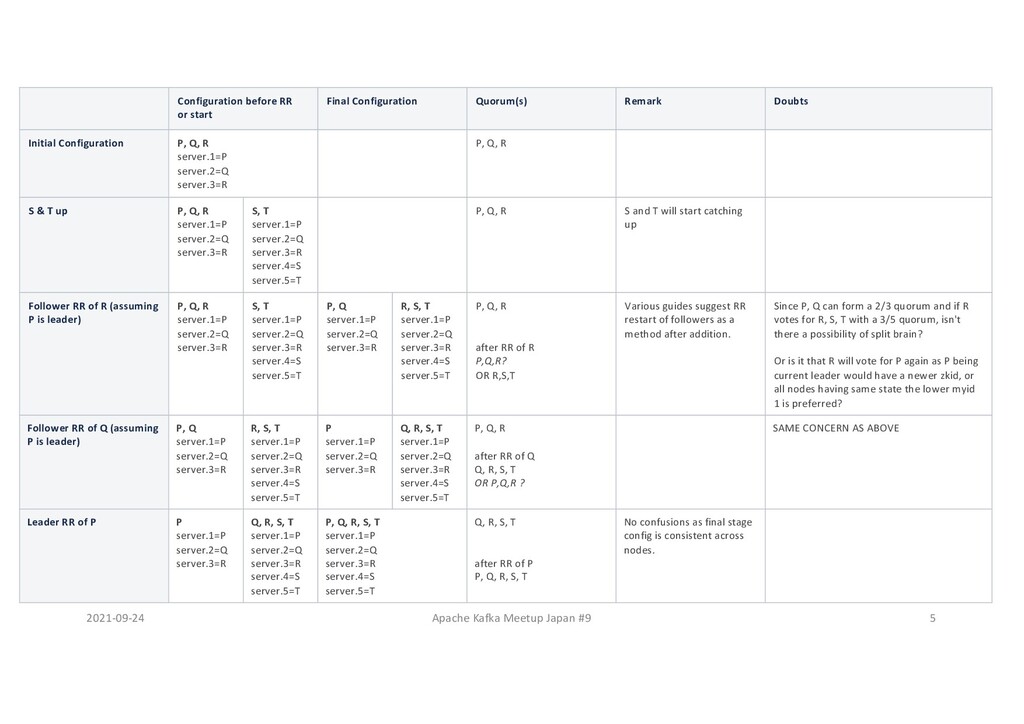
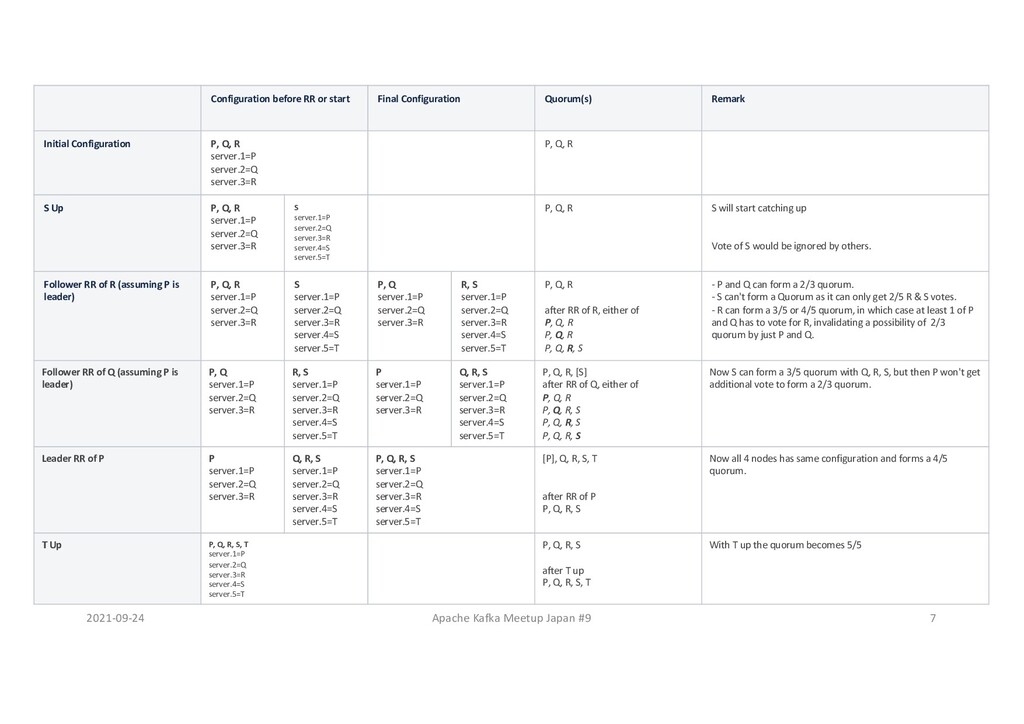
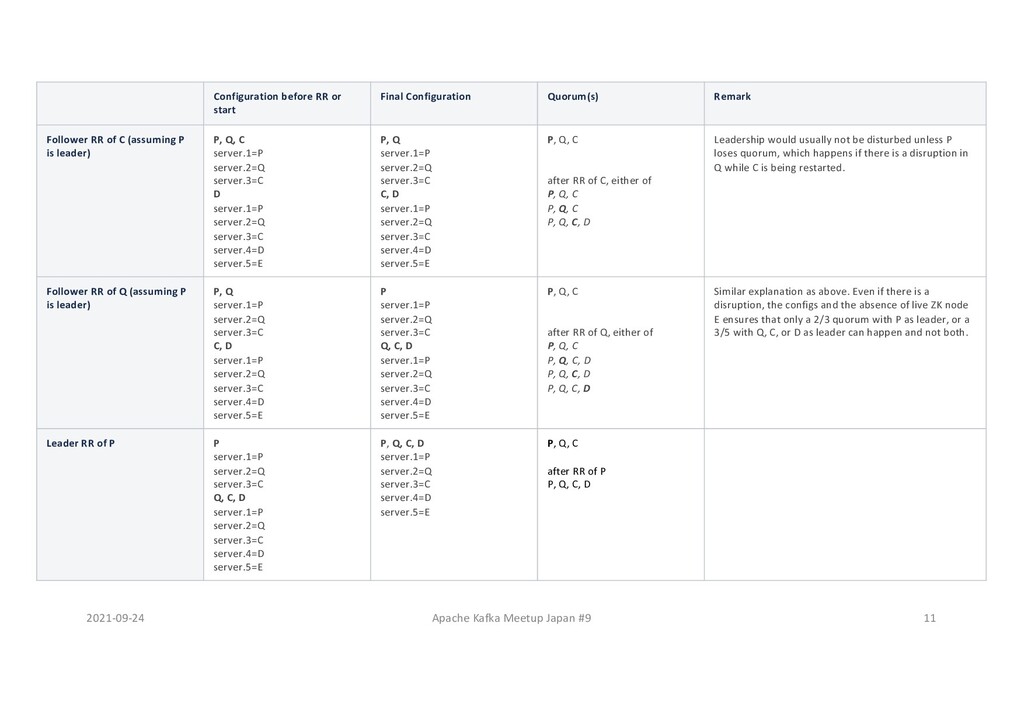
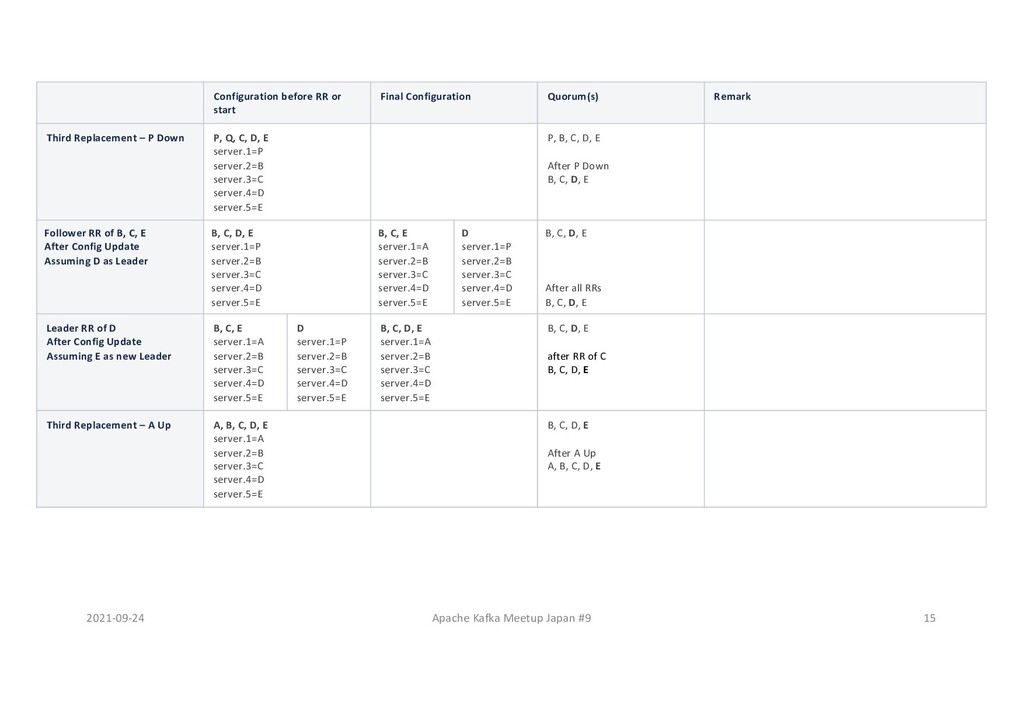
or start Final Configuration Quorum(s) Remark Initial Configuration P, Q, R server.1=P server.2=Q server.3=R P, Q, R S Up P, Q, R server.1=P server.2=Q server.3=R S server.1=P server.2=Q server.3=R server.4=S server.5=T P, Q, R S will start catching up Vote of S would be ignored by others. Follower RR of R (assuming P is leader) P, Q, R server.1=P server.2=Q server.3=R S server.1=P server.2=Q server.3=R server.4=S server.5=T P, Q server.1=P server.2=Q server.3=R R, S server.1=P server.2=Q server.3=R server.4=S server.5=T P, Q, R after RR of R, either of P, Q, R P, Q, R P, Q, R, S - P and Q can form a 2/3 quorum. - S can't form a Quorum as it can only get 2/5 R & S votes. - R can form a 3/5 or 4/5 quorum, in which case at least 1 of P and Q has to vote for R, invalidating a possibility of 2/3 quorum by just P and Q. Follower RR of Q (assuming P is leader) P, Q server.1=P server.2=Q server.3=R R, S server.1=P server.2=Q server.3=R server.4=S server.5=T P server.1=P server.2=Q server.3=R Q, R, S server.1=P server.2=Q server.3=R server.4=S server.5=T P, Q, R, [S] after RR of Q, either of P, Q, R P, Q, R, S P, Q, R, S P, Q, R, S Now S can form a 3/5 quorum with Q, R, S, but then P won't get additional vote to form a 2/3 quorum. Leader RR of P P server.1=P server.2=Q server.3=R Q, R, S server.1=P server.2=Q server.3=R server.4=S server.5=T P, Q, R, S server.1=P server.2=Q server.3=R server.4=S server.5=T [P], Q, R, S, T after RR of P P, Q, R, S Now all 4 nodes has same configuration and forms a 4/5 quorum. T Up P, Q, R, S, T server.1=P server.2=Q server.3=R server.4=S server.5=T P, Q, R, S after T up P, Q, R, S, T With T up the quorum becomes 5/5
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}