変化のスピードが加速する生成AI時代において、企業が押さえるべき生成AIガバナンスの要点を俯瞰的に解説します。そのうえで、AIエージェントに特有のセキュリティ課題に焦点を当てます。
生成AIの急速な普及はリスク評価を難しくし、さらに敵対的攻撃、ジェイルブレイク、プロンプトインジェクション、バックドア攻撃など多様な脅威が拡大しています。特に、LLMを基盤としたエージェントは接点が増えることで攻撃の起点も広がり、従来のLLM単体利用とは異なる複雑なリスクに直面しています。
本講演では、最近報告された脆弱性の事例を踏まえつつ、多層防御の重要性を強調するとともに、歴史的に培われた情報システムのセキュリティ設計原則が依然として有効であることを示します。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
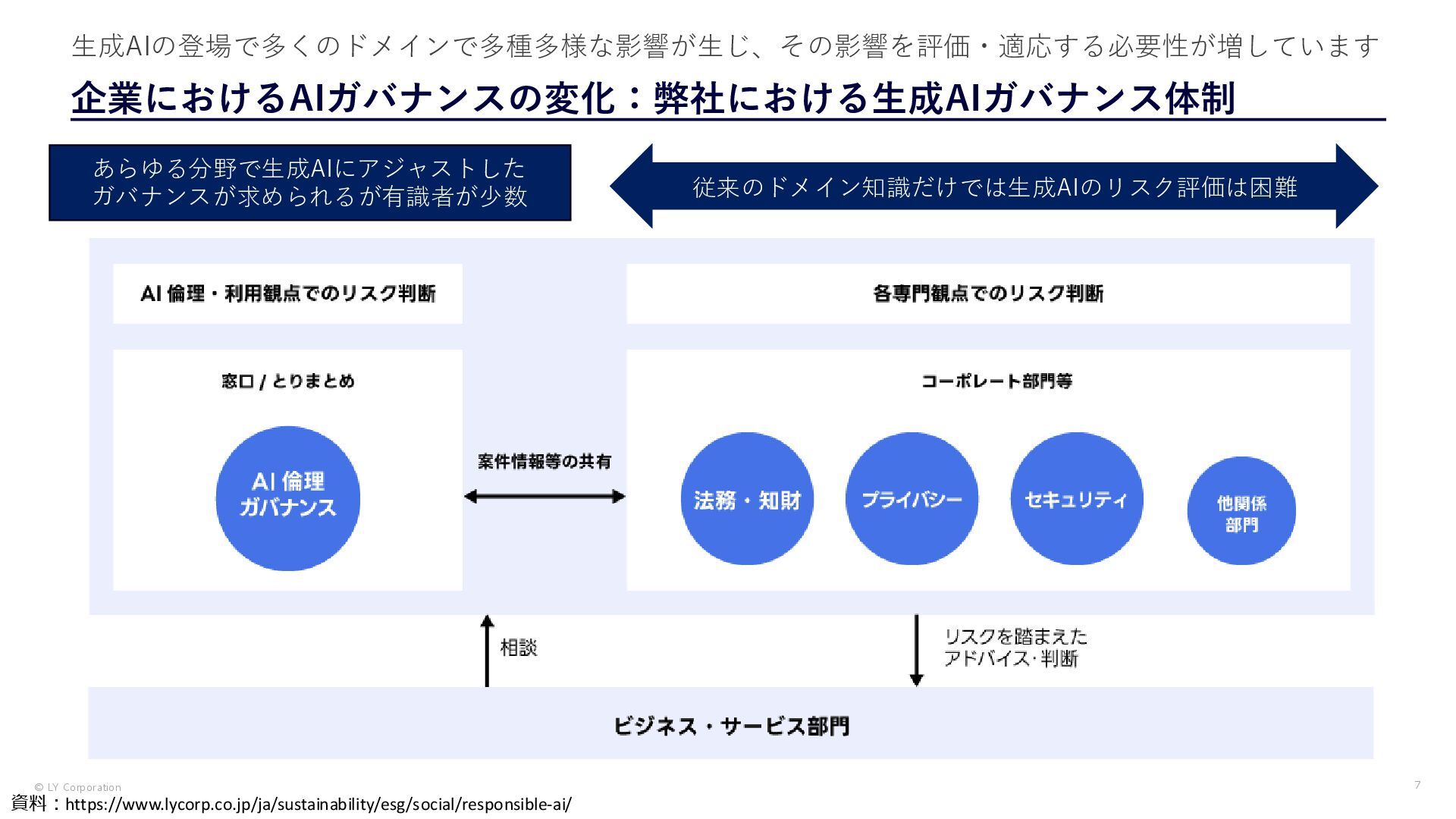{kind=link}
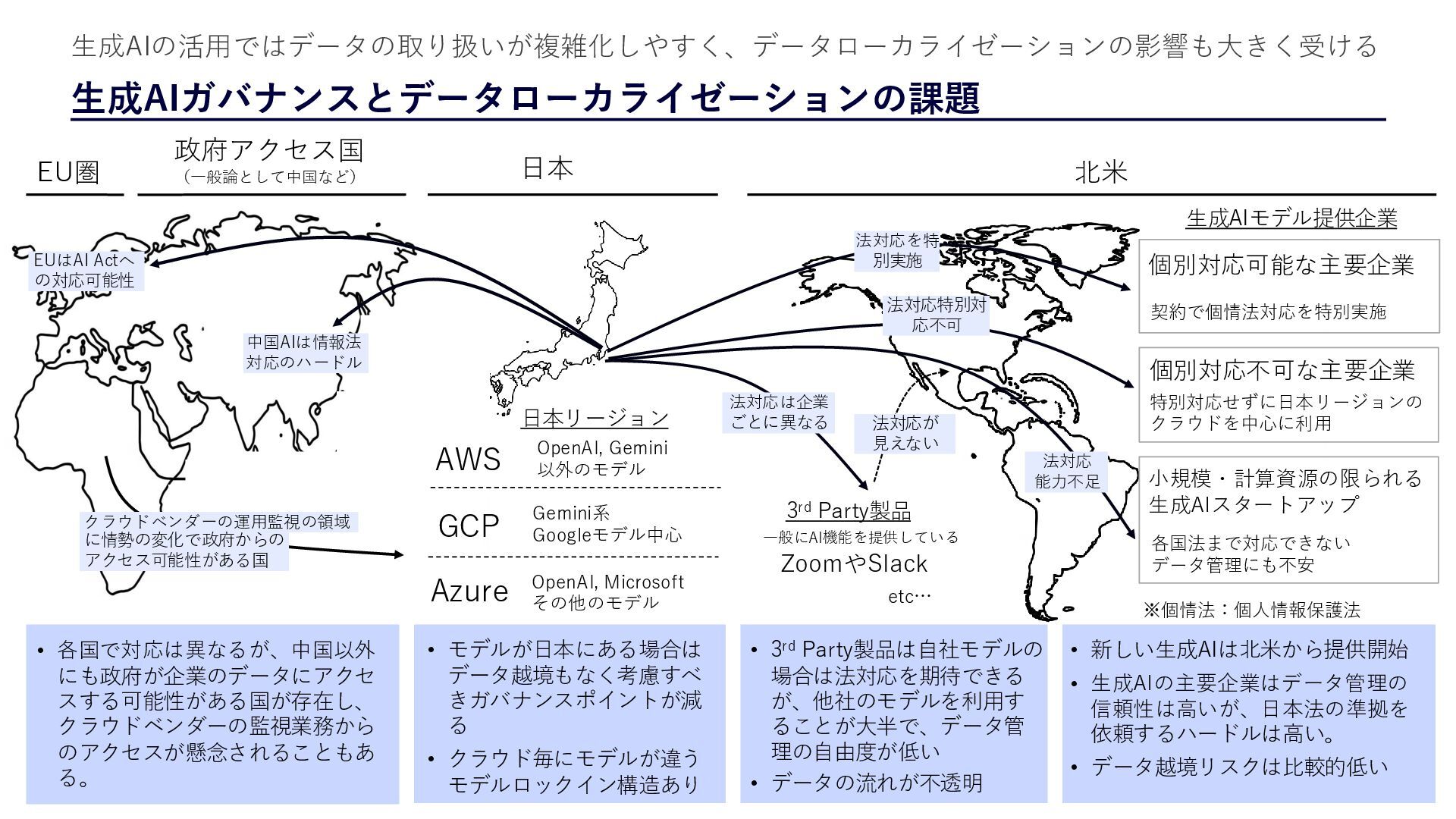{kind=link}
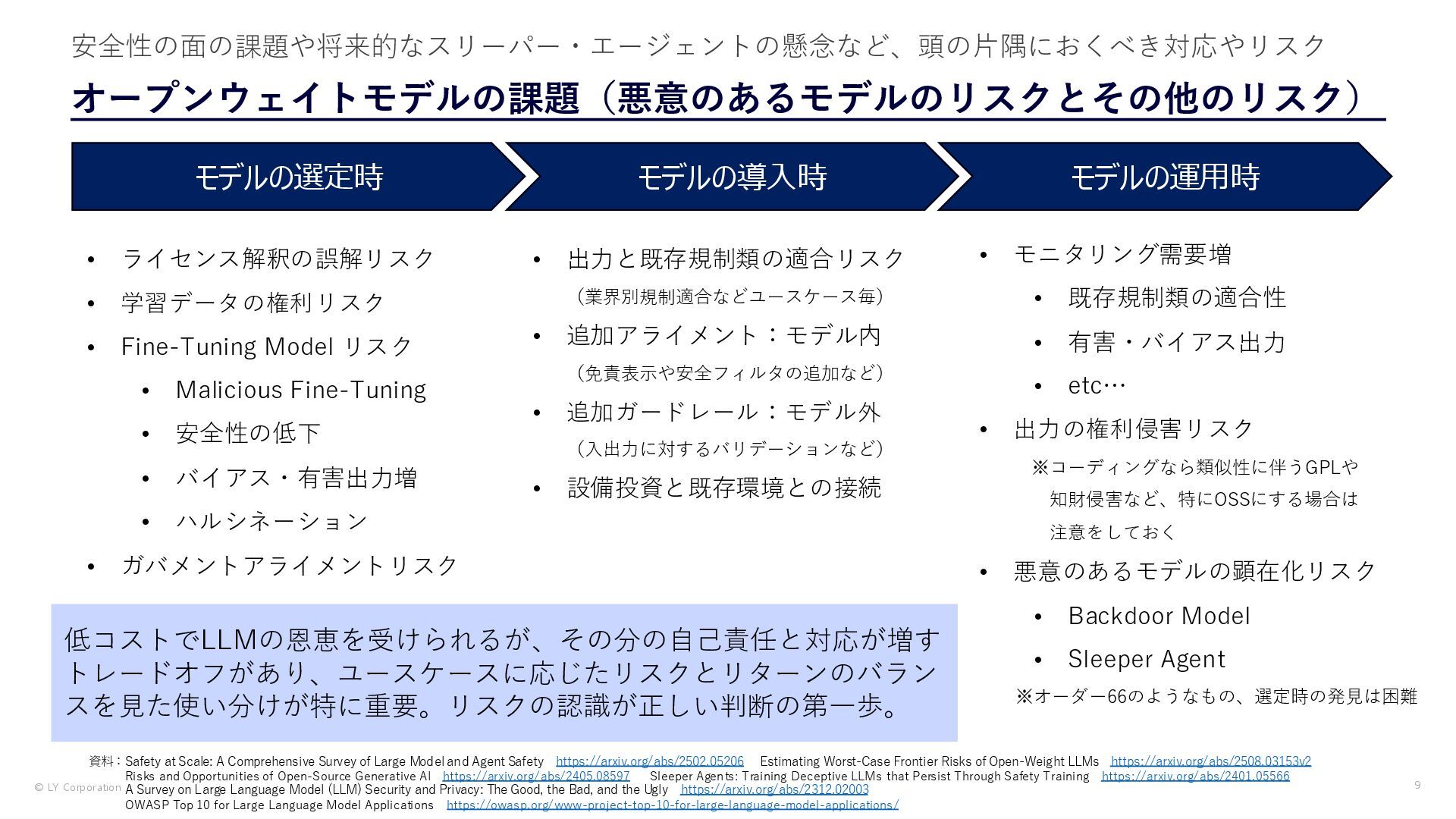{kind=link}
{kind=link}
{kind=link}
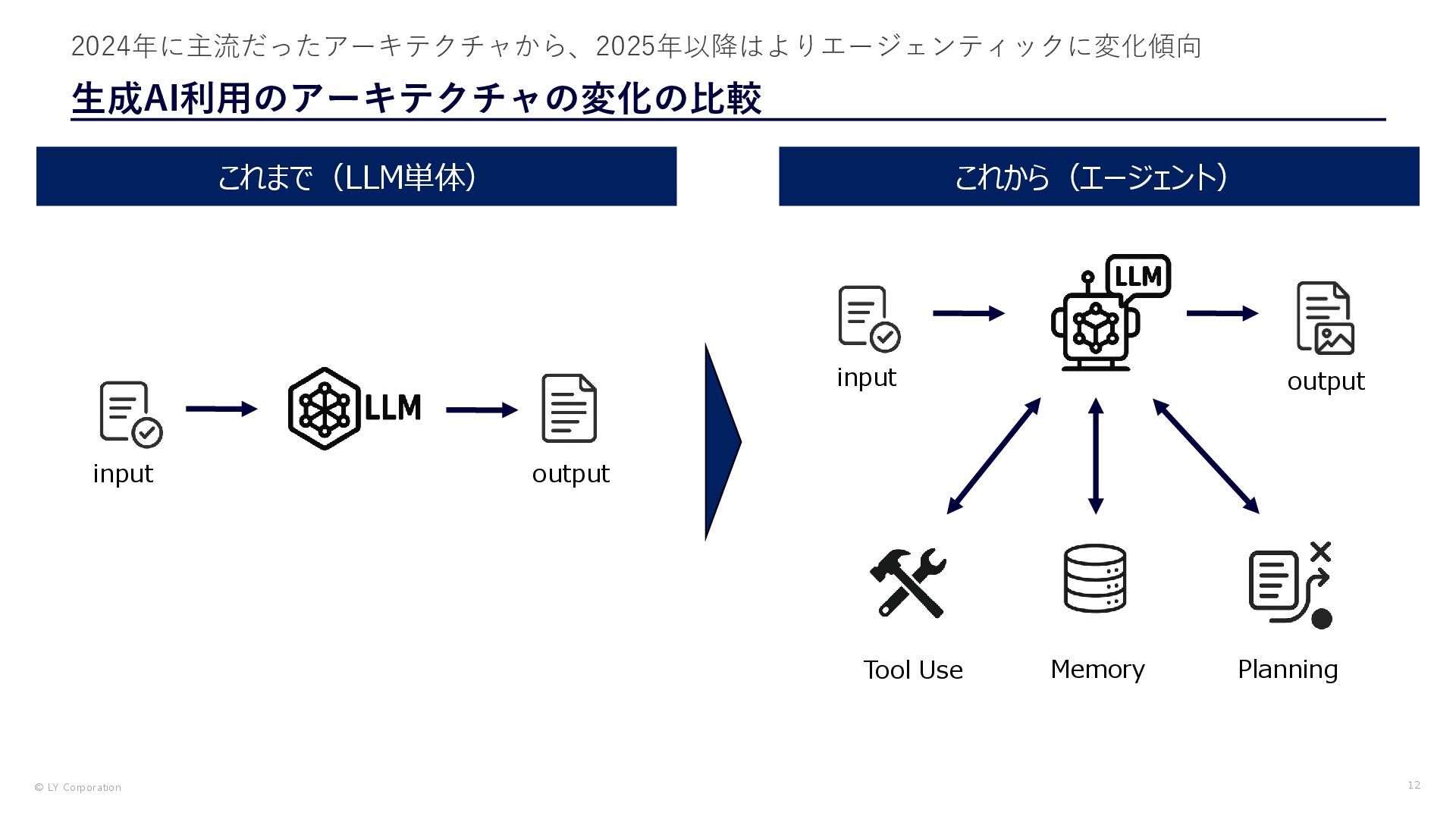{kind=link}
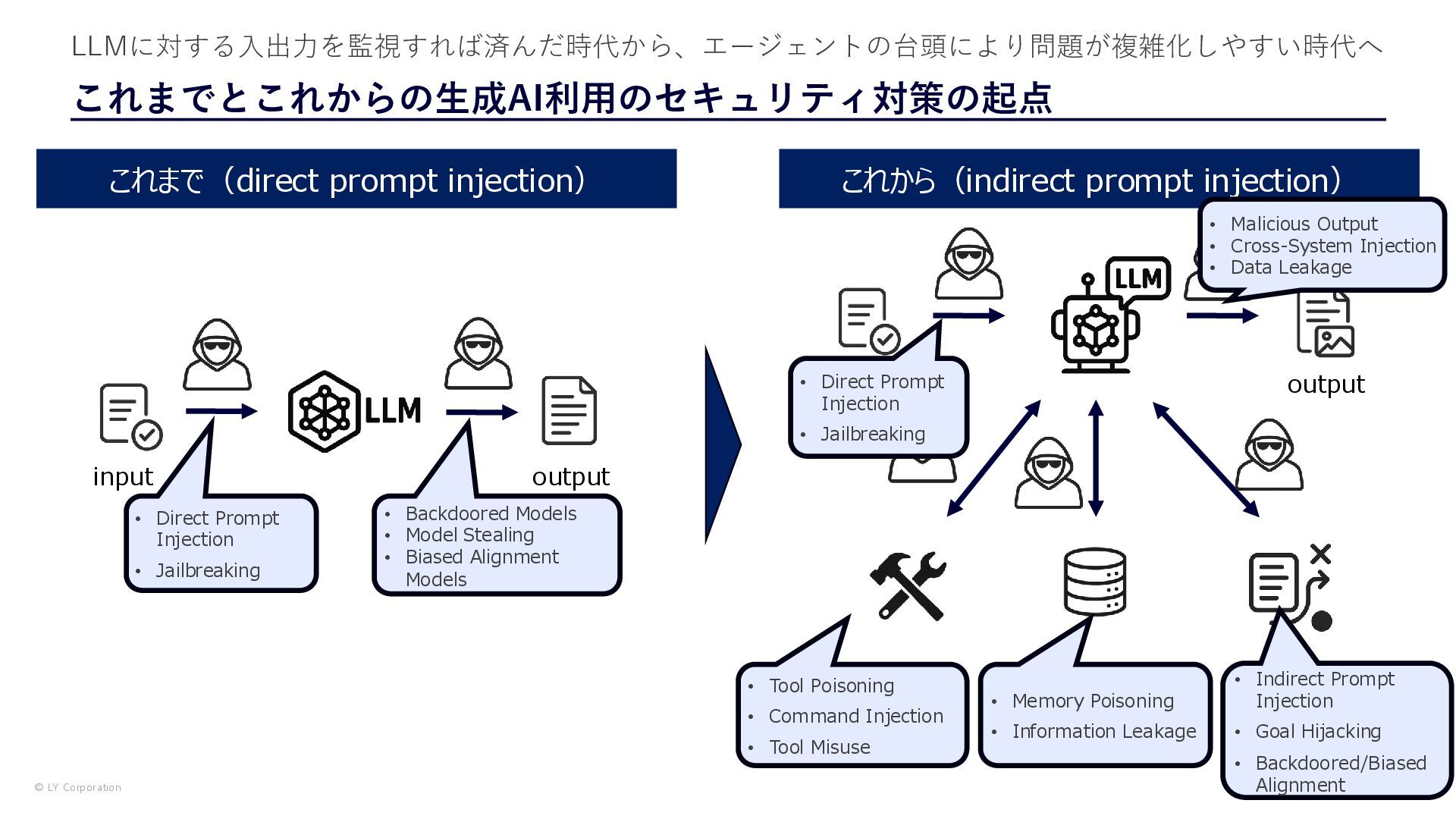{kind=link}
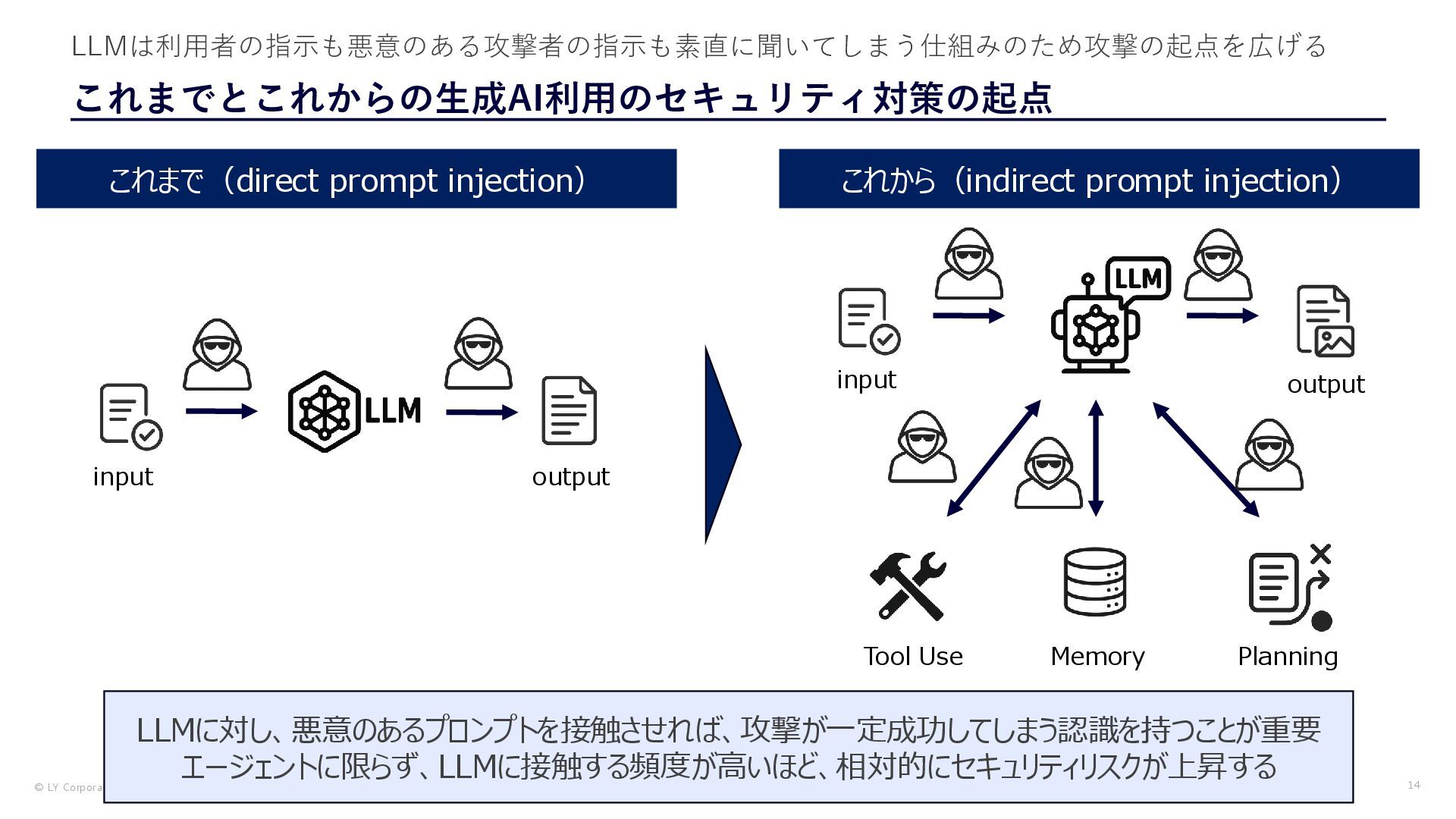{kind=link}
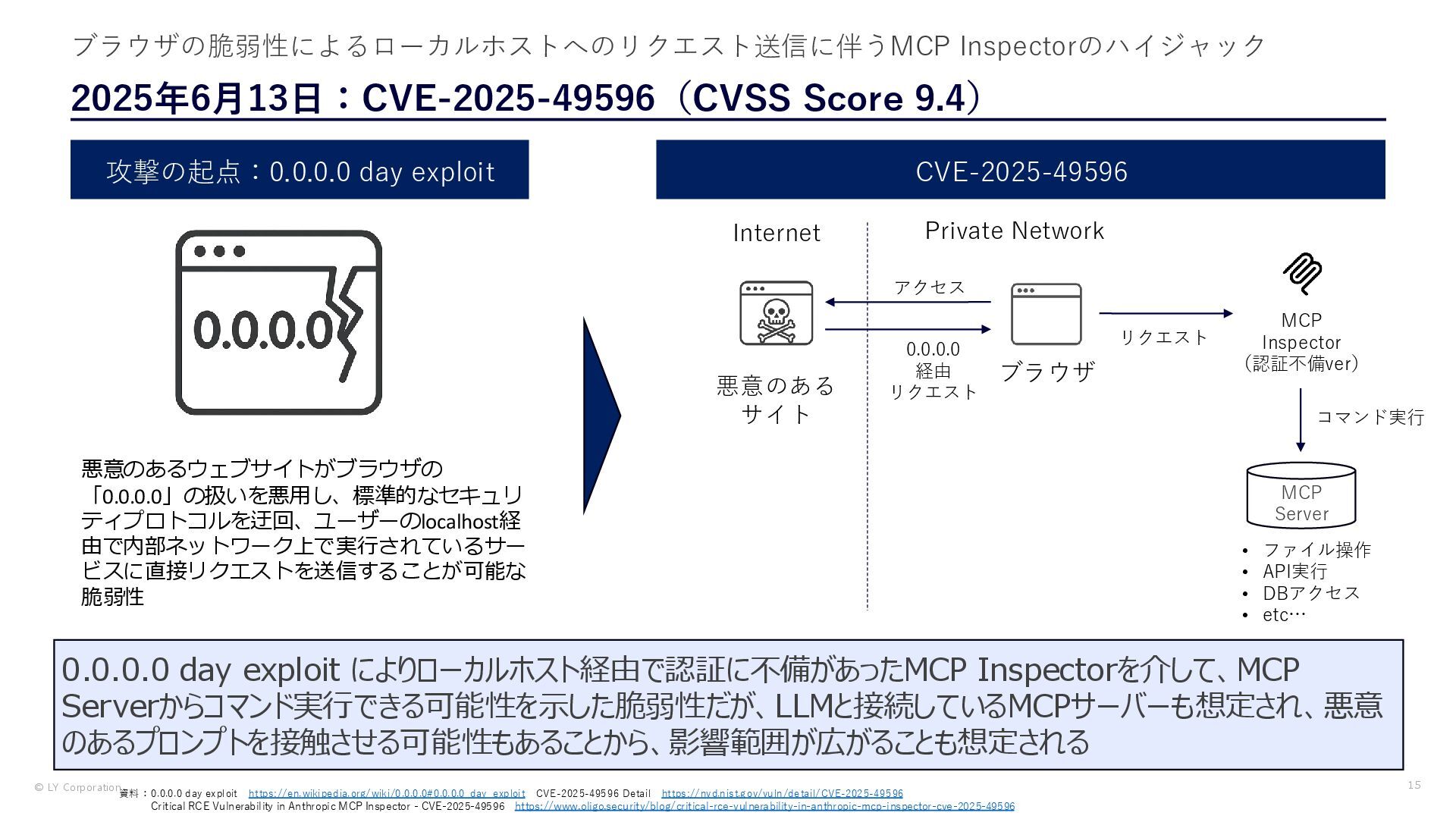{kind=link}
{kind=link}
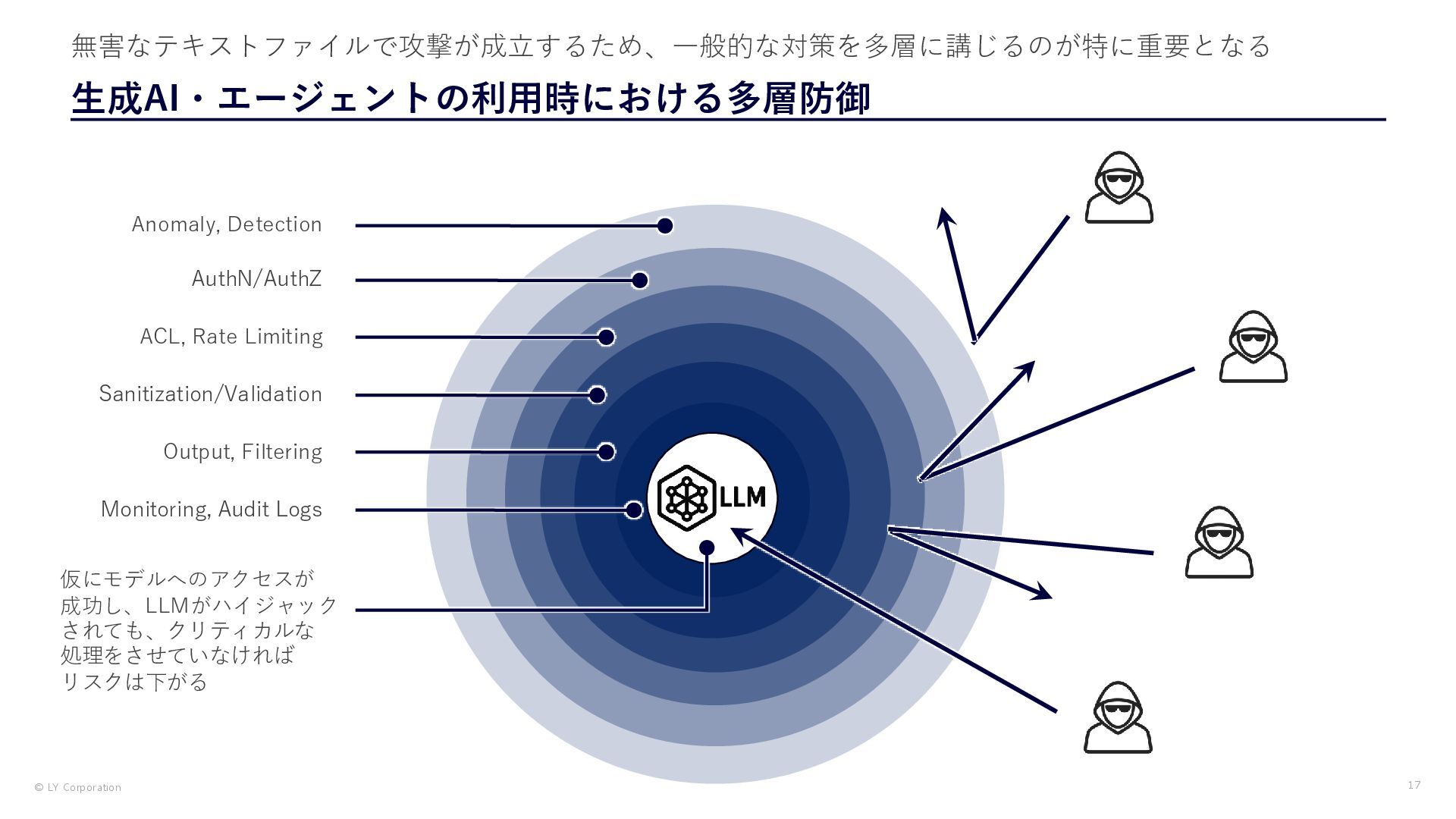{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}