Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
LINE GAME PLATFORM の中身を見てみよう / Let's see LINE G...
Search
LINE Developers
September 13, 2020
Technology
910
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
LINE GAME PLATFORM の中身を見てみよう / Let's see LINE GAME PLATFORM architecture
WOMAN TECH TERRACE 2020での発表資料です。
https://cyberagent.events/site/554169
LINE Developers
September 13, 2020
More Decks by LINE Developers
See All by LINE Developers
LINEスタンプのSREing事例集:大きなスパイクアクセスを捌くためのSREing
line_developers
3
2.5k
Java 21 Overview
line_developers
6
1.3k
Code Review Challenge: An example of a solution
line_developers
1
1.7k
KARTEのAPIサーバ化
line_developers
1
640
著作権とは何か?〜初歩的概念から権利利用法、侵害要件まで
line_developers
5
2.3k
生成AIと著作権 〜生成AIによって生じる著作権関連の課題と対処
line_developers
3
2.5k
マイクロサービスにおけるBFFアーキテクチャでのモジュラモノリスの導入
line_developers
9
4k
A/B Testing at LINE NEWS
line_developers
3
1.2k
LINEのサポートバージョンの考え方
line_developers
2
1.6k
Other Decks in Technology
See All in Technology
ダッシュボード"開発"について 〜使われるダッシュボードのつくりかた〜
kimichan
0
240
Escolhendo LLMs na Prática: Lições Reais em Busca Agêntica no Mercado Livre —TDC 2026 Floripa
jpbonson
0
100
全社でのソフトウェアサプライチェーン攻撃対策をやってみた with Takumi Guard
z63d
0
330
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
AI研修(Day1)【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
2.7k
現場で使える AWS DevOps Agent 活用ノウハウ - Release Management 機能の検証結果を添えて / AWS DevOps Agent Release Management and Know-How
kinunori
4
760
Amazon Bedrock Managed Knowledge Base Dive Deep
ren8k
0
250
AI時代におけるテストの基礎の再定義 / Rethinking the Fundamentals of Testing in the AI Era
mineo_matsuya
15
6.2k
人依存からAIネイティブの体制へ:バックエンド開発の裏側【SORACOM Discovery 2026】
soracom
PRO
0
130
ウォーターフォール開発案件のPMとしてAI活用を模索している話
hatahata021
2
200
AIがAPIを書く時代に、私たちは何を設計すべきか
nagix
0
160
BigQuery を検索ソースとした AI Agent の作り方って 〇〇 通りあんねん
satohjohn
0
140
Featured
See All Featured
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
64
56k
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
240
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
HDC tutorial
michielstock
2
760
Templates, Plugins, & Blocks: Oh My! Creating the theme that thinks of everything
marktimemedia
31
2.8k
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.2k
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
3
370
Scaling GitHub
holman
464
140k
Navigating Team Friction
lara
192
16k
Claude Code どこまでも/ Claude Code Everywhere
nwiizo
65
57k
Transcript
LINE GAME PLATFORM の中⾝を⾒てみよう LINE株式会社 ゲームプラットフォーム開発室 @aira813 2020.09.13
登壇者紹介 @aira813 サーバーサイドエンジニア 2011: (株)サイバーエージェント新卒⼊社 Amebaマイページ、認証 2016: LINE(株)⼊社 ゲームプラットフォーム 好きなもの
⼤量のアクセス ⼤量のデータ ⼤事なデータ 得意なもの 0を1にする 1を10にする 10を10にする この辺
LINE GAMEの開発者向けプラットフォーム LINE GAME PLATFORMって︖ ※出典︓https://gdc.game.line.me/games/ ※個⼈向けには提供しておりません
今⽇話すこと • 主にIn-Game向けAPI周りの話 • プロフィール • ランキング • フレンド •
フォロー • ギルド • チャット • 運⽤開発フェーズのエンジニア視点で何を普段やっているの か (よく聞かれますがLINE本体の話は詳しくありません)
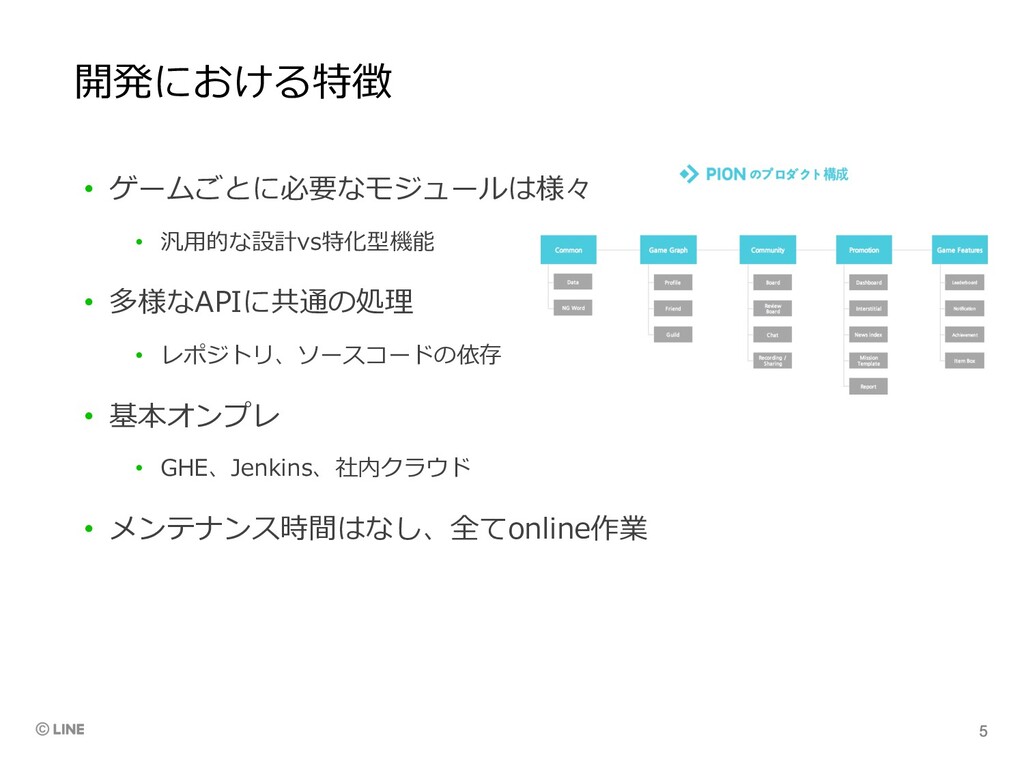
開発における特徴 • ゲームごとに必要なモジュールは様々 • 汎⽤的な設計vs特化型機能 • 多様なAPIに共通の処理 • レポジトリ、ソースコードの依存 •
基本オンプレ • GHE、Jenkins、社内クラウド • メンテナンス時間はなし、全てonline作業
ALPHA 開発⽤ 多い 環境は5フェーズ BETA 開発QA⽤ SANDBOX ゲーム開発⽤ STAGING ゲームQA⽤
RELEASE 本番
アーキテクチャについて
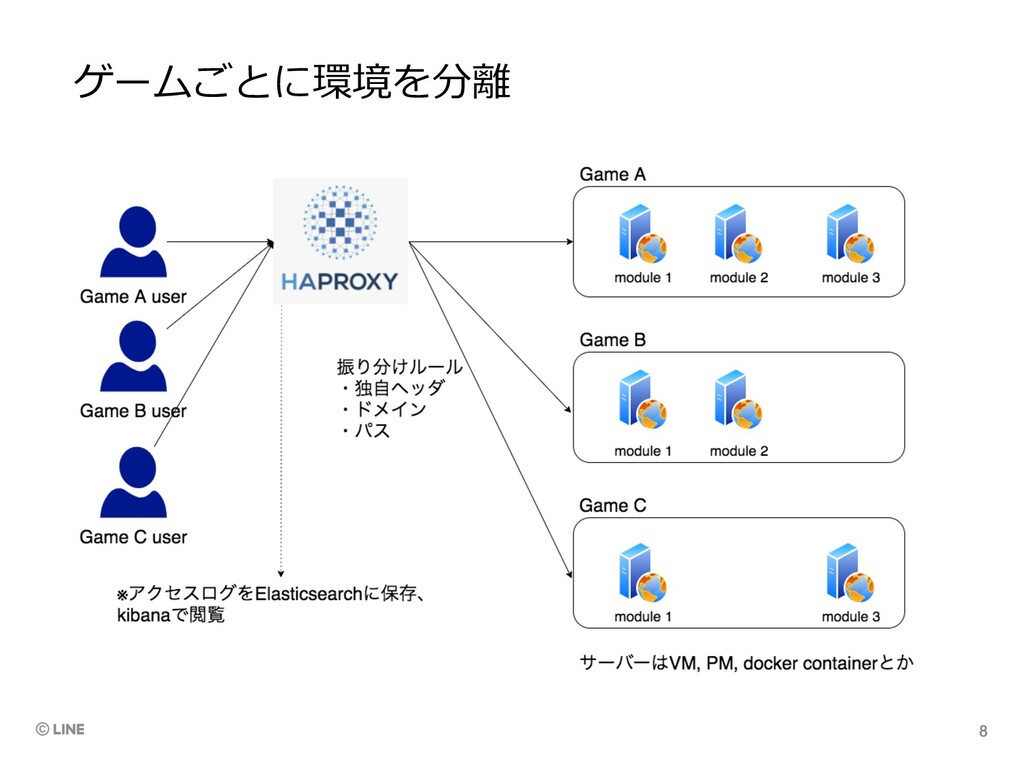
ゲームごとに環境を分離
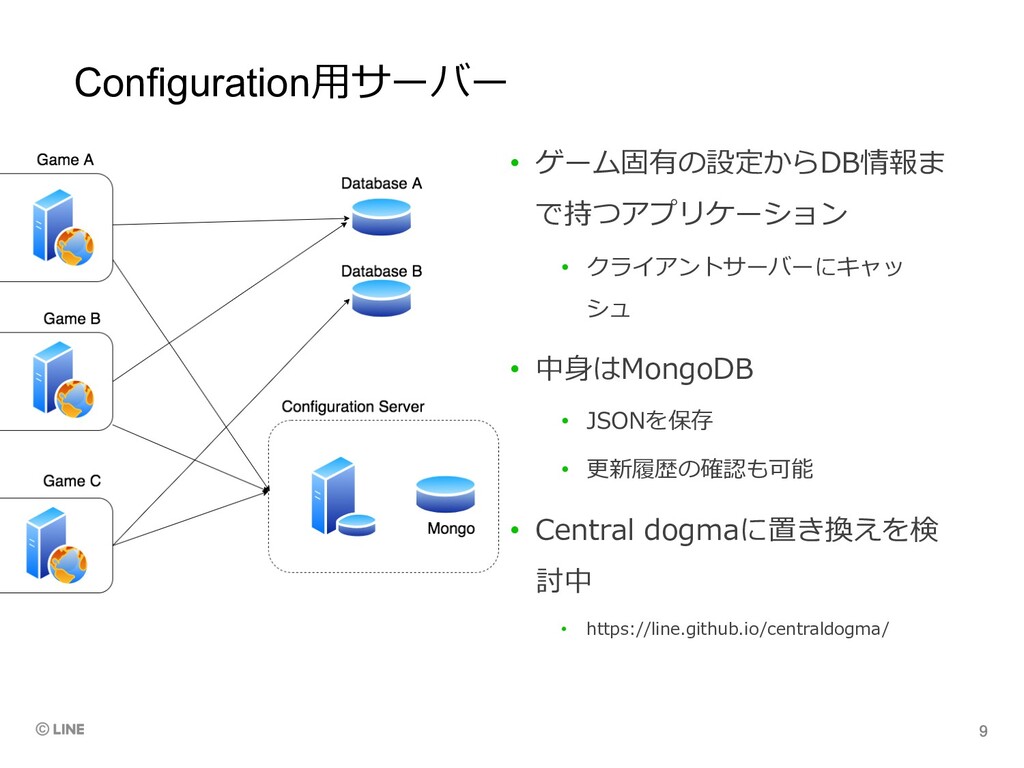
Configuration⽤サーバー • ゲーム固有の設定からDB情報ま で持つアプリケーション • クライアントサーバーにキャッ シュ • 中⾝はMongoDB •
JSONを保存 • 更新履歴の確認も可能 • Central dogmaに置き換えを検 討中 • https://line.github.io/centraldogma/
モジュールサーバー周り • サービス⽤データはHBase+Redis cluster • ログ⽤にHadoopやElasticsearchに⾮同期で保存 • キューはApache Kafka •
Redis Streamsに置き換え検討中(ミドルウェア減らしたい…) • 検索はElasticsearch • ゲームごと(さらに⽇付ごと)にindexをわける
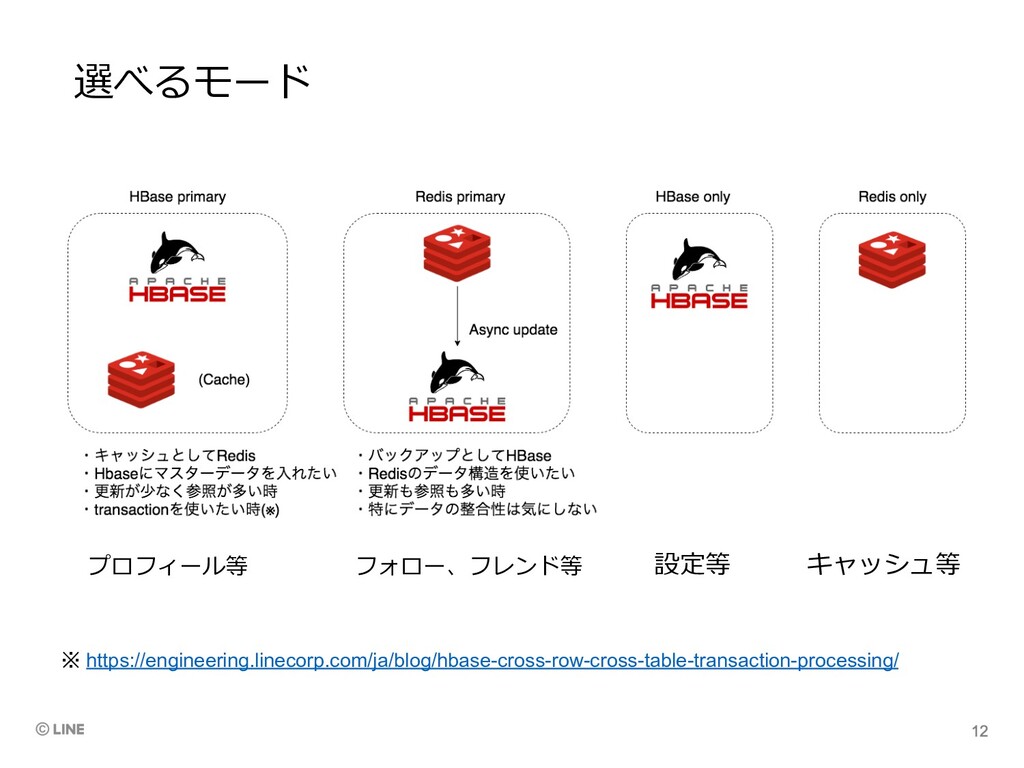
HBase+Redis clusterをまとめた”AEGIS” • マスターデータ⽤のDB(=HBase)とキャッシュ⽤のDB(=Red is cluster)をまとめて処理できる独⾃ライブラリ • データに合わせてモード(※次ページ)を選択
選べるモード プロフィール等 フォロー、フレンド等 設定等 キャッシュ等 ※ https://engineering.linecorp.com/ja/blog/hbase-cross-row-cross-table-transaction-processing/
実装例(プロフィール) • 1key 1data • JSON形式で保存、schemaはゲーム管理者が⾃由に決められ る • 1レコードあたりのデータ量が定まらない •
1ゲームあたりのデータ量も定まらない • HBaseはRowkeyでソートされてregionという単位に分けら れてデータが格納される
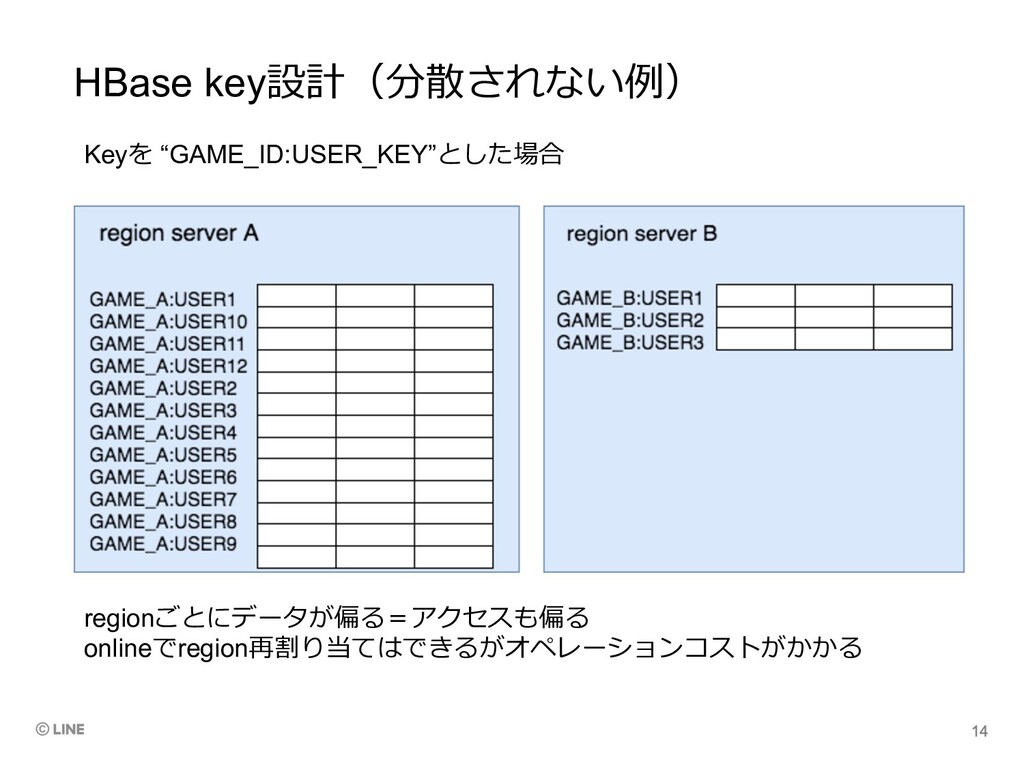
HBase key設計(分散されない例) Keyを “GAME_ID:USER_KEY”とした場合 regionごとにデータが偏る=アクセスも偏る onlineでregion再割り当てはできるがオペレーションコストがかかる
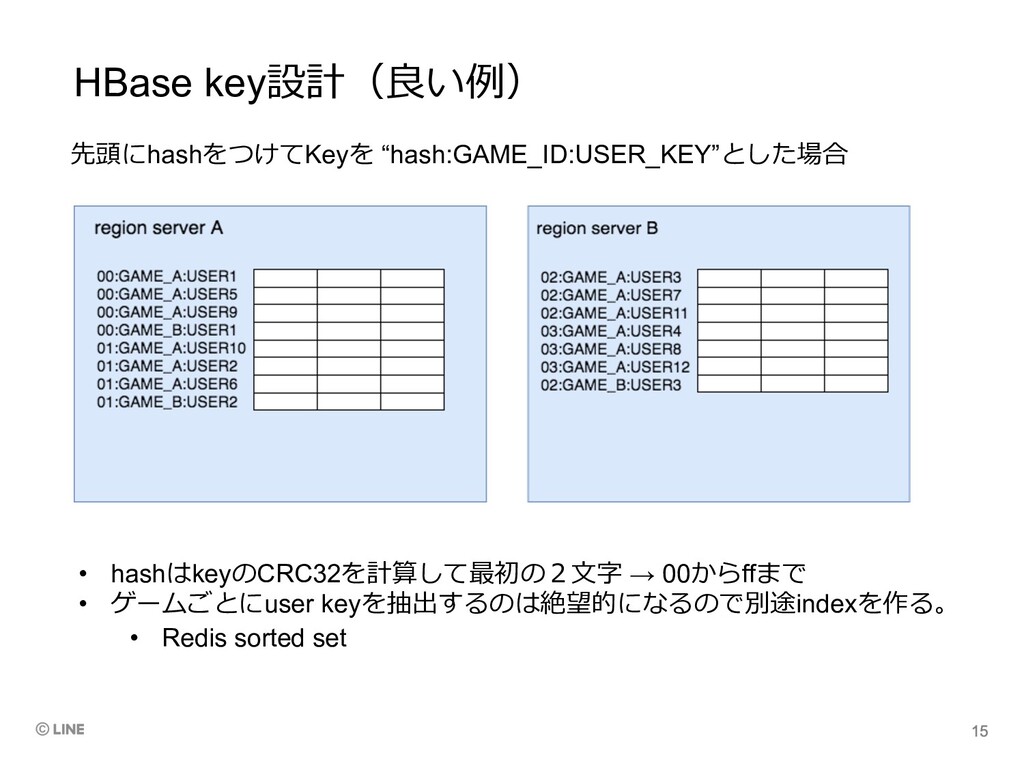
HBase key設計(良い例) 先頭にhashをつけてKeyを “hash:GAME_ID:USER_KEY”とした場合 • hashはkeyのCRC32を計算して最初の2⽂字 → 00からffまで • ゲームごとにuser
keyを抽出するのは絶望的になるので別途indexを作る。 • Redis sorted set
各ゲームに対して⽤意する環境① • モジュールサーバー • ゲーム側で必要なものを選んで初期化→サーバーが⽤意される • ただし、VM,PMの場合は共通のものを使⽤ • その他はdocker containerを起動
専⽤の環境が⽤意される
各ゲームに対して⽤意する環境② • Redis cluster • 使われ⽅によってデータ量/アクセスの⼤⼩があるので、ゲーム専⽤に⽤ 意することもある • configuration serverで切り替え
場合によっては新しい環境が⽤意される
各ゲームに対して⽤意する環境③ • HBase • key設計とキャッシュさえうまくいっていれば特定のゲームに対して負 荷が増加してても他のゲームに影響することがほぼない • クラスター管理のコストが⾼い • Elasticsearch
• 現状そこまで負荷は⾼くない • Kafka • キューという特性上、⾮同期処理のためすぐにサービス影響が出ること が少ない 既存のものを使う
よく直⾯する問題
移設(Hbase、Redis) • バージョンアップ、スケールダウンetc... • 単純なRedis double writeはConfigurationサーバー+Aegis ですぐに開始できる • テーブル設計変えるならUserごとに移⾏ステータスを管理す
る必要がある • id1は未移⾏︖ • id1を新しいDBにコピー • 古いデータと新しいデータを⽐較 • id1の移⾏ステータスを更新 • 古いデータと新しいデータを⽐較...
ゲームに設置したモジュールのバージョンが古い • ゲームが必要な時のみモジュールアプリを更新できる • ということは • 必要ない限り更新しないので、久々に更新して挙動が変わっ ていることに気づく • QAチームと密に連携すること
• 前のバージョンのcontainerにすぐ切り替えられる
Redisはシングルスレッド • キャッシュ⽤途とデータストア⽤途として同時に使っている ので気を使わなければならない • うっかり重いクエリを投げると⽌まる • データが⼤きくなると重くなる型がいくつかある • 公式のドキュメントの計算量を確認すること
• 特にHash mapは順番に取ることができないので、うっかり ⼤きいキーに対して操作しがち
低使⽤率APIの把握 • 定期的にHAProxyのログを取得してSwaggerと突き合わせて 低使⽤率APIを抽出 • 使わないシステムの運⽤コスト > 必要になった時に新しく作るコスト • 捨てる勇気
※ JSONを使⽤して表現されたRESTful APIを記述するためのインターフェース 記述⾔語。
テスト⽤ページを忘れる • CI/CDは当然導⼊ • DeployしたらURL付きでslackに通知
まとめ • いかに既存のサービス影響を最⼩限に開発するか、が最重要 ポイント • 多すぎると把握もできなくなってくるので忘れないためのシ ステム作りも⼤事
THANK YOU
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}