String = "<model.topic>" val version: String = "<model.version>" val model: String = "gs://.../<model.version>" //… val producer = new KafkaProducer[_, TFSavedModel](... val key = ModelKey("<app.name>") val value = TFSavedModel(… //… producer.send(topic, key, value) producer.flush()
Dimon Blr on Unsplash Photo by Lerone Pieters on Unsplash Photo by Miryam León on Unsplash Photo by Matthew Hamilton on Unsplash Photo by Luke Stackpoole on Unsplash Photo by Gustavo on Unsplash Photo by Negative Space from Pexels Photo by Gerrie van der Walt on Unsplash Photo by Eepeng Cheong on Unsplash Photo by Rock'n Roll Monkey on Unsplash Photo by chuttersnap on Unsplash Photo by Denys Nevozhai on Unsplash Photo by Mike Tsitas on Unsplash
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
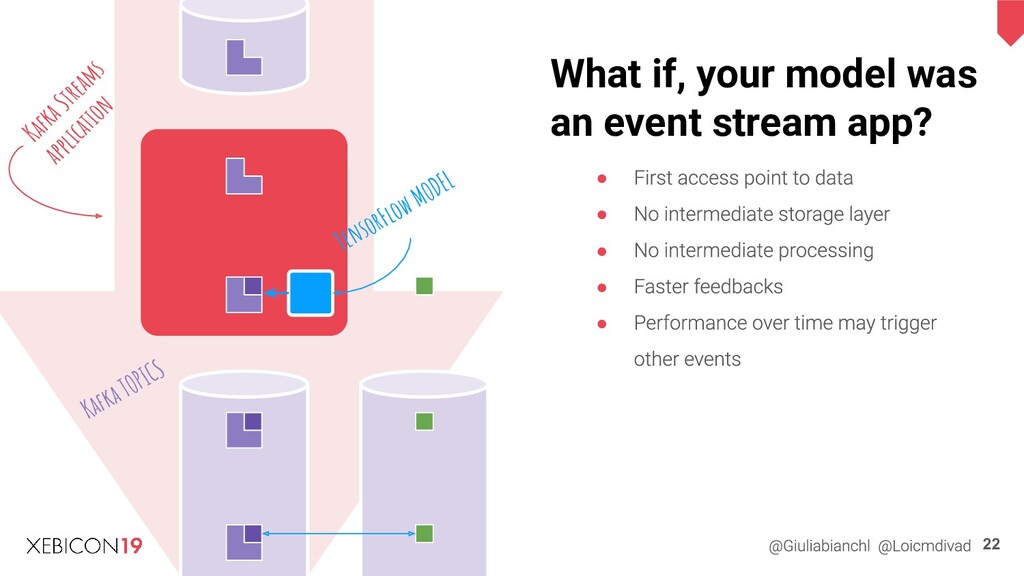{kind=link}
{kind=link}
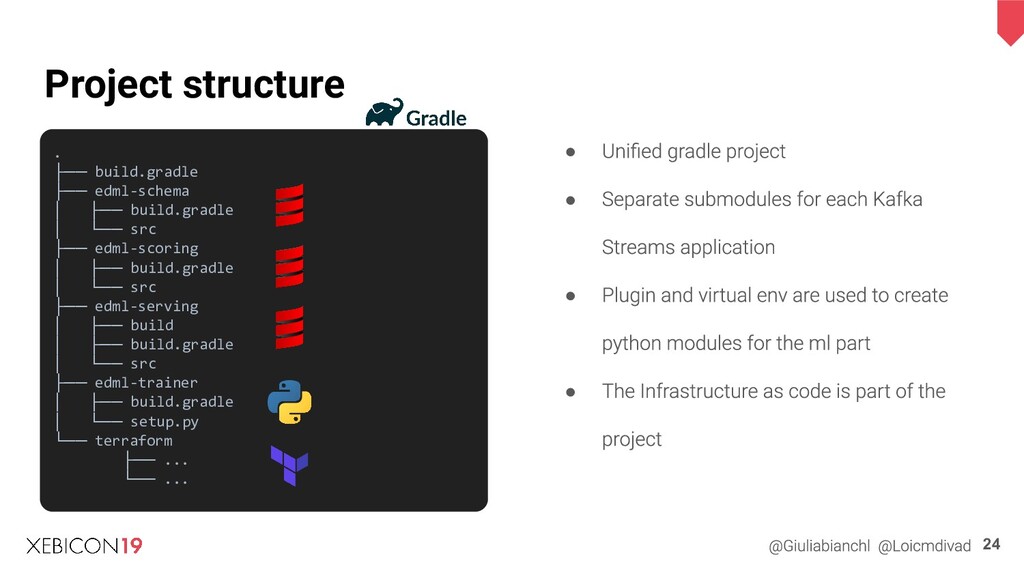{kind=link}
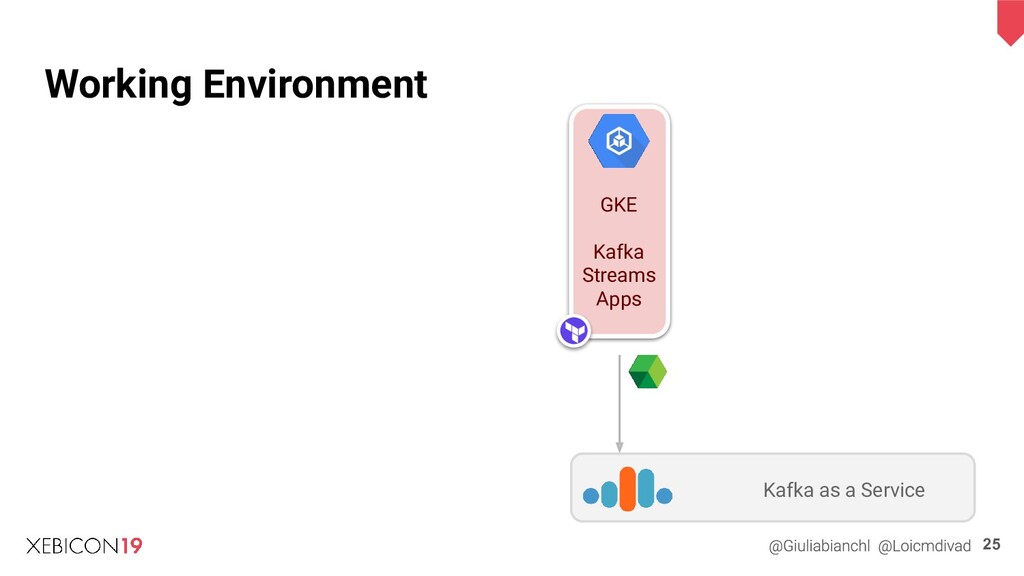{kind=link}
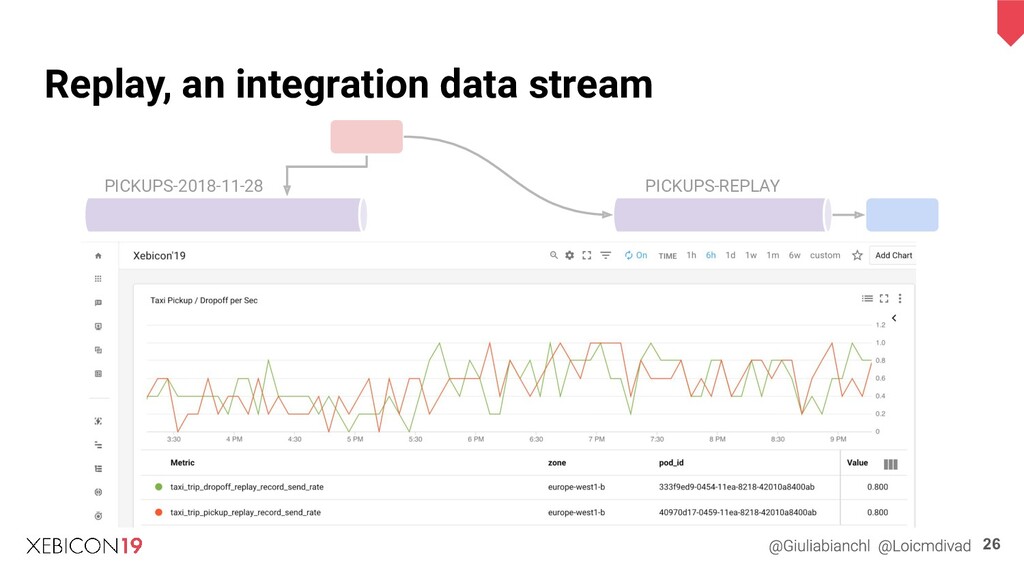{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}