Engineer • Data Infrastructure Team / Data Platform / Data Science and Engineering Center • History • Working at LINE since 02/2018 • Hadoop ecosystems, Kafka and Flink • Interest • Distributed systems • Program verification theory • Dependent type systems • Model checking • Facebook: https://www.facebook.com/toshihiko.uchida.7 PROFILE
isolation • Data governance • Cost governance • Efficient utilization of the limited hardware resources • Increasing data size • Jobs requesting excessive resources • Reliability of large-scale distributed systems • … CHALLENGE
clusters by HDFS Federation + ViewFs • LINE DEV DAY 2019 • 100+PB scale Unified Hadoop cluster Federation with 2k+ nodes UNIFICATION Small HDP 2.6 Small Small HDP 2.6 Small Apache Hadoop 3 HDFS Federation + ViewFs
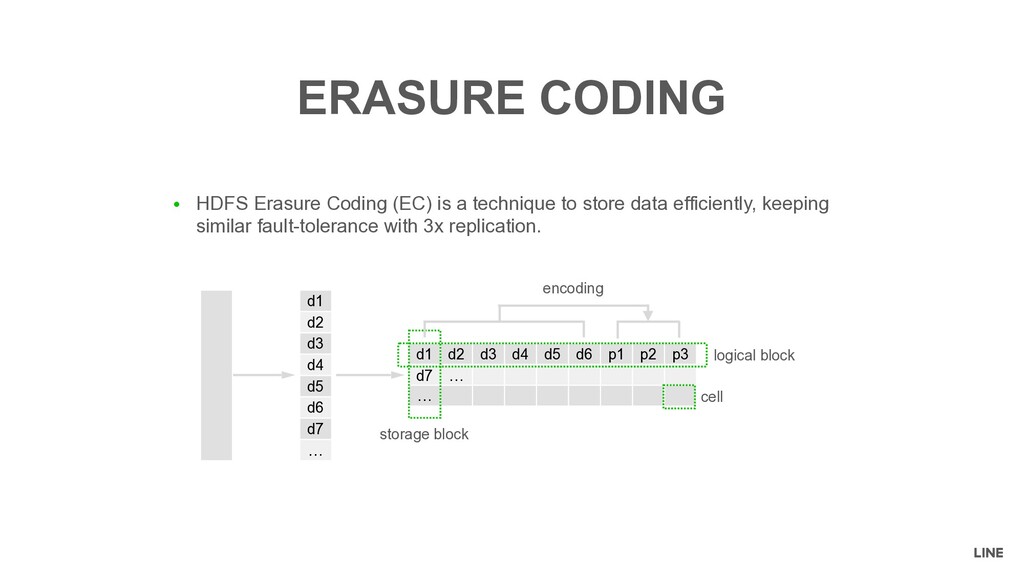
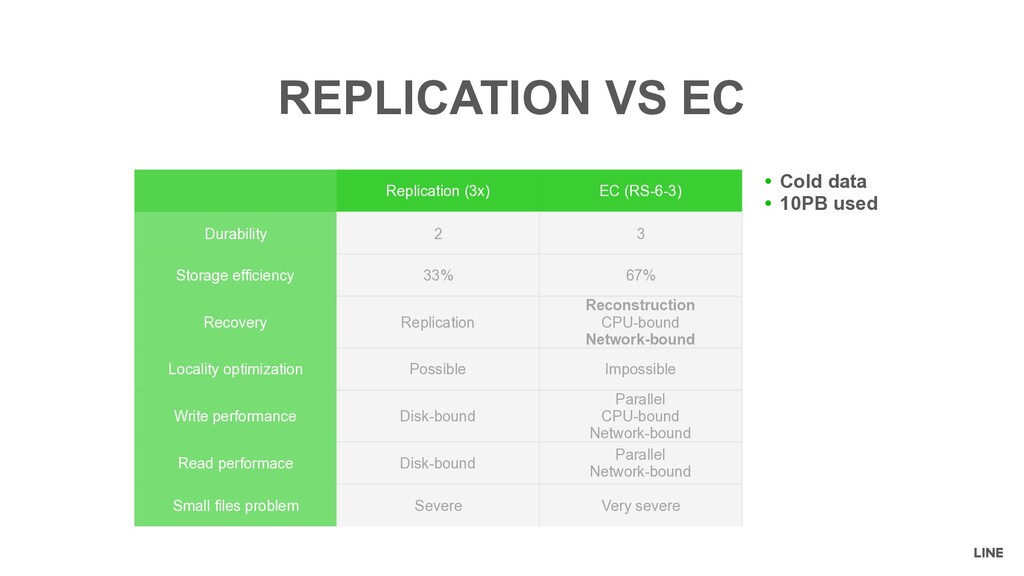
Storage efficiency 33% 67% Recovery Replication Reconstruction CPU-bound Network-bound Locality optimization Possible Impossible Write performance Disk-bound Parallel CPU-bound Network-bound Read performace Disk-bound Parallel Network-bound Small files problem Severe Very severe • Cold data • 10PB used
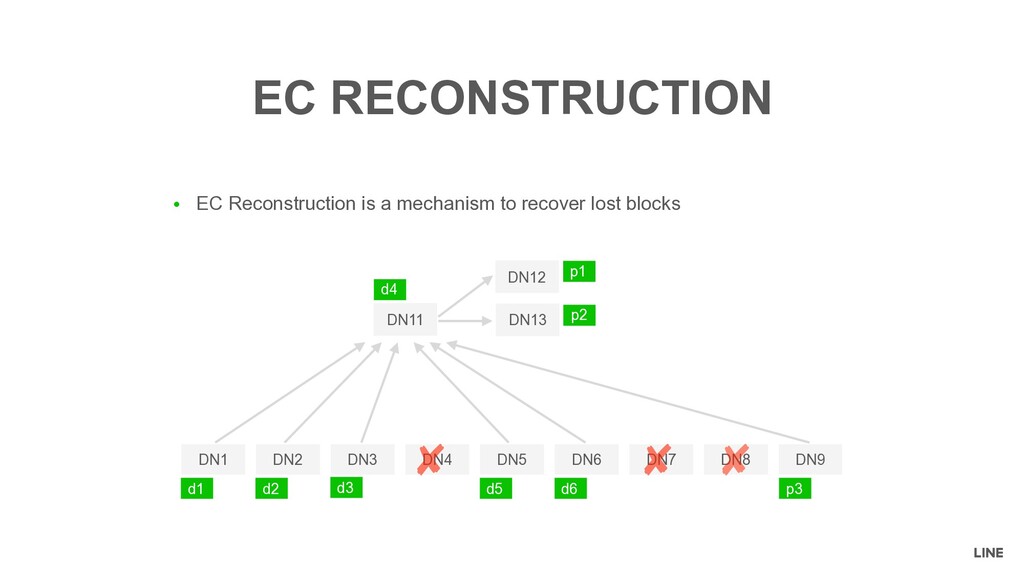
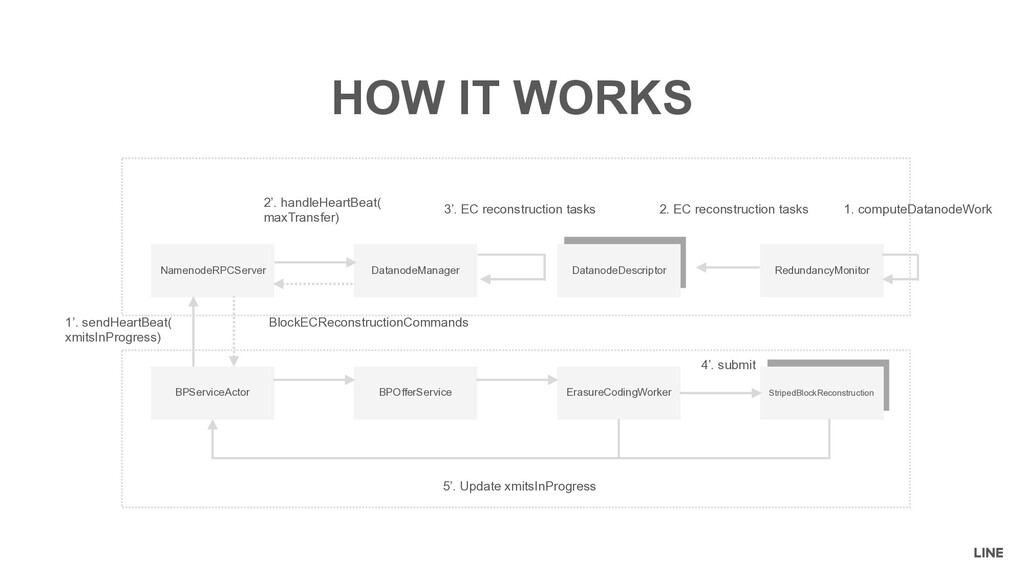
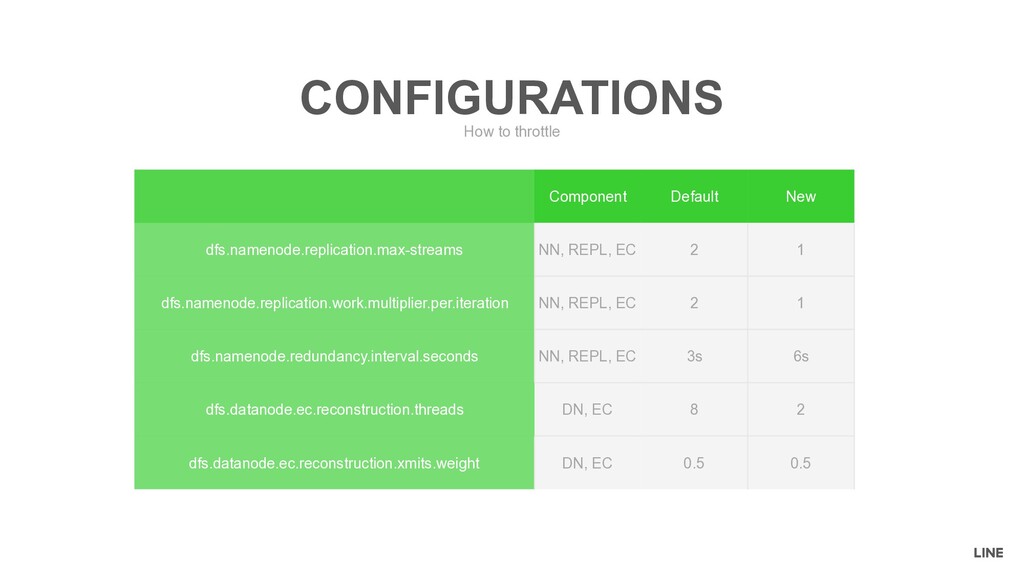
= # of reconstruction tasks • weight = dfs.datanode.ec.reconstruction.xmits.weight (= 0.5 by default) Definition XMITSINPROGRESS xmitsInProgress = repl + Σrecon i=1 max(max(sources, targets),1) * weight Meaning For each Datanode, xmitsInProgress represents the weighted number of running replication/reconstruction tasks
MAXTRANSFER maxTransfer = maxStreams − xmitsInProgress Meaning For any Namenode and Datanode, maxTransfer represents the number of replication/reconstruction tasks can be sent from Namenode to Datanode
replication/reconstruction task • 2 - 0 = 2 -> Two replication/reconstruction tasks • 1 - 0 = 1 -> One replication/reconstruction tasks Example MAXTRANSFER maxTransfer = maxStreams − xmitsInProgress Note Namenode does not take dfs.datanode.ec.reconstruction.xmits.weight into consideration Let’s set maxStreams=1!
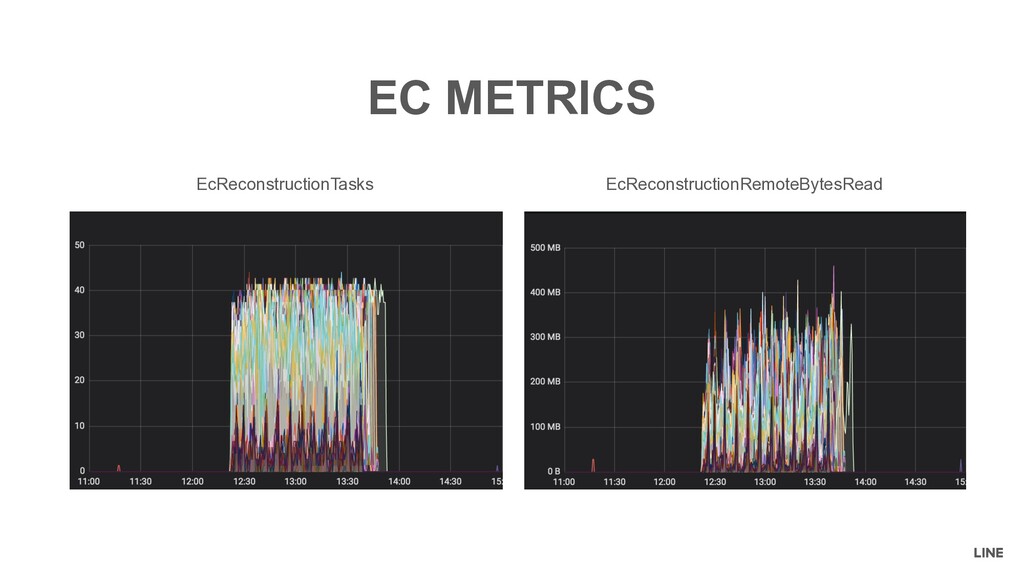
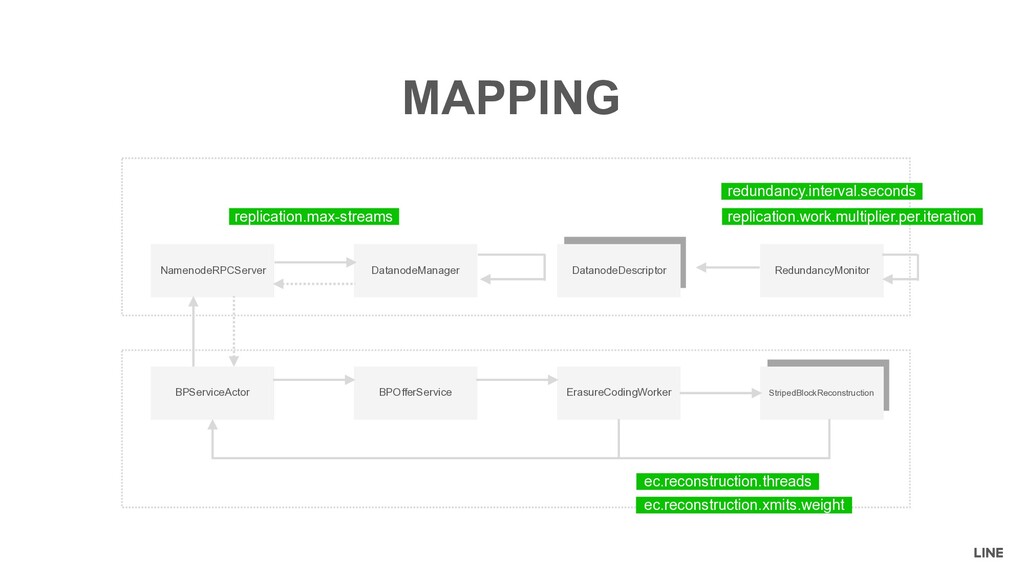
Remember maxTransfer = maxStreams - xmitsInProgress • Known, but open issue in the community • HDFS-14353: Erasure Coding: metrics xmitsInProgress become to negative. • Fixed the unit test xmitsInProgress become to negative OPEN ISSUE StripedBlockReconstruction BPServiceActor BPOfferService ErasureCodingWorker StripedBlockReconstruction The weight was not taken into consideration Update xmitsInProgress
archiving cold data by EC • E.g., based on the last access time of files • Use Archival Storage for EC • Develop I/O based throttling of EC reconstruction tasks • HDFS-11023 FUTURE WORK
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}