Software Engineer @ EMC Received PhD, Wayne State University Intern @ Microsoft, Data Domain Team Leader @ Actuate Received MS, SJTU ◦ Specialties Working on distributed storage systems during PhD Performance profiling.
Research Ph.D. Washington University B.S. and M.S. EE Dept, SJTU ◦ Research interest cloud services, internet measurements, erasure correction codes, distributed storage systems, peer-to-peer streaming, networking and multimedia communications. ◦ INFOCOM 2011 Public DNS System and Global Traffic Management Estimating the Performance of Hypothetical Cloud Service Deployments: A Measurement-Based Approach
ERA! Digital Universe 1.8 ZB (=1.8e9 TB) Several PBs photo stored on Facebook 14.1PB data stored on Taobao (2010) ◦ Data security is IMPORTANT Free from unwanted actions of unauthorized users. Free from data loss caused by destructive forces
operation GFS[1]: Hundreds or even thousands of machines Inexpensive commodity parts High concurrency/IO ◦ High failure tolerance, both for High availability and to prevent data loss [1] S. Ghemawat, H. Gobioff, and S.-T. Leung, “The Google file system,” in SOSP ’03: Proc. of the 19th ACM Symposium on Operating Systems Principles, 2003.
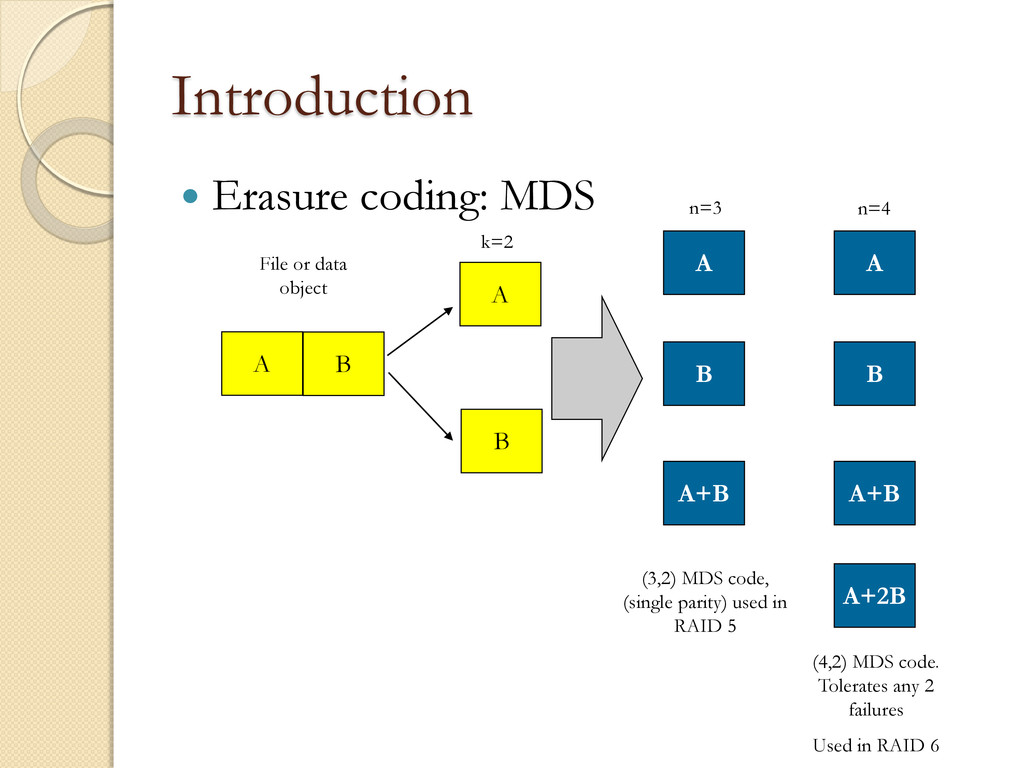
B A+2B A A+B A B (3,2) MDS code, (single parity) used in RAID 5 (4,2) MDS code. Tolerates any 2 failures Used in RAID 6 k=2 n=3 n=4 File or data object
B B A+B A+2B (4,2) MDS erasure code (any 2 suffice to recover) A B vs Erasure coding is introducing redundancy in an optimal way. Very useful in practice i.e. Reed-Solomon codes, Fountain Codes, (LT and Raptor)… Replication File or data object [3]A. G. Dimakis, P. G. Godfrey, Y. Wu, M. J. Wainwright, and K. Ramchandran,“Network coding for distributed storage systems,” in IEEE Trans. on Inform. Theory, vol. 56, pp. 4539 – 4551, Sep. 2010.
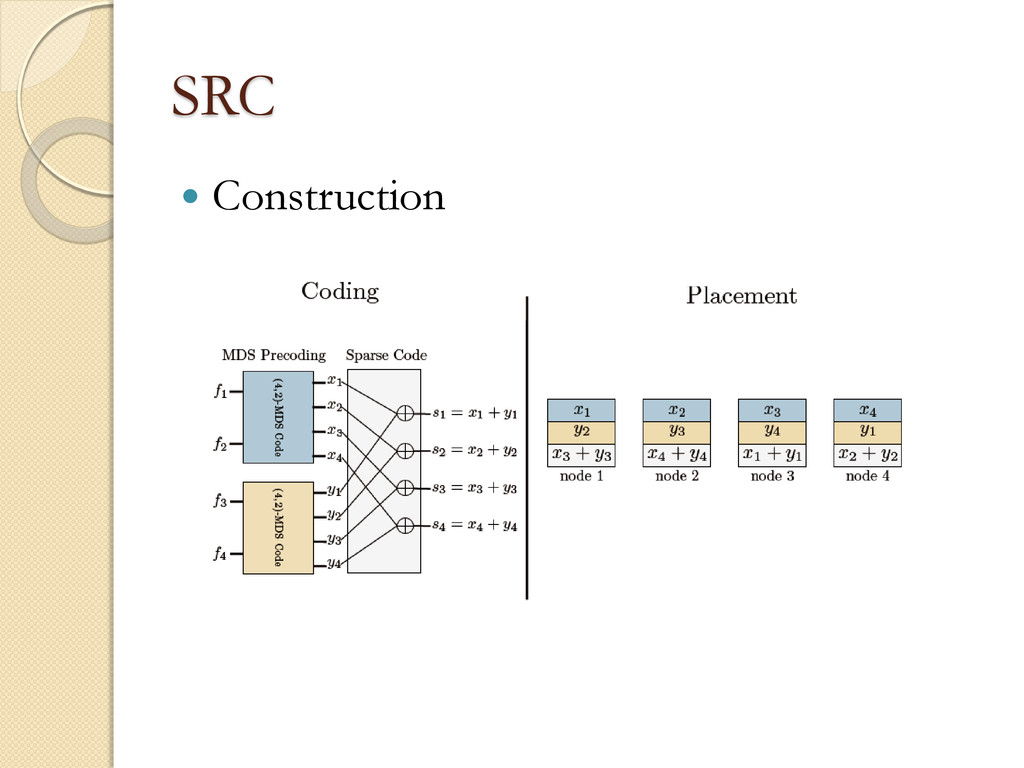
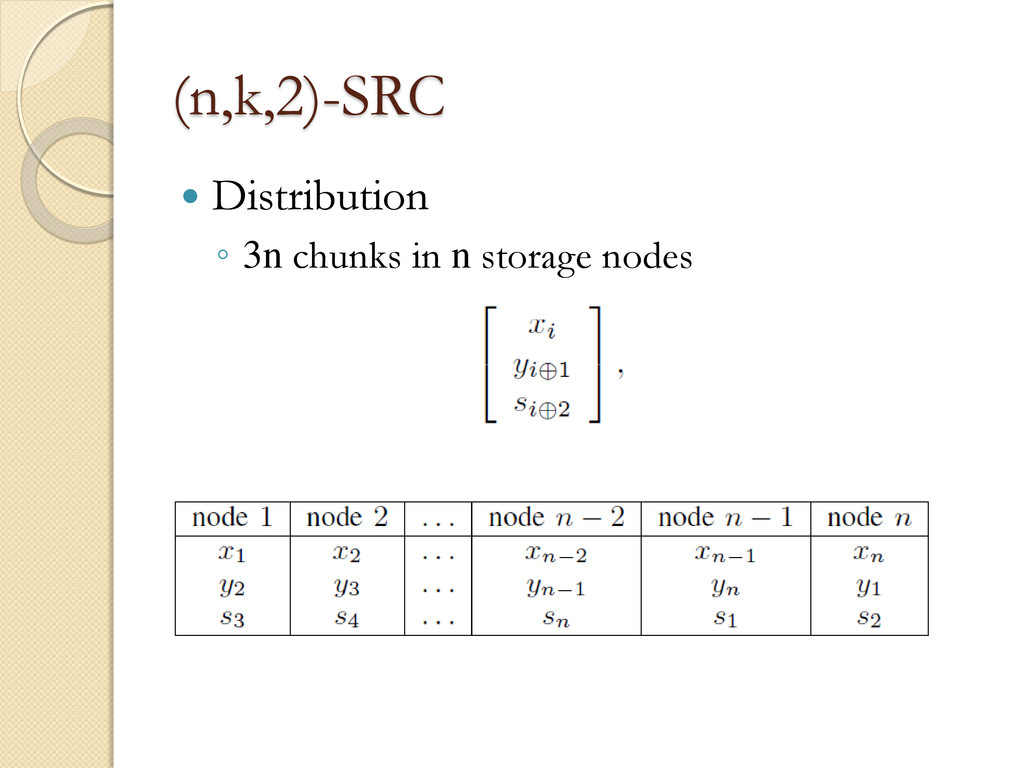
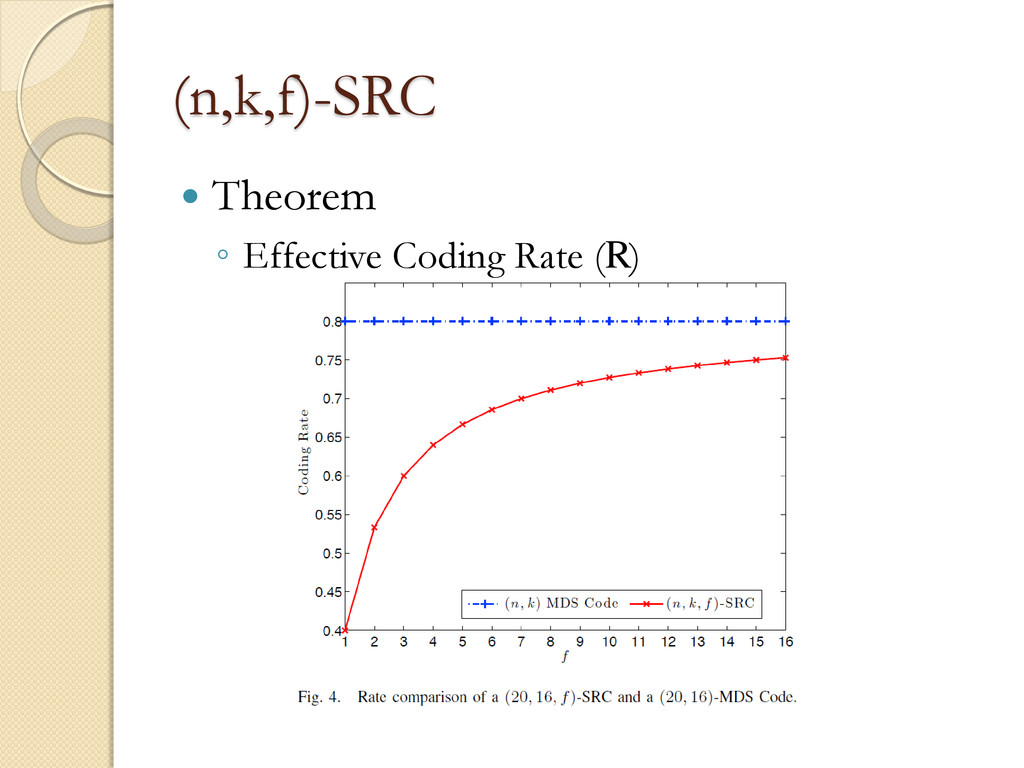
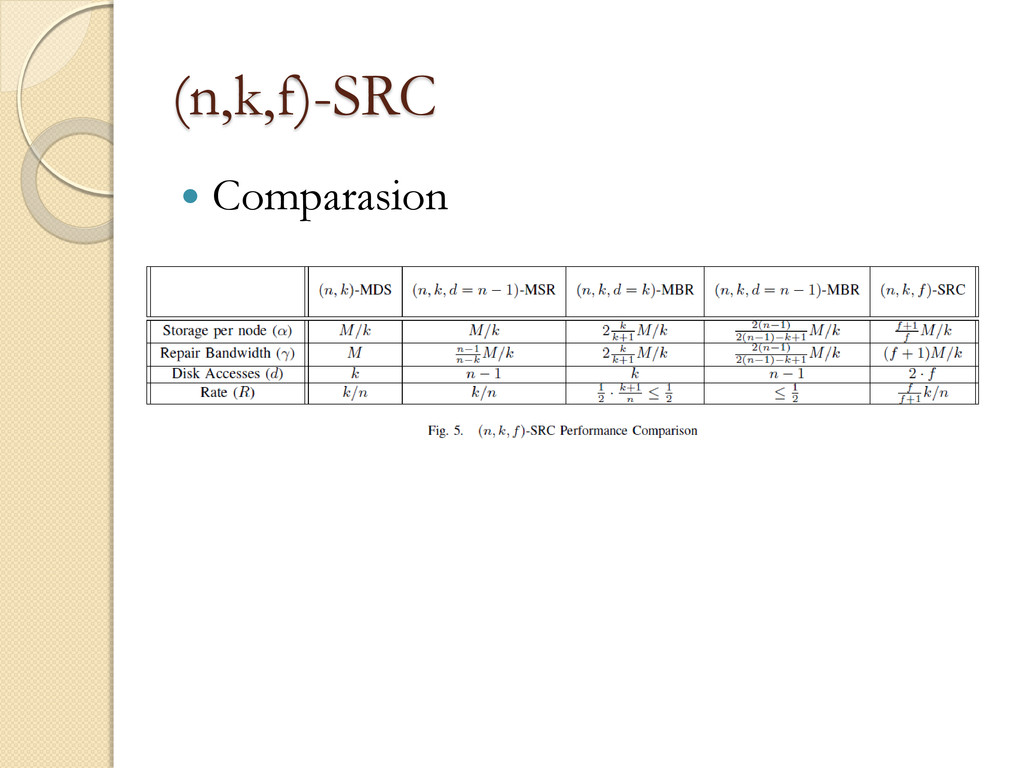
Bandwidth per single node repair (γ) ◦ Disk Accesses per single node repair (d) ◦ Effective Coding Rate (R) Contribution ◦ High R, Small d ◦ Low repair computation complexity
address the issue of rebuilding (also called repairing) lost encoded fragments from existing encoded fragments. This issue arises in distributed storage systems where communication to maintain encoded redundancy is a problem.
MDS[2] [2] Alexandros G. Dimakis, Kannan Ramchandran, Yunnan Wu, Changho Suh: A Survey on Network Codes for Distributed Storage. in Proceedings of the IEEE, 2011
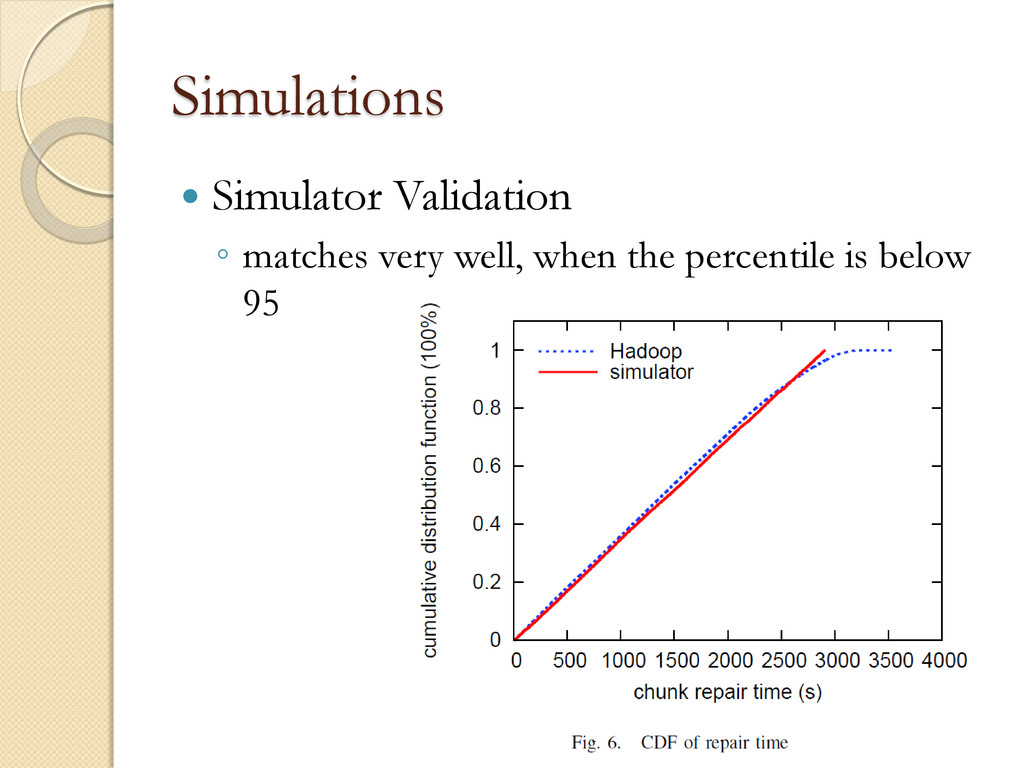
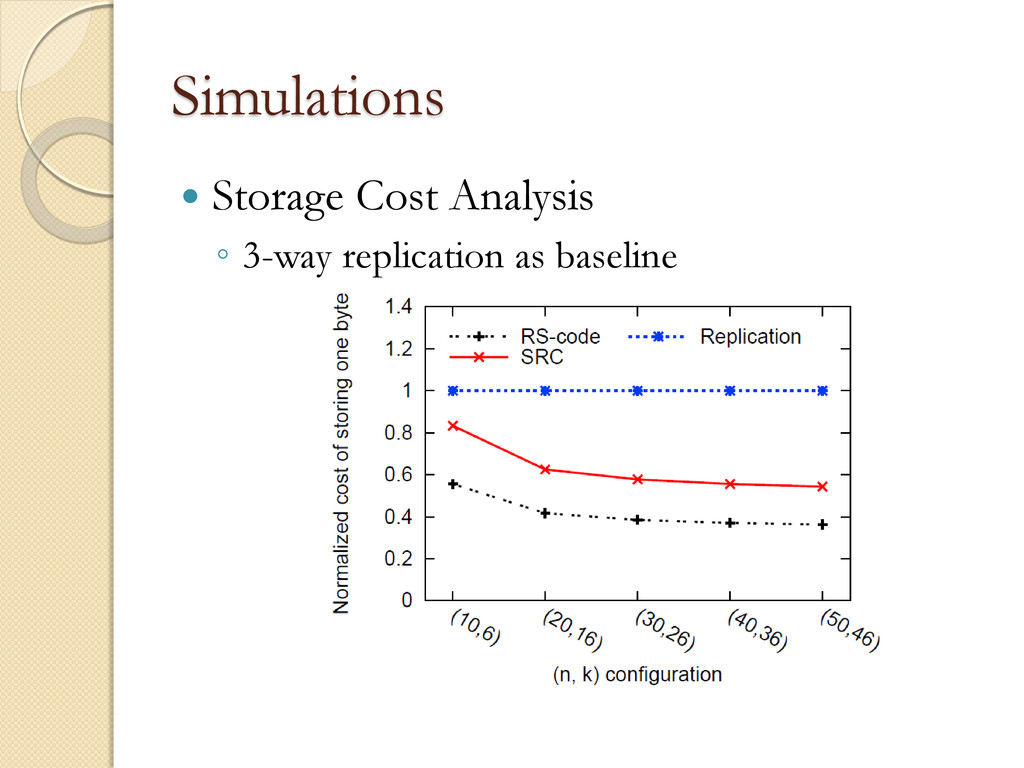
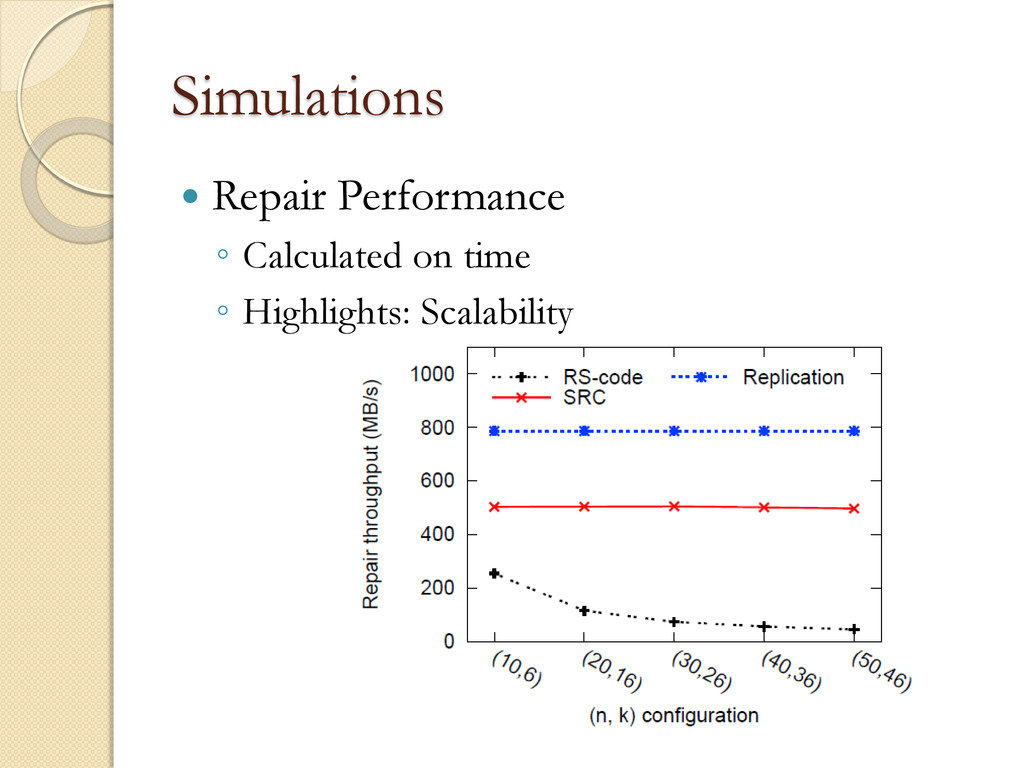
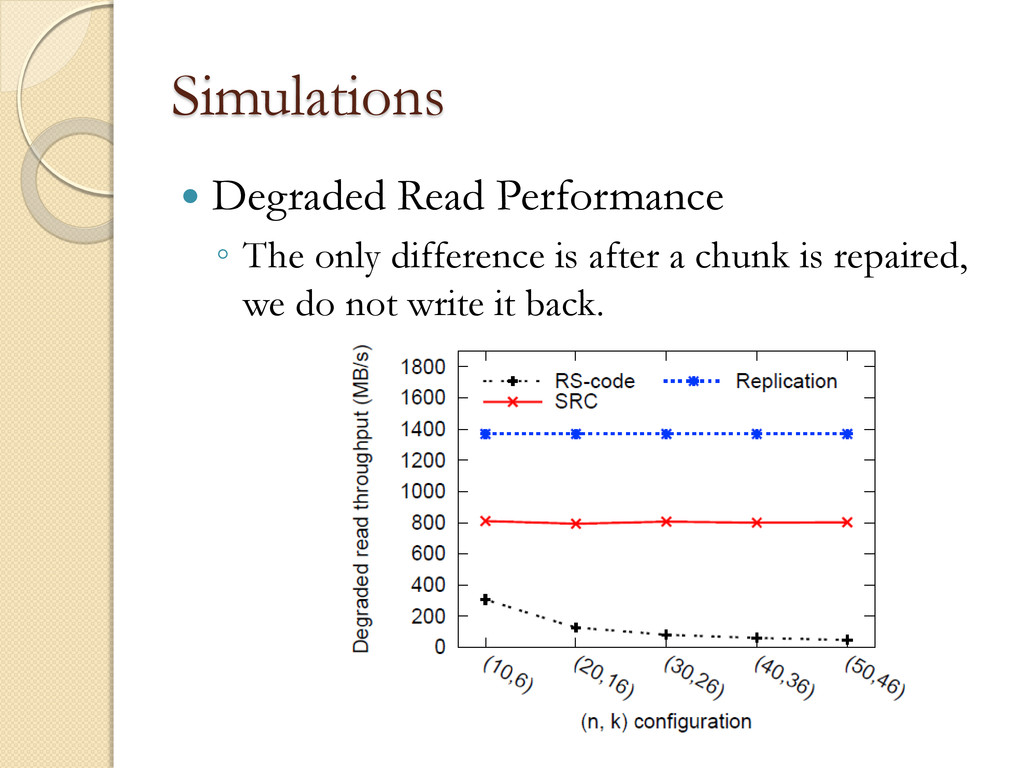
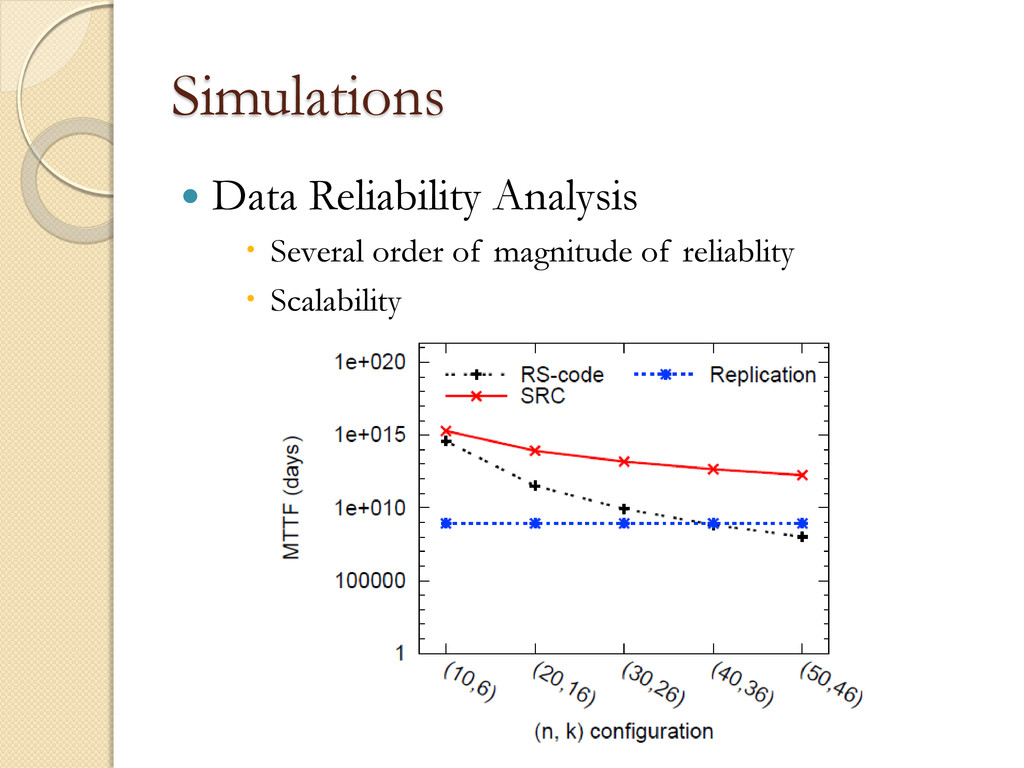
◦ Chunks form the smallest accessible data units and in our system are set to be 64MB Simulator Validation ◦ 16 machines ◦ 1Gbps network. ◦ 410GB data per machine ◦ Approximately 6400 chunks
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Introduction Erasure coding vs. Replica[3] A B A A](https://files.speakerdeck.com/presentations/b00212409ddb0130fb9f62f0e76f3894/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}