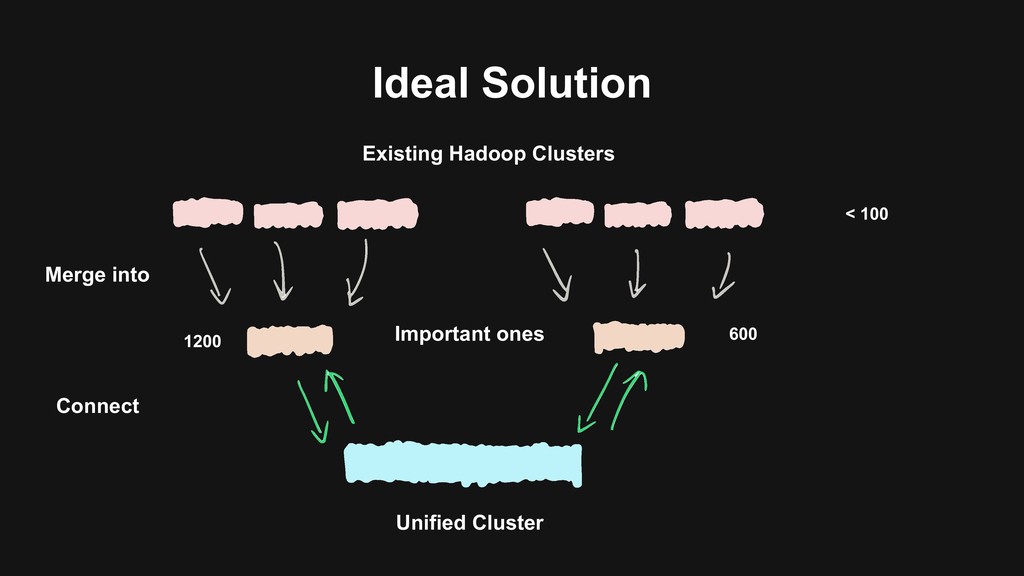
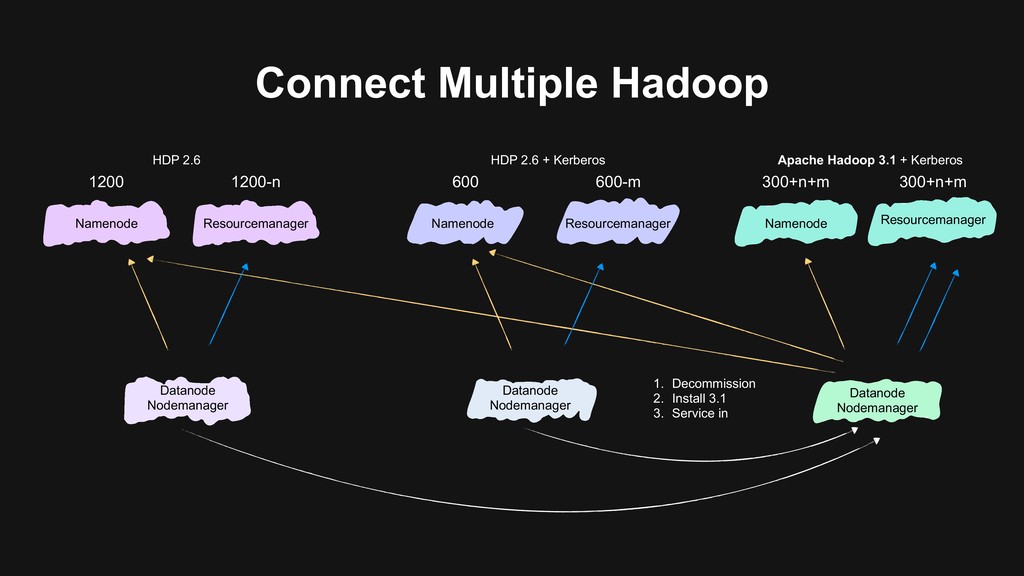
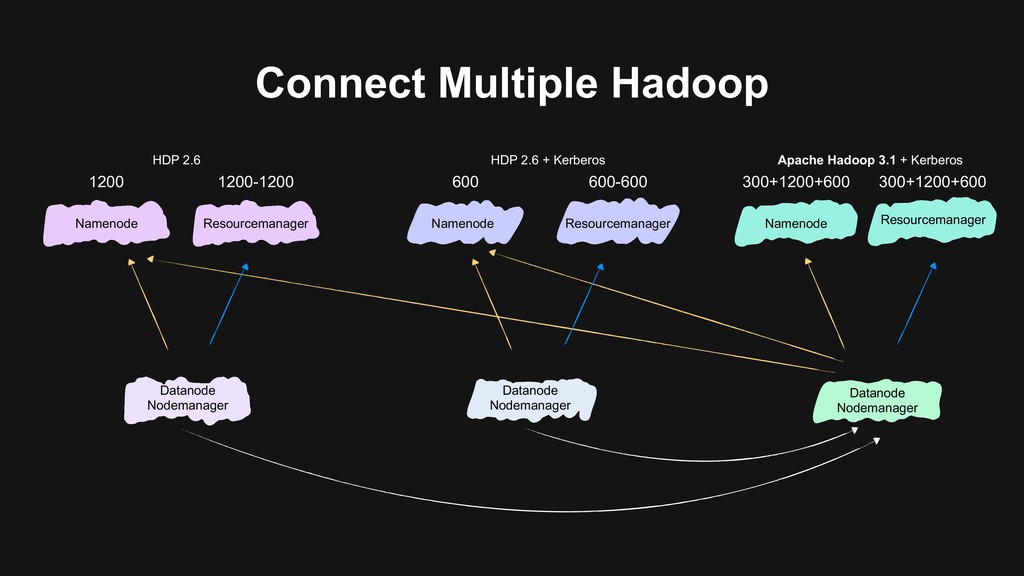
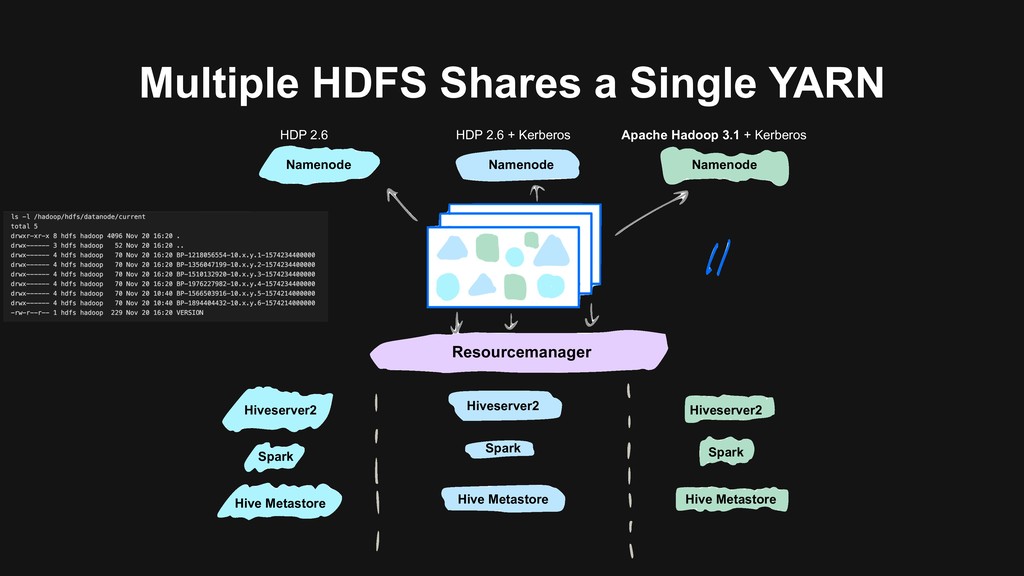
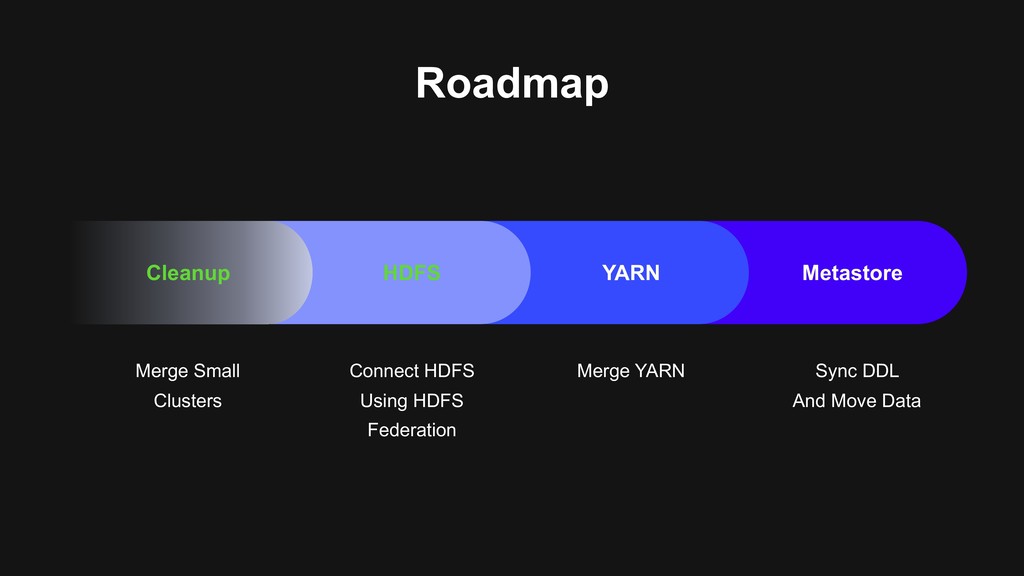
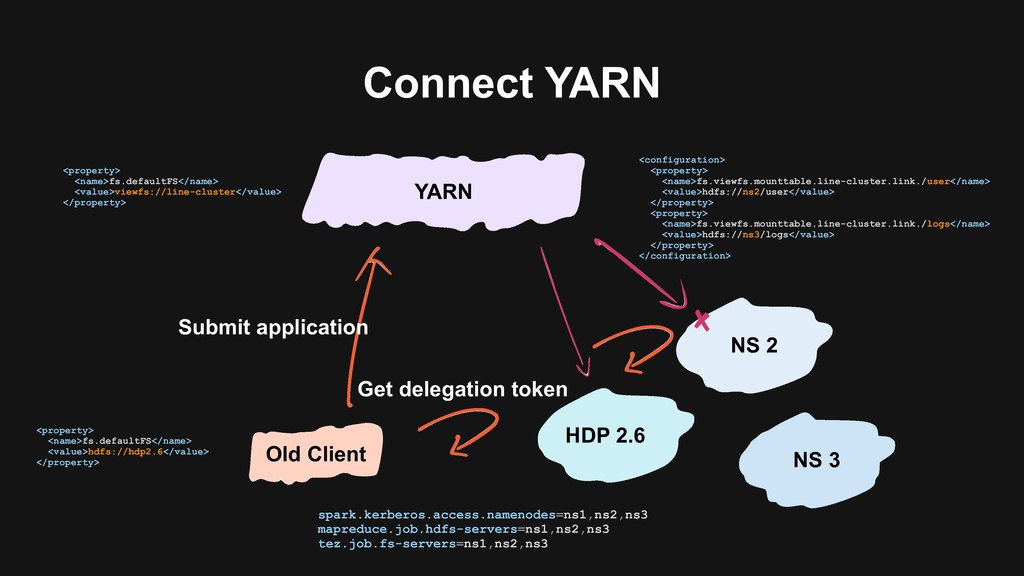
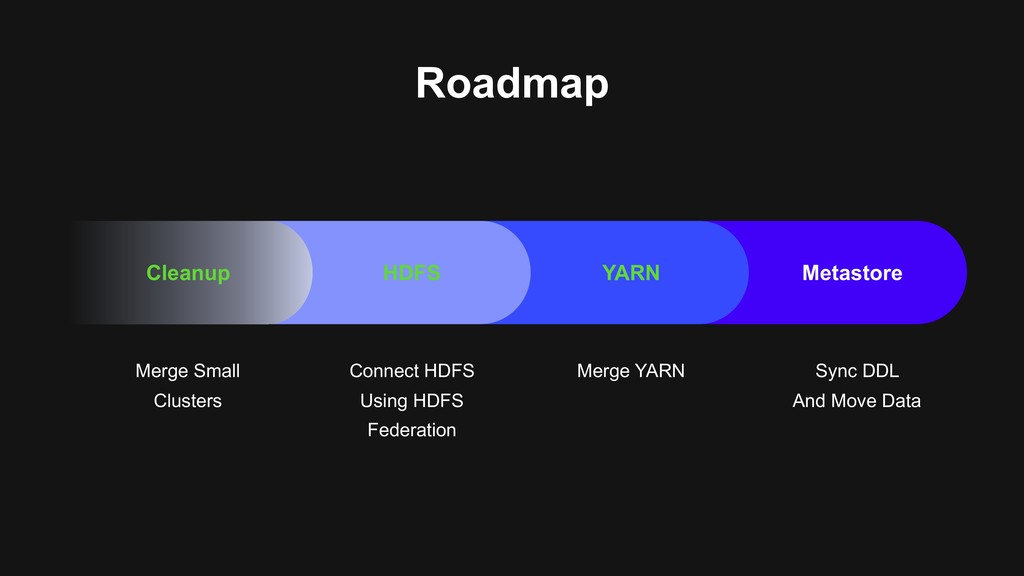
users to migrate > Backward-compatibility > Flexible migration schedule > Build the next generation data platform based on Hadoop 3 > Using Erasure Coding > Using Docker on YARN > Build a unified cluster based on old clusters > Upgrade Hadoop at the same time > Storage, computational resources merged
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}