Toward the Establishment of Standards and Best Practices Johann-Mattis List Research Group “Computer-Assisted Language Comparison” Department of Linguistic and Cultural Evolution Max-Planck Institute for the Science of Human History Jena, Germany 2017/07/07 very long title P(A|B)=P(B|A)... 1 / 36
also crucial in comparative linguistics: alignment analysis (show where words are cognate, i.e., in which segments they coincide) correspondence pattern analysis (show the most frequently corresponding sounds for a number of related languages) 8 / 36
also crucial in comparative linguistics: alignment analysis (show where words are cognate, i.e., in which segments they coincide) correspondence pattern analysis (show the most frequently corresponding sounds for a number of related languages) etymological analysis (show how the original meaning of a word evolved, etc.) 8 / 36
also crucial in comparative linguistics: alignment analysis (show where words are cognate, i.e., in which segments they coincide) correspondence pattern analysis (show the most frequently corresponding sounds for a number of related languages) etymological analysis (show how the original meaning of a word evolved, etc.) etc. 8 / 36
in linguistic research: journals still accept too many papers which do not share full material and code they used for their analyses if authors share, they make it often very difficult to use the data for testing by converting data which was in tabular form originally into PDF, which may at times even not even be searchable, etc. 11 / 36
in linguistic research: journals still accept too many papers which do not share full material and code they used for their analyses if authors share, they make it often very difficult to use the data for testing by converting data which was in tabular form originally into PDF, which may at times even not even be searchable, etc. even if authors share, they may often forget to share their explicit annotations and analyses, thus leaving the readers alone with the raw data 11 / 36
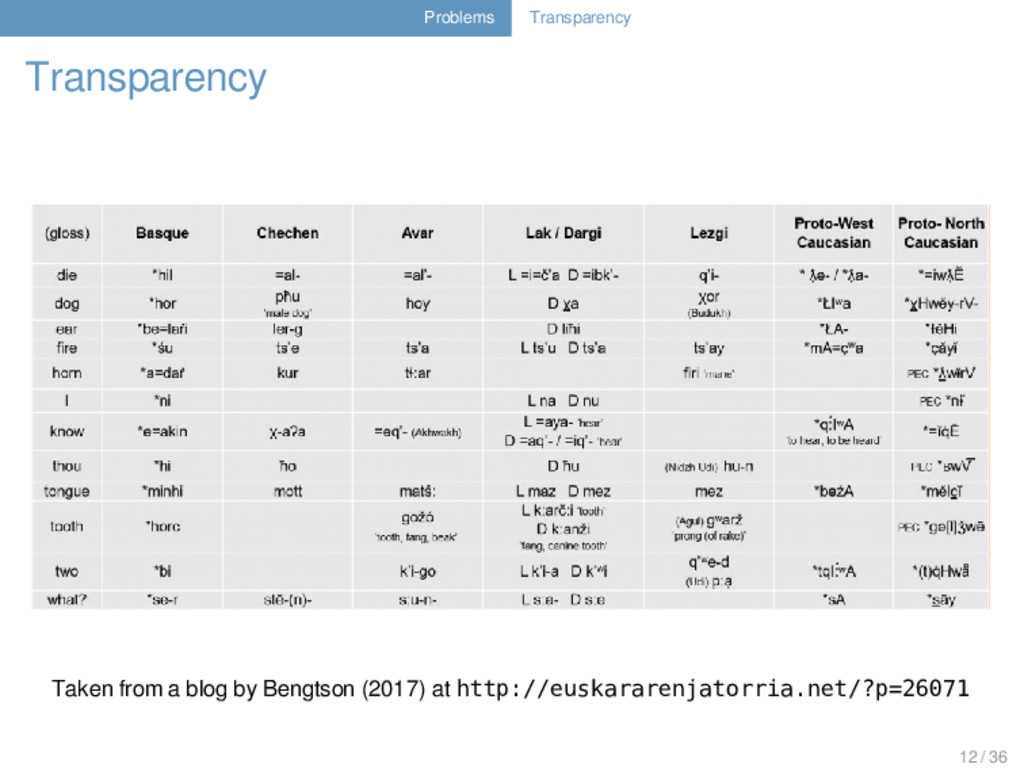
cannot be understood in the raw form in which they are provided: words are declared as cognate, but nobody really knows WHERE the words should be cognate 13 / 36
cannot be understood in the raw form in which they are provided: words are declared as cognate, but nobody really knows WHERE the words should be cognate correspondences are labeled as “regular” without giving sufficient proof for this neither in the texts nor in the data 13 / 36
cannot be understood in the raw form in which they are provided: words are declared as cognate, but nobody really knows WHERE the words should be cognate correspondences are labeled as “regular” without giving sufficient proof for this neither in the texts nor in the data sources are omitted and readers are left alone with a bunch of word lists of which nobody knows where they were exactly taken from 13 / 36
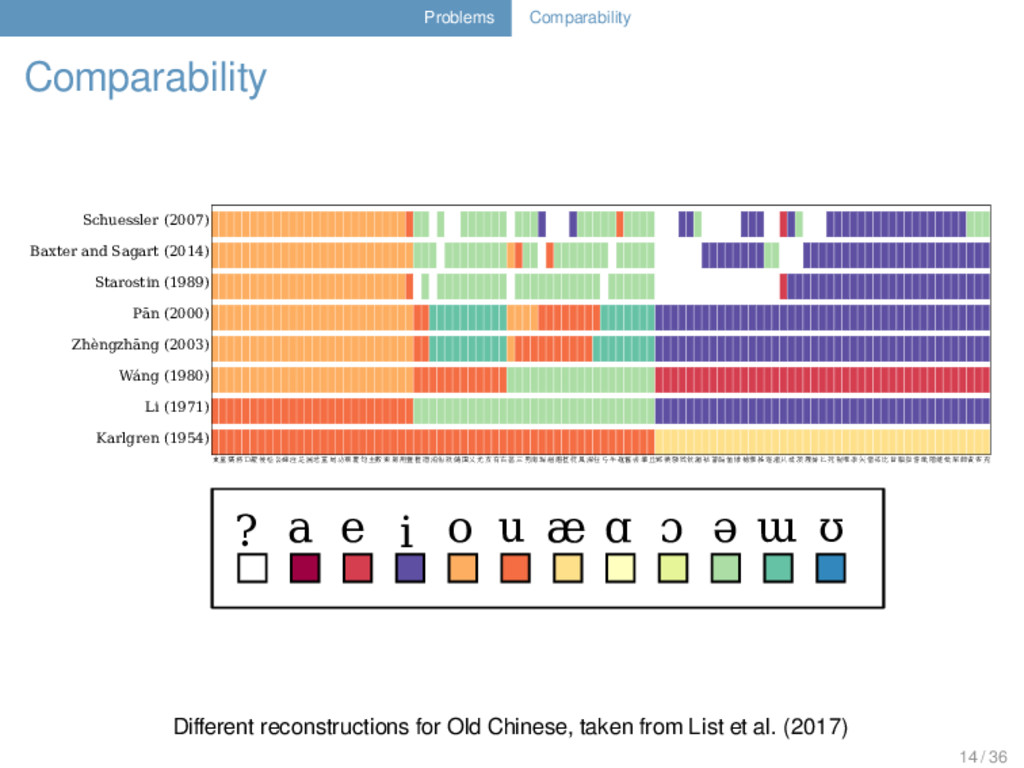
Zhèngzhāng (2003) Pān (2000) Starostin (1989) Baxter and Sagart (2014) Schuessler (2007) ? a e i o u æ ɑ ɔ ə ɯ ʊ Different reconstructions for Old Chinese, taken from List et al. (2017) 14 / 36
opinions in comparative linguistics: data sources are insufficiently reported computational studies are based on different subsets of the data analyses exclude or focus on specific parts of a given dataset 15 / 36
an extremely data-driven discipline, we often still behave as if it was all about prose and discourse. In times when digital applications make the lives of scientists a lot easier, linguists need to find ways to transfer their analyses into the new age. This can only be done if we drastically increase the availabil- ity, transparency, and comparability of data in linguistics. 16 / 36
Formats initiative (Forkel et al. 2016, http://cldf.clld.org) aims at increasing the comparability of cross-linguistic data and analyses. It comes along with: 18 / 36
Formats initiative (Forkel et al. 2016, http://cldf.clld.org) aims at increasing the comparability of cross-linguistic data and analyses. It comes along with: standardization efforts (linguistic meta-data-bases like Glottolog and Concepticon), 18 / 36
Formats initiative (Forkel et al. 2016, http://cldf.clld.org) aims at increasing the comparability of cross-linguistic data and analyses. It comes along with: standardization efforts (linguistic meta-data-bases like Glottolog and Concepticon), software APIs which help to test whether data conforms to standards, and 18 / 36
Formats initiative (Forkel et al. 2016, http://cldf.clld.org) aims at increasing the comparability of cross-linguistic data and analyses. It comes along with: standardization efforts (linguistic meta-data-bases like Glottolog and Concepticon), software APIs which help to test whether data conforms to standards, and working examples for best practice. 18 / 36
a couple of software tools (LingPy, Beastling, EDICTOR) support CLDF to some degree. In the future, we hope that the number of users will increase, and that the community helps to develop the formats further. 19 / 36
details, discussions, and working examples. Format for machine-readable specification is CSV with metadata in JSON, following the W3C’s Model for Tabular Data and Metadata on the Web (http://www.w3.org/TR/tabular-data-model/). 20 / 36
details, discussions, and working examples. Format for machine-readable specification is CSV with metadata in JSON, following the W3C’s Model for Tabular Data and Metadata on the Web (http://www.w3.org/TR/tabular-data-model/). CLDF ontology builds and expands upon the General Ontology for Linguistic Description (GOLD). 20 / 36
details, discussions, and working examples. Format for machine-readable specification is CSV with metadata in JSON, following the W3C’s Model for Tabular Data and Metadata on the Web (http://www.w3.org/TR/tabular-data-model/). CLDF ontology builds and expands upon the General Ontology for Linguistic Description (GOLD). A pycldf API in Python is currently in preparation and will help users to evaluate whether their data conforms to CLDF. 20 / 36
Robert Forkel) A lot of the guidelines put forward for Python code in The Zen of Python (https://www.python.org/dev/peps/pep-0020/) can also be used to characterize CLDF. In particular Explicit is better than implicit. 21 / 36
Robert Forkel) A lot of the guidelines put forward for Python code in The Zen of Python (https://www.python.org/dev/peps/pep-0020/) can also be used to characterize CLDF. In particular Explicit is better than implicit. Readability counts. 21 / 36
Robert Forkel) A lot of the guidelines put forward for Python code in The Zen of Python (https://www.python.org/dev/peps/pep-0020/) can also be used to characterize CLDF. In particular Explicit is better than implicit. Readability counts. Errors should never pass silently (Unless explicitly silenced). 21 / 36
Robert Forkel) A lot of the guidelines put forward for Python code in The Zen of Python (https://www.python.org/dev/peps/pep-0020/) can also be used to characterize CLDF. In particular Explicit is better than implicit. Readability counts. Errors should never pass silently (Unless explicitly silenced). Simple is better than complex. 21 / 36
Robert Forkel) A lot of the guidelines put forward for Python code in The Zen of Python (https://www.python.org/dev/peps/pep-0020/) can also be used to characterize CLDF. In particular Explicit is better than implicit. Readability counts. Errors should never pass silently (Unless explicitly silenced). Simple is better than complex. In the face of ambiguity, refuse the temptation to guess. 21 / 36
the form of the linguistic sign are the triple pillars upon which CLDF rests. Together, they will restore comparability of linguistic data in the world." — Tommen Baratheon (King of the Iron Throne, † in 6x10) 22 / 36
2017) to refer to language varieties use Concepticon (List et al. 2016) to refer to concepts develop a cross-linguistic phonetic notation system to evaluate whether phonetic transcriptions for word forms conform to cross-linguistic standards 23 / 36
2016) link concept labels in published concept lists (questionnaires) to concept sets link concept sets to meta-data define relations between concept sets never link one concept in a given list to more than one concept set (guarantees consistency) provide an API to check the consistency of the data and to query the data provide a web-interface to browse through the data 24 / 36
Notations (in prep.) normalize ambiguities of IPA establish a pool of phonetic segments which are linked to other datasets (Phoible, Moran et al. 2014, PBase, Mielke 2008, etc.) provide or link to feature systems or additional kinds of metadata provide generic transformation tables for frequently used phonetic transcription systems provide an API to check the consistency of a given transcription 27 / 36
identifier for each word) Language and Language_ID (Glottolog) Concept and Paramter_ID (Concepticon) Value, Form, and Segments (CLPN) Source (key of BibTex file) 30 / 36
identifier for each word) Language and Language_ID (Glottolog) Concept and Paramter_ID (Concepticon) Value, Form, and Segments (CLPN) Source (key of BibTex file) Comment (free text) 30 / 36
Set Alignment MEANING RELATION Morphemes Slice Form Value Segments FORM ID A B requires important language-internal language-external Language LANGUAGE 31 / 36
web-based tool for the annotation of etymological data online available at http://edictor.digling.org description available in List (2017) works client-side and offline 32 / 36
web-based tool for the annotation of etymological data online available at http://edictor.digling.org description available in List (2017) works client-side and offline allows for morpheme annotation, alignment analysis, cognate annotation, and phonological analysis 32 / 36
web-based tool for the annotation of etymological data online available at http://edictor.digling.org description available in List (2017) works client-side and offline allows for morpheme annotation, alignment analysis, cognate annotation, and phonological analysis serves as a litmus test for the expressive power of wordlists in CLDF 32 / 36
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}