Review and New Perspectives," in IEEE TPAMI., vol. 35, no. 8, pp. 1798-1828, Aug. 2013. [Johnson 2016] M. Johnson et al., “Composing graphical models with neural networks for structured representations and fast inference”, NeurIPS, 2016. [Common 1994] P. Common, “Independent component analysis, a new concept?,” Signal Processing, vol. 36, no. 3, pp. 287–314, April 1994. [Duong 2010] N.Q.K. Duong, et al., “Underdetermined reverberant audio source separation using a fullrank spatial covariance model,” IEEE TASLP., vol. 18, no. 7, pp. 1830–1840, 2010. [Kim 2006] T. Kim, et al., “Independent vector analysis: an extension of ica to multivariate components,” in Proceedings ICA, pp. 165–172, Mar. 2006. [Hiroe 2006] A. Hiroe, “Solution of permutation problem in frequency domain ica using multivariate probability density functions,” in Proceedings ICA, pp. 601–608, Mar. 2006. [Kitamura 2016] D. Kitamura, et al., "Determined blind source separation unifying independent vector analysis and nonnegativematrix factorization," IEEE/ACM TASLP., vol. 24, no. 9, pp. 1626-1641, 2016. [Nugraha 2016] A.A. Nugraha, et al., “Multichannel audio source separation with deep neural networks,” IEEE/ACM TASLP., vol. 24, no. 9, pp. 1652–1664, 2016. [Mogami 2018] S. Mogami, et al., “Independent deeply learned matrix analysis for multichannel audio source separation,” in EUSIPCO, pp. 1557–1561, Sep. 2018. [Kameoka 2018] H. Kameoka, et al., "Semi-blind source separation with multichannel variational autoencoder," arXiv:1808.00892, Aug. 2018. [Heymann 2016] J. Heymann, et al., “Neural network based spectral mask estimation for acoustic beamforming,” in ICASSP, 2016, pp. 196–200. [Hershey 2016] J.R. Hershey, et al., “Deep clustering: Discriminative embeddings for segmentation and separation,” in ICASSP, 2016, pp. 31–35. [Kolbæk 2017] M. Kolbæk, et al., “Multitalker speech separation with utterance-level permutation invariant training of deep recurrent neural networks,” IEEE/ACM TASLP., vol. 25, pp. 1901–1913, 2017. [Togami ICASSP2019_1] M. Togami, “Multi-channel Itakura Saito Distance Minimization with deep neural network,” in ICASSP, 2019, pp. 536-540. [Togami ICASSP2019_2] M. Togami, “Spatial Constraint on Multi-channel Deep Clustering,” in ICASSP, 2019, pp. 531-535. [Togami ICASSP2019_3] M. Togami, “Simultaneous Optimization of Forgetting Factor and Time-frequency Mask for Block Online Multi-channel Speech Enhancement,” in ICASSP, 2019, pp. 2702-2706. [Nakagome 2019] Y. Nakagome, “Adaptive beamformer for desired source extraction with neural network based direction of arrival estimation,” in IEICE Technical Report, vol. 118, no. 497, SP2018-85 , pp. 143-147 (in Japanese), Mar. 2019. [Masuyama Interspeech2019] Y. Masuyama, et al., “Multichannel Loss Function for Supervised Speech Source Separation by Mask-based Beamforming,” in Interspeech, Sep. 2019 (Accepted). [Togami 2005] M. Togami et al., “Adaptation methodology for minimum variance beam-former based on frequency segregation,” in Proc. of the 2005 Autumn Meeting of the Acoustical Society of Japan (in Japanese), Sep. 2005. [Lukas 2019] L. Drude, et al., "Unsupervised Training of a Deep Clustering Model for Multichannel Blind Source Separation," in ICASSP, 2019, pp. 695-699.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
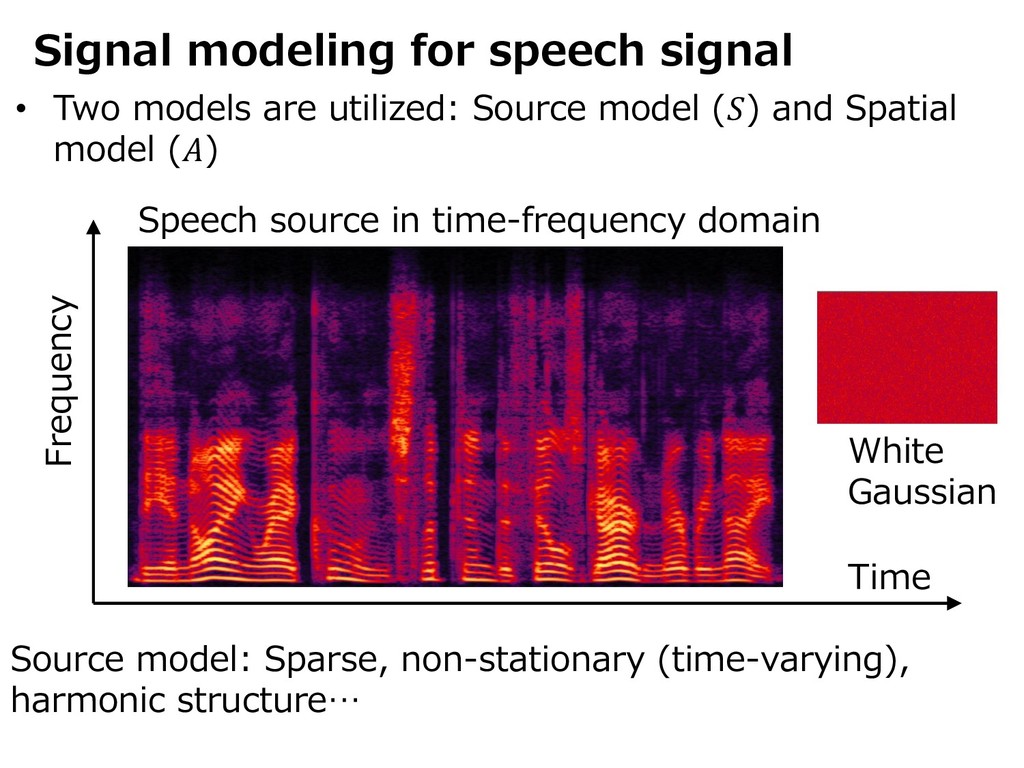{kind=link}
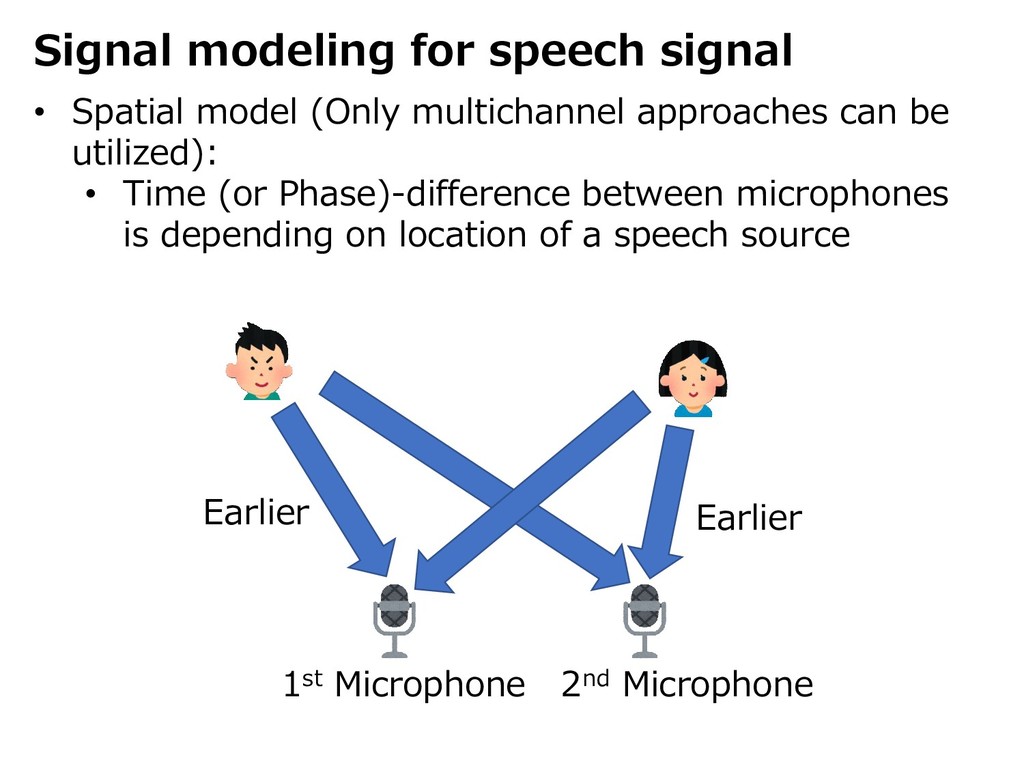{kind=link}
{kind=link}
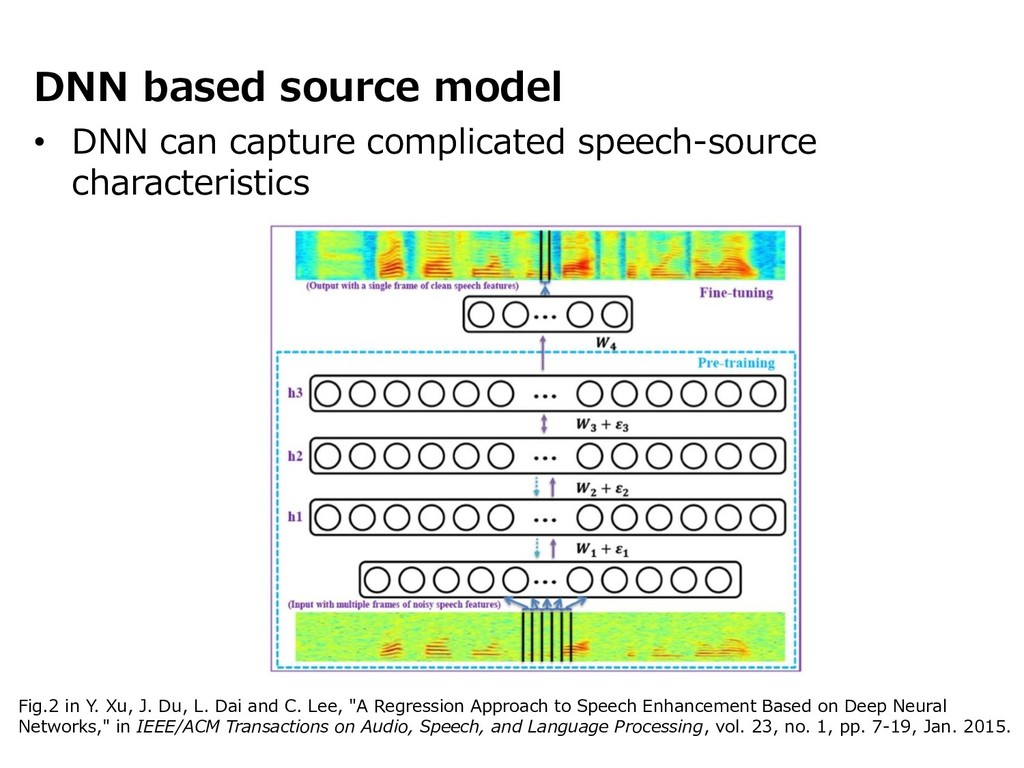{kind=link}
{kind=link}
{kind=link}
{kind=link}
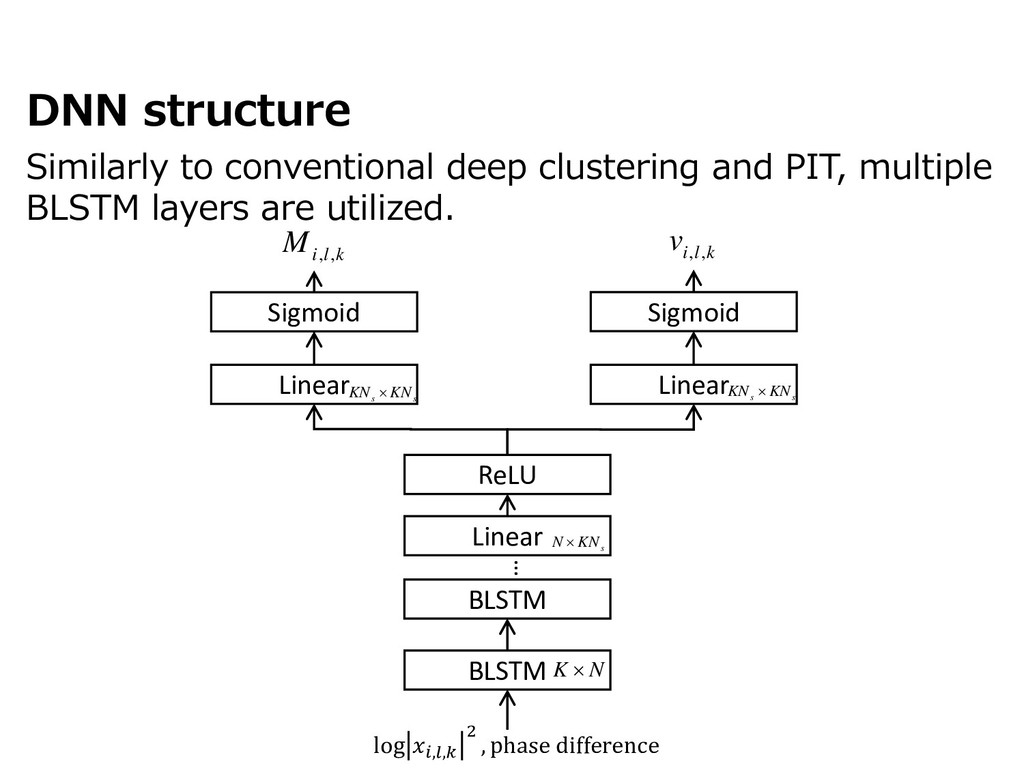{kind=link}
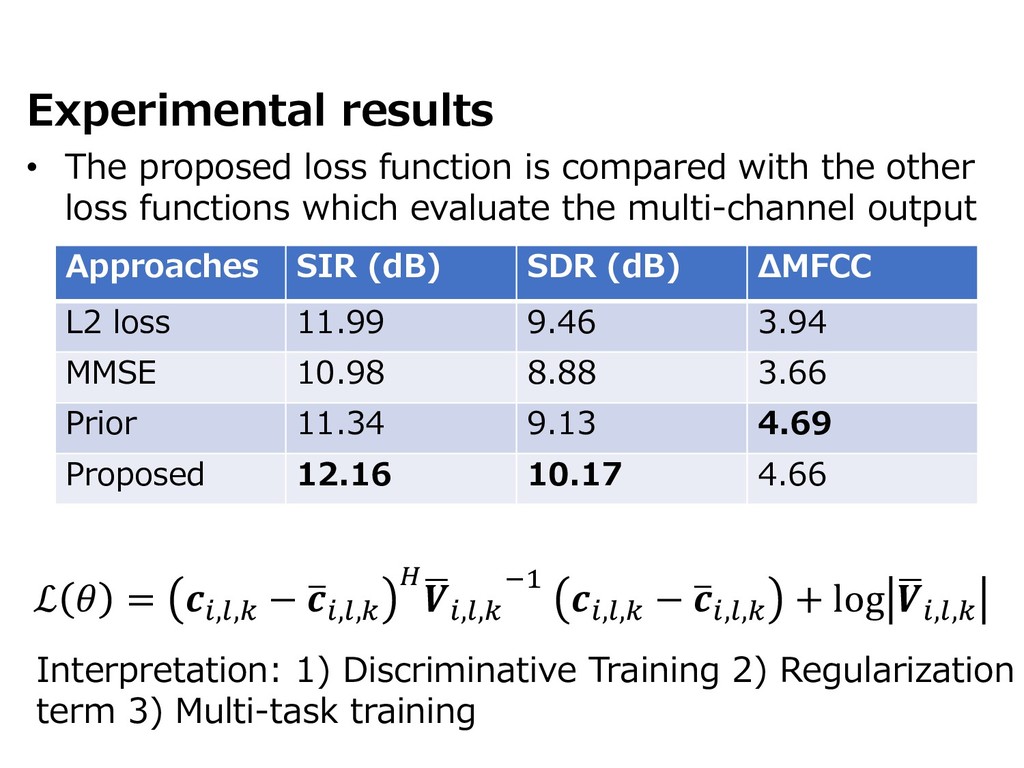{kind=link}
![Experimental results for time-invariant beamformer [Masuyama Interspeech2019] • Only time-frequency](https://files.speakerdeck.com/presentations/f0a9d14cde524c57b66eb01945cd3acd/slide_17.jpg){kind=link}
![Insertion of MWF between BLSTM layers [Togami ICASSP2019_2] • Roughly](https://files.speakerdeck.com/presentations/f0a9d14cde524c57b66eb01945cd3acd/slide_18.jpg){kind=link}
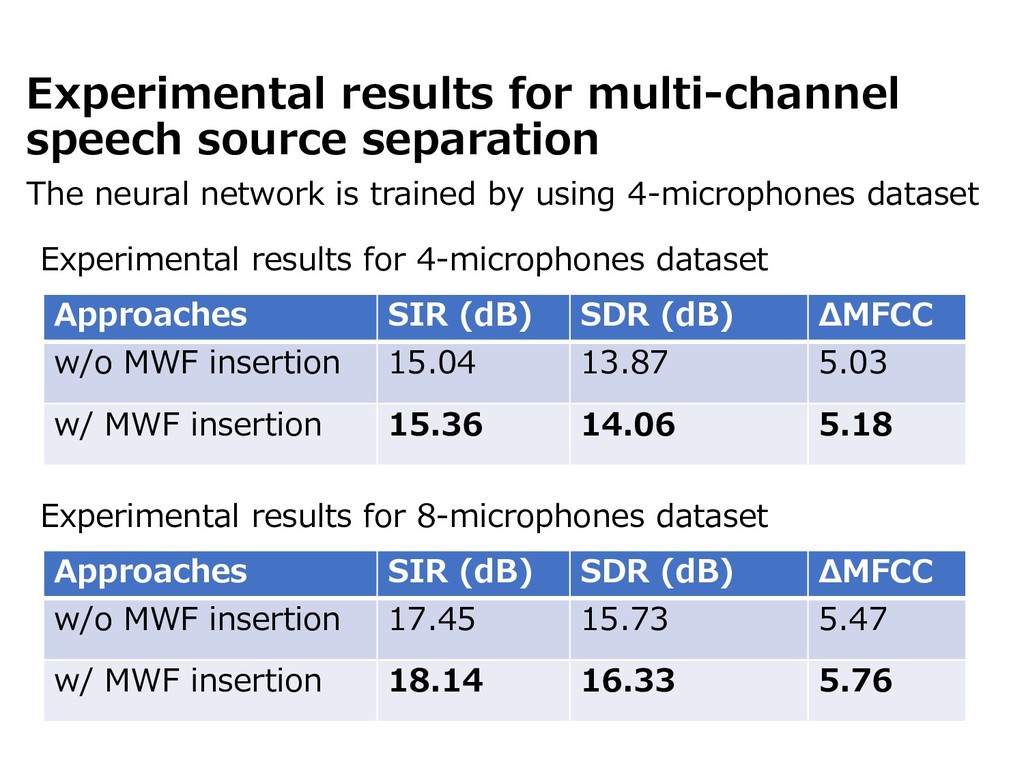{kind=link}
{kind=link}
{kind=link}
![References [Bengio 2013] Y. Bengio, et al., "Representation Learning: A](https://files.speakerdeck.com/presentations/f0a9d14cde524c57b66eb01945cd3acd/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}