it you better never let it go you only get one shot do not miss your chance to blow this opportunity comes once in a lifetime… (Eminem, “Lose yourself”, 2002)
it you better never let it go you only get one shot do not miss your chance to blow this opportunity comes once in a lifetime… (Eminem, “Lose yourself”, 2002)
moment you own it [-ɪt] ? [ai] you better never let it go you only get one shot do not miss your chance to blow this opportunity comes once in a lifetime… (Eminem, “Lose yourself”, 2002)
was constructed for this talk are the rhyme annotations given in the appendix of Baxter (1992). Since the data was not digitally available, I transferred the annotations by Baxter to a digital version of the Shījīng (Project Gutenberg) and checked it with additional digital versions (e.g., http://ctext.org).
where the comparison with other versions and with Baxter’s data showed that it contained errors. Furthermore, I had a digital collection of most of the Old Chinese reconstructions given in the new OCBS system (provided by L. Sagart).
way, the Shījīng was organized into: • poems (numbered as 1, 2, 3, etc.) • stanzas (numbered 1.1, 1.2, etc.) • section (part ended by comma or full stop in which normally the rhyme words occur, numbered for each stanza, 1, 2, 3, etc.)
to Baxter’s annotation, this was noted as such. If I detected further rhyme words or had reasons to disagree with Baxter’s annotation, this was noted in an alternative annotation. For each section, I tried to identify the Old Chinese readings of the OCBS system. This was not possible in all cases. Some 400 readings are missing, and I still did not have time to check them.
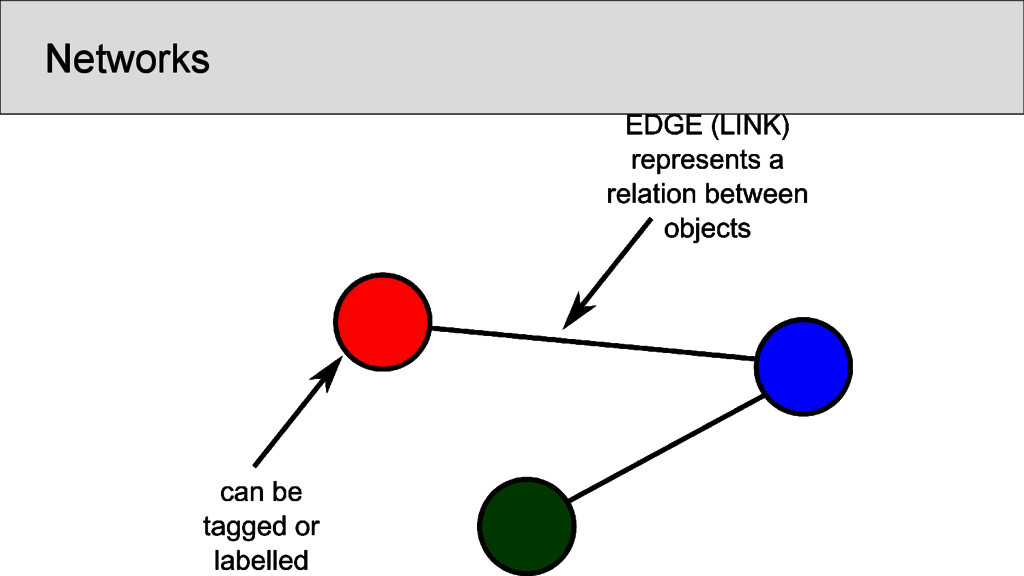
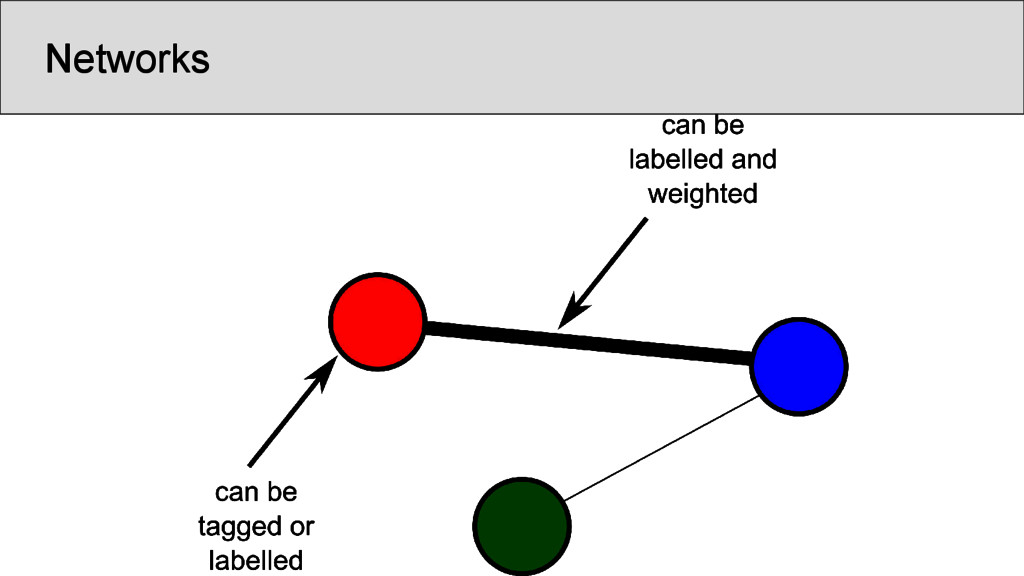
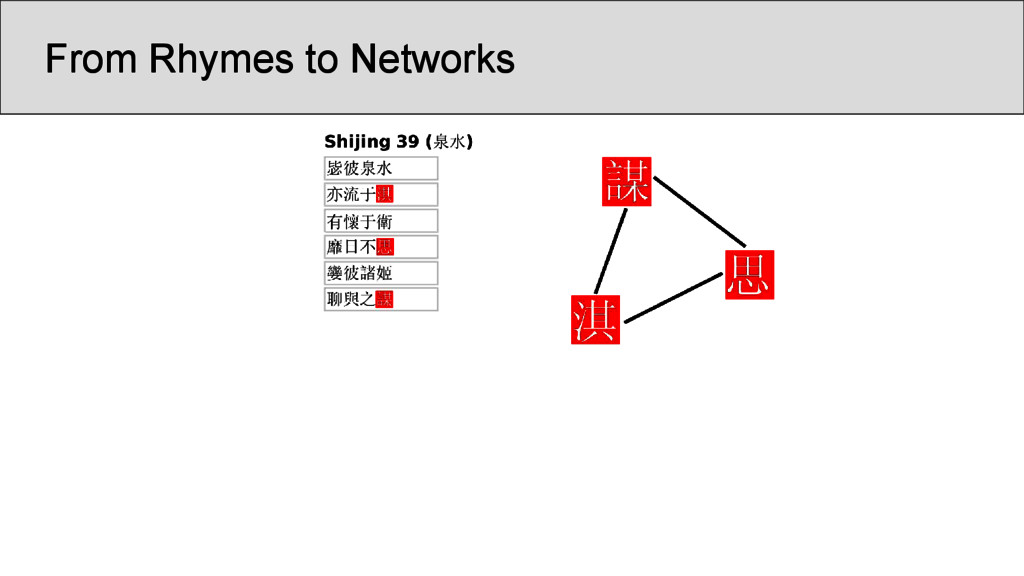
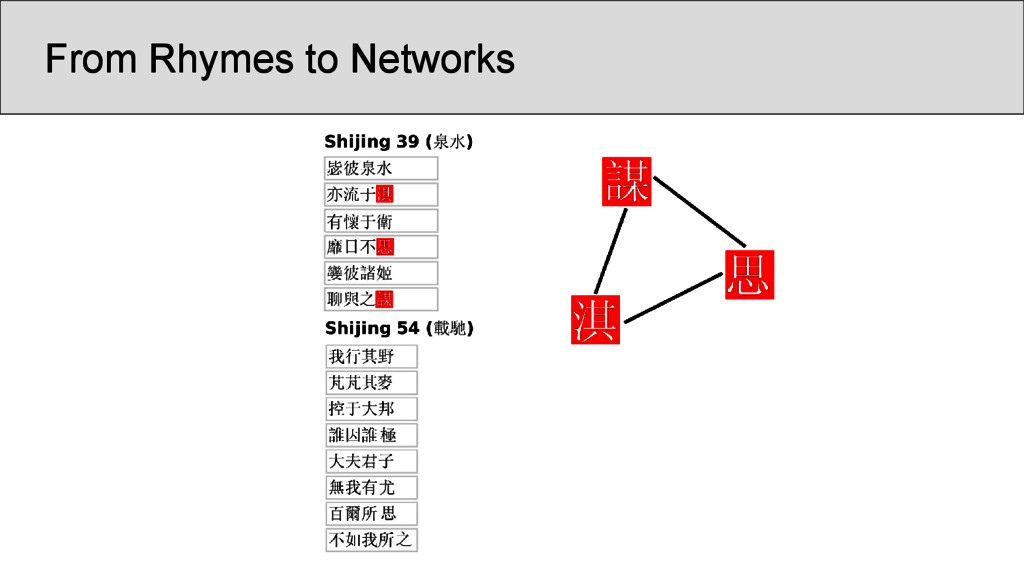
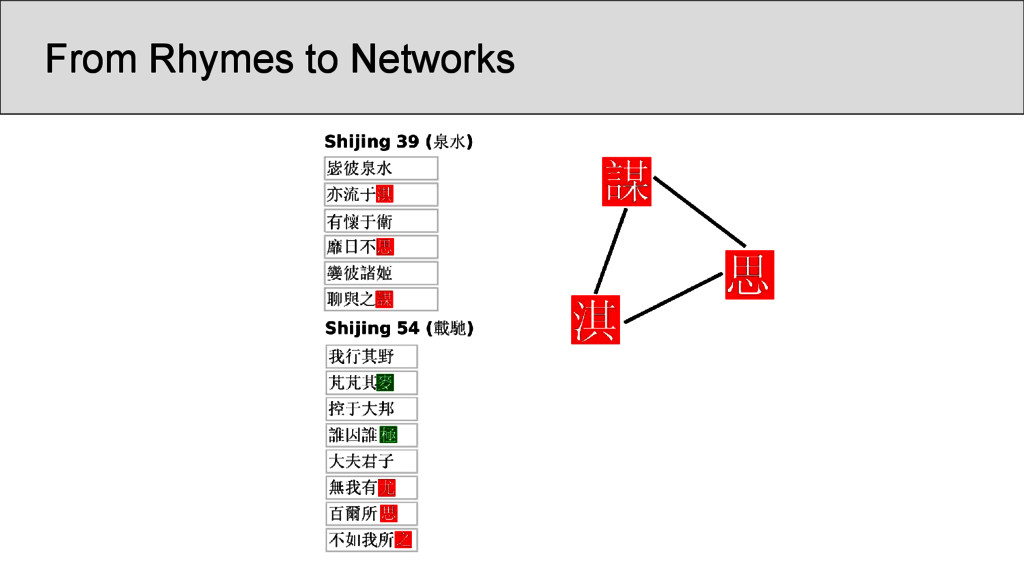
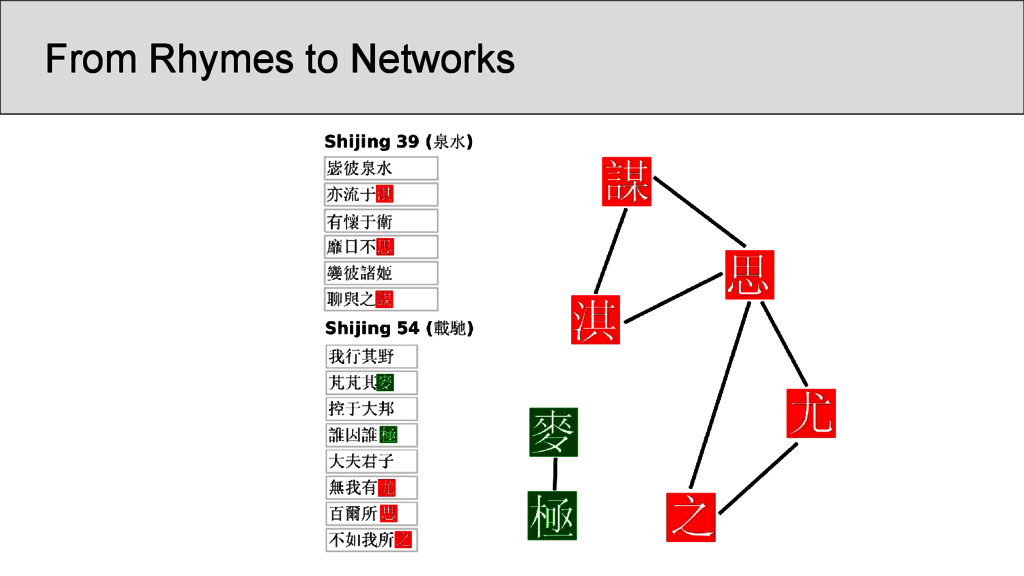
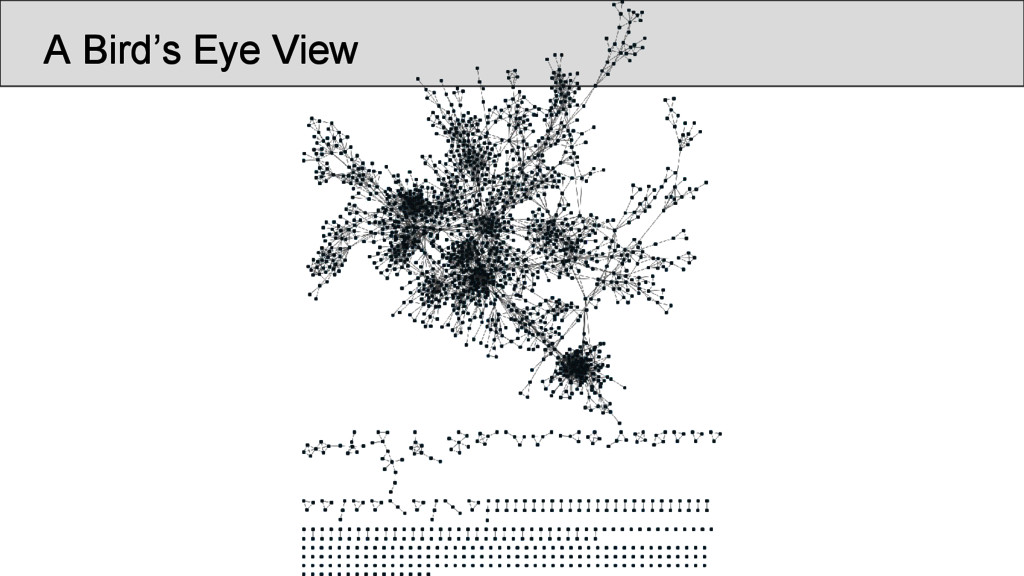
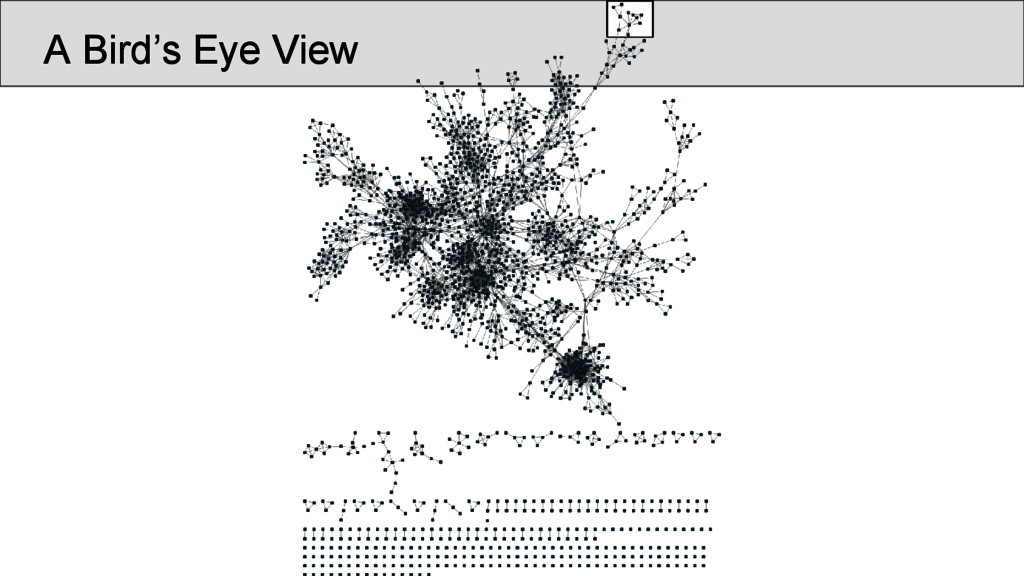
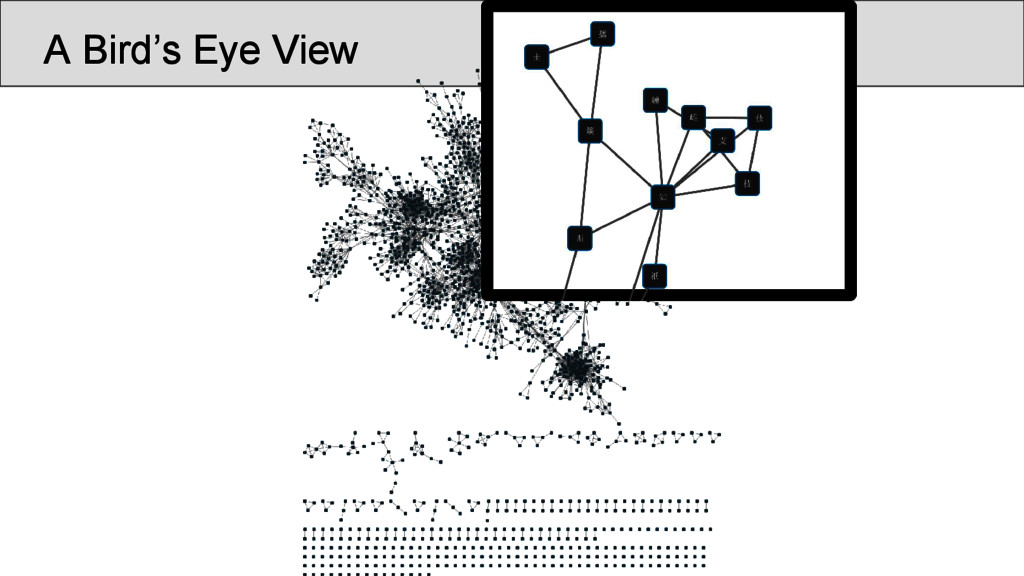
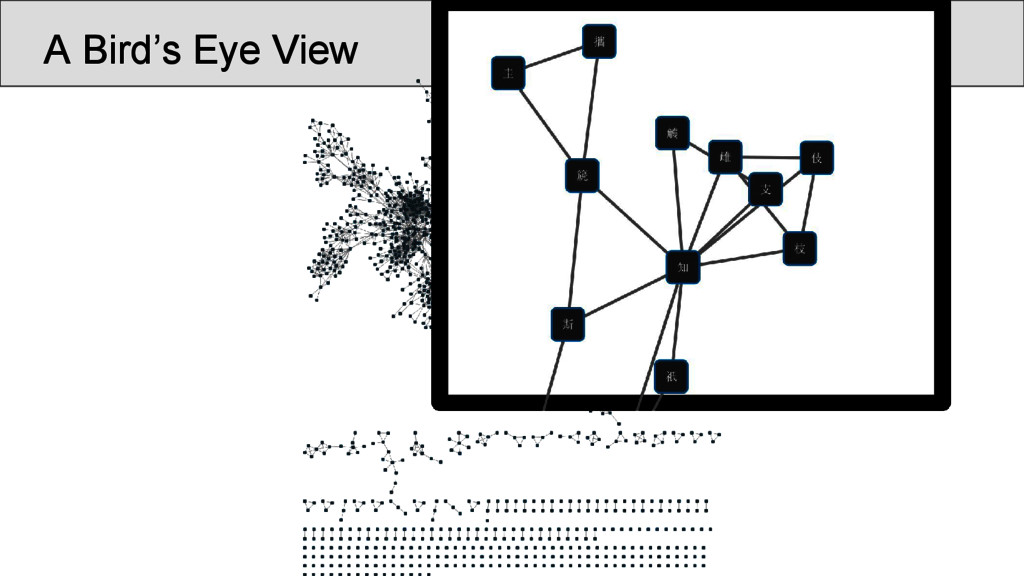
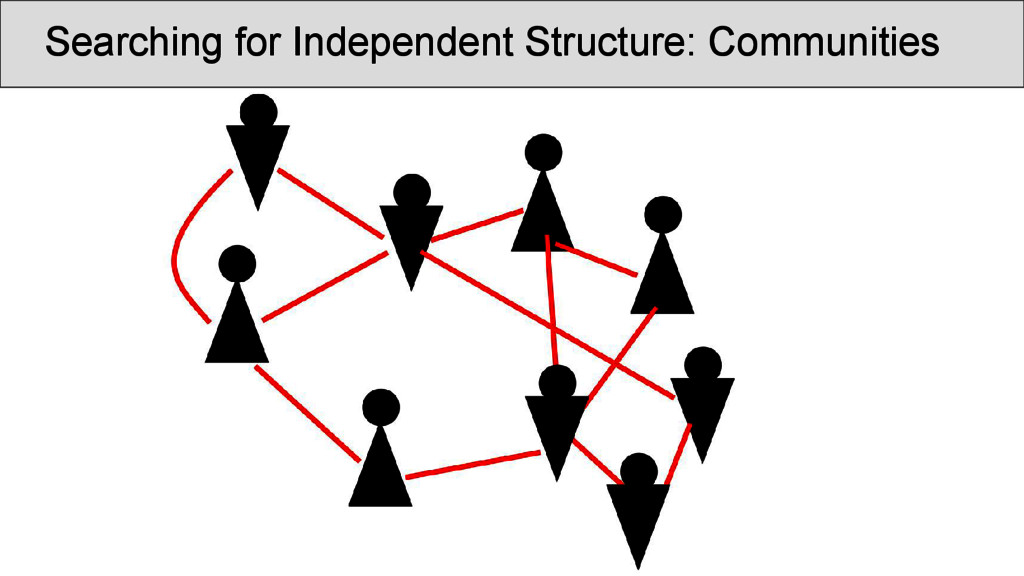
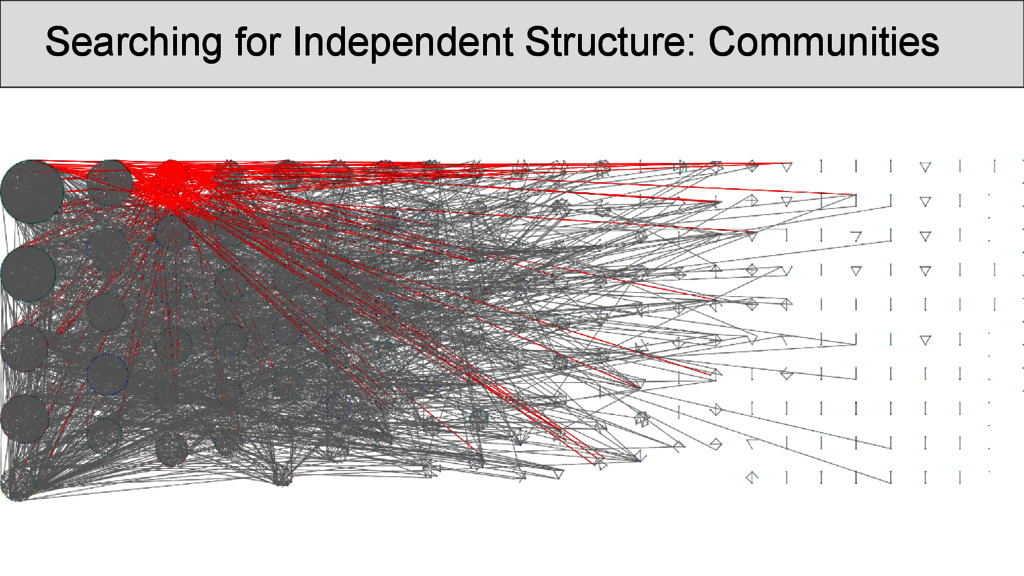
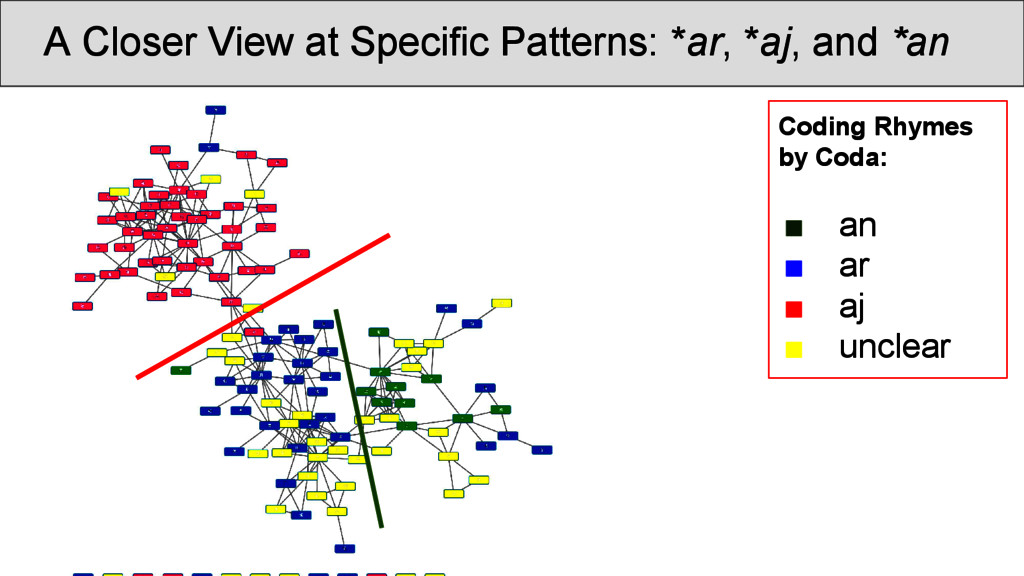
characters which occur in the Shījīng in a position that was annotated as “rhyming” according to Baxter’s annotation, are represented as nodes • links between two characters are drawn whenever they are annotated as being rhyming in a given poem • the number of instances in which two characters rhyme in separate stanzas were counted and assigned as the edge weights of the network • node weights were derived from the number of times the rhyme words occurred in the Shījīng
pair of identical lines only once, in order to avoid that phrases bear too much weight The data should be further normalized (but there was no time for the analysis): • by controlling the weight of each occurrence of a rhyme along with the size of the rhyme group, in which it occurs, in order to avoid that one overcounts links in poems with really large groups of rhyming words per stanza
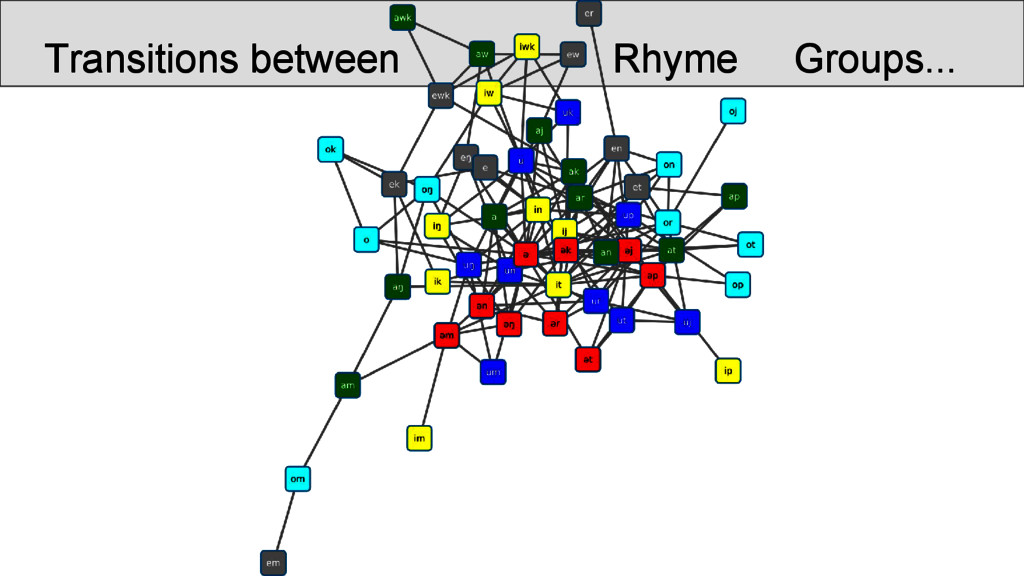
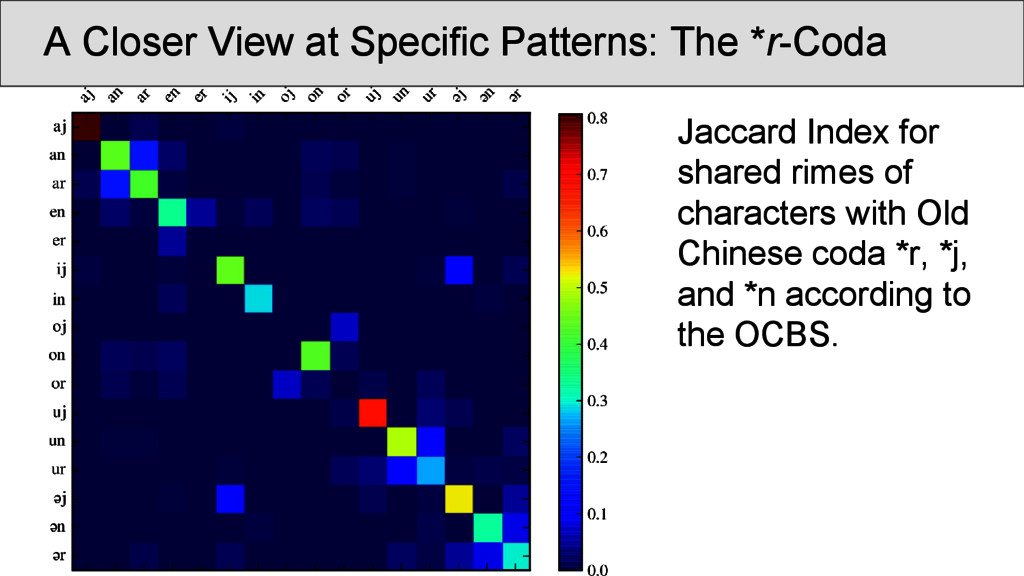
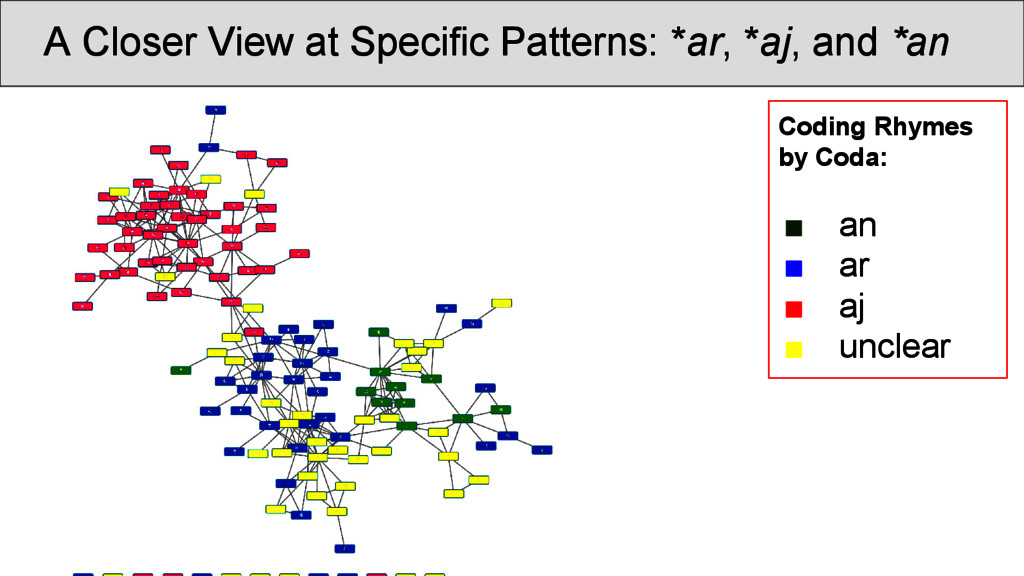
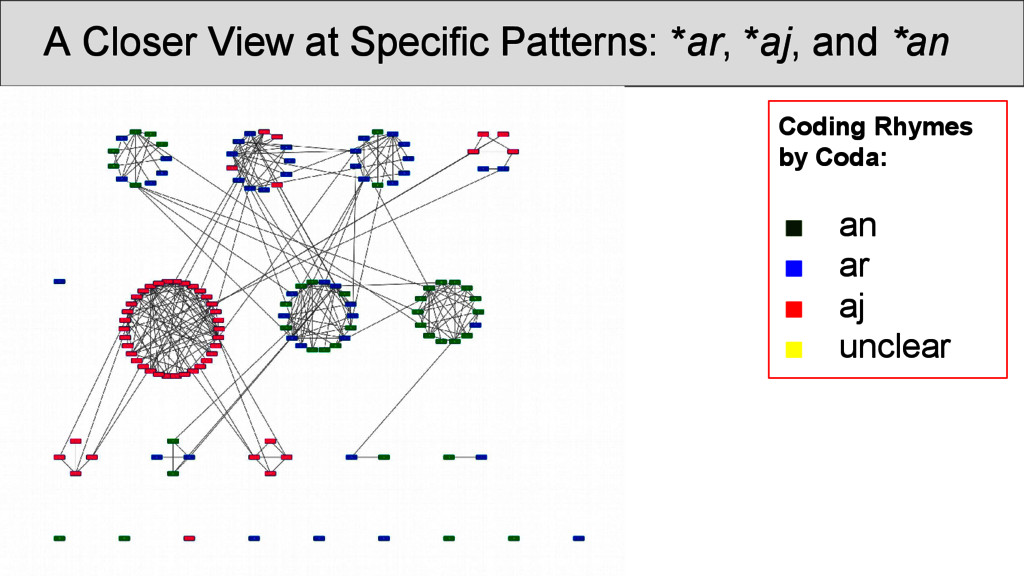
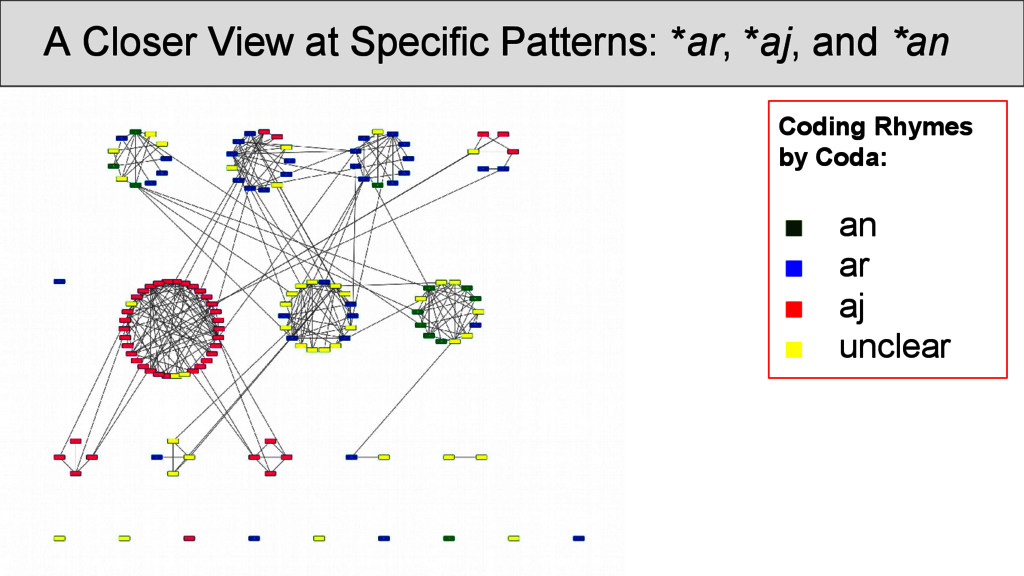
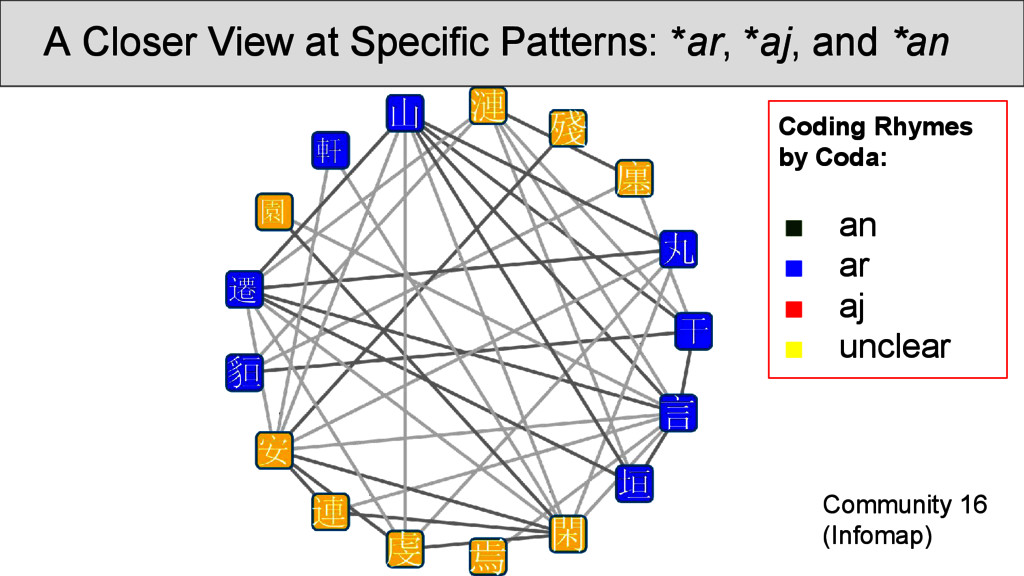
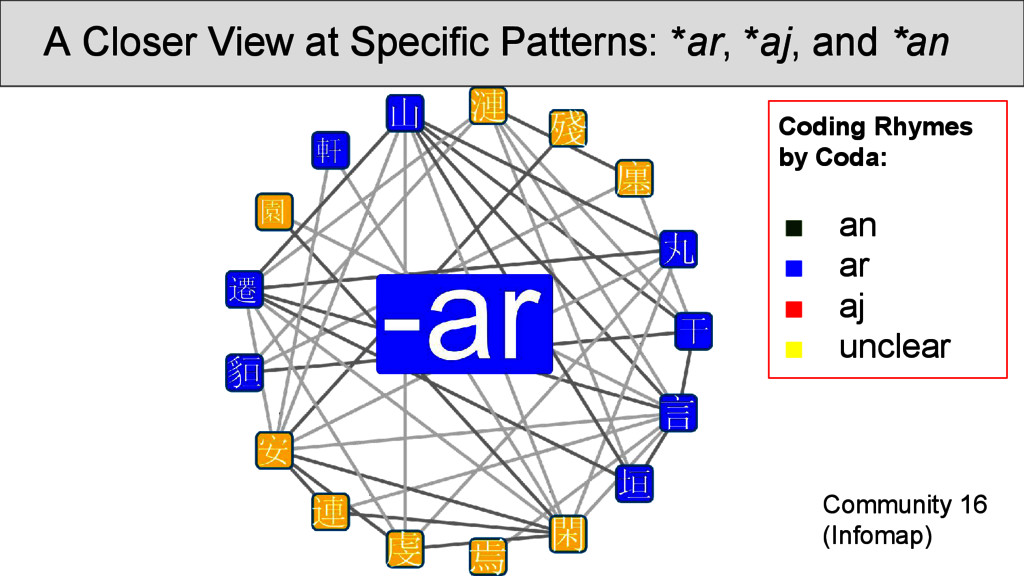
OCBS rhyme groups and inside the same group. Most of the groups are strongly recovered, some, however, occur so infrequently that they rhyme more often with other words than with words of their own group. Transitions betweenRhyme Groups...
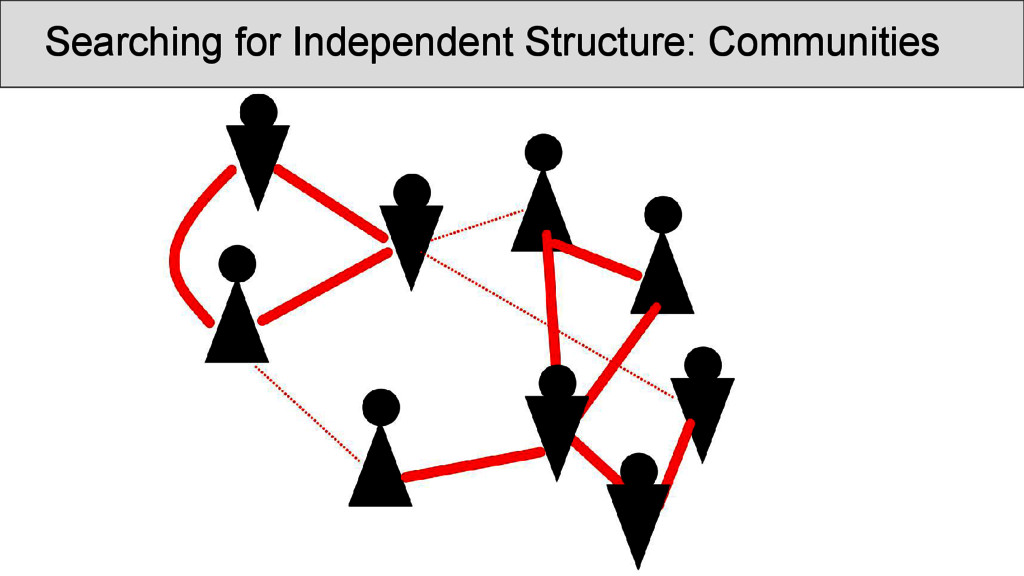
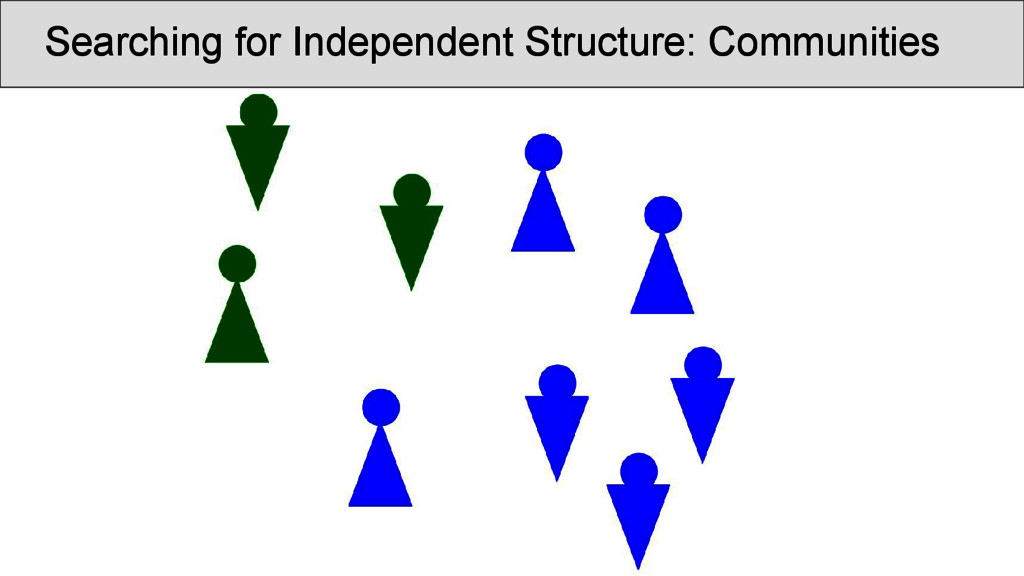
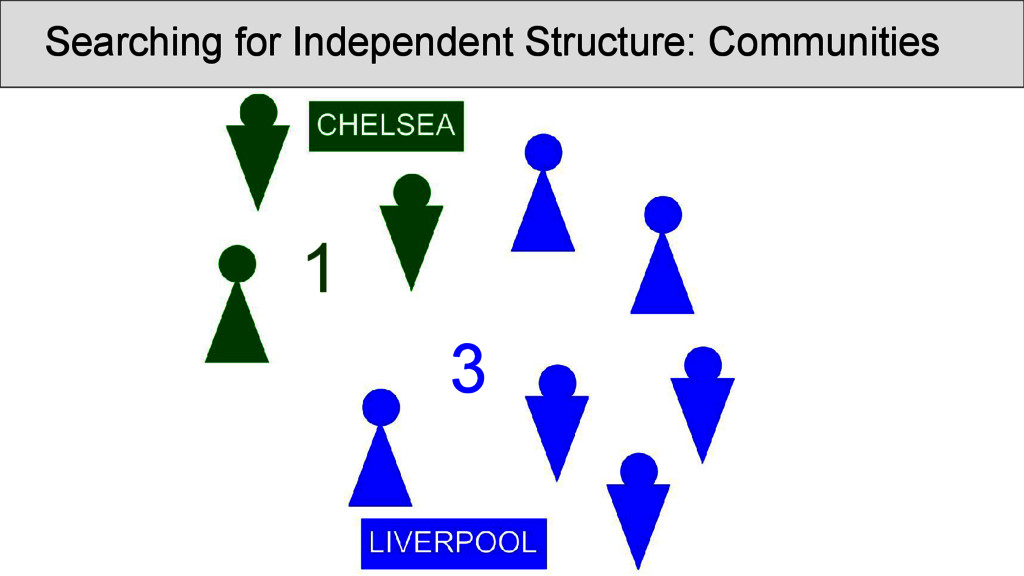
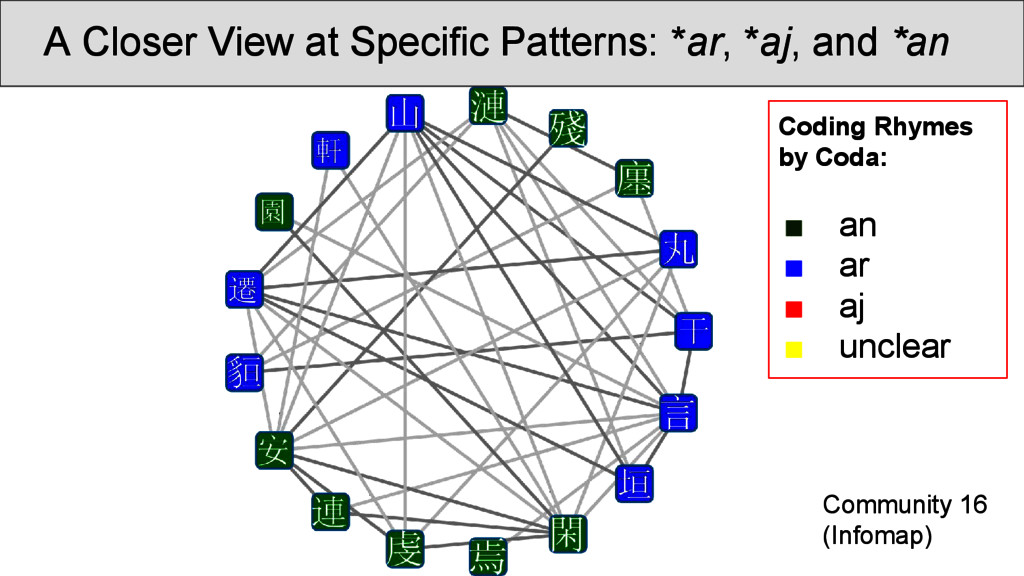
was carried out on the rhyme data. Infomap (Rosvall and Bergstrom 2008) is a fast community detection algorithm with a very good performance. It handles weighted nodes and weighted edges, and uses random walks through the network in order to determine the best partition into communities. • Results can be inspected at http://digling. org/shijing/infomap.html
are not necessarily overlapping directly with the OCBS reconstructions of the rhymes, but show interesting transitions between rhyme groups as well as splits. Interpreting the data, however, is difficult, since: • a community identified by Infomap is not necessarily homogeneous, since rhyming is not homogeneous • a split of words with the same rhyme group into two communities does not imply that they do not rhyme • we always need to get back to the real data and see what is going on there
approaches is still strictly experimental. • We need to enhance the data (missing readings, swapped lines in the Shījīng text). • We need to enhance the models (better normalization!)
turns be useful to inspect the automatically identified clusters in times of doubt regarding the reading of a certain character. • It is generally useful to make use of interactive visualization techniques when dealing with huge amounts of data (especially when it comes from different sources). • Tools like the “Shījīng rhyme browser” are especially useful for beginners, but probably also for experts (?).
we have large collections of rhyme networks on all kinds of poetry, ranging Shakespeare via Bob Dylan, up to Eminem. • We could gather important information on rhyming behaviour — both cross-cultural and culture-specific. • We could track the emergence of hip hop, or the degradation of rhyme patterns in modern poetry, or even the influence of the “Judas!-call” on Bob Dylans rhyming practice...
could carry out large-scale comparisons on rhyming practice in different stages of Chinese • that we could propose transparently our individual assessments of what we think rhymed in pieces of old Chinese poetry • that we could trace the history of Chinese in poetry networks … doesn’t that sound like it could be interesting?
tanks convention dimension green gentian comprehension suspension Thanks to Laurent Sagart and William Baxter for helpful discussion, tips, ideas, and data! Thanks to Bob Dylan, Eminem, Shakespeare, and all the other poets out there!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Rhymes Lose yourself in the music [-ɪk] ? [ɔi] the](https://files.speakerdeck.com/presentations/b75367879bf540cba44316a822b81e41/slide_4.jpg){kind=link}
![Rhymes music [-ɪk] own it [-ɪt] But Germans would rhyme](https://files.speakerdeck.com/presentations/b75367879bf540cba44316a822b81e41/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}