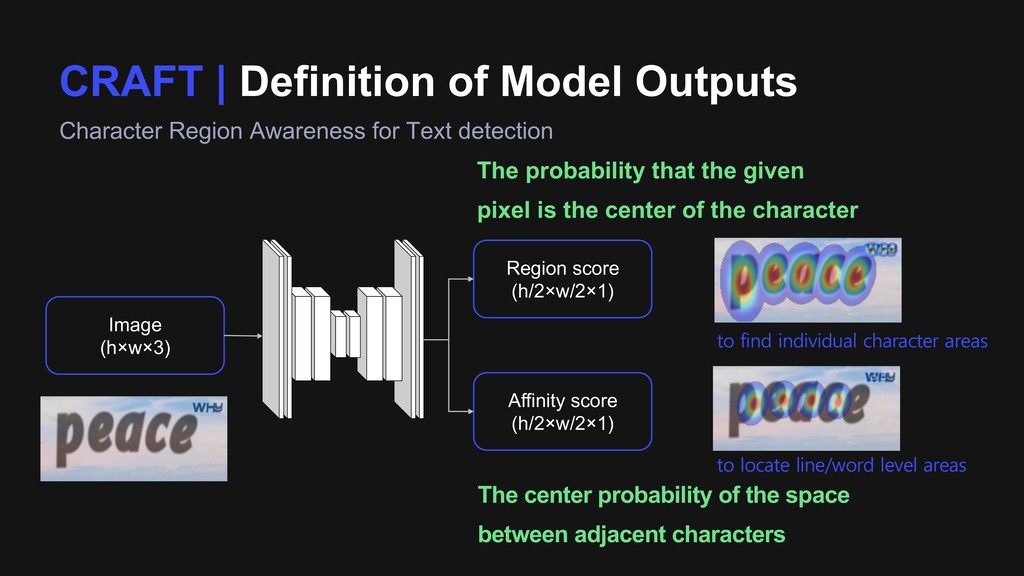
Text detection Image (h×w×3) Region score (h/2×w/2×1) Affinity score (h/2×w/2×1) The probability that the given pixel is the center of the character The center probability of the space between adjacent characters
Text detection Image (h×w×3) Region score (h/2×w/2×1) Affinity score (h/2×w/2×1) The probability that the given pixel is the center of the character The center probability of the space between adjacent characters to find individual character areas to locate line/word level areas
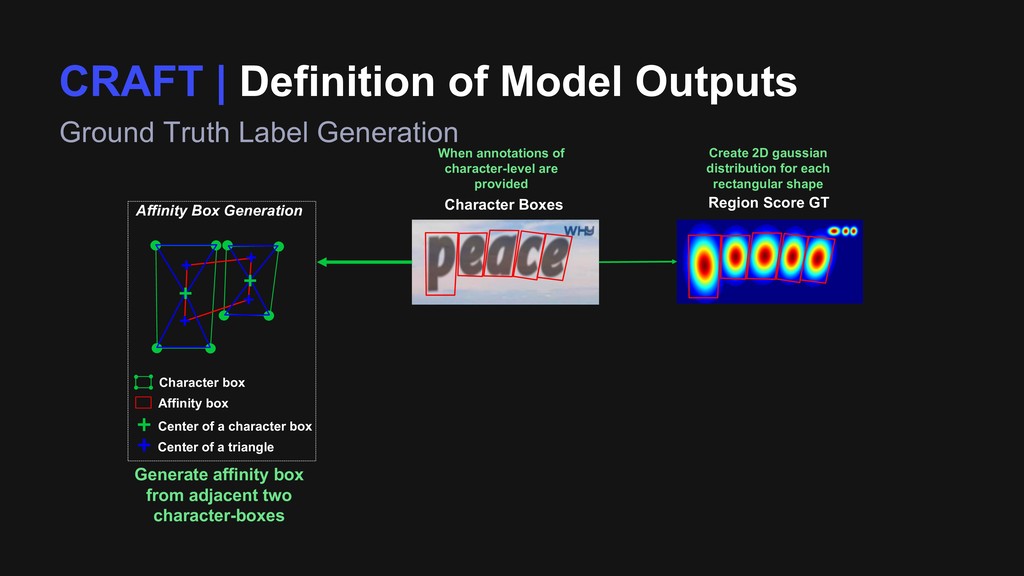
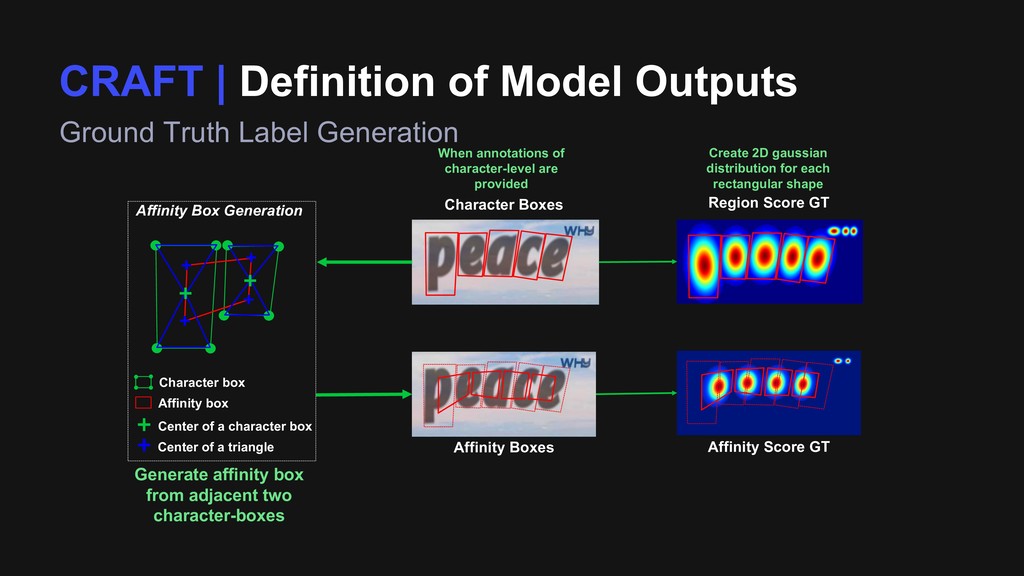
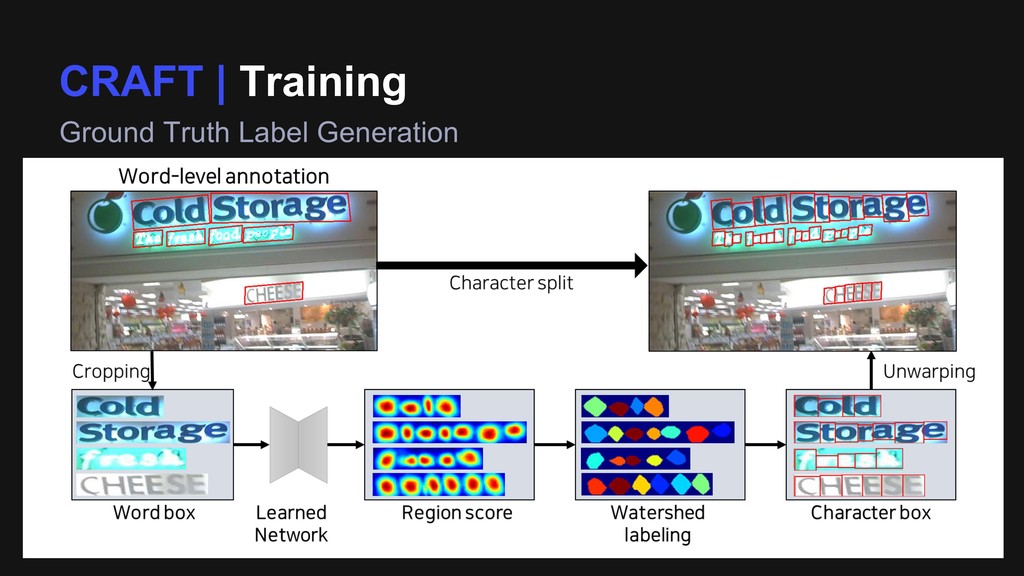
Region Score GT Character Boxes Affinity Box Generation Center of a character box Center of a triangle Character box Affinity box When annotations of character-level are provided Create 2D gaussian distribution for each rectangular shape Generate affinity box from adjacent two character-boxes
Region Score GT Character Boxes Affinity Box Generation Center of a character box Center of a triangle Character box Affinity box Affinity Score GT Affinity Boxes When annotations of character-level are provided Create 2D gaussian distribution for each rectangular shape Generate affinity box from adjacent two character-boxes
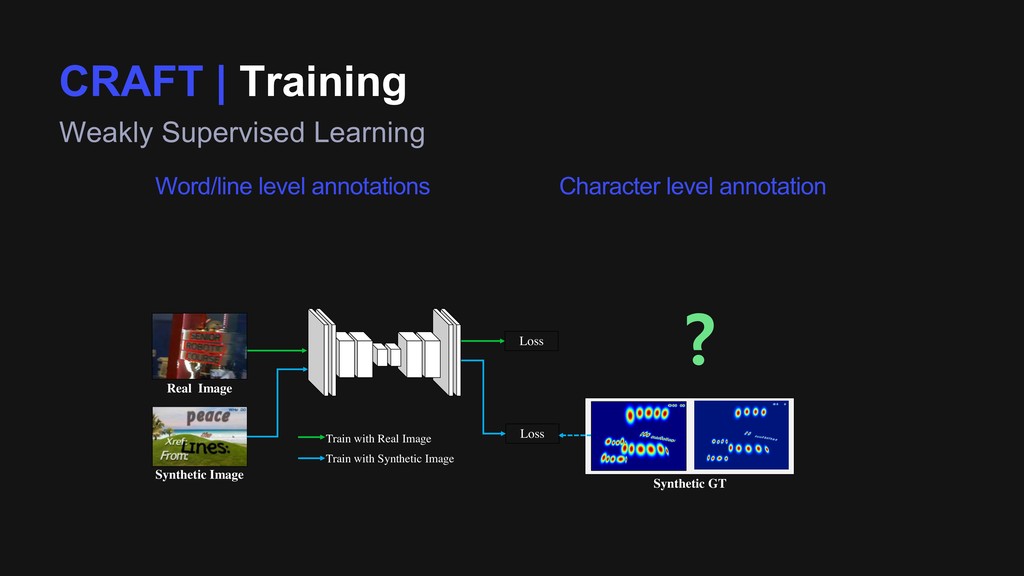
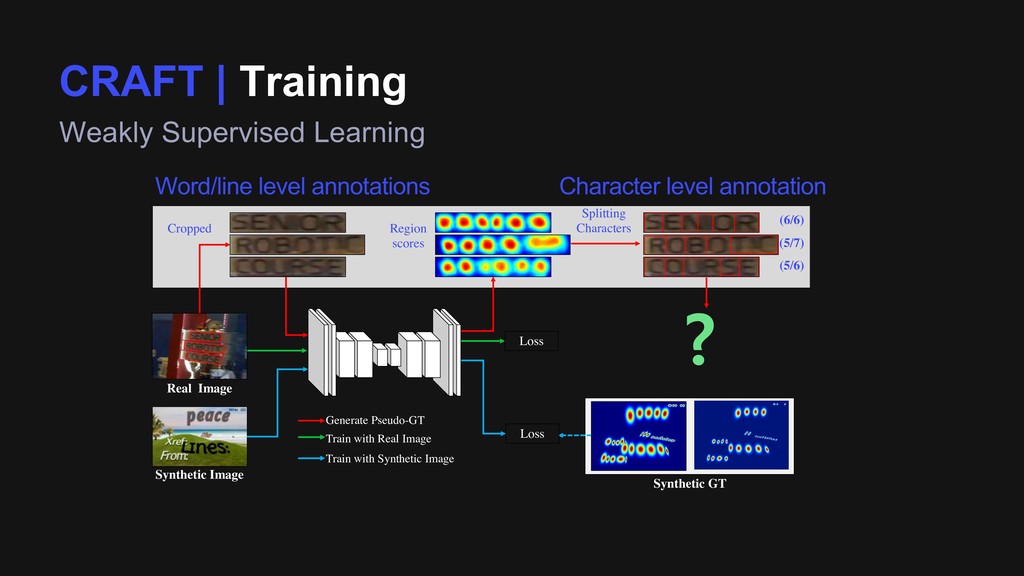
Cropped Splitting Characters Loss Loss Generate Pseudo-GT Train with Real Image Train with Synthetic Image (6/6) (5/7) (5/6) Synthetic GT Word/line level annotations Character level annotation ? Region scores
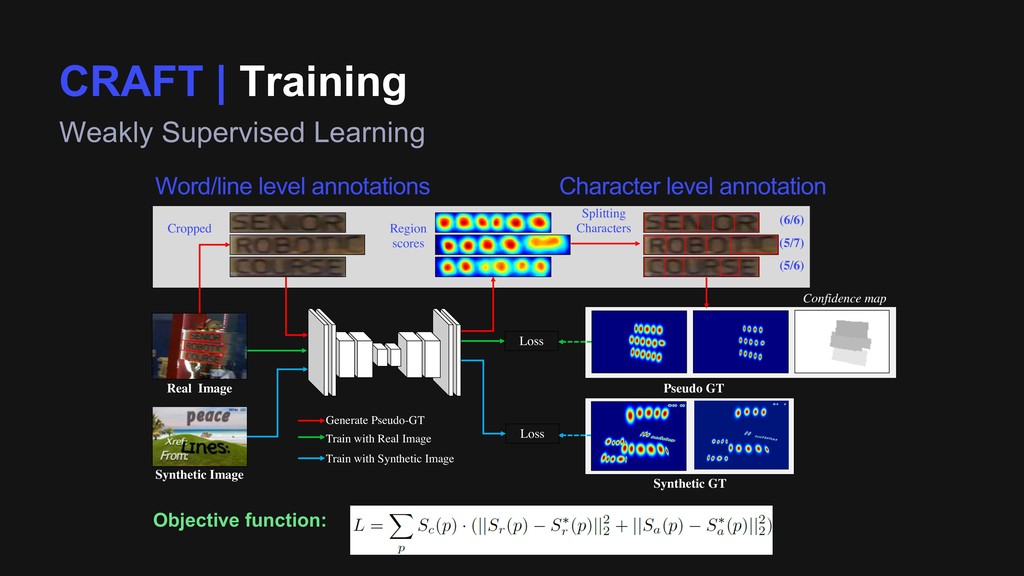
Cropped Splitting Characters Loss Loss Confidence map Generate Pseudo-GT Train with Real Image Train with Synthetic Image (6/6) (5/7) (5/6) Synthetic GT Pseudo GT Objective function: Word/line level annotations Character level annotation Region scores
{kind=link}
{kind=link}
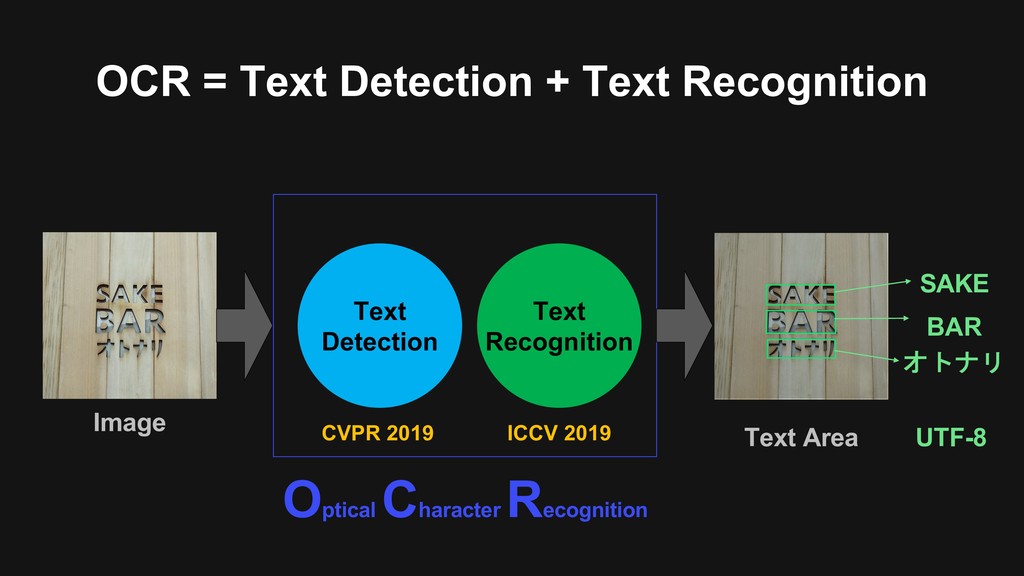{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
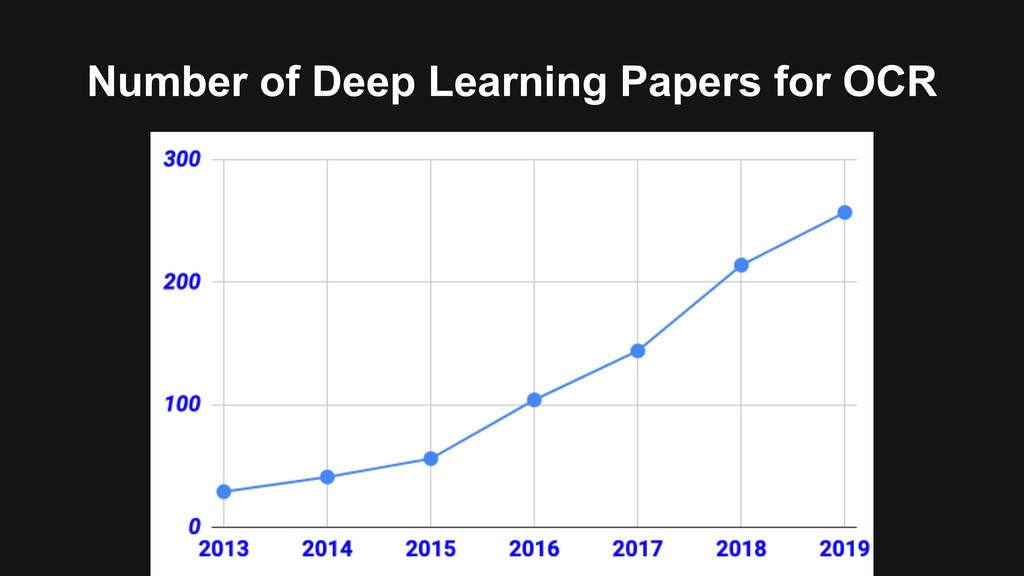{kind=link}
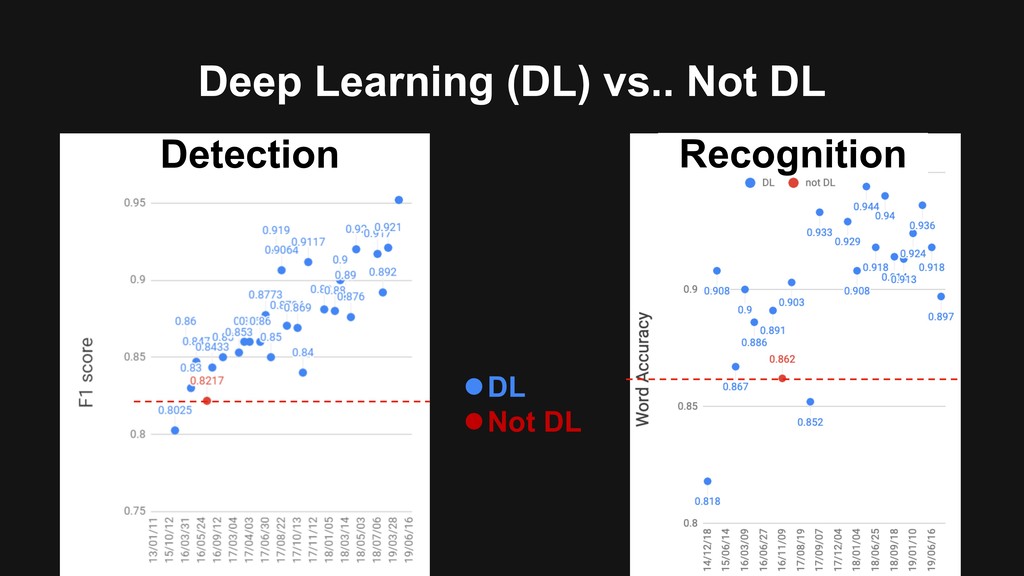{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
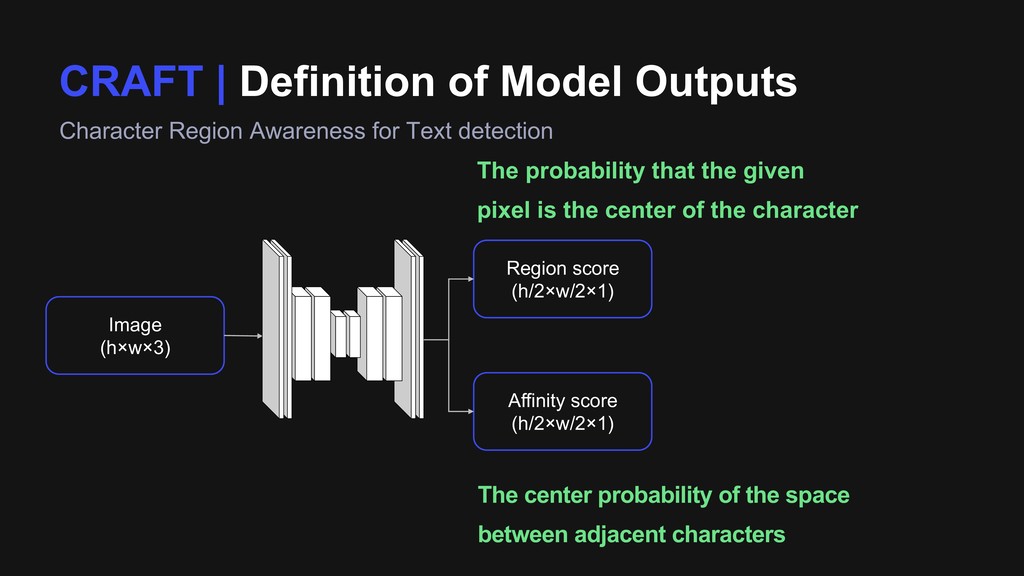{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}