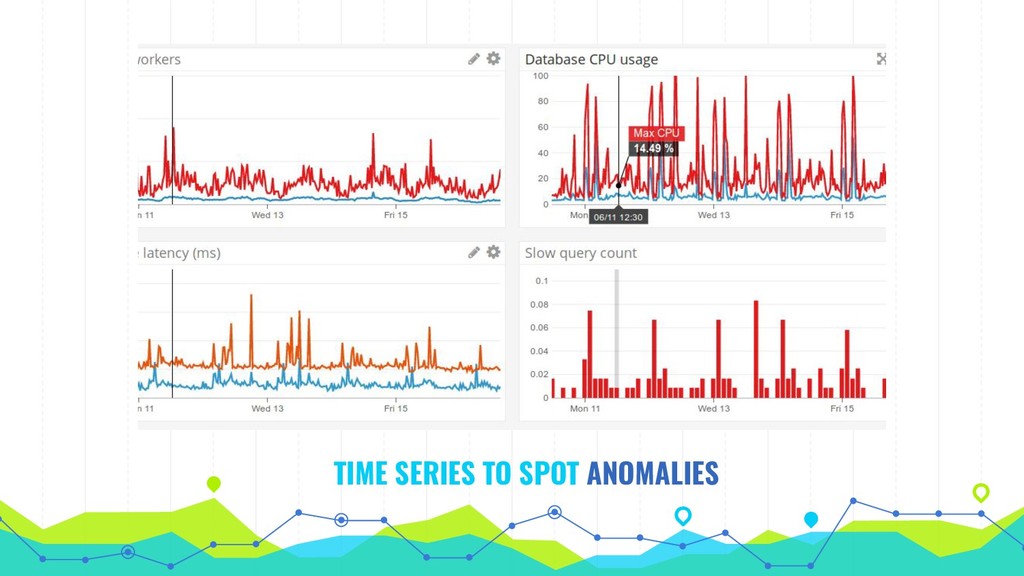
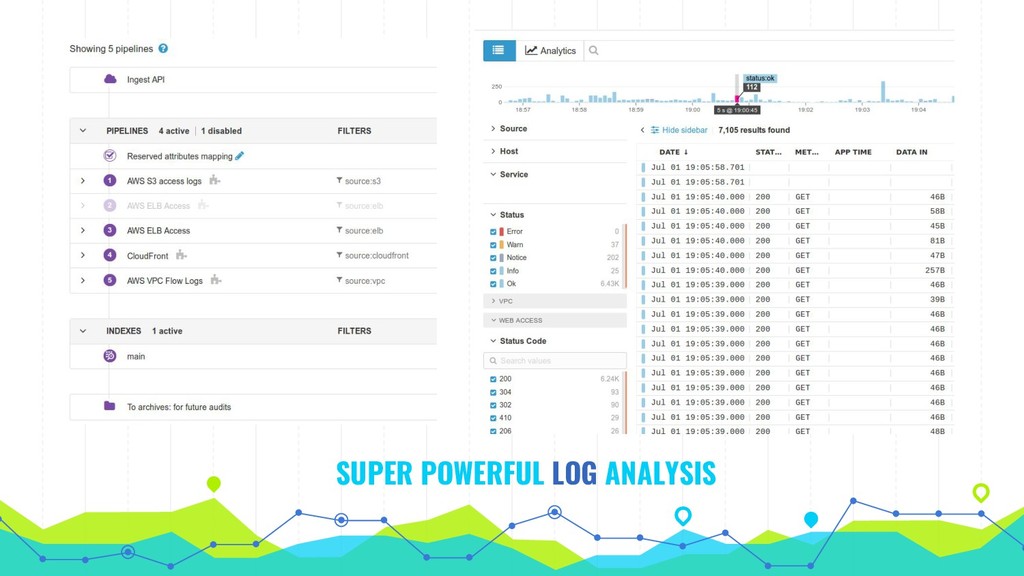
Fix problems before they happen with maximum visibility into your application, with practical steps on monitoring, metric collection, tracing & log analysis. To prevent and fix problems it's important to see how your application works from macro down to micro scale. This can be achieved using a variety of free and paid tools from multiple vendors.
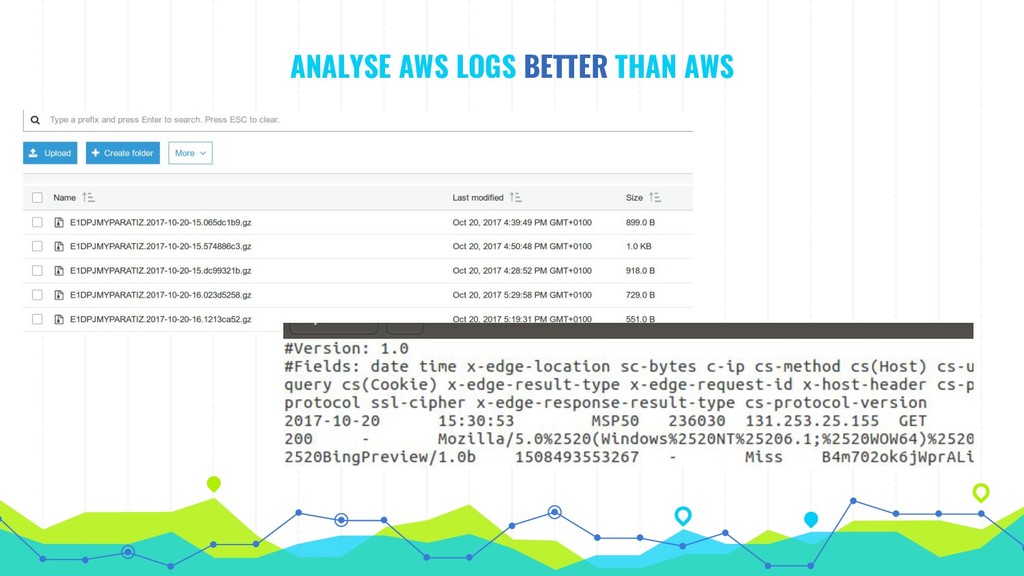
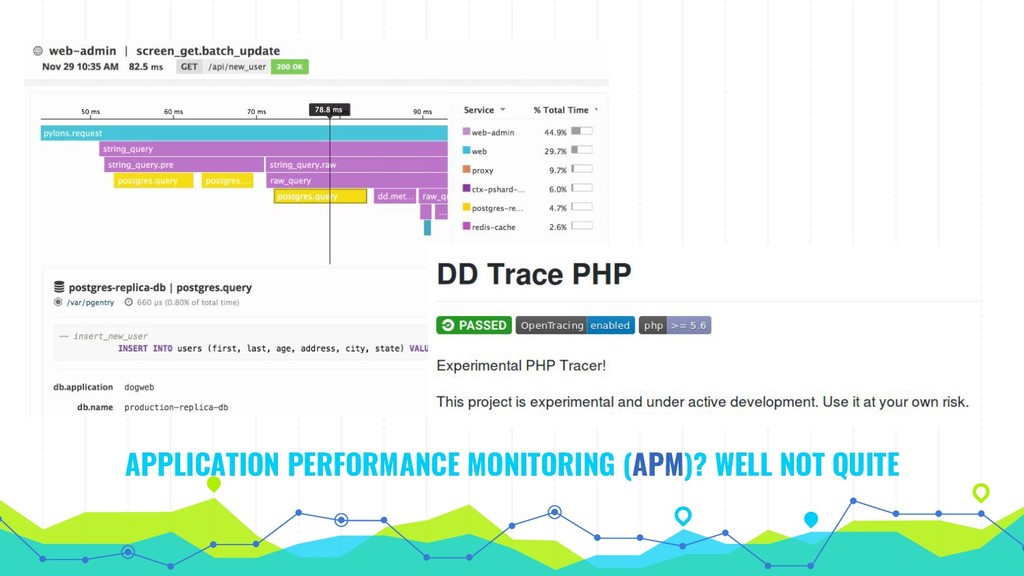
The talk explores practical use of AWS CloudWatch, Datadog & New Relic, all of which can be applied across different cloud or on-premises providers as well as an overview of other available products such as Pagerduty, Loggly, Sentry and Tideways.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}