shell script to open connections 2. write another script to send messages 3. run system locally or on a benchmarking cluster 4. start generating load 5. pray for results to be good
you probably don’t gather enough metrics 3. you might be doing too many things at once 4. you can’t be sure your script is not the bottleneck 5. altering scripts is time-consuming and error-prone 6. distributing scripts to vary the load is awkward
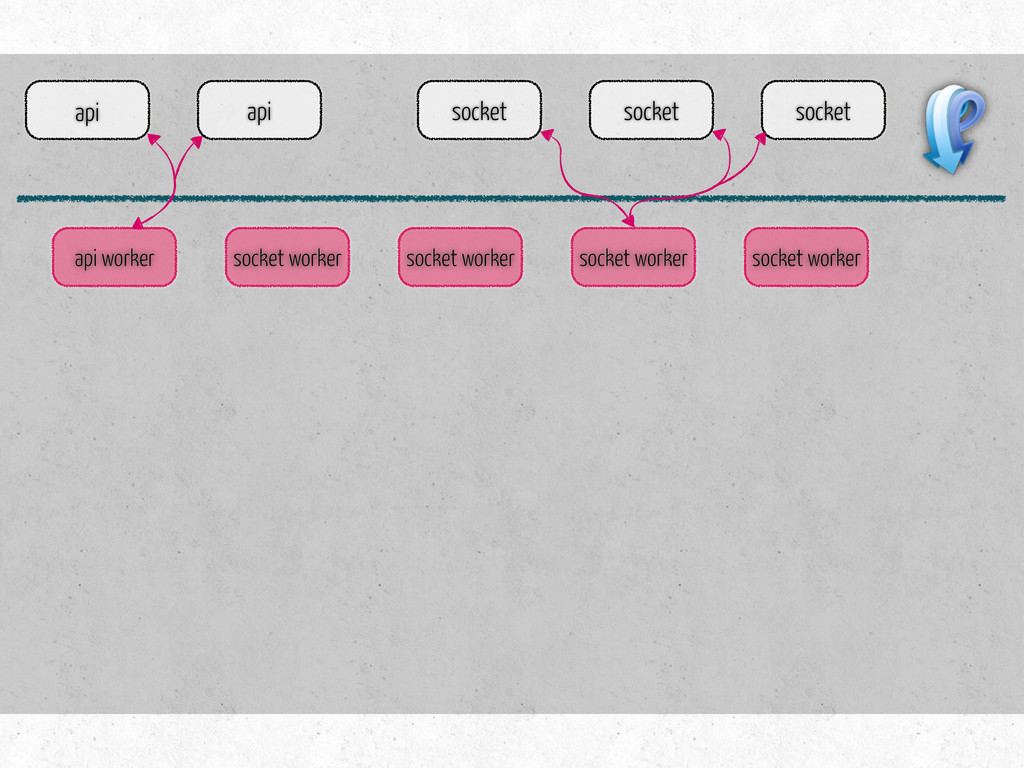
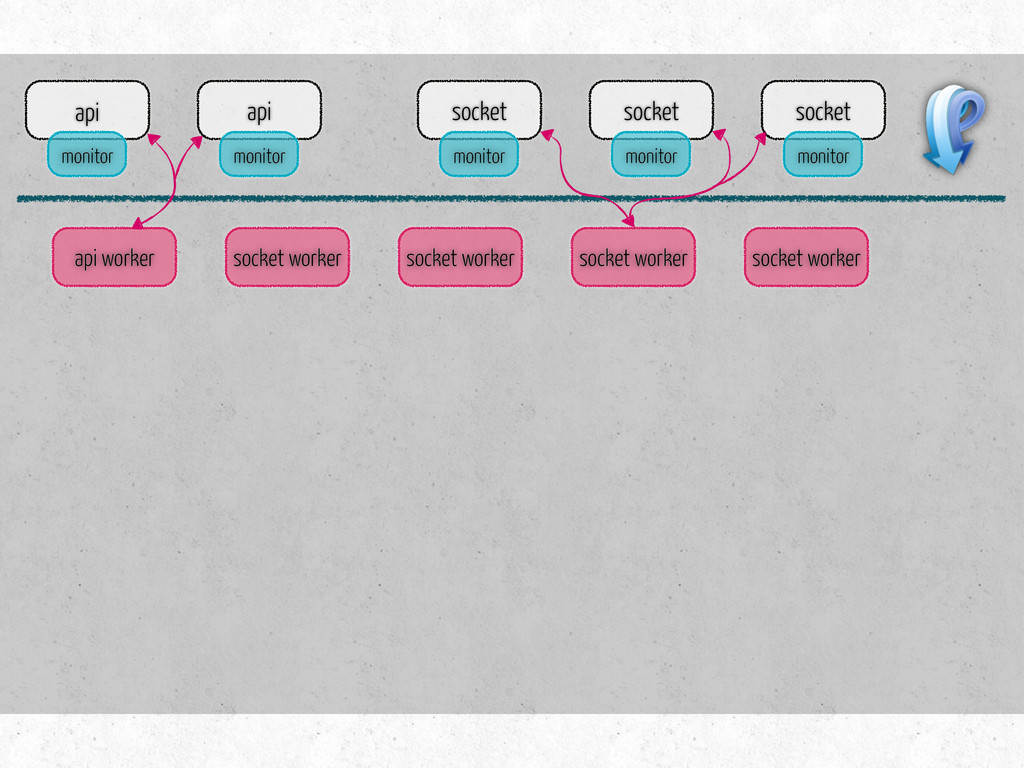
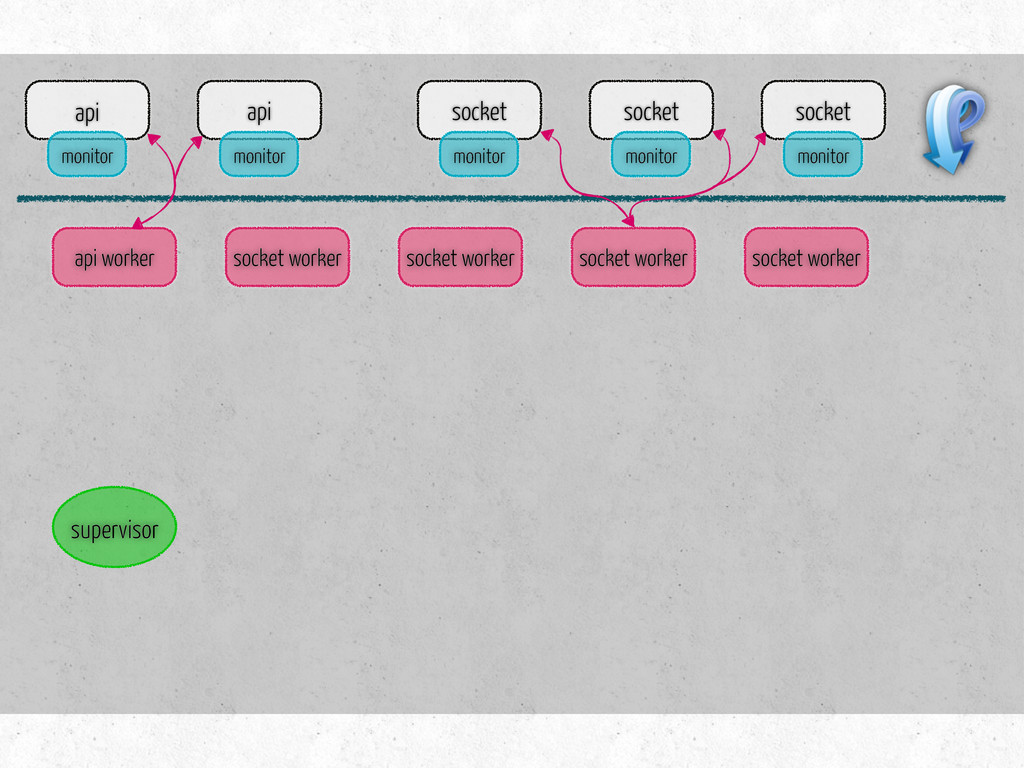
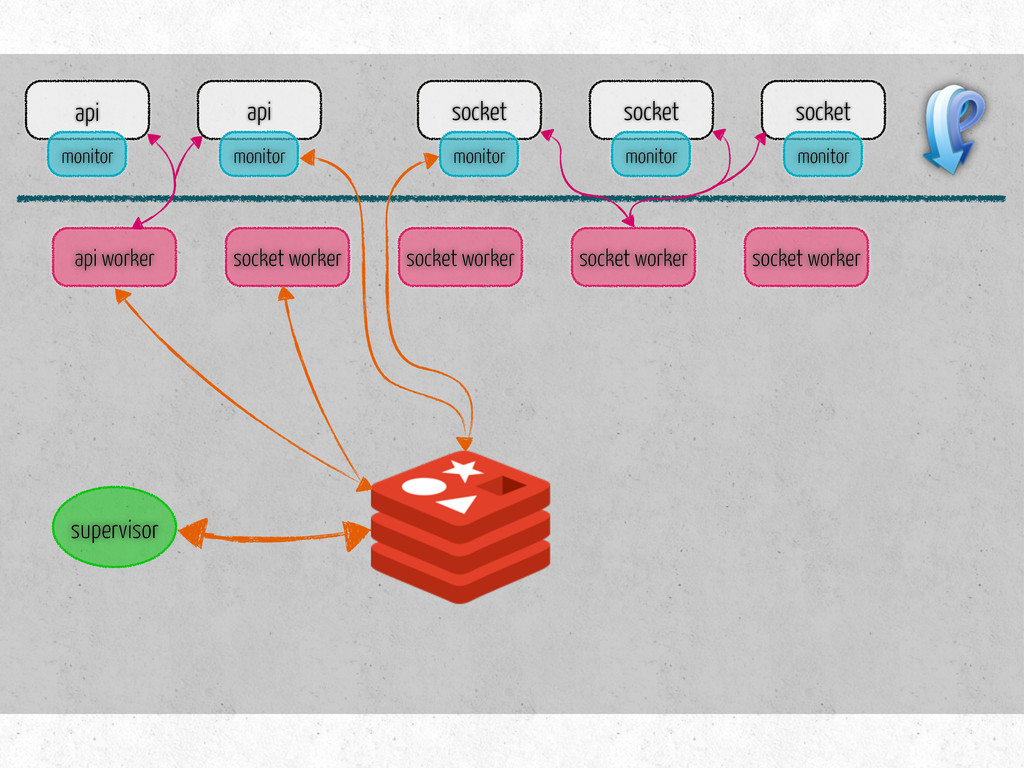
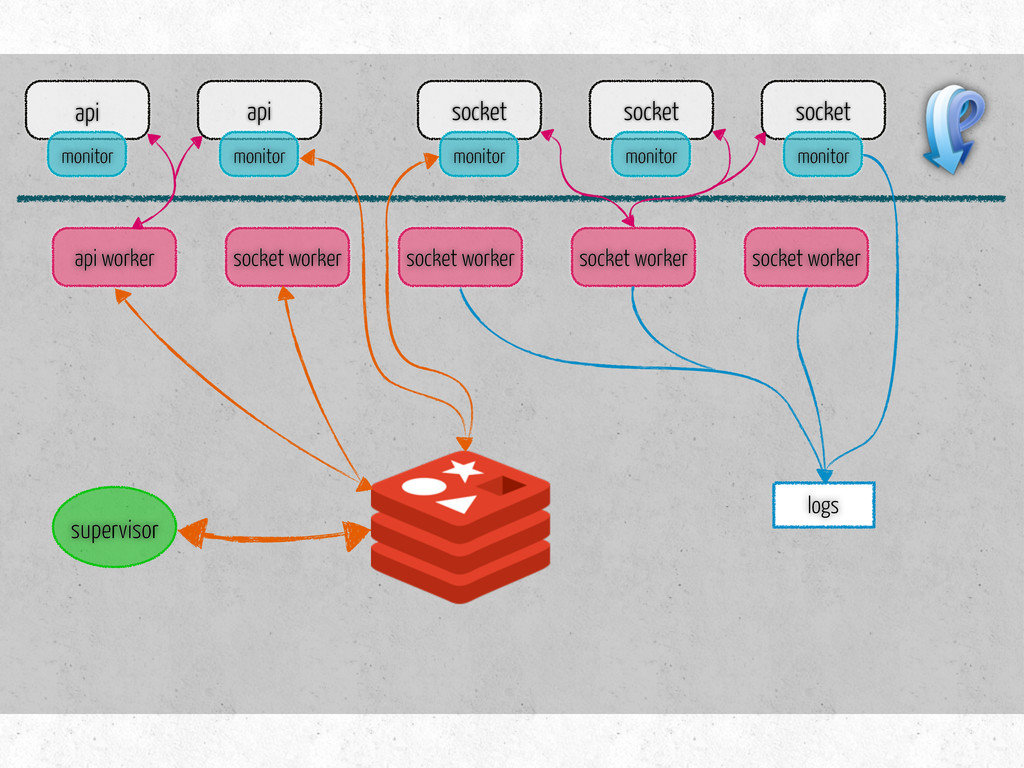
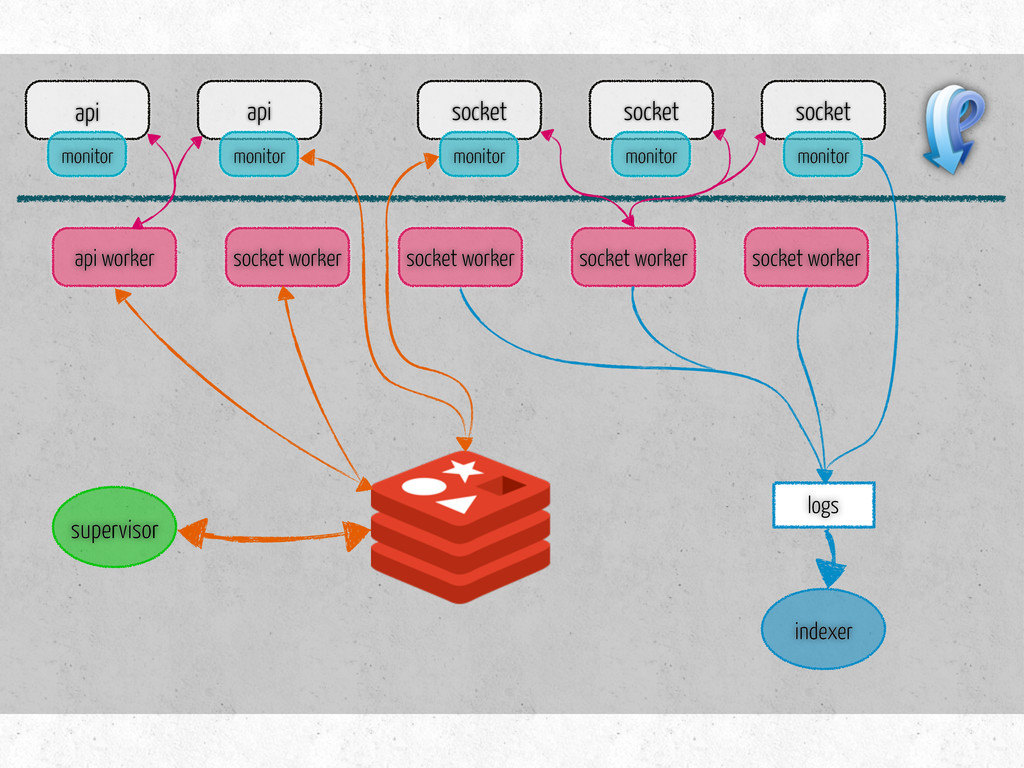
number of connections per channel socket/api hosts, keys number of workers of each type per host list of tasks for each type of workers metrics to collect on workers monitor hosts metrics to collect on monitors steps to prepare for benchmark
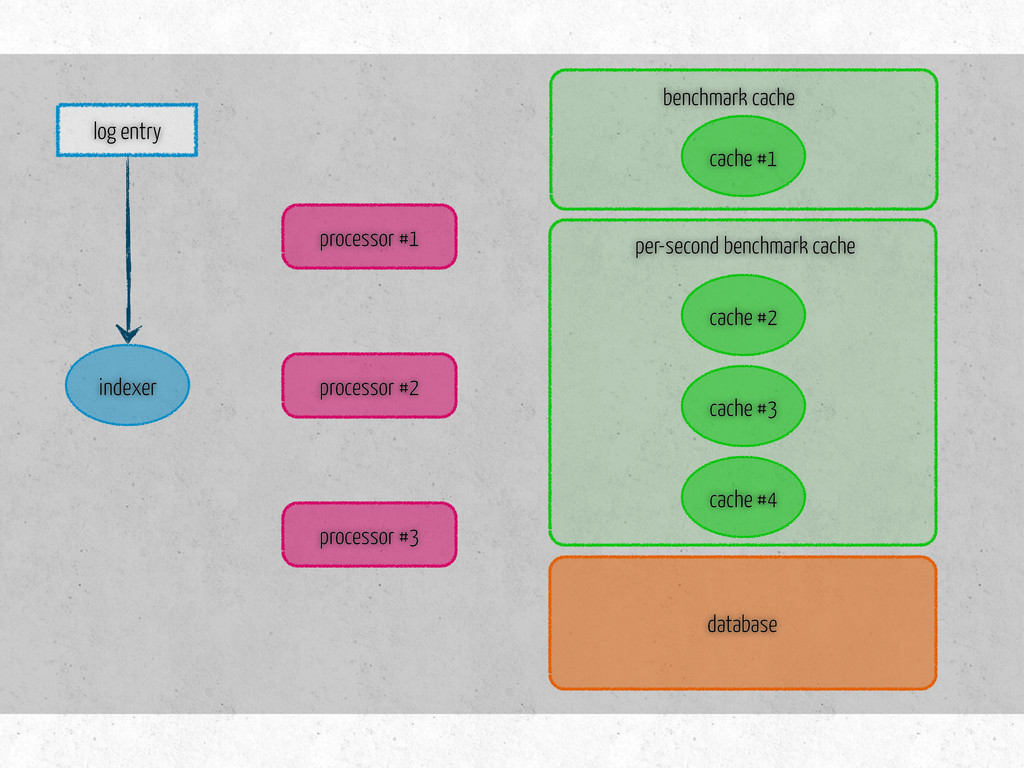
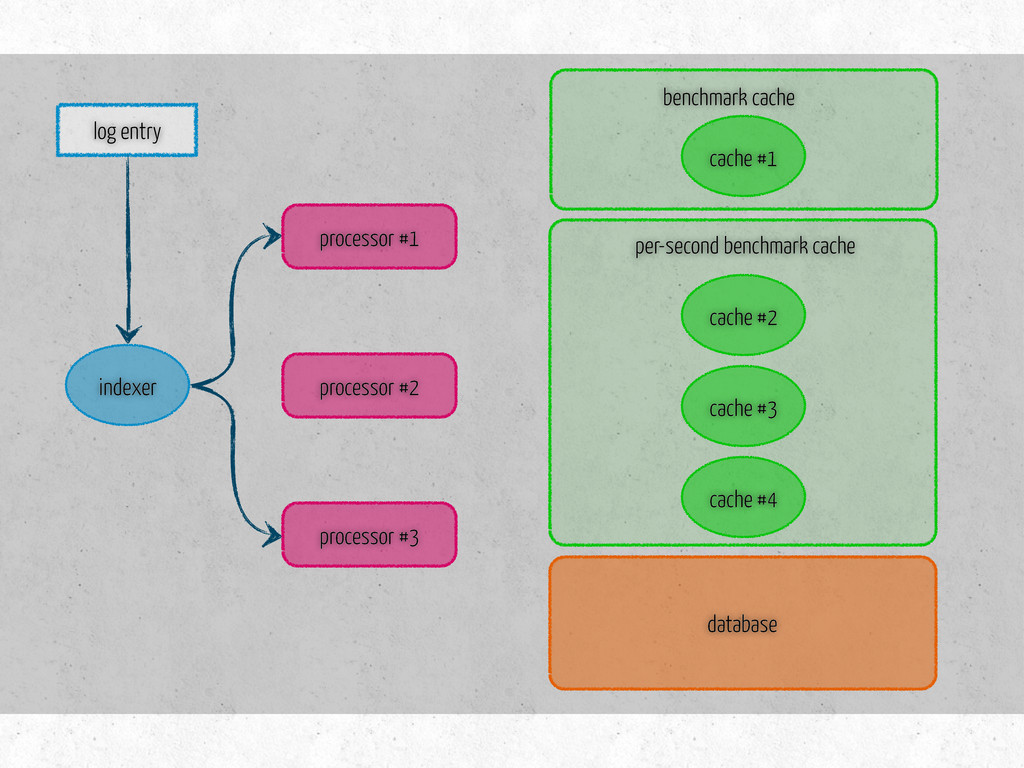
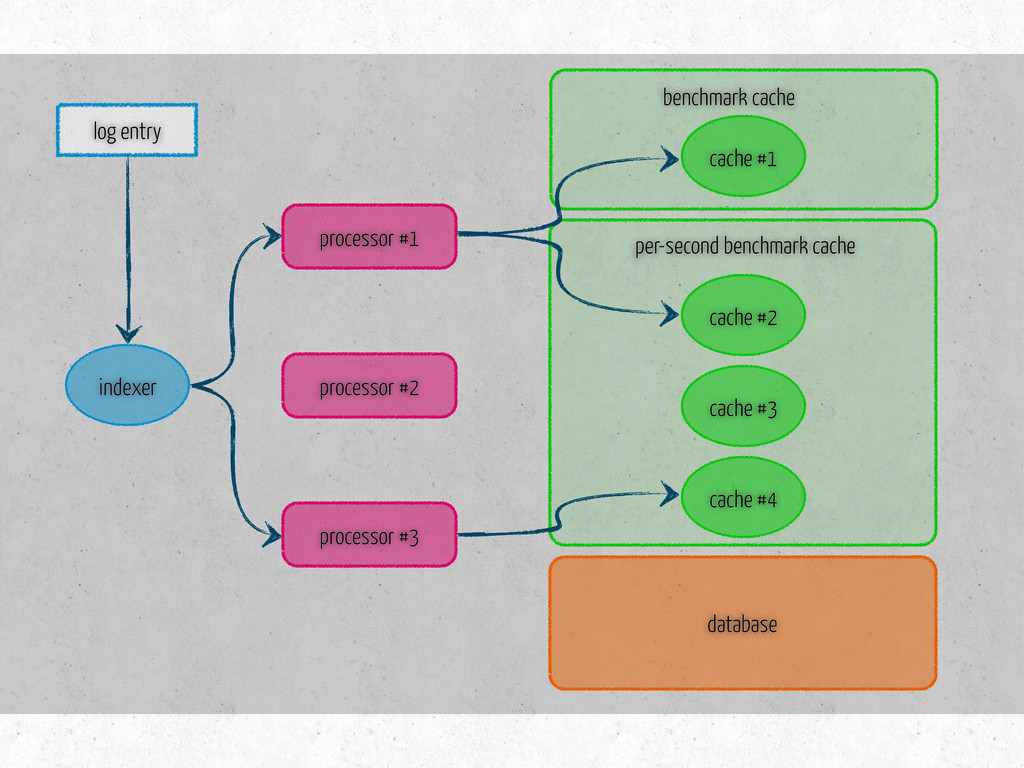
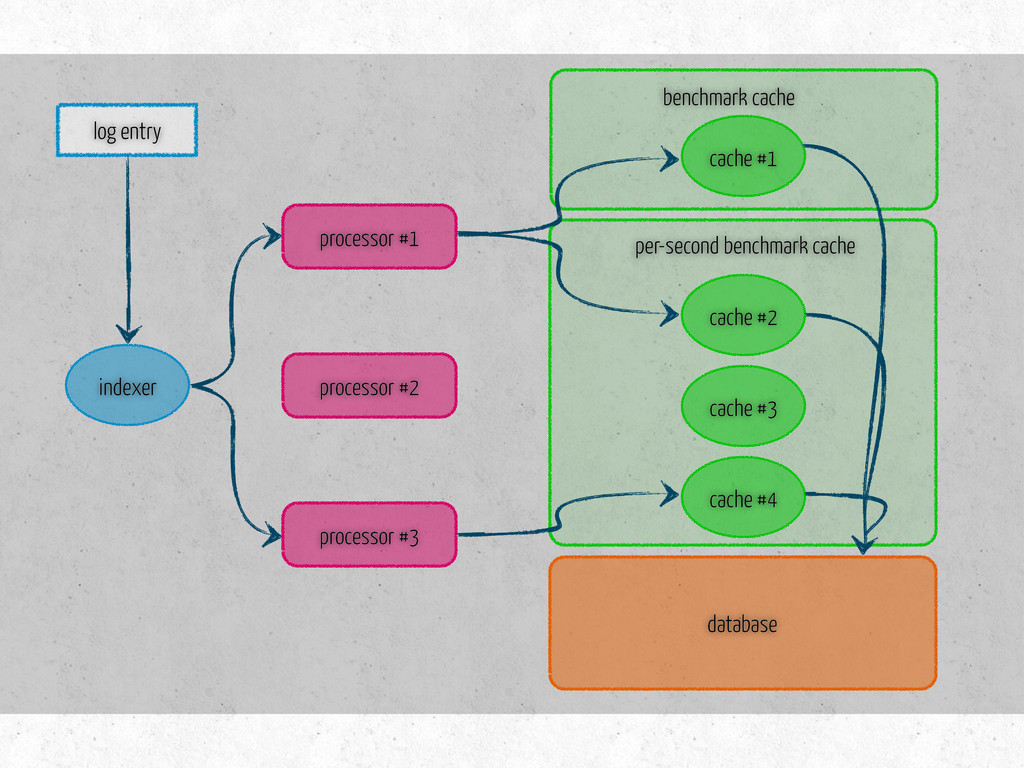
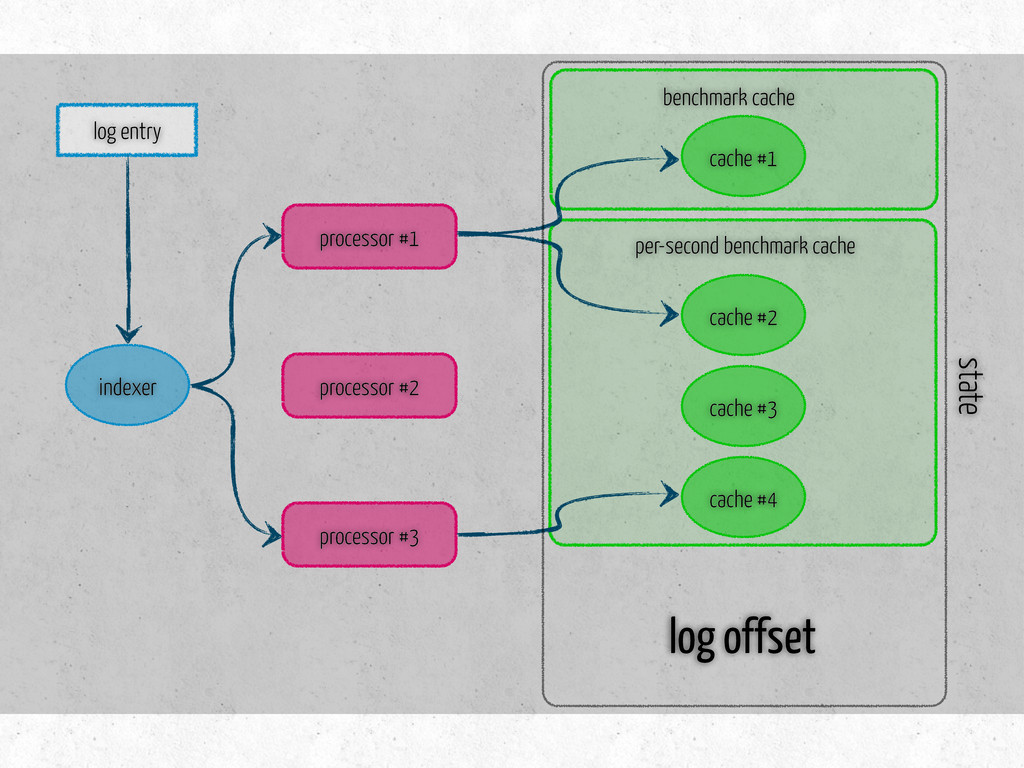
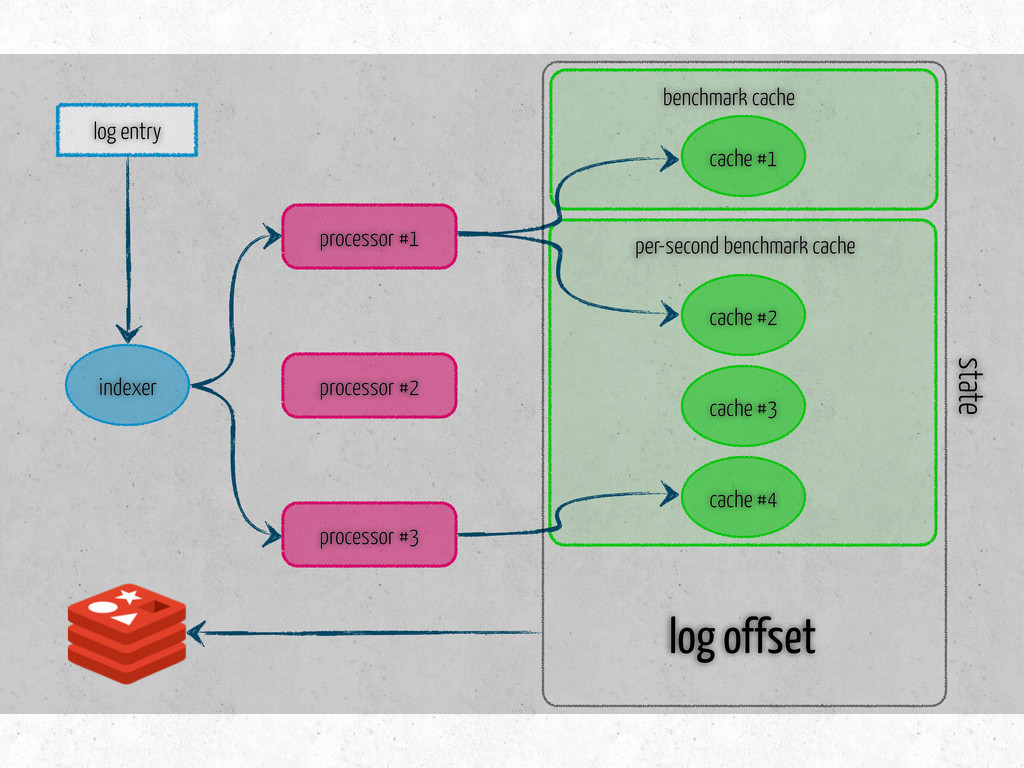
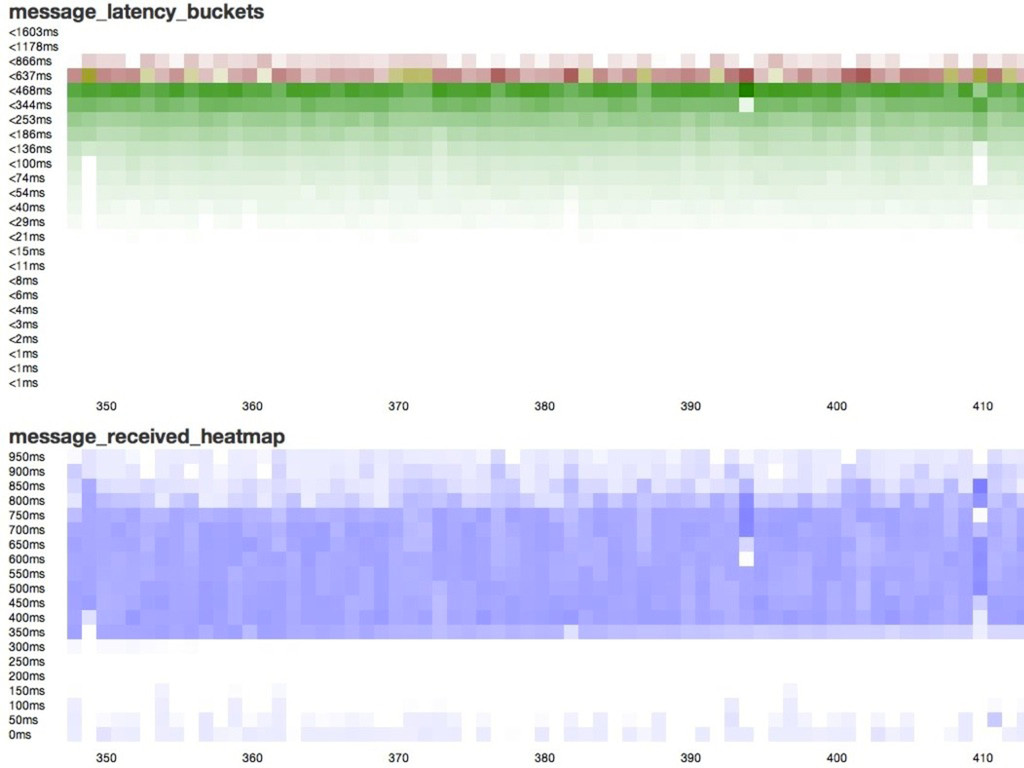
time per-second: message latency fetches existing data on initialization three methods update – metric specific store – saves data in the db is dirty? – true if modified since last store
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}