◦ Local Streaming I/O ◦ streaming data from the storage system by an inter-process communication scheme, such as TCP/IP or JDBC. ◦ Local and remote Direct I/O > Streaming I/O by 10%-15%
files stored in a distributed file system, i.e. HDFS Ranged-indexes ◦ input HDFS files are not sorted but each data chunk in the files are indexed by keys Block-level indexes ◦ tables stored in database servers Database indexed tables Boost selection task 2x-10x depending on the selectivity
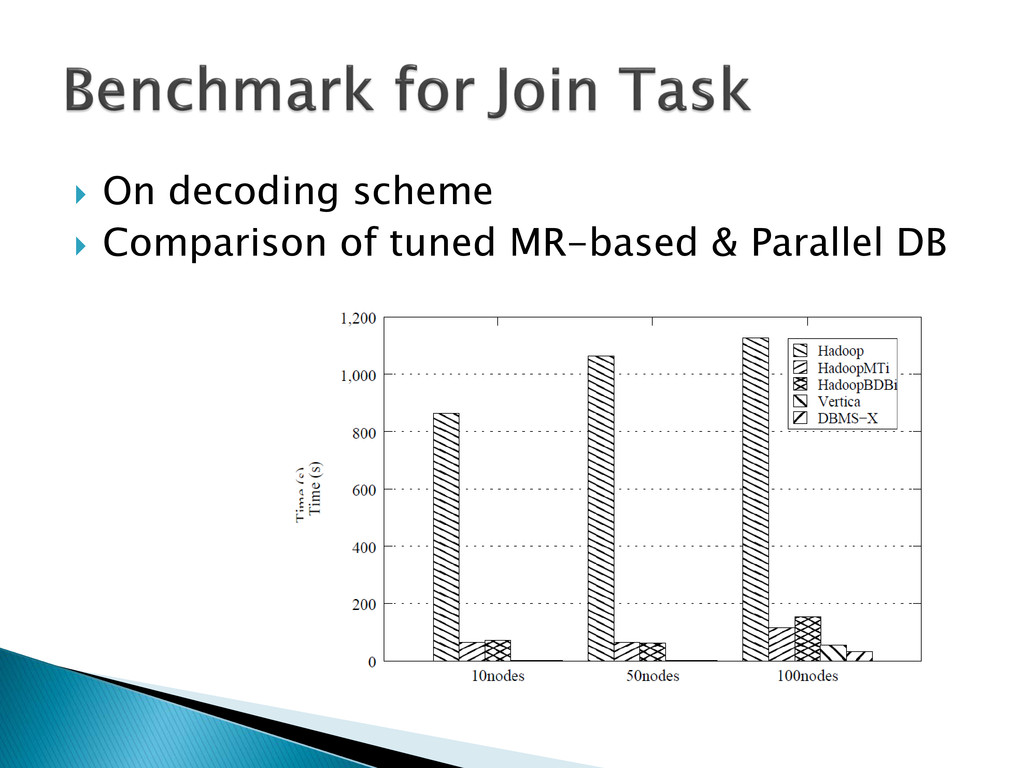
Modification of data node implementation Text decoder ◦ Immutable same as Dewitt ◦ Mutable by ourselves Binary decoder ◦ Hadoop Immutable Writable decoder Mutable using hadoop API by ourselves ◦ Google Protocol buffer Build-in compiler->mutable Immutable by ourselves ◦ Berkeley DB BDB binding API (mutable)
code tree ◦ A complete framework is needed instead of miscellaneous patches. ◦ Various API support: CLI, Web rather than Java. Future work ◦ Provide query parser, optimizer etc to build a complete solution ◦ Elastic power-aware data intensive Cloud http://www.comp.nus.edu.sg/~epic/download/MapRe duceBenchmark.tar.gz Tenzing: A SQL Implemetation On The MapReduce Framework
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
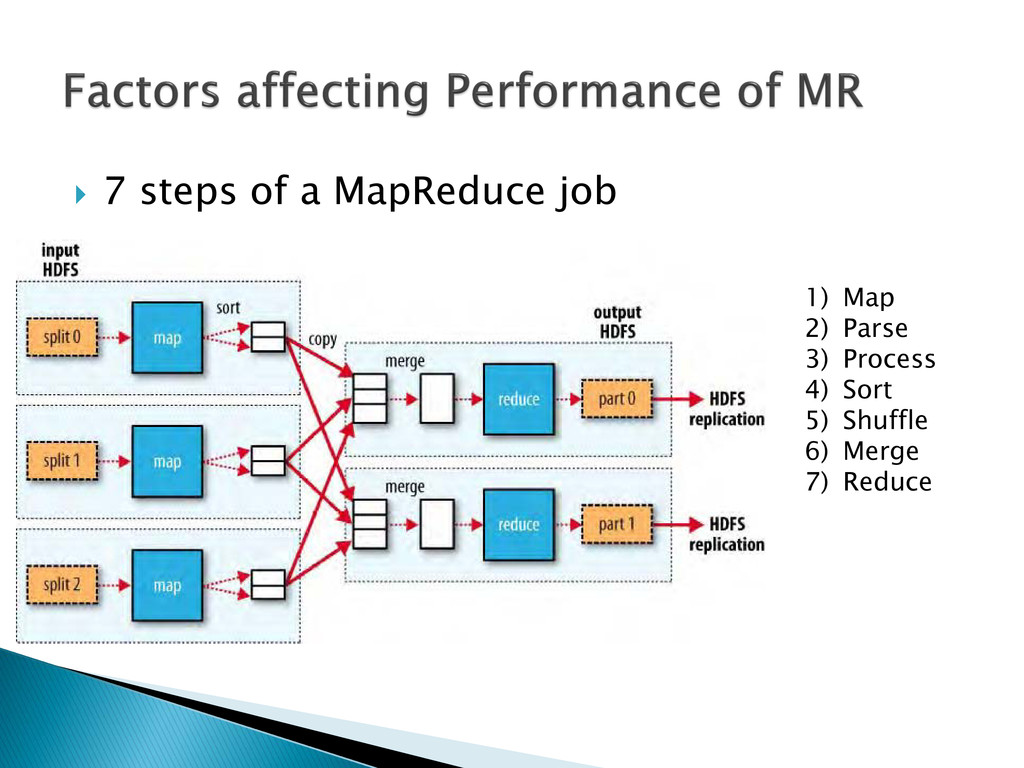{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
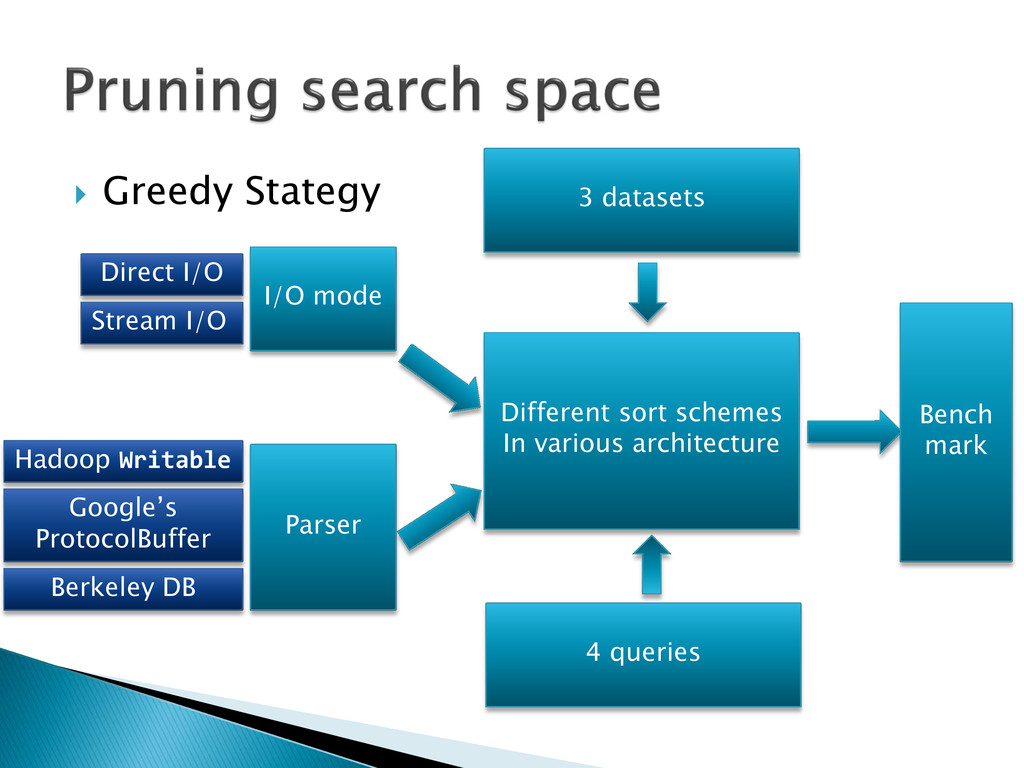{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
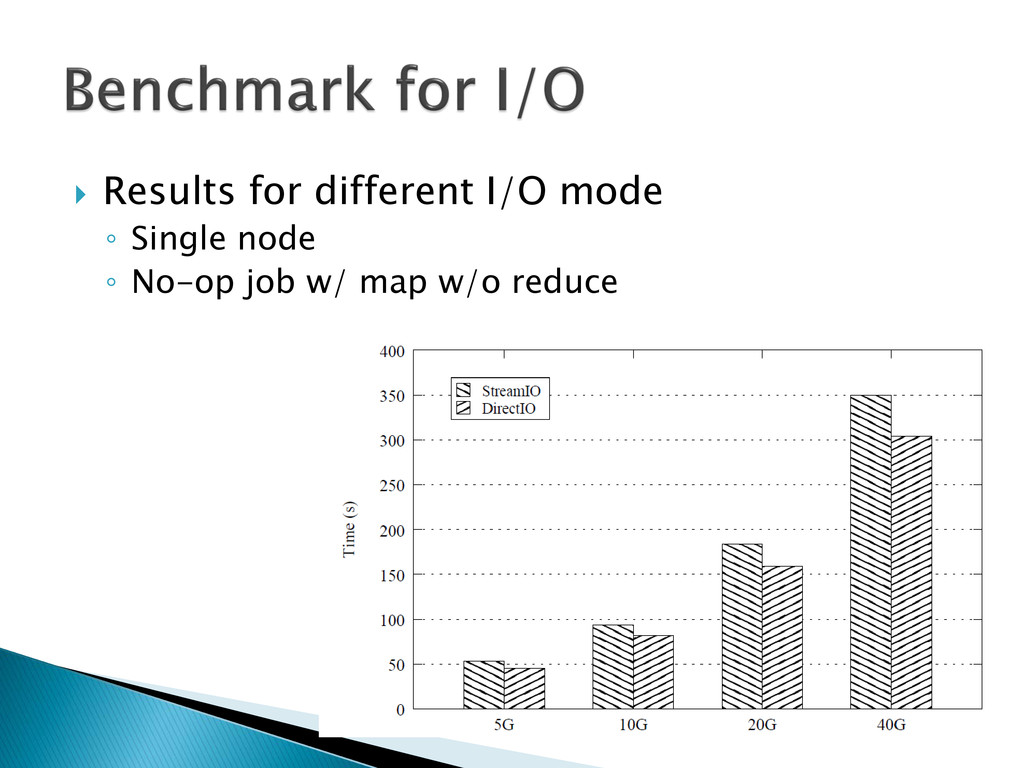{kind=link}
{kind=link}
{kind=link}
{kind=link}
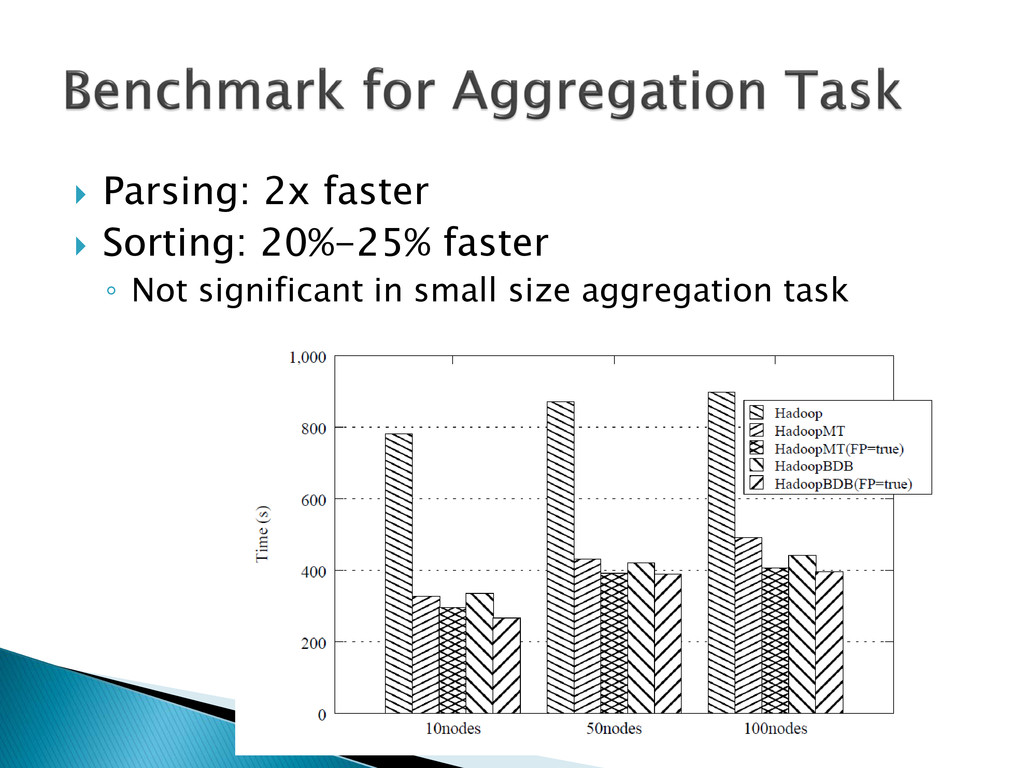{kind=link}
{kind=link}
{kind=link}