Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
CQRS+ESをKinesis,Spark,RDB,S3でやってみた
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
machu
July 18, 2019
Technology
3.5k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
CQRS+ESをKinesis,Spark,RDB,S3でやってみた
machu
July 18, 2019
More Decks by machu
See All by machu
NBAチームから学ぶ強いチームの作り方
machuz
0
70
Authorization to implement with Extensible Effect
machuz
0
460
アルプの 認証/認可分離戦略と手法
machuz
3
800
AuthzCtx - Alp社内共有会
machuz
0
100
アルプのEff独自エフェクト集 / Alp-original ’Eff’ pearls
machuz
1
2.3k
Scalebaseバックエンド構成について/the backend design of Scalebase
machuz
0
6.6k
SQL Meisterへの道 ~更新編~ / sql-meister-CUD
machuz
0
2.4k
SQL Meisterへの道 ~基礎〜参照編~ / sql-meister-R
machuz
0
2.8k
Authz
machuz
0
320
Other Decks in Technology
See All in Technology
しくみを学んで使いこなそう GitHub Copilot app
torumakabe
2
290
AICoEでAIネイティブ組織への進化
yukiogawa
0
200
「早く出す」より「事業に効く」 ── 顧客の業務サイクルから逆算するAI時代の二重ループ開発と「変化の設計者」 / devsumi2026
rakus_dev
1
400
AI時代の闇と光
tatsuya1970
0
110
Playwright × AI Agent でE2Eテストはどう変わるか AI駆動テストの可能性と実用検証の結果
taiga7543
1
300
個人開発で育てる「大規模設計の苗床」 - AI時代の1人開発から始める業務への知識接続 / The Seedbed for Large-Scale Design - From AI-Era Solo Projects to Professional Knowledge
bitkey
PRO
1
280
LLM/Agent評価:トップ営業の発言を「正解」にする 〜暗黙的正解による評価を営業資産に変える〜
takkuhiro
1
230
知らん間に、回ってる
ming_ayami
0
730
プロダクト開発組織の現在地(Ver.2026/07) / product-organization
kaonavi
0
110
生成AI×AWS CDK×AWS FISで"振り返れる"ミニGameDayをつくろう
yoshimi0227
1
410
Amazon EVS で VCF 9.0 / 9.1 のサポート開始まとめ
mtoyoda
0
310
AI時代のYAGNI:「爆速で無駄になった機能」からの学び / 20260720 Naoki Takahashi
shift_evolve
PRO
2
320
Featured
See All Featured
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.8k
Discover your Explorer Soul
emna__ayadi
2
1.2k
How to Think Like a Performance Engineer
csswizardry
28
2.7k
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
2
1.5k
Documentation Writing (for coders)
carmenintech
77
5.4k
The Power of CSS Pseudo Elements
geoffreycrofte
82
6.4k
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
2.1k
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.4k
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
Optimising Largest Contentful Paint
csswizardry
37
3.8k
Designing for humans not robots
tammielis
254
26k
Transcript
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた CQRS+ESを Kinesis,Spark,RDB,S3でやってみた @ma2k8 Tsubasa Matsukawa スタディサプリ/Quipper Product Meetup
#3
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた About me @ma2k8 Tsubasa Matsukawa スタディサプリEnglishのサーバーサイドとインフラを 担当しています。 2
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた Agenda | 01 CQRSとは 02 EventSourcingとは 03 CQRS+ESとは
04 スタディサプリENGLISHにCQRS+ESを導入する前の課題 05 CQRS with Embulkの導入 06 Spark,Kinesis,S3,RDBでCQRS+ES 07 まとめ 3
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた CQRSとは 01 4
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた コマンドクエリ分離原則 ~ Command and Query Responsibility Segregation ~
➔ ざっくりいうと ◆ Commandは副作用を伴う処理(更新系) ◆ Queryは値だけ返す処理(参照系) ◆ この2つをわけようという考え(CQS)をアーキ テクチャへ適用したもの 5
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた メリット ➔ 参照はページングが必要なケースも多く、更新系のときと同じロジックで組み 立てるのはかなりしんどいので、参照する時の形で保存し、値を取って返だ けにすることでシンプルにできる ➔ これによりアプリケーションのコードがシンプルになり、参照系の計算量もか なり減る
➔ 一定以上の規模、複雑さを持つアプリケーションではかなり有用なアプロー チとなる 6
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた たとえば・・・・? 7
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた ゲームの巨大ロボットの部位破壊を例にしてメリットの一部を紹介 ➔ 攻撃を受けてHPを減少させる処理(更新系)は、どの箇所に受けたダメージ か、その箇所はすでに破壊済みか(壊れていたらHPの減少なし)などのロ ジックを挟むので各部位の現状の状態を計算しないといけない ➔ しかし、全体のHPを表示する(参照系)のに更新系に必要なロジックを挟むの は煩雑で、部位数が多いと重くなってしまうので、更新系が走るタイミングで
全体のHPをどこかに保存しておくことで参照系がシンプルになります 8
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた デメリット ➔ Command/Queryの保存先、同期の方法を考える必要がある 9
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた EventSourcingとは 02 10
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた Event Sourcing ➔ データではなく、イベントを主役とするパターン ➔ 発生するイベントはすべて記録し、基本的に追加しかしない ➔ 対となる概念は「State
Sourcing」 11
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた メリット ➔ State Sourcingでは消えてしまう、有用な履歴情報をすべて残せる ➔ 後で「あの情報欲しいな」と思い直したときに、積み上げたEventから好きな 状態に復元することができる ➔
Eventをhookに様々な処理が書ける。マイクロサービス文脈でも有用 12
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた デメリット ➔ Eventの数が多くなると状態を計算する処理のコ ストが大きい ➔ 任意のタイミングでスナップショットデータをつくっ て回避する 13
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた CQRS+ESとは 03 14
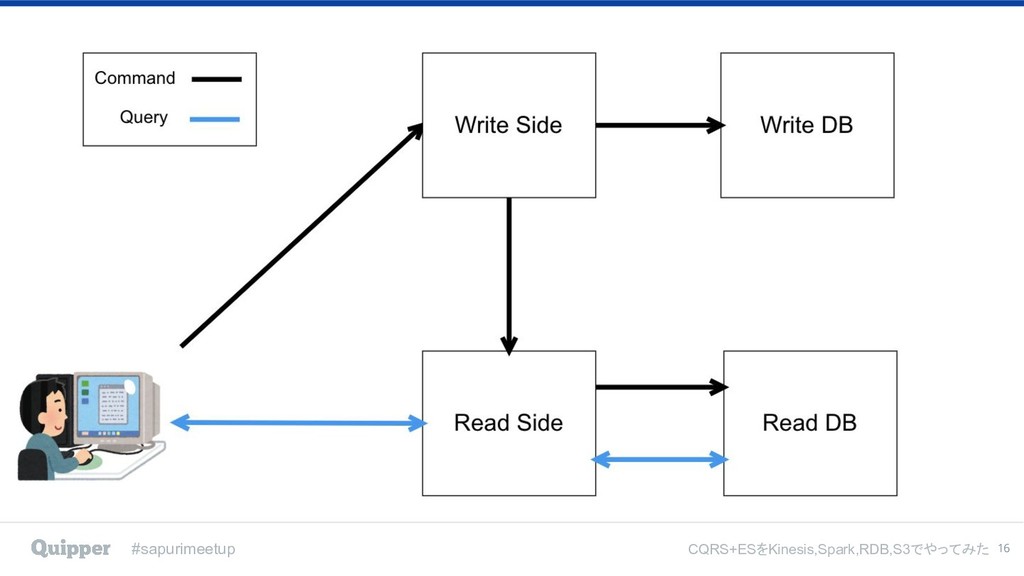
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた CQRS+ES ➔ CommandとQueryの結合をEventで行う ➔ QueryをEvent契機で更新していく ➔ Queryはカウンターキャッシュ的に更新されていくイメージ 15
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた 16
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた スタディサプリEnglishに CQRS+ESを導入する前の課題 04 17
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた データの持ち方 ➔ スタディサプリENGLISHではリリース当初から学習ログをEvent Sourcingで RDBに保存する設計になっていた ◆ 立ち上げ期の保存場所としては妥当 ◆
State Sourcingに振っていないのでデータが残っている点もGood ➔ その学習ログを都度集計してクライアントがほしい形に加工していた 18
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた データが増え、つらみが・・ ➔ 学習者のグループを管理する要件が追加され、学習履歴一覧ページが誕生 してしまい、都度集計の重さが実用に耐えなくなってしまった ➔ ただ表示したいだけなのにロジックもめちゃくちゃ複雑 ➔ 集計しないと学習状況がわからないので、学習日数などでソートしてページ
ングするのに、全学習者分の集計が必要となり、重・・・・ 19
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた これではスケールしない 20
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた CQRS with Embulkの導入 05 21
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた スケールしないので、 まずは簡単にCQRSを初めてみた 22
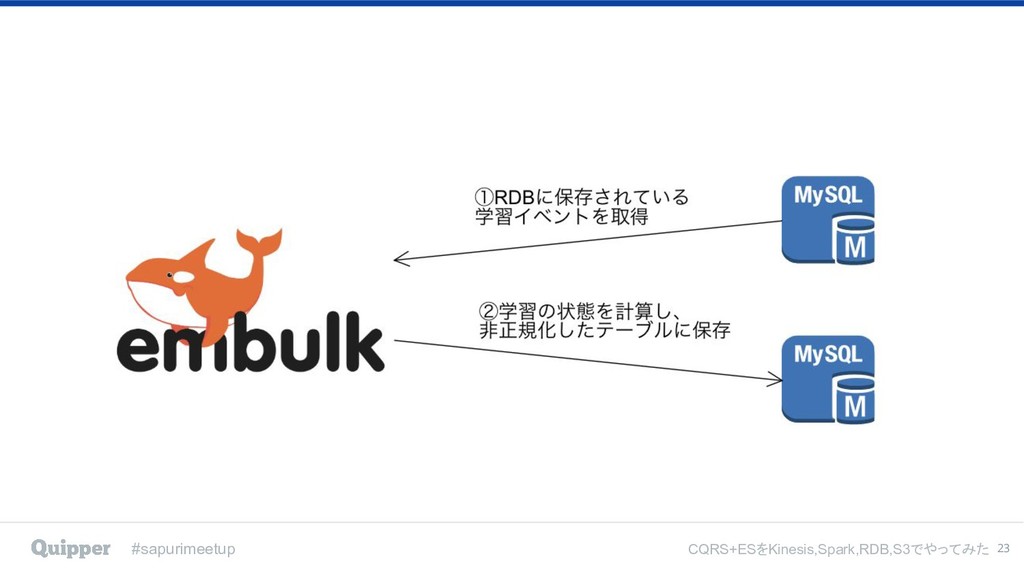
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた 23
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた API 軽くなった 24
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた だが・・・・ 25
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた 一時しのぎのCQRS ➔ APIは軽くなったが、Embulkでの集計処理はデータ量に応じて重くなる ➔ 導入後1年ほどして、集計に1時間を超えるようになってしまった ➔ 結果反映が1h以上おくれるので、ユースケースもかなり限られる ➔
Embulkはとても便利で大好きなツールですが、集計用の巨大な生SQLは ちょっとメンテしにくい 26
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた Spark,Kinesis,S3,RDBでCQRS+ES 06 27
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた それぞれの要素を軽く紹介 ※RDBとS3は除く 28
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた Kinesisとは ➔ マネージドなリアルタイムストリーム基盤 ➔ Consumerを自分で書けるKinesis Data Streamsと、Consumerを書かな いでもs3等、特定の箇所に突っ込んでくれるKinesis
Data Firehoseがある ➔ at-least-once 29
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた Sparkとは ➔ Scalaで書かれた並列分散処理フレームワーク ➔ Hadoop MapReduceのDisk IOが重い弱点を、データをオンメモリで処理 することにより解決した
➔ 繰り返し処理、リアルタイム処理などにかなり強い ➔ Scalaで直感的に並列分散処理が書くことができて素敵 30
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた SparkはEMR上で動かしています 31
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた EMRとは ➔ Hadoop,Hive,Sparkなどのクラスタをマネージドに立ち上げることができる マネージドクラスタプラットフォーム ➔ 構築、保守がとても面倒な大規模分散処理基盤をお手軽に立ち上げ、実行 することができ、S3,Dynamo,Redshift等のAWSサービスへのインテグレー ションも容易
32
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた これらを使ってCQRS+ESを 効率よくやる 33
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた Command,Query,Eventの保存場所 ➔ Commandはトランザクション整合性で正規化されたデータを保存する ➔ Queryは結果整合性で、非正規化されたクライアント都合のデータを保存す る ➔ Eventは大量のデータをスキーマレスに保存する
➔ Command,QueryはRDB、EventはS3へ保存することにした 34
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた S3はいいぞ ➔ S3は書き込みを`Prefix毎に3500req/sec` 捌ける ➔ AWSはS3をHubにいろんなサービスへ展開しやすい ➔ 可用性99.99%
耐久性イレブンナイン ➔ 安い ➔ `Full managed object storage` 容量キニシナイ 35
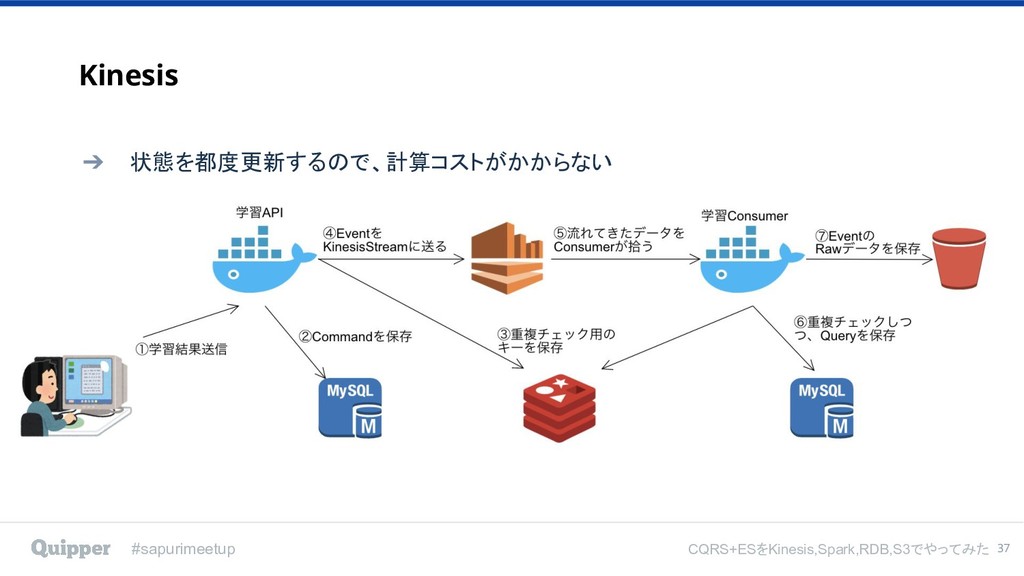
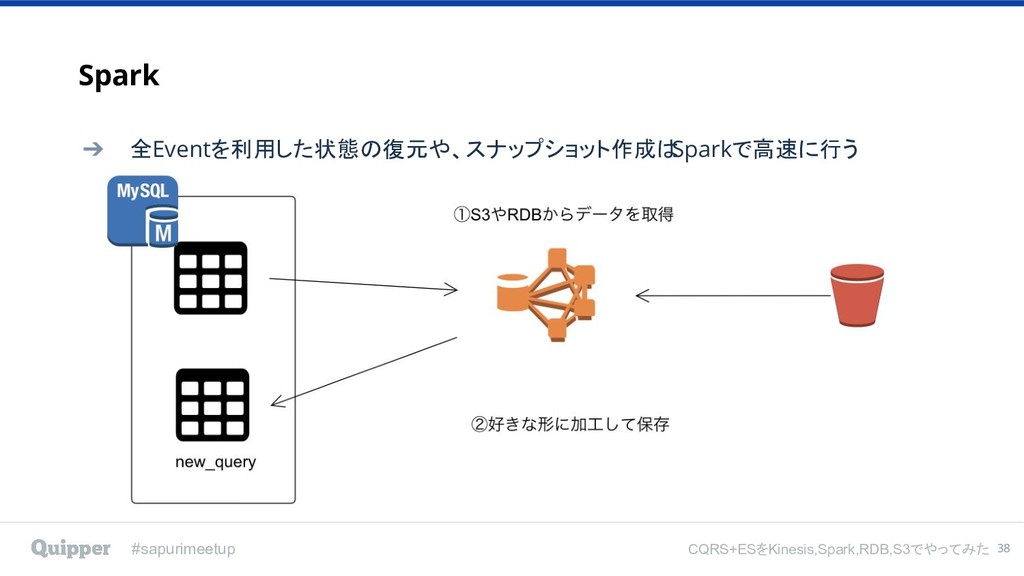
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた Kinesisはイベントの伝播 SparkはQueryの集計で使う 36
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた Kinesis 37 ➔ 状態を都度更新するので、計算コストがかからない
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた Spark 38 ➔ 全Eventを利用した状態の復元や、スナップショット作成は Sparkで高速に行う
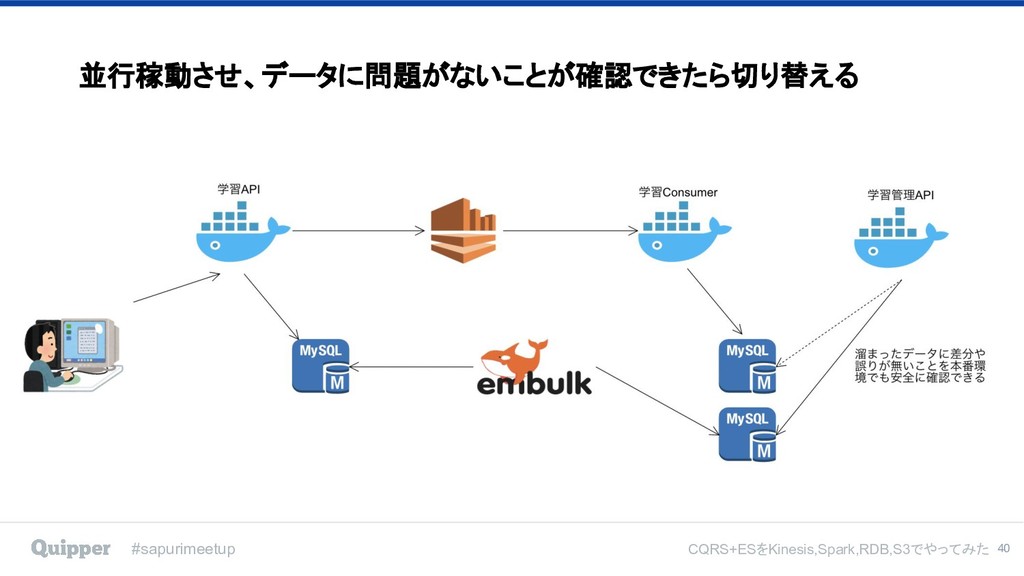
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた 切り替えも安心安全 39
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた 並行稼動させ、データに問題がないことが確認できたら切り替える 40
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた まとめ 07 41
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた CQRS+ESは便利 42
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた EventはS3においておくと 分析などで再利用しやすい 43
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた EMR,Spark,Kinesisは 大規模と戦う際にとても有用 44
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた 45
#sapurimeetup CQRS+ESをKinesis,Spark,RDB,S3でやってみた ご清聴ありがとうございました 46
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}