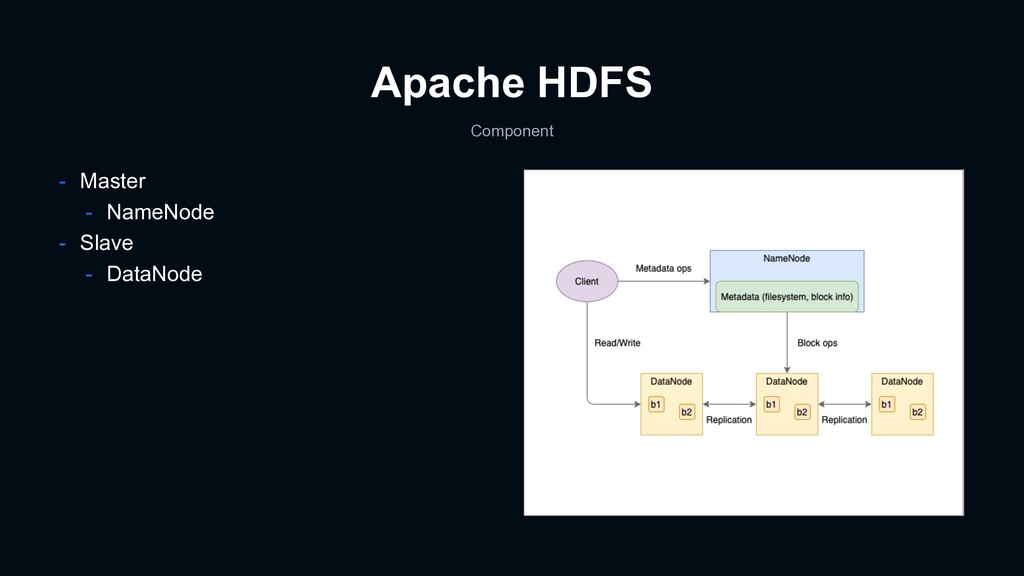
- Senior Software Engineer - Tech lead team member at Data Platform Dept. - Interests - Distributed systems - Formal methods - Apache Hadoop/Hive contributor
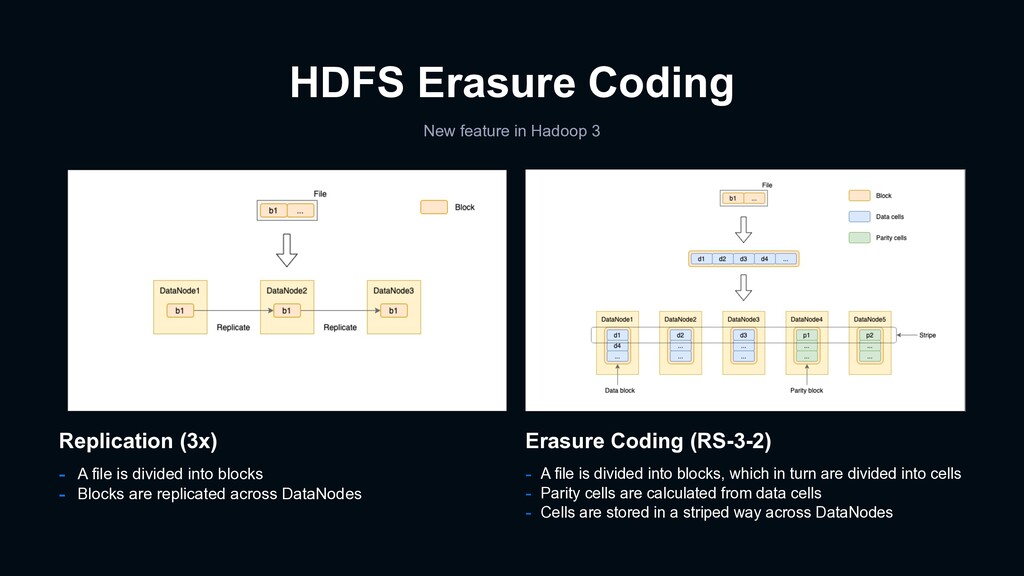
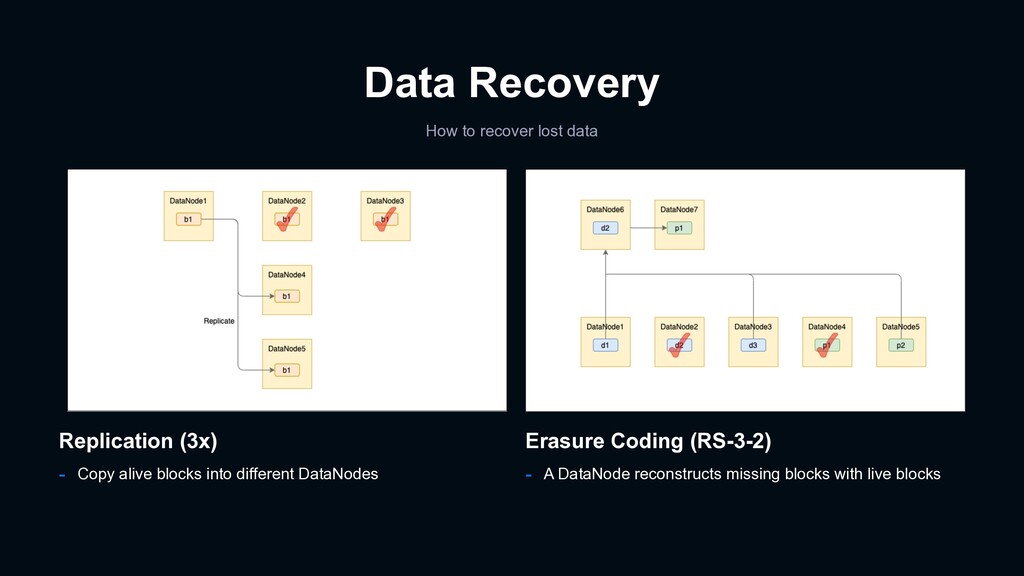
(RS-3-2) - A file is divided into blocks, which in turn are divided into cells - Parity cells are calculated from data cells - Cells are stored in a striped way across DataNodes Replication (3x) - A file is divided into blocks - Blocks are replicated across DataNodes
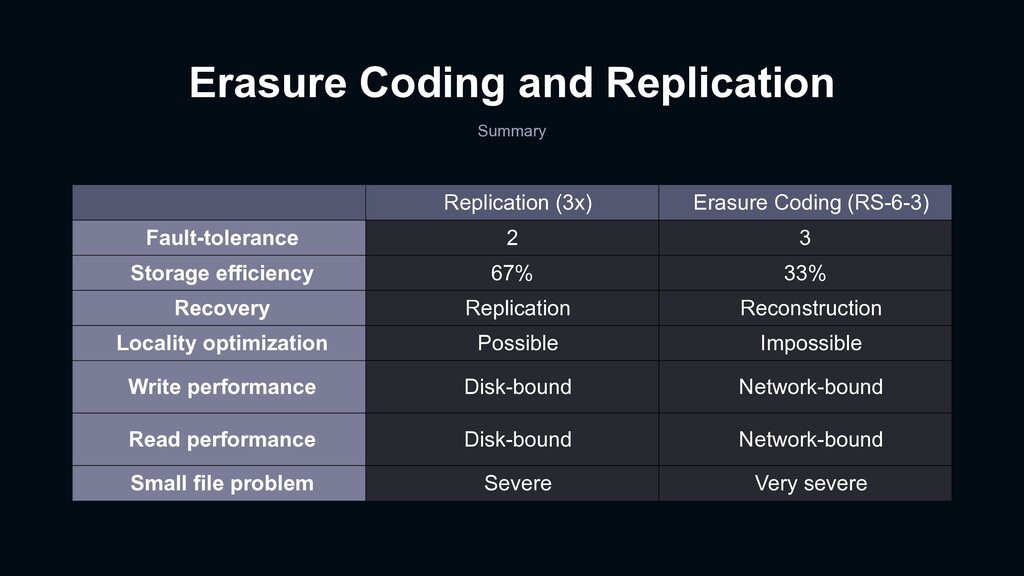
Fault-tolerance 2 3 Storage efficiency 67% 33% Recovery Replication Reconstruction Locality optimization Possible Impossible Write performance Disk-bound Network-bound Read performance Disk-bound Network-bound Small file problem Severe Very severe
not for hot data? - It is often hard to avoid small files for hot data - HDFS Erasure Coding is still immature - Merge small files at archiving to avoid the small file problem - 12 PB stored with RS-6-3 => 32 servers with 12 TB * 24 disks saved
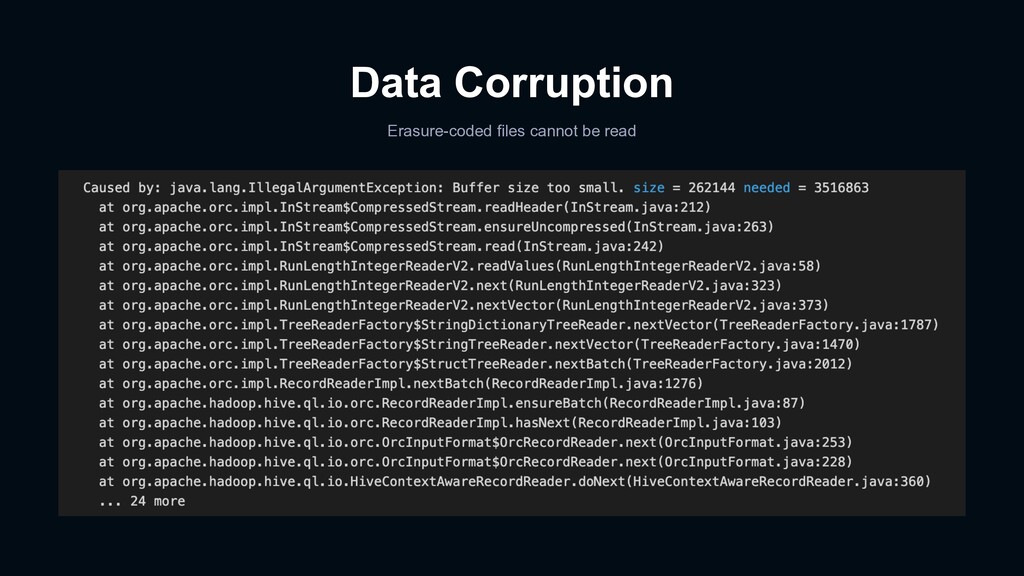
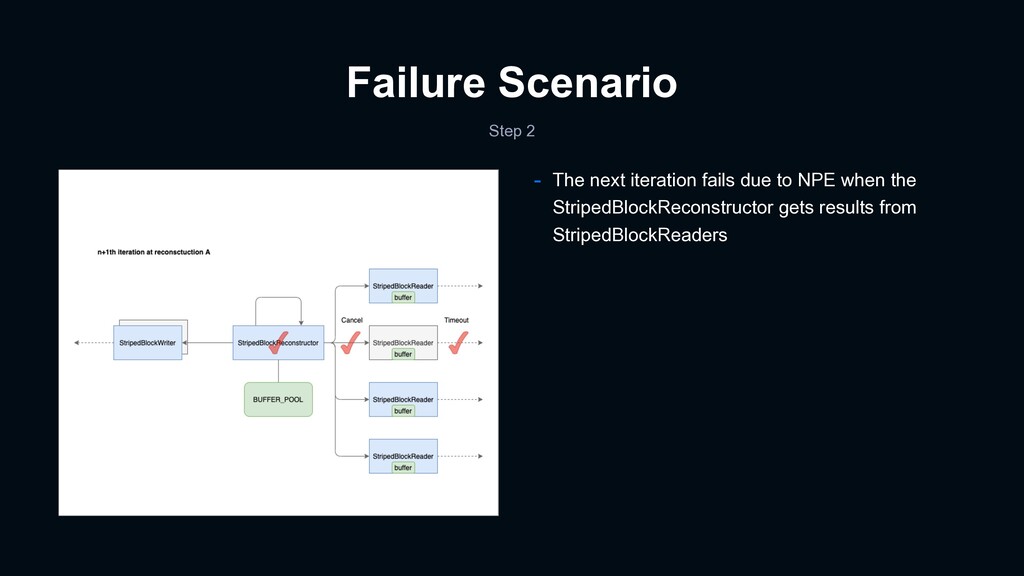
certain storage blocks were corrupted - Compared bit-wise between corrupted files and their original ones - Those corrupted blocks were reconstructed in the past - NullPointerException sometimes happened at StripedBlockReconstructor - It made reconstruction fail - Corruption rate: 0.005 % - Ran a Spark application to scan all erasure-coded files
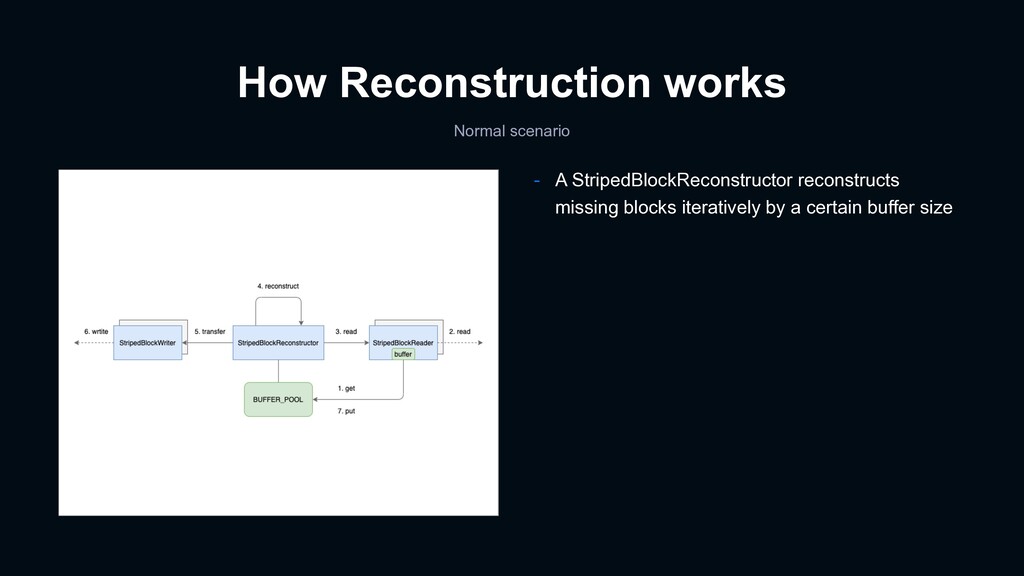
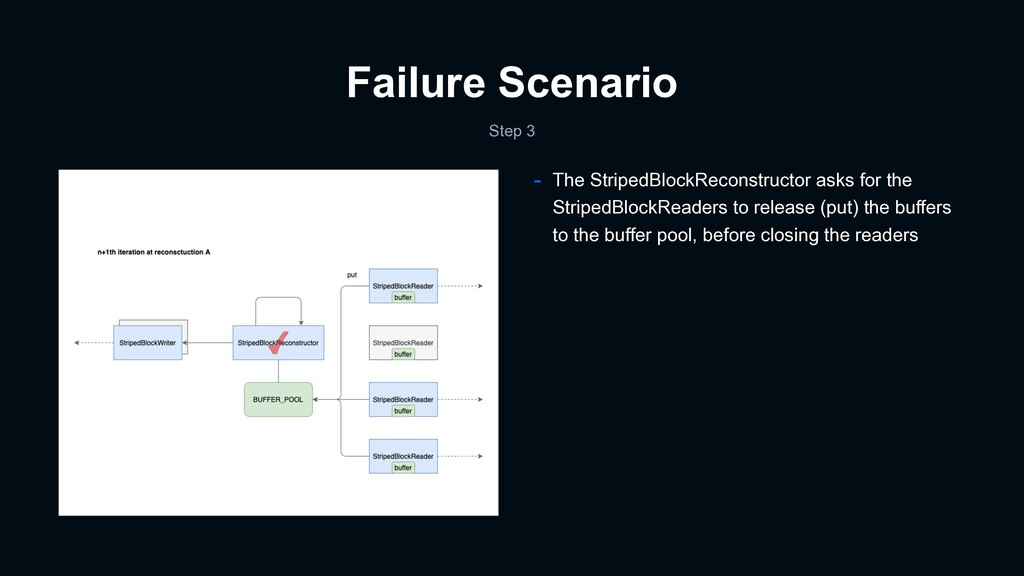
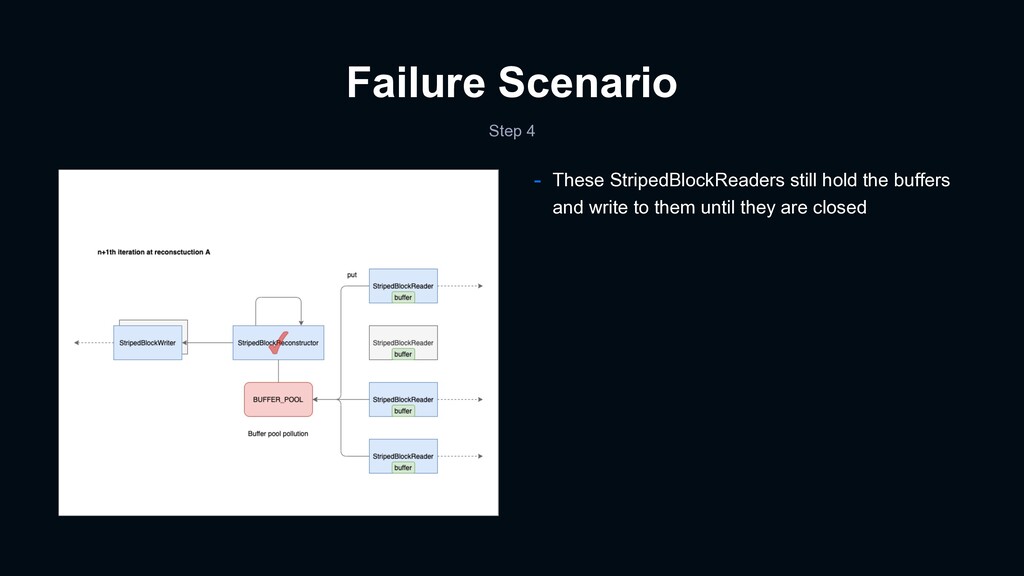
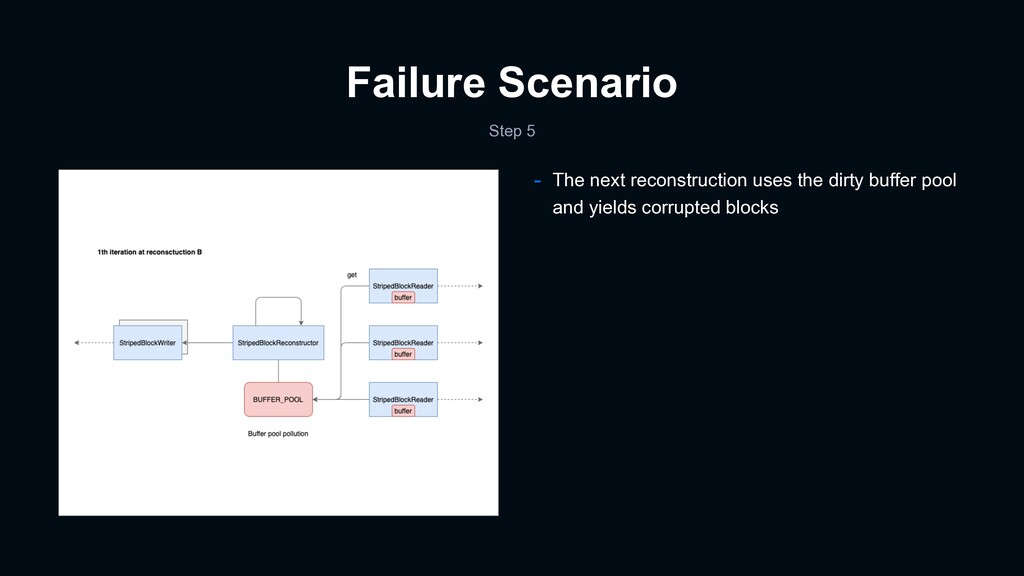
dirty buffer causes reconstruction block error - It was an open issue at the time of our troubleshooting - We helped with a unit test :) - Summary - StripedBlockReconstructor uses a buffer pool, defined as a static field, for reconstruction - The buffer pool will be polluted under a certain scenario - The next reconstruction with the dirty buffer pool yields corrupted blocks
it enough just to apply the patch? - No - Challenge - How to detect - How can we ensure that no data corruption occurs? - How to prevent - How can we prevent data corruption for the future?
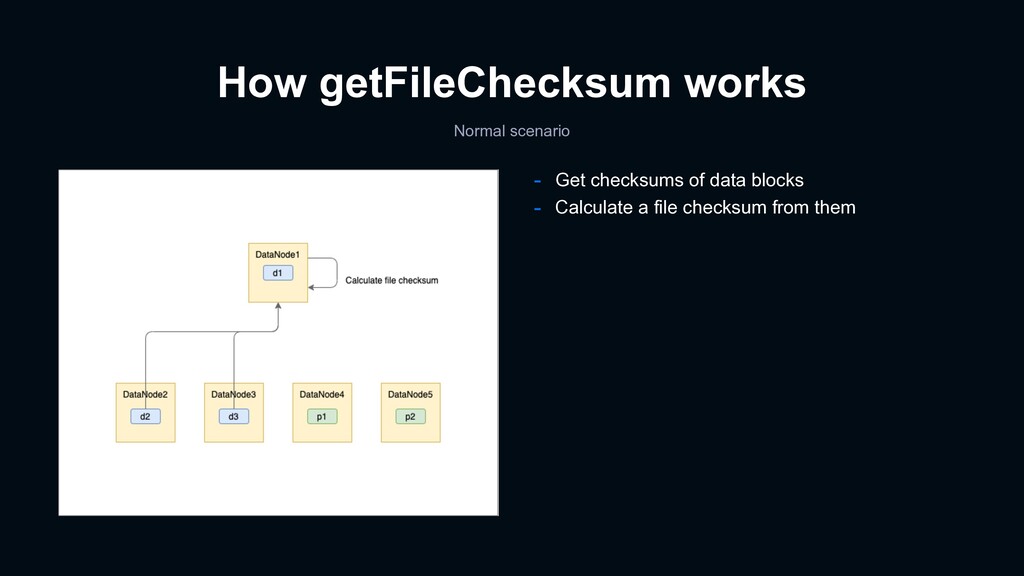
cannot recognize this kind of data corruption natively - Solution - Record file checksums of erasure-coded files daily with Spark - Contribution - HDFS-15709 EC: Socket file descriptor leak in StripedBlockChecksumReconstructor - HDFS-15795 EC: Wrong checksum when reconstruction was failed by exception
Problem - A new bug may cause data corruption again in the future - Solution - Verify correctness of reconstruction inside HDFS - Contribution - HDFS-15759 EC: Verify EC reconstruction correctness on DataNode - Set dfs.datanode.ec.reconstruction.validation=true - Monitor EcInvalidReconstructionTasks metric
applied, no data corruption has been observed by our monitoring system - However, - Recording checksums of all erasure-coded files periodically is costly and unfeasible - Our reconstruction validation does not provide 100% guarantee - To take one step further, - We need to record block checksums at streaming
of the time - It may still cause troubles on a large scale or under certain conditions - Recommendation - Keep upgrading to the latest maintenance version - Check HDFS JIRA issues with ec/erasure-coding Components regularly - Backup some of original data for troubleshooting - We will keep contributing to OSS communities
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}