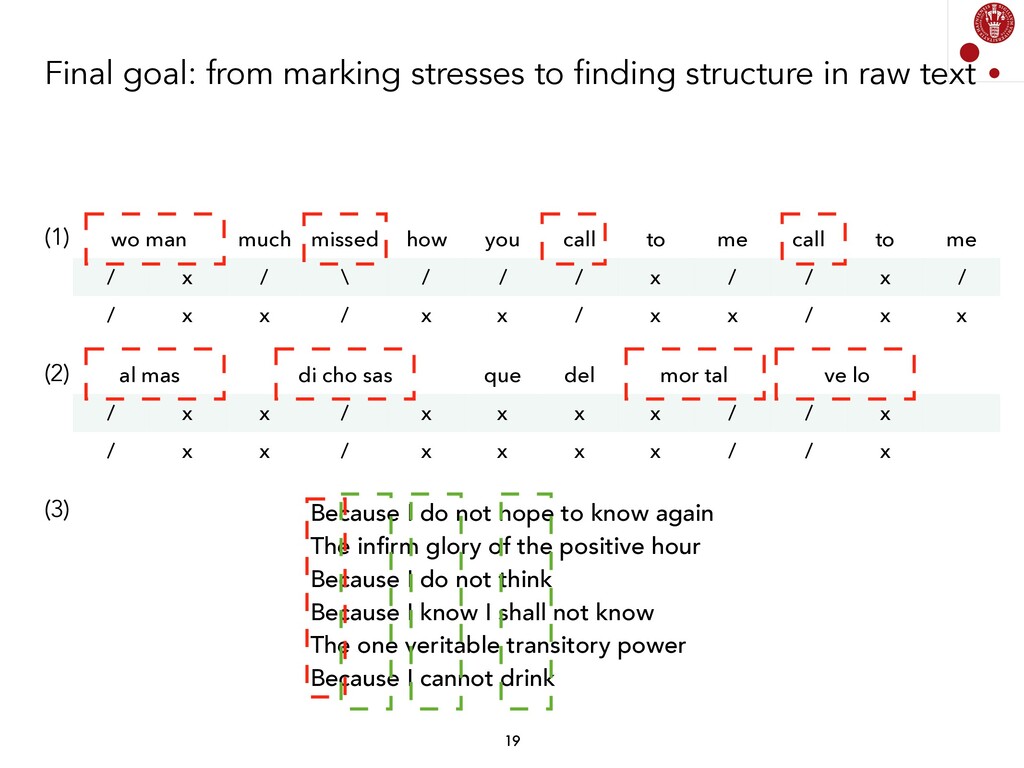
In this talk I will discuss about some work on automatic scansion of poetry. Scansion is a well- established form of poetry analysis which involves marking the prosodic meter of lines of verse and possibly also dividing the lines into feet. The specific technique and scansion notation may differ from language to language because of phonological and prosodic differences, and also because of different traditions regarding meter and form. Scansion is traditionally done manually by students and scholars of poetry.
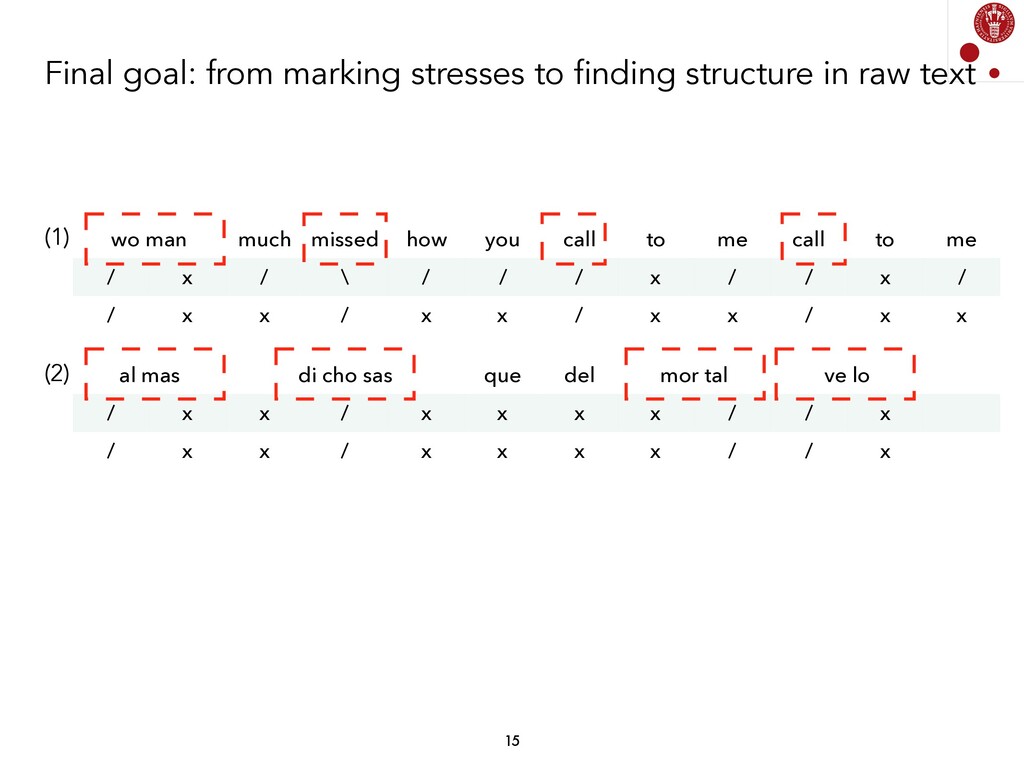
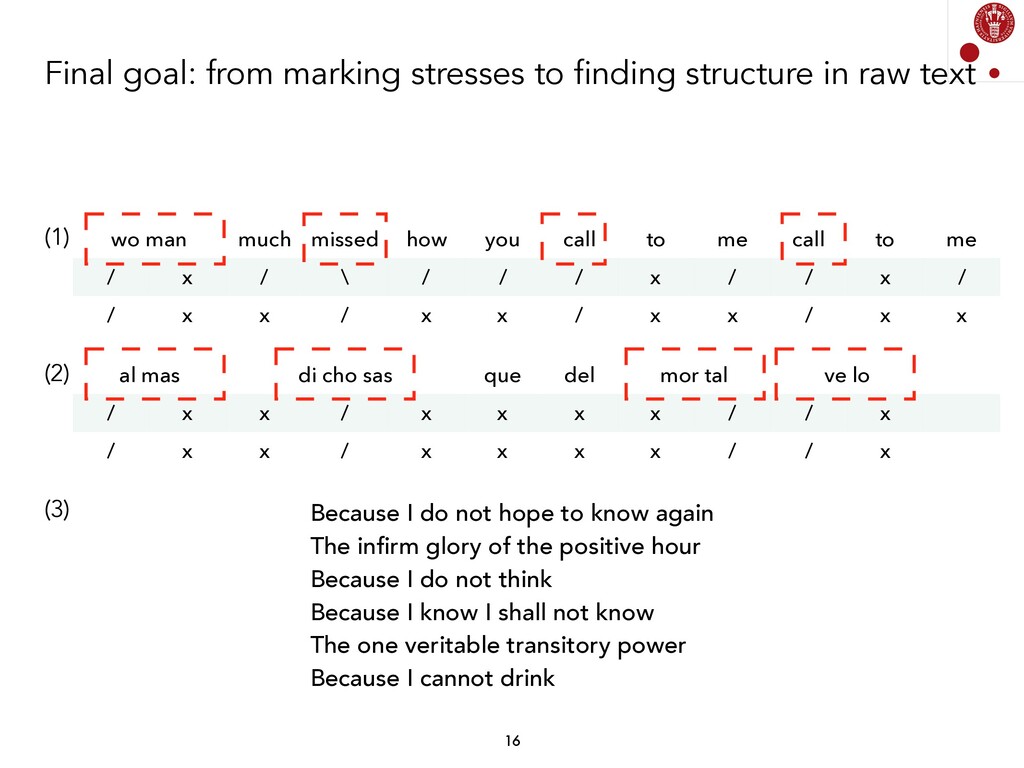
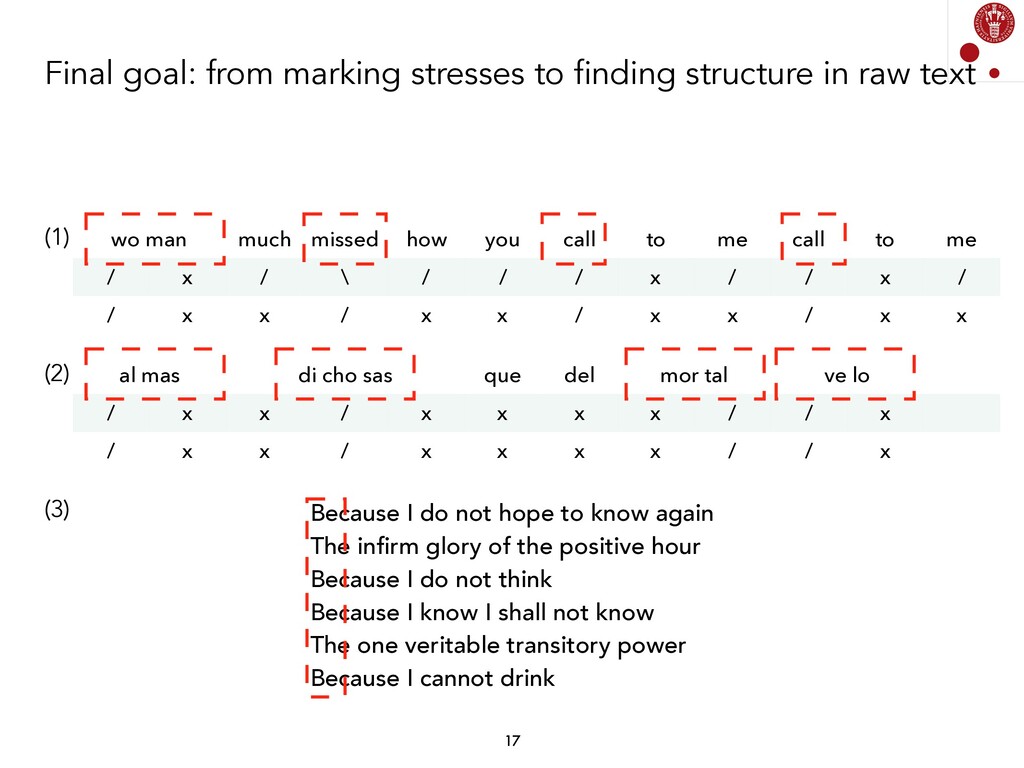
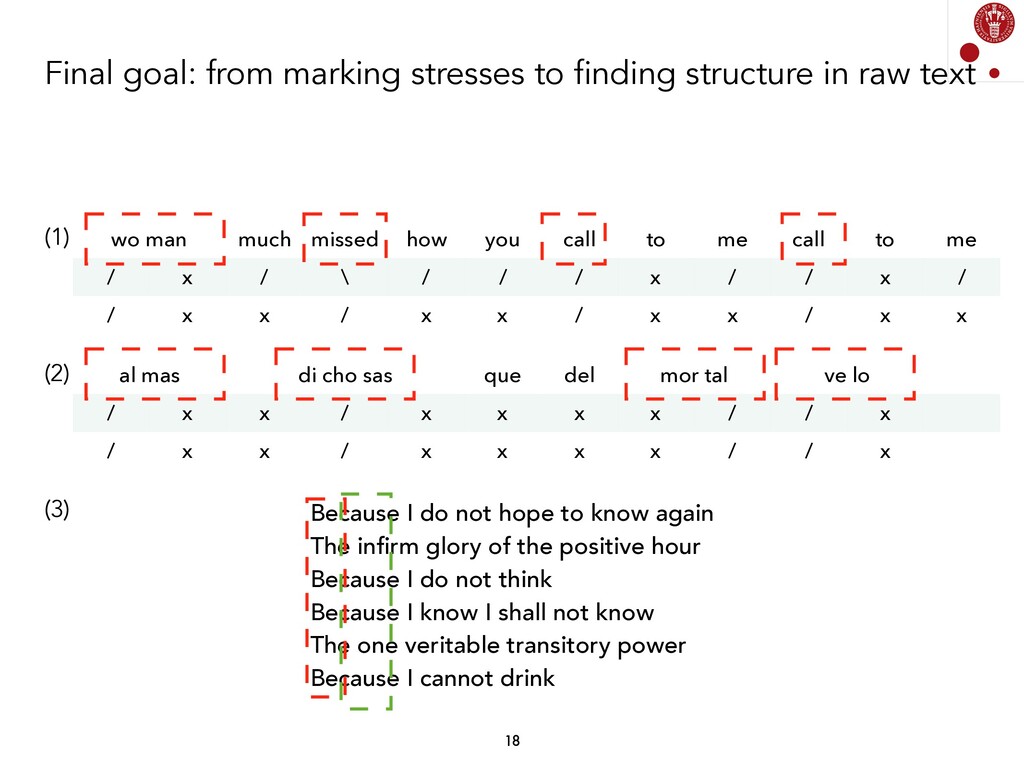
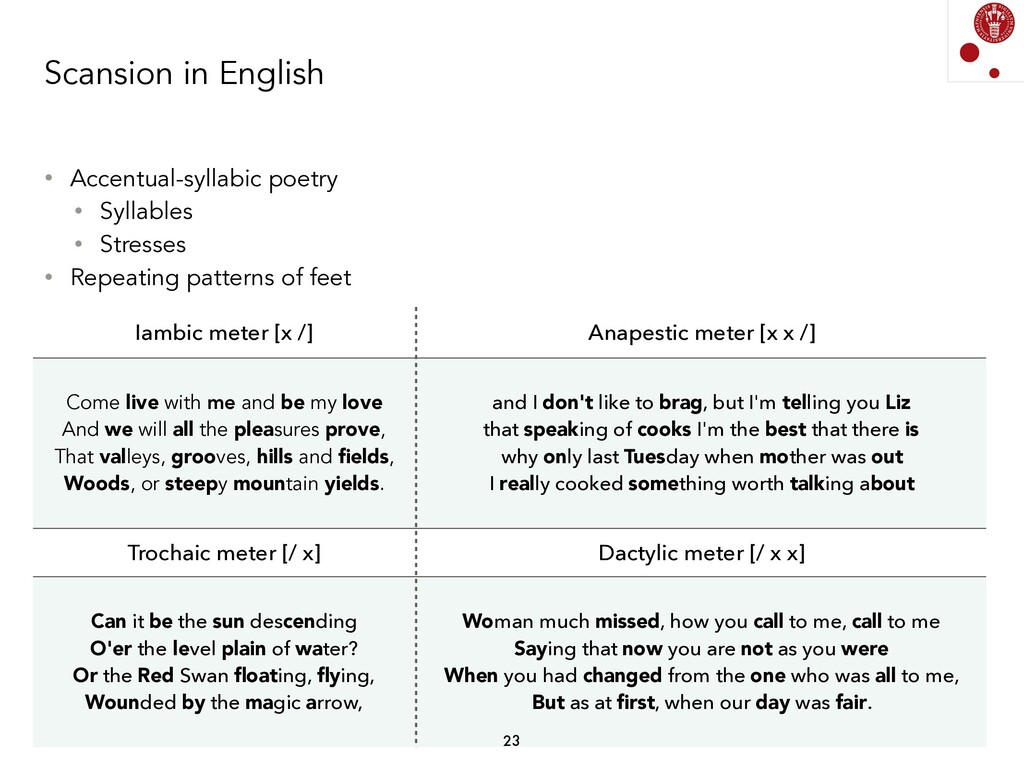
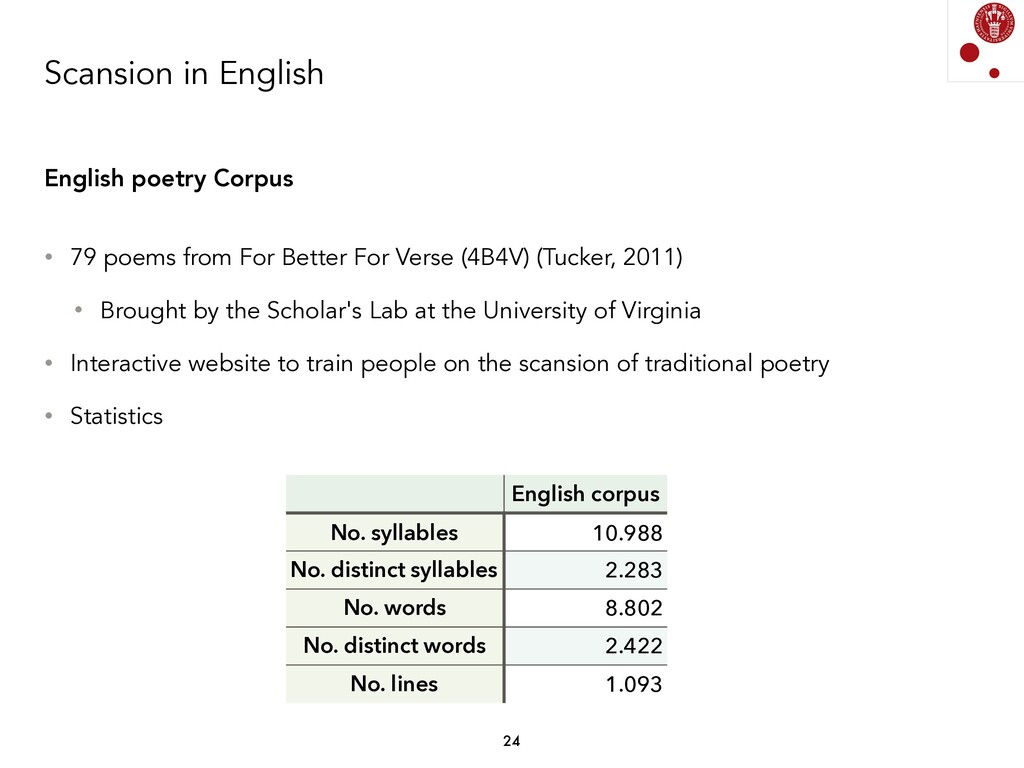
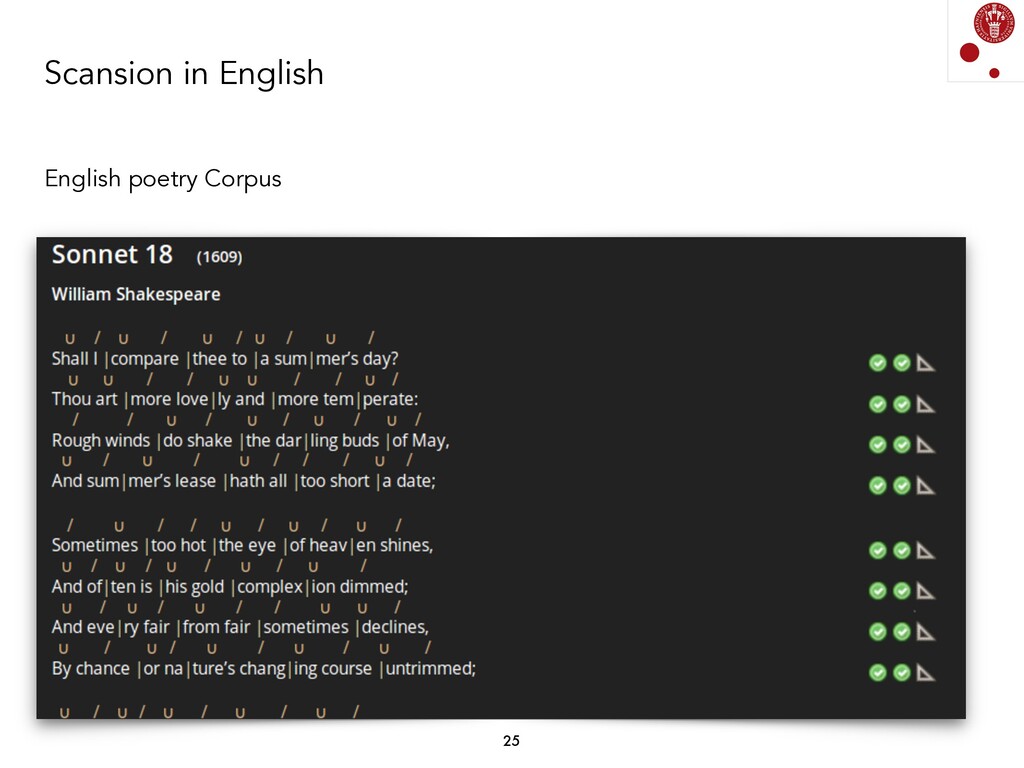
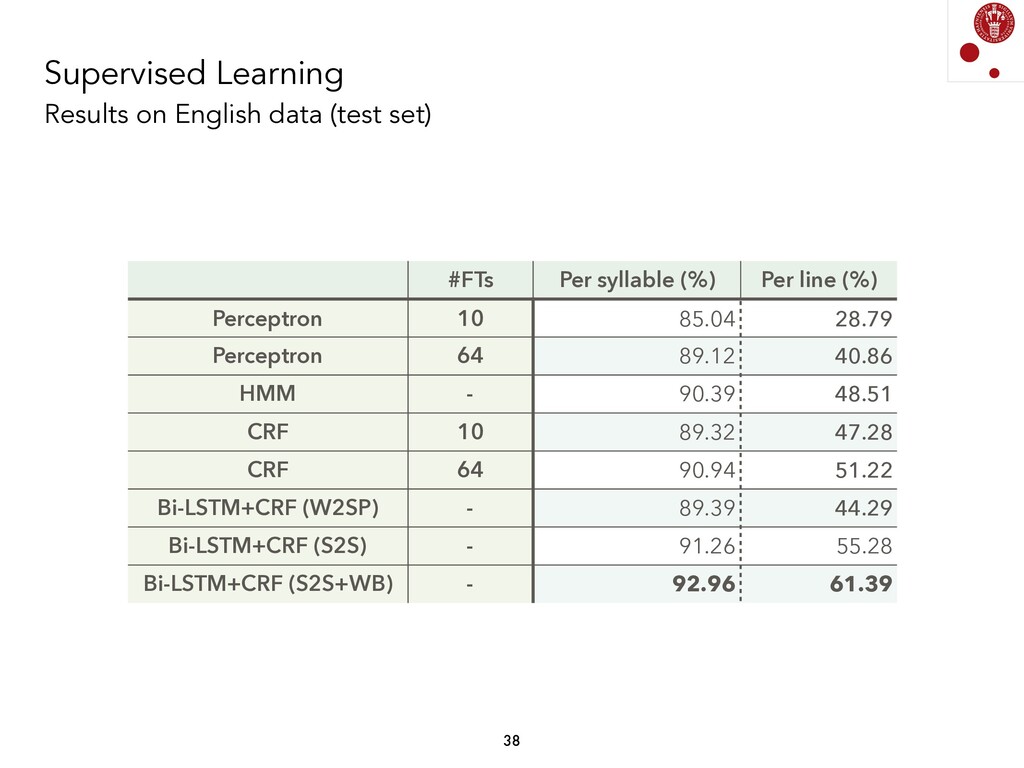
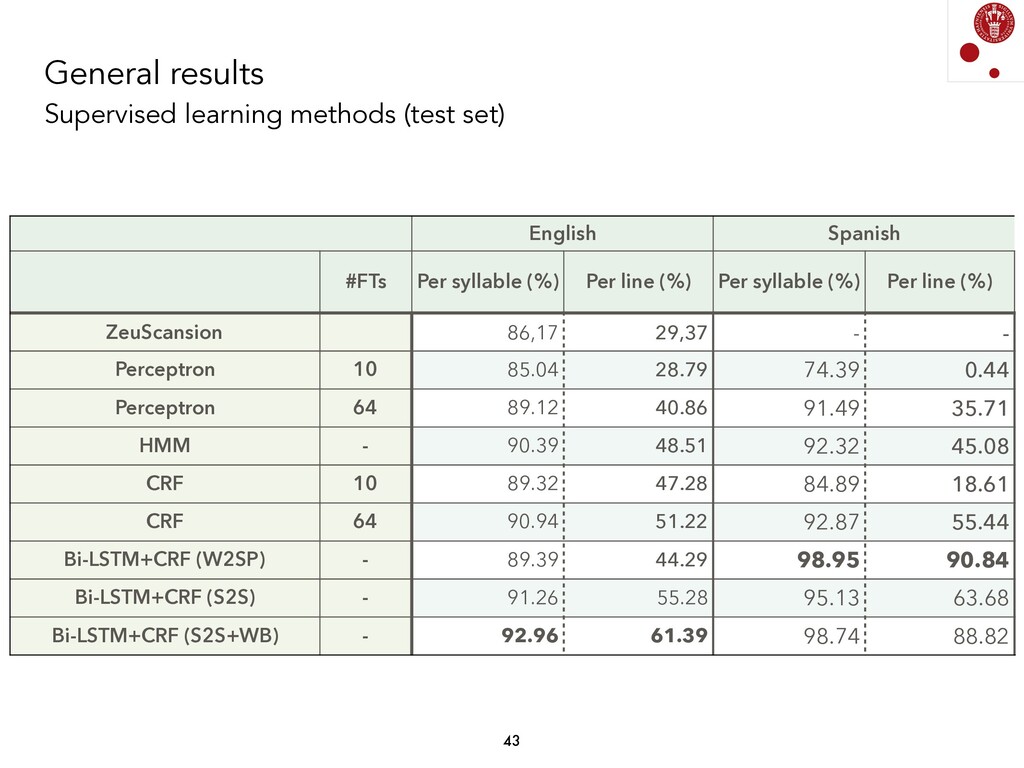
We explored different Natural Language Processing techniques to approach the task of scansion in English poetry. Some of them rely on linguistic rules, encoded as finite-state transducers, and others are based on data. The models built on top of data assume that there exists a data set, where each syllable in a poem is marked, following a rather traditional notation, with either x (for unstressed syllables) or / (for stressed syllables).
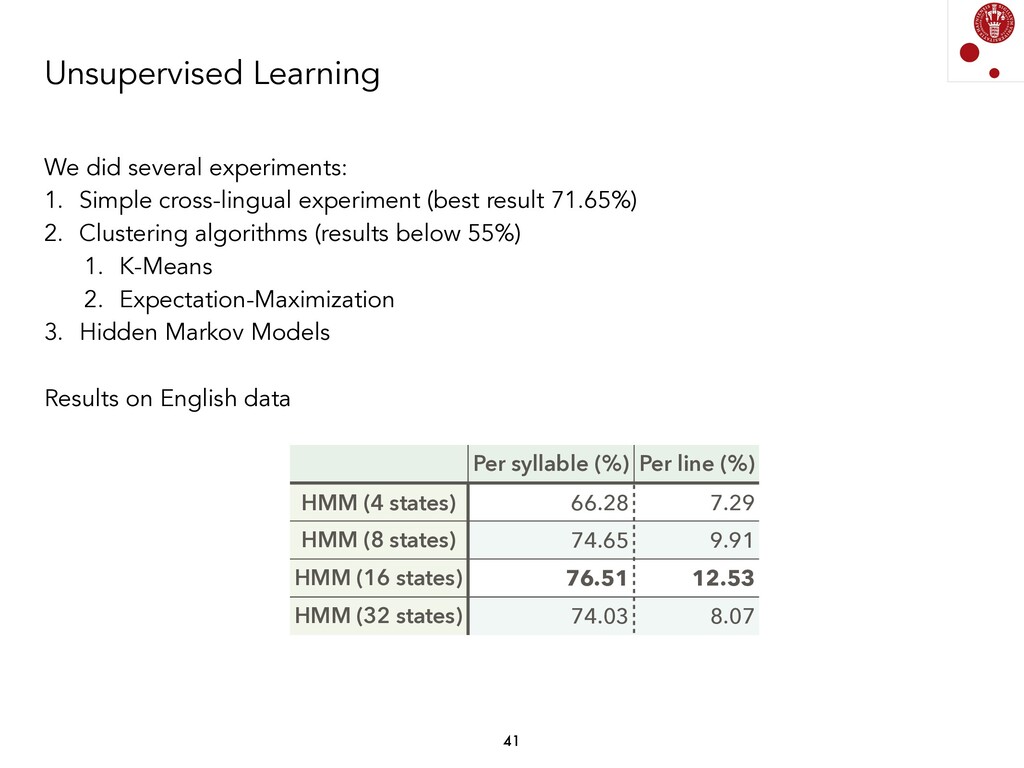
Generating a model from some input data (a syllabified poem) and some output data (a sequence of syllable stresses) has been done using different techniques, and is fairly straightforward if we consider current Supervised Machine Learning models. Currently, we are exploring whether these associations can be found by not using any information about stresses. We are, therefore, analyzing Unsupervised Learning models in order to find prosodic structure in poems.
{kind=link}
{kind=link}
![[One, two!] [One, two!] [And through] [and through] [The vor][pal](https://files.speakerdeck.com/presentations/8cefe1fb9bb949a08521bbf1ab5ee061/slide_2.jpg){kind=link}
![[One, two!] [One, two!] [And through] [and through] [The vor][pal](https://files.speakerdeck.com/presentations/8cefe1fb9bb949a08521bbf1ab5ee061/slide_3.jpg){kind=link}
![[One, two!] [One, two!] [And through] [and through] [The vor][pal](https://files.speakerdeck.com/presentations/8cefe1fb9bb949a08521bbf1ab5ee061/slide_4.jpg){kind=link}
![[One, two!] [One, two!] [And through] [and through] [The vor][pal](https://files.speakerdeck.com/presentations/8cefe1fb9bb949a08521bbf1ab5ee061/slide_5.jpg){kind=link}
![[One, two!] [One, two!] [And through] [and through] [The vor][pal](https://files.speakerdeck.com/presentations/8cefe1fb9bb949a08521bbf1ab5ee061/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
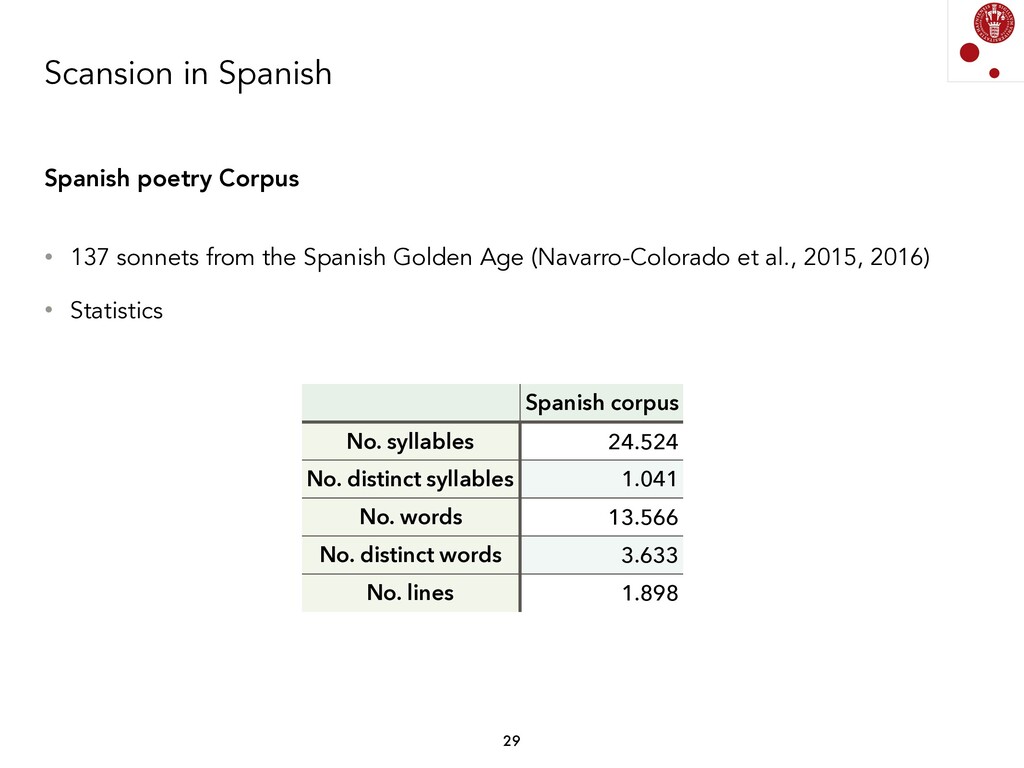{kind=link}
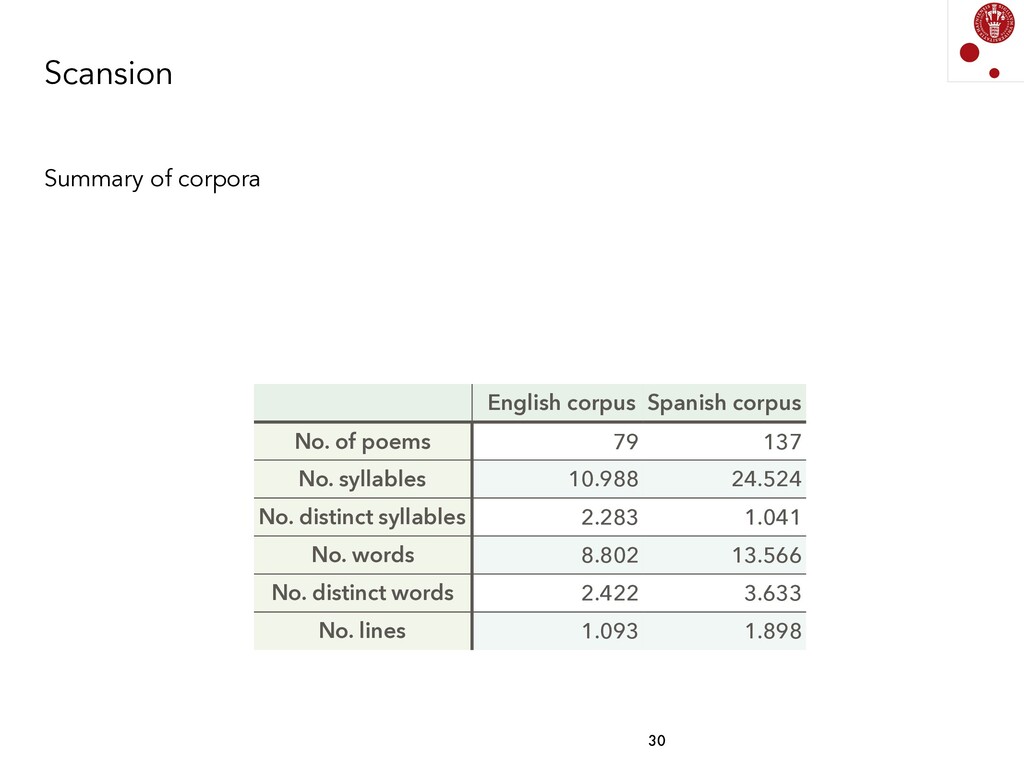{kind=link}
{kind=link}
{kind=link}
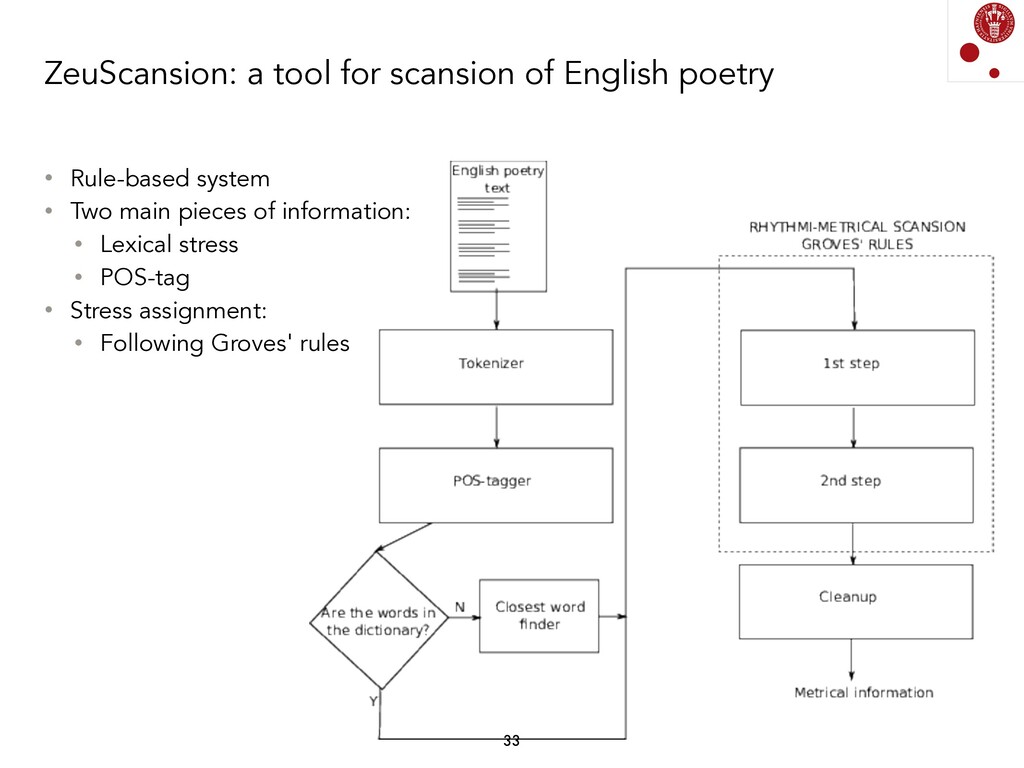{kind=link}
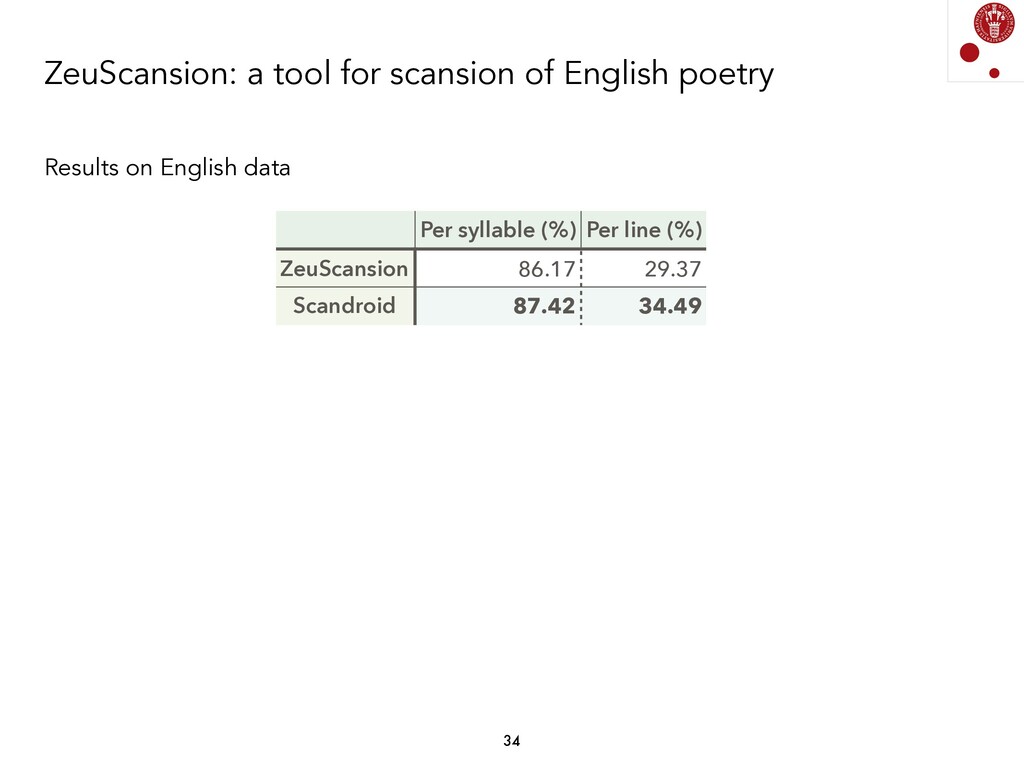{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}