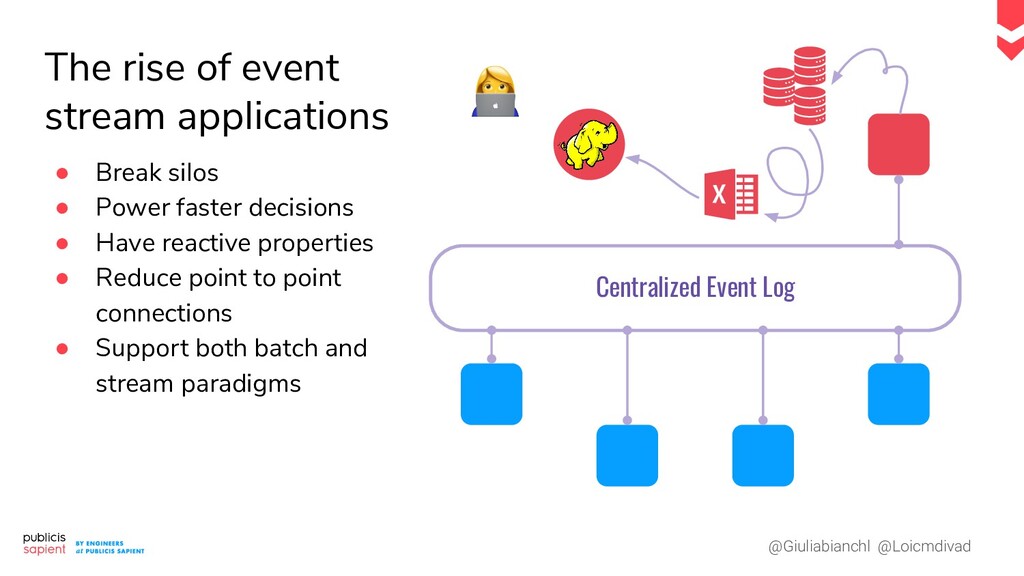
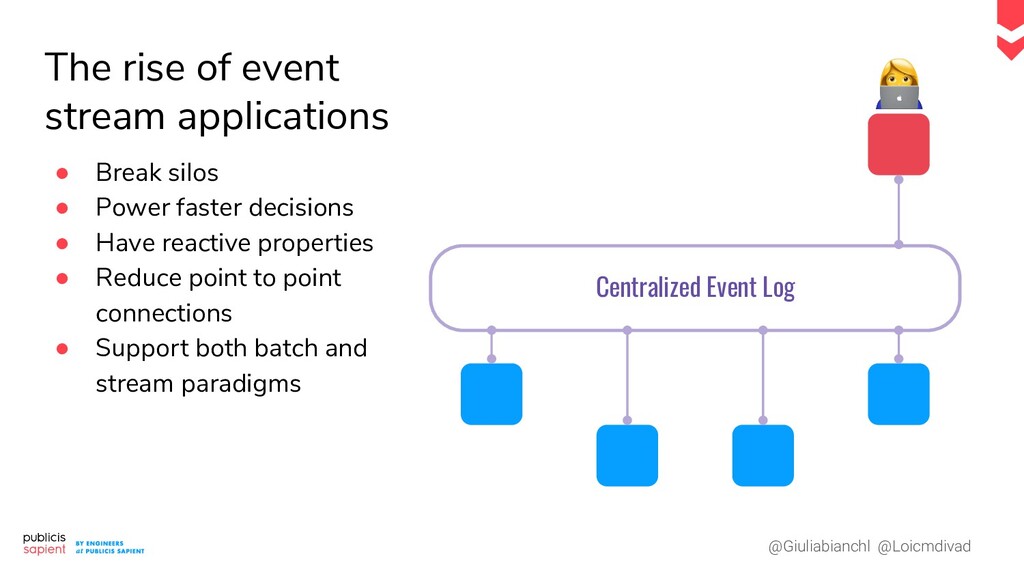
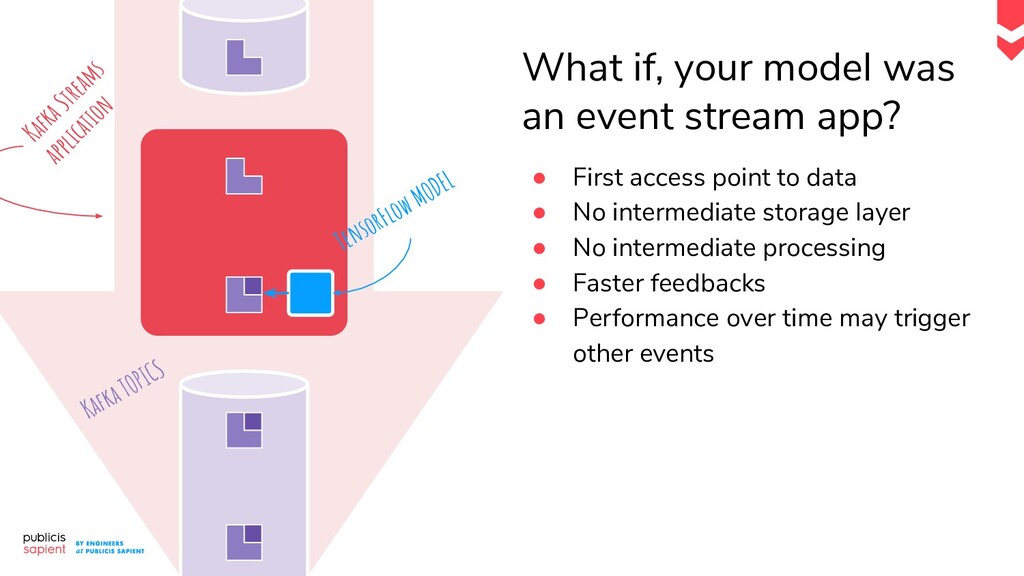
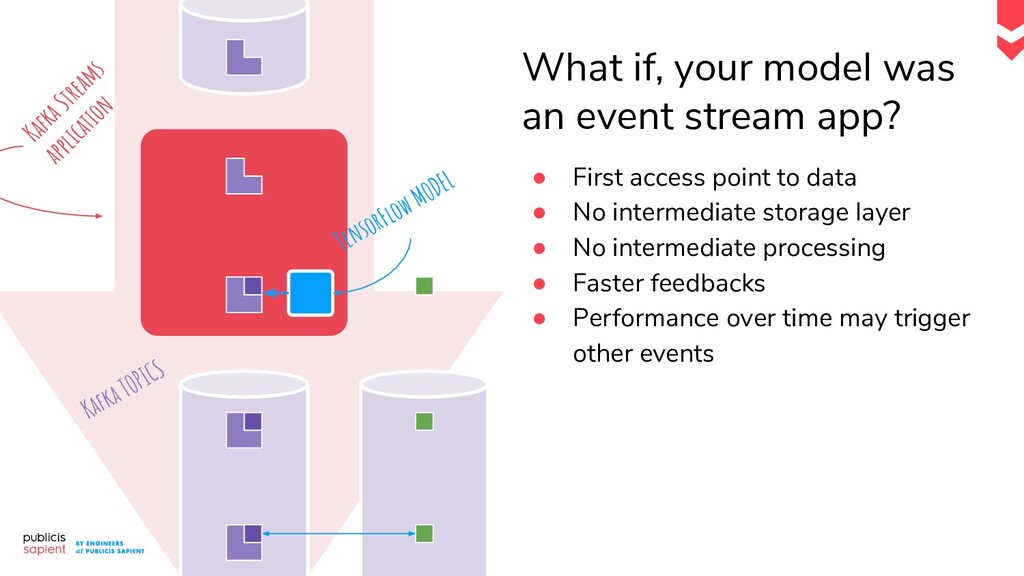
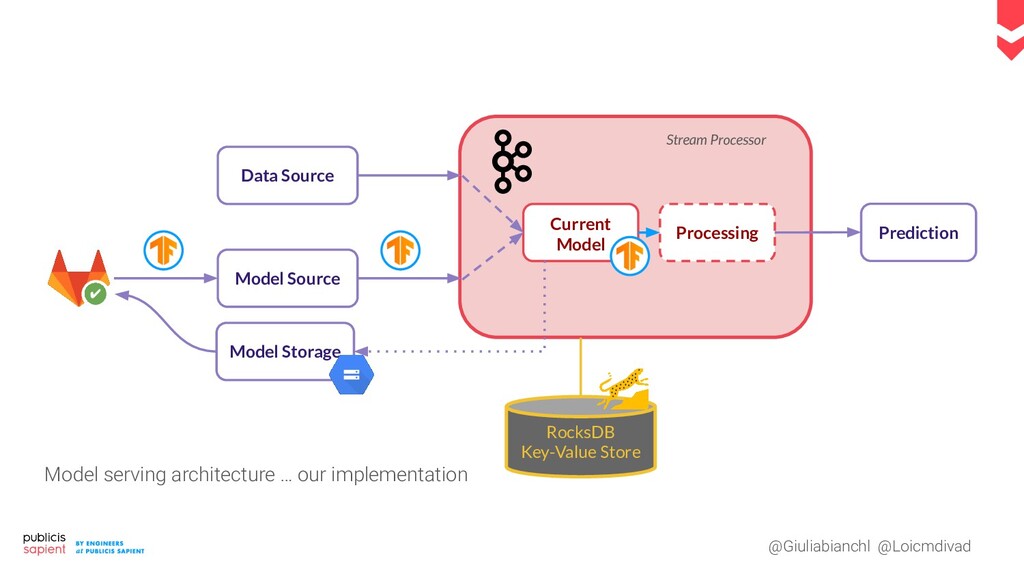
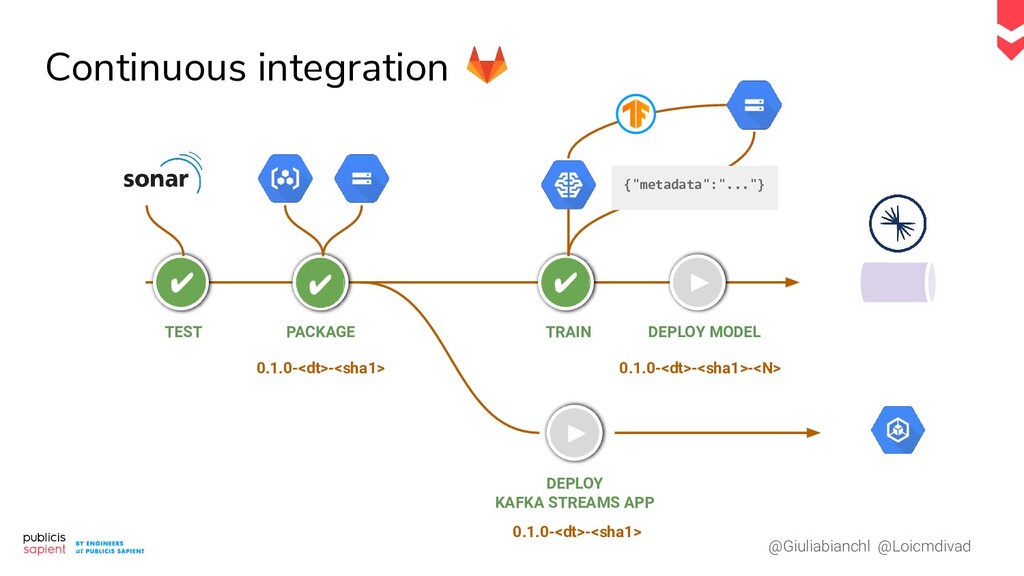
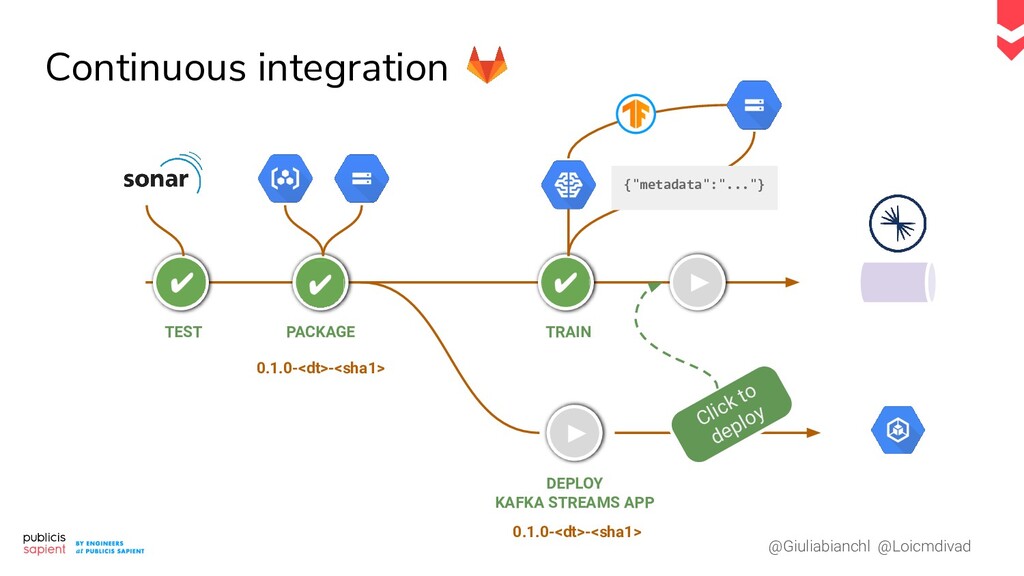
Le serving de modèle de Machine Learning pour la prédiction en temps réel présente des défis tant en Data Engineering qu'en Data Science. Comment construire un pipeline moderne qui permet de réaliser des prédictions en continu ? Dans le cas d'un exercice supervisé, comment allier tracing et tracking des performances ? Comment récupérer un feedback pour déclencher un réentraînement réactif ?
Dans ce talk nous vous proposons de dresser, ensemble, une proposition concrète de pipeline, qui prend en compte les phases d'exploration et de monitoring dans un contexte temps réel. Les ingrédients : un event log, une plateforme notebook et d'autres surprises nous venant tout droit du Cloud.
{kind=link}
{kind=link}
{kind=link}
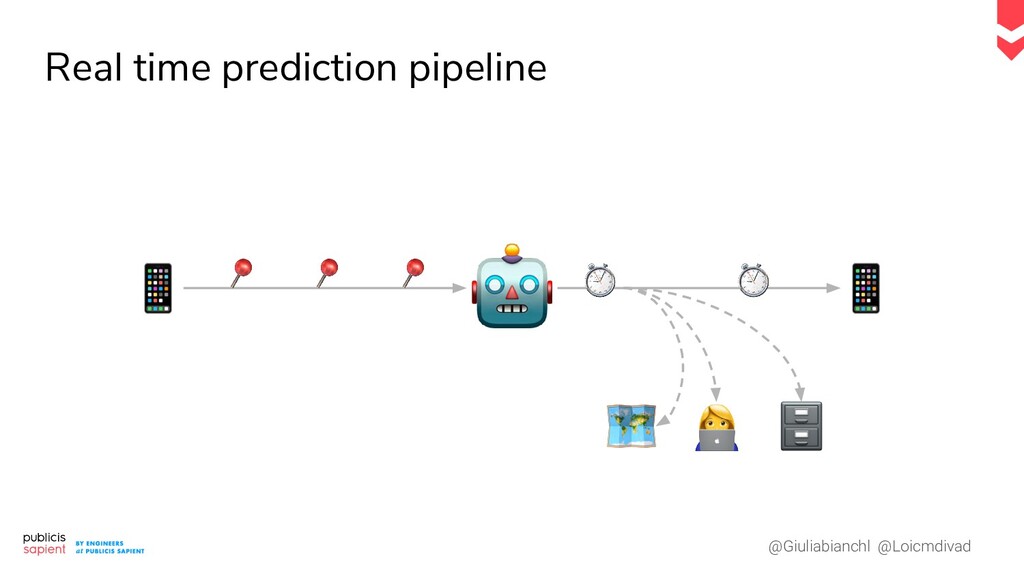{kind=link}
{kind=link}
{kind=link}
{kind=link}
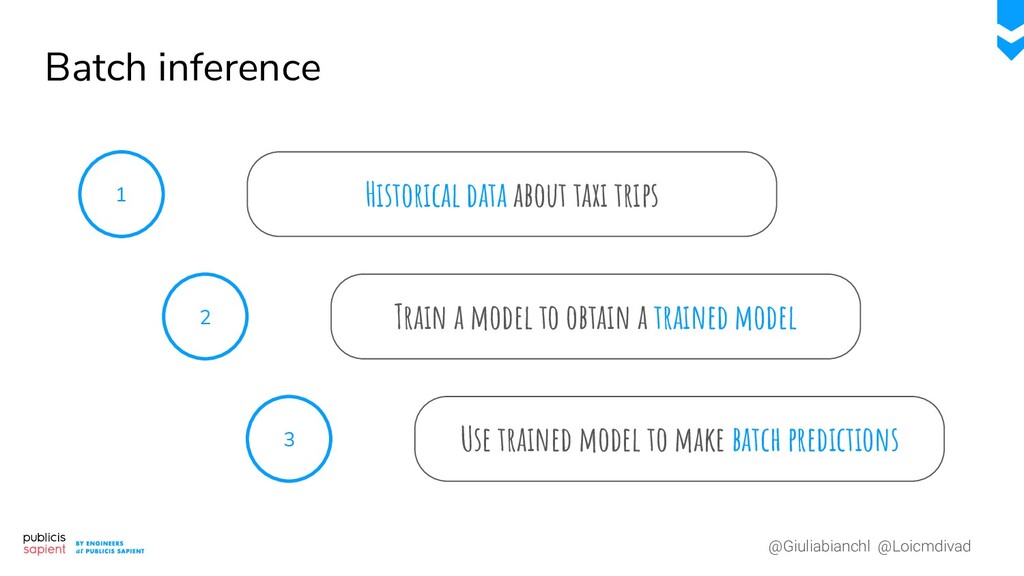{kind=link}
{kind=link}
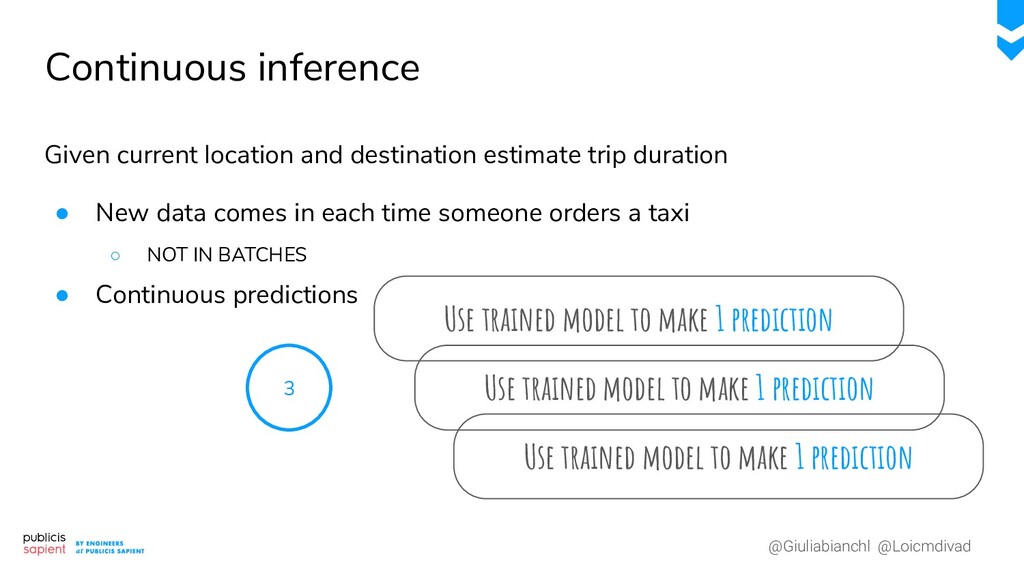{kind=link}
{kind=link}
{kind=link}
{kind=link}
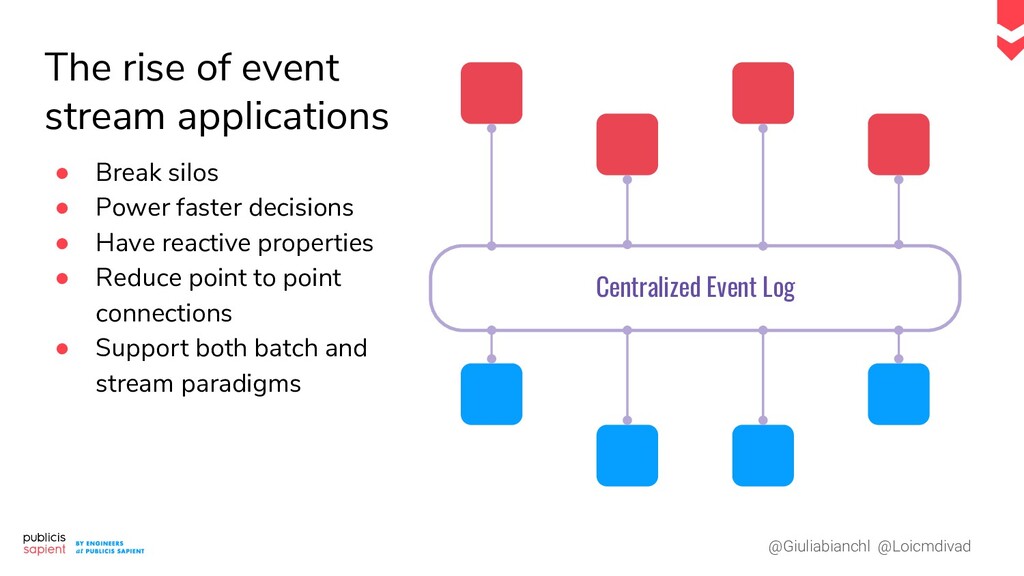{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}