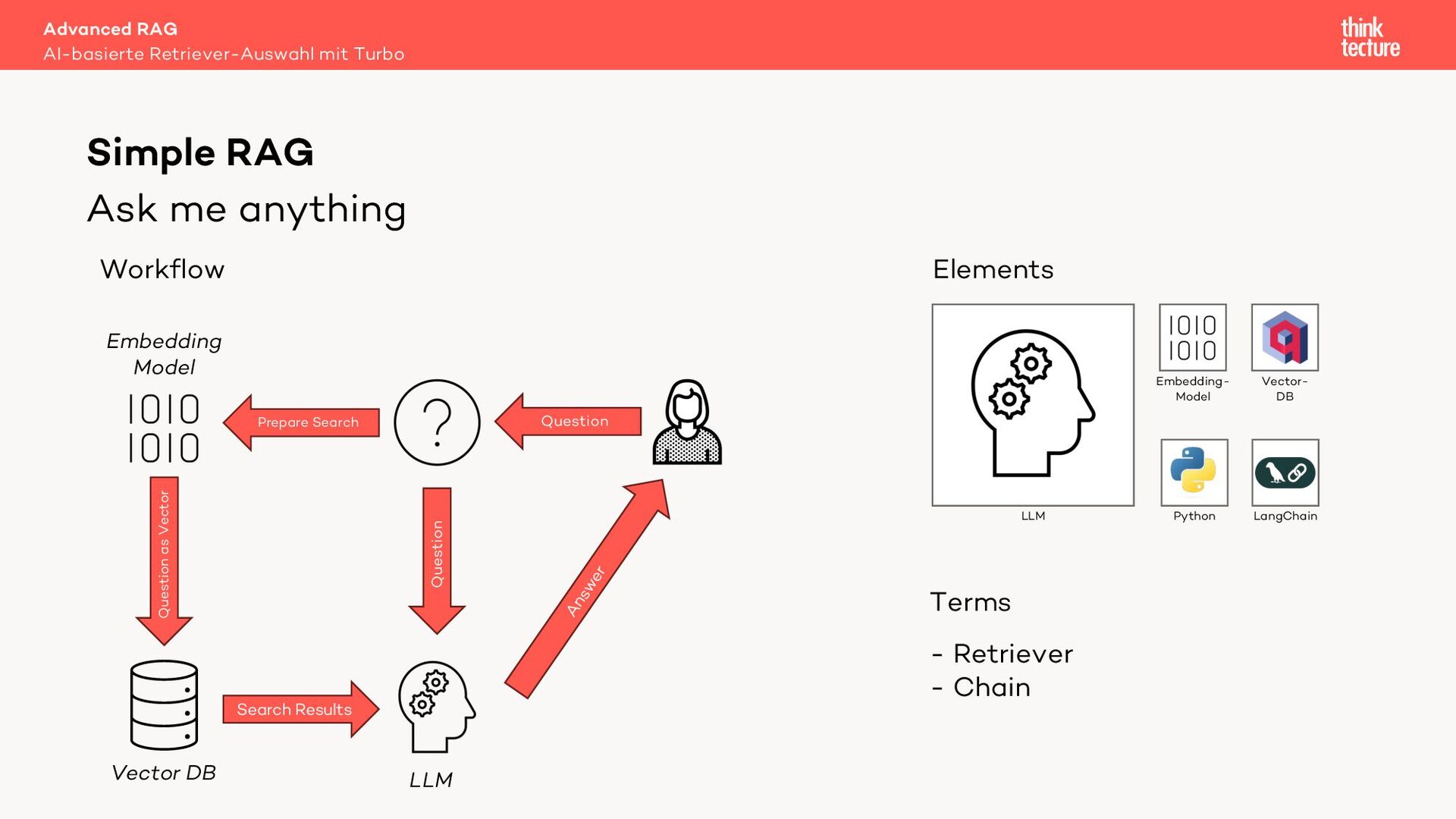
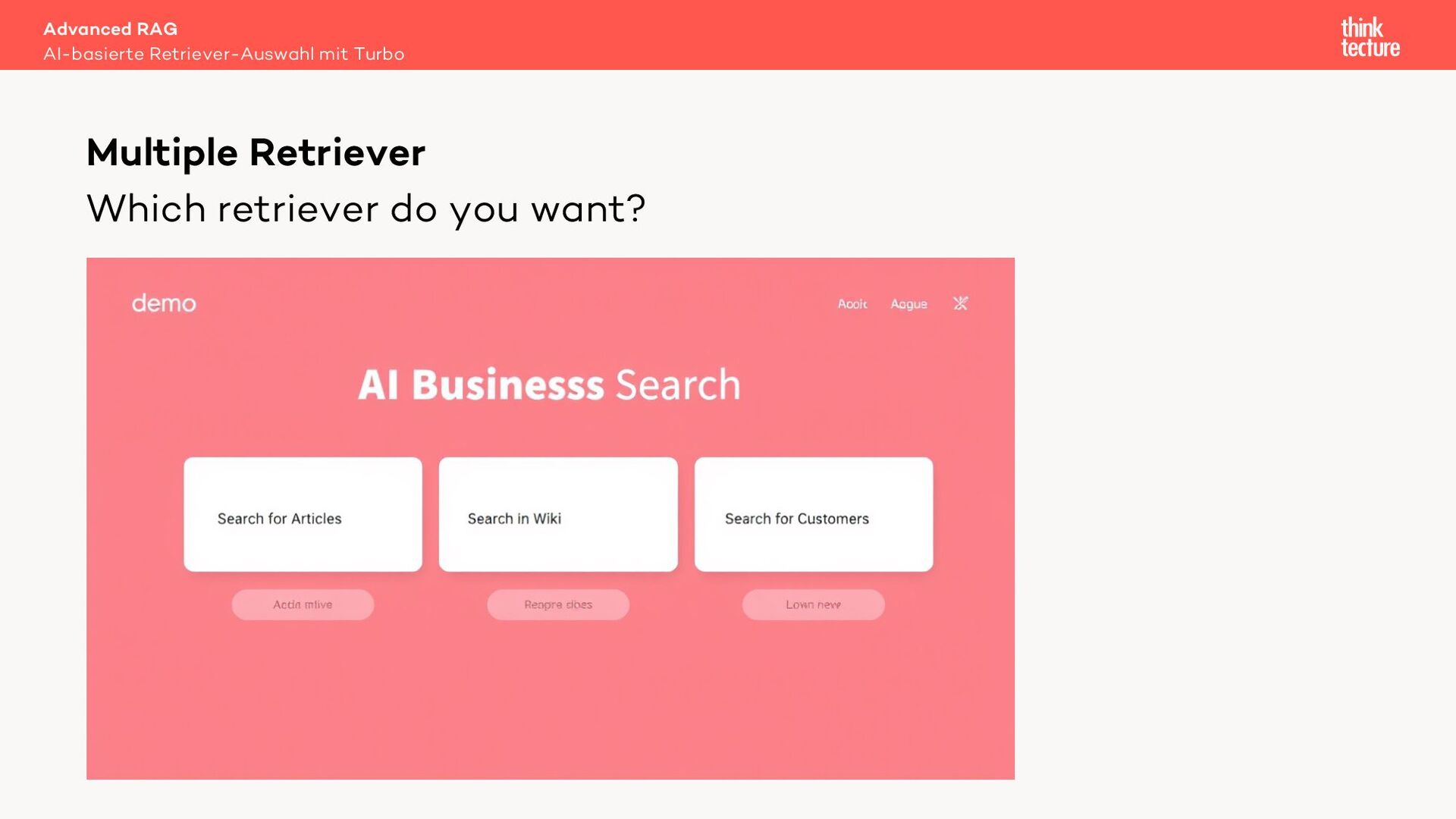
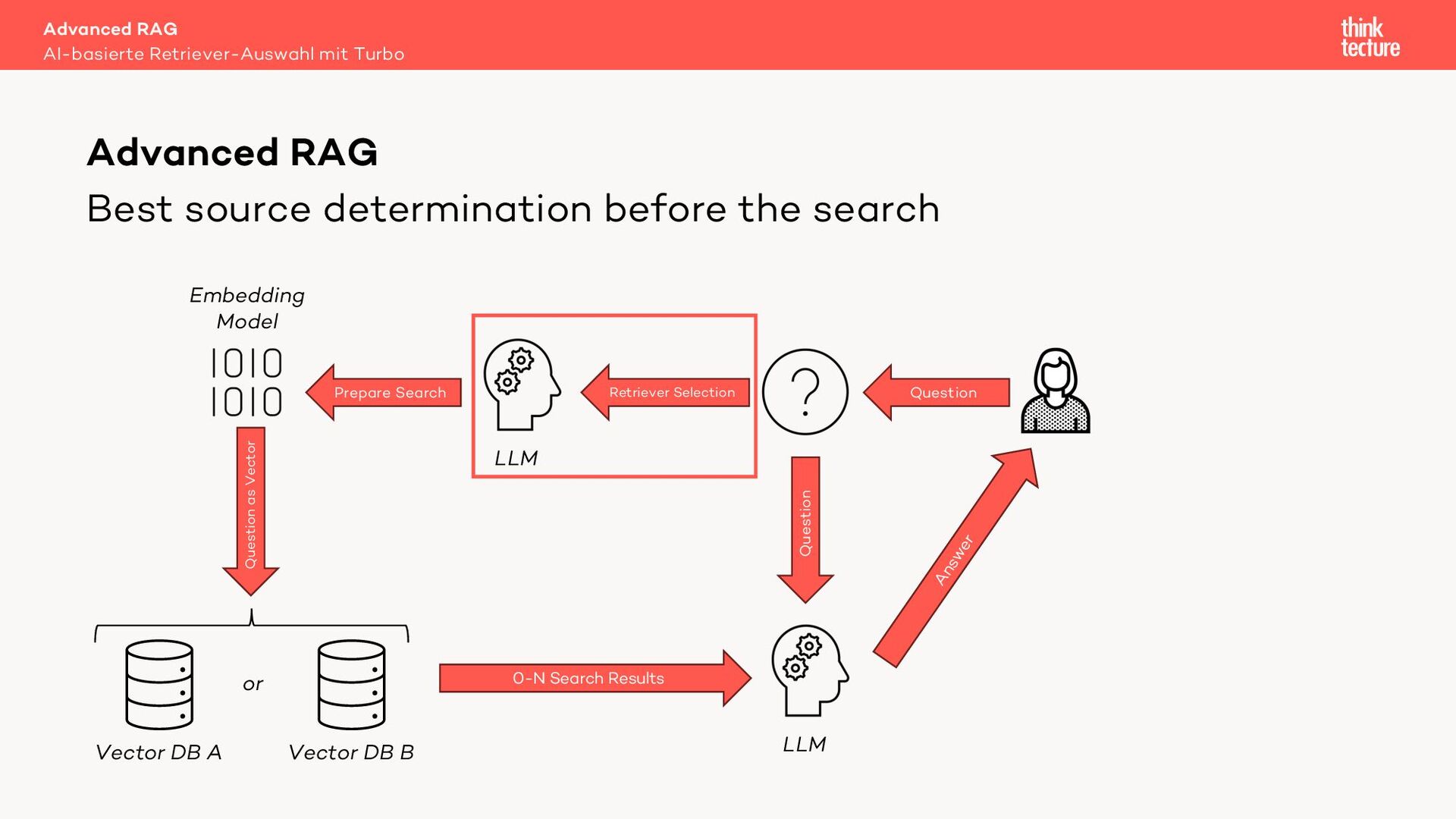
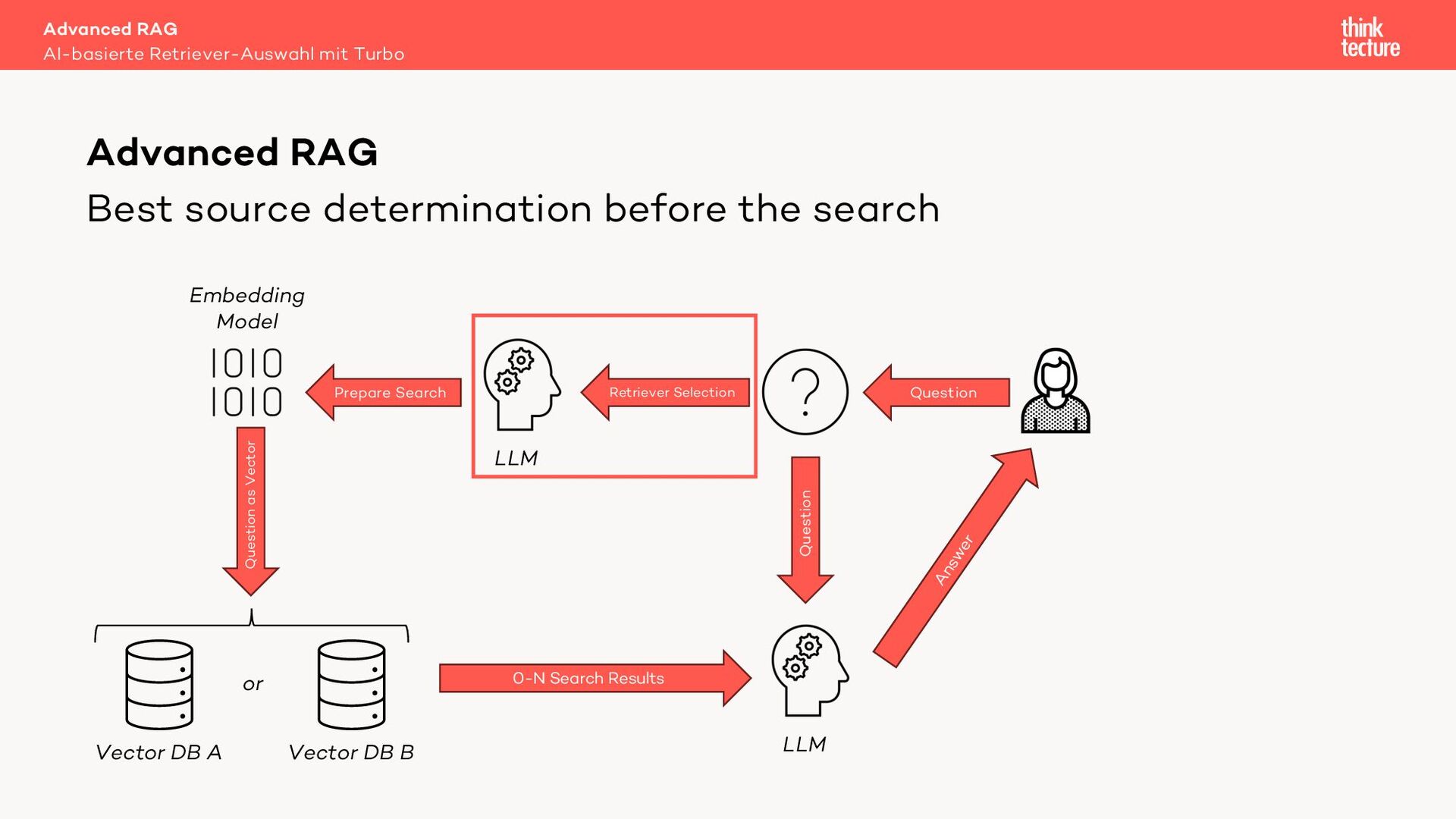
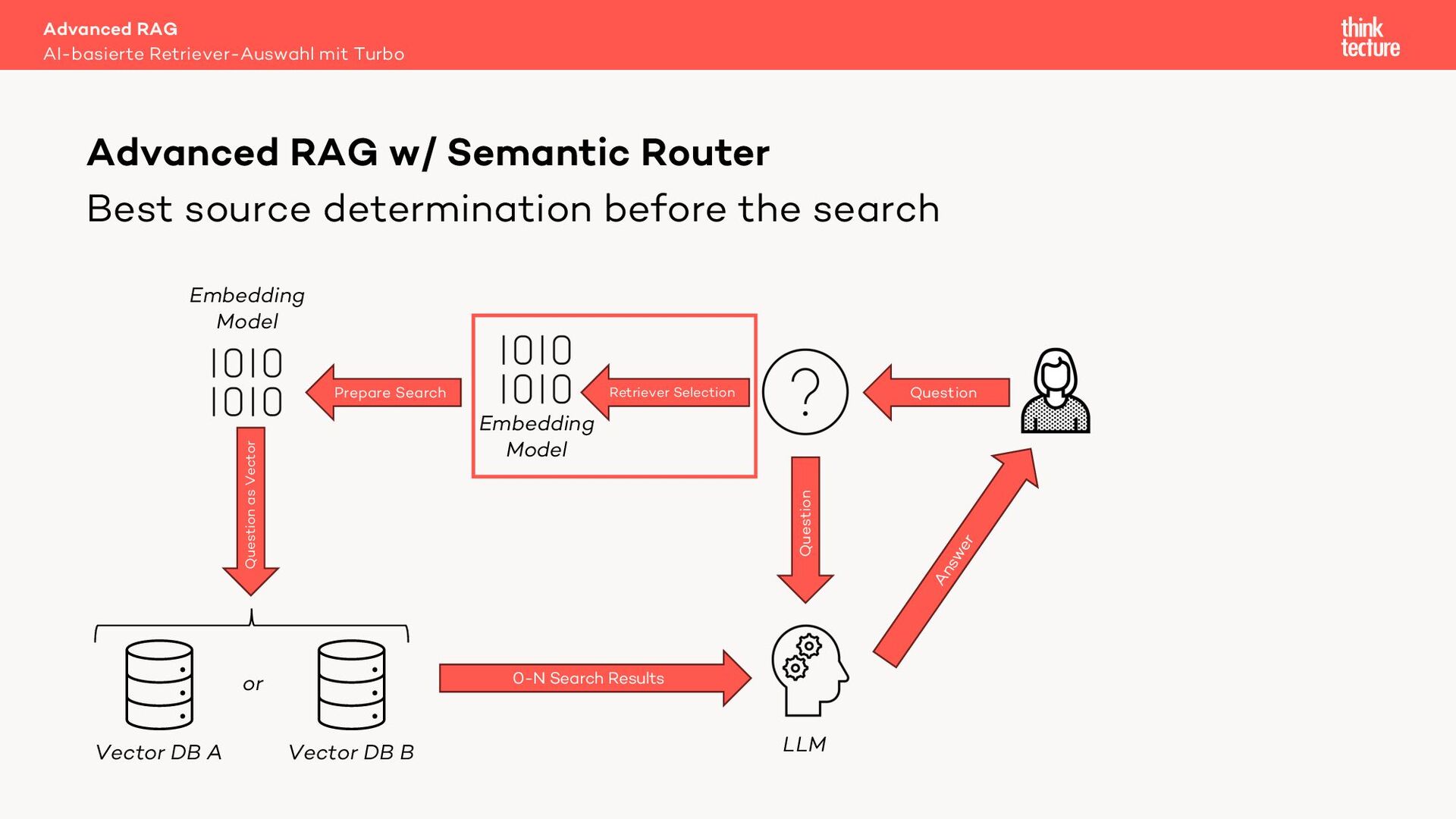
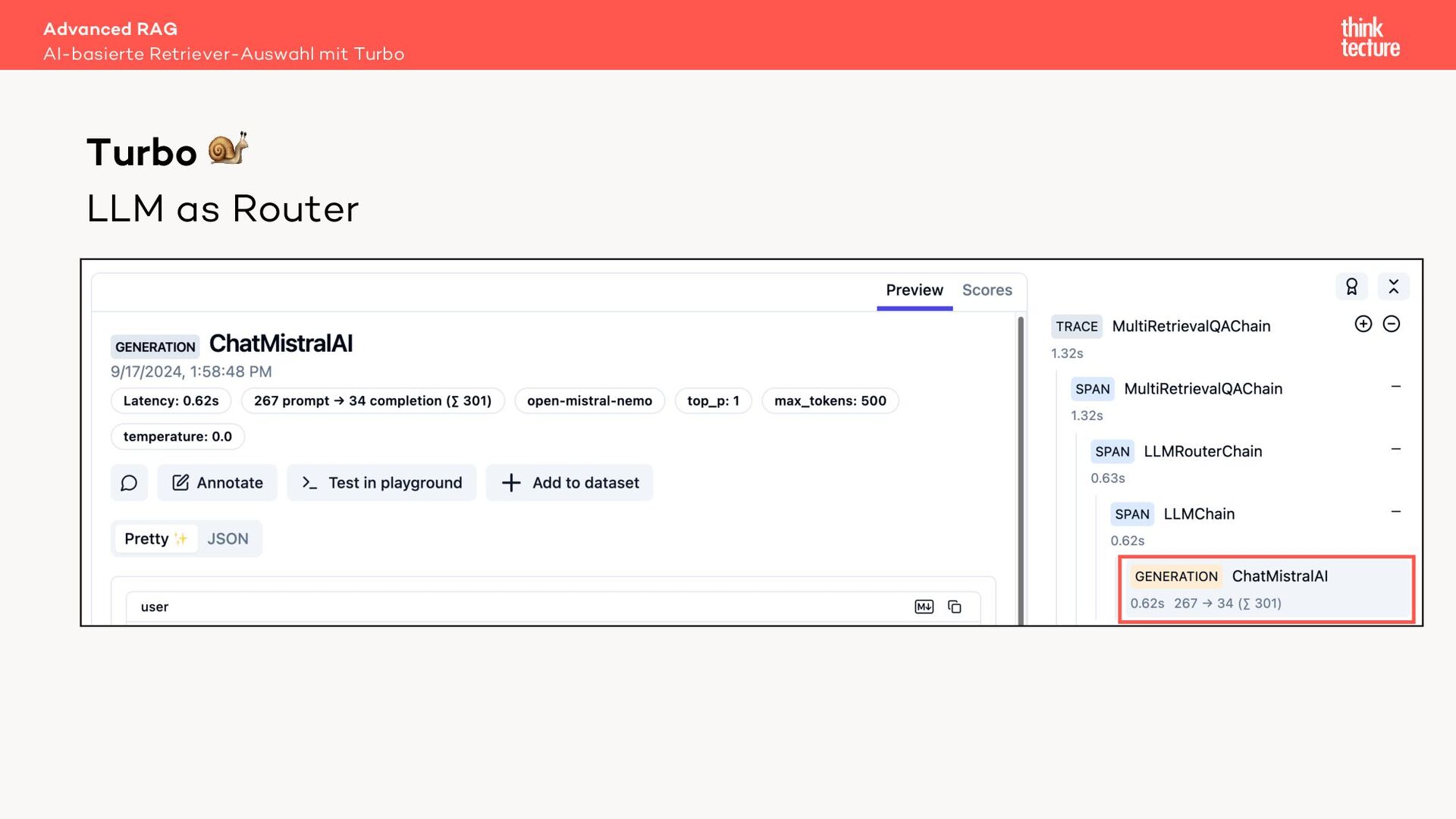
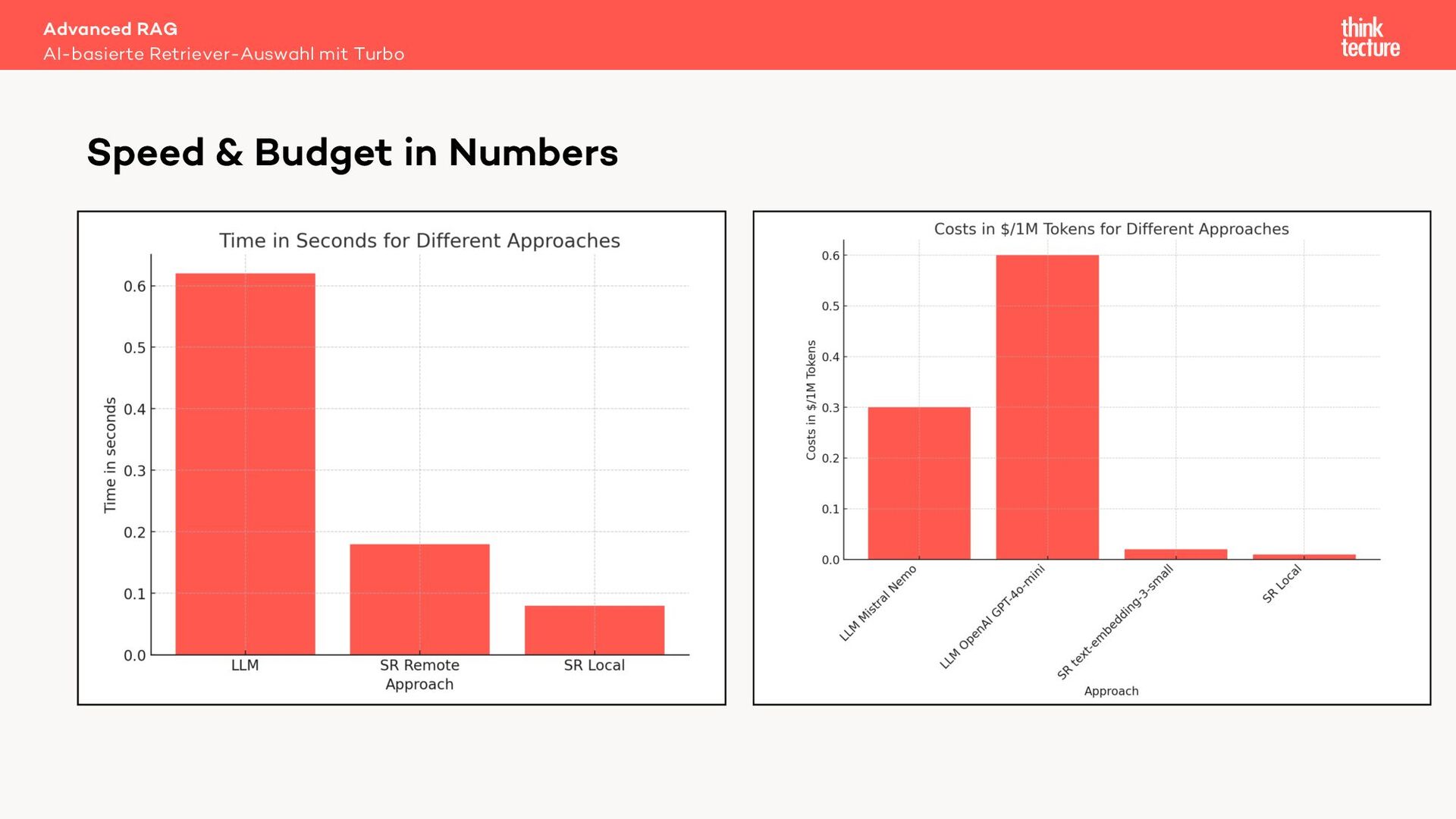
Retrieval Augmented Generation (RAG) verwendet Daten aus Retrieval-Systemen wie Vector-DBs, um die relevanten Informationen zur Beantwortung einer Benutzeranfrage zu finden. In Real-World-Szenarien geht es häufig um mehrere Quellen (Retriever) mit unterschiedlichen Datenarten. Um den zur Frage passenden Retriever auszuwählen, können wir eine MultiRoute-Chain nutzen. Hierbei wählt das LLM dynamisch die semantisch am besten passende Datenquelle für die Suche. Allerdings verlängert dieser Ansatz die Antwortzeit unseres AI-Workflows und kostet Tokens - also Geld.
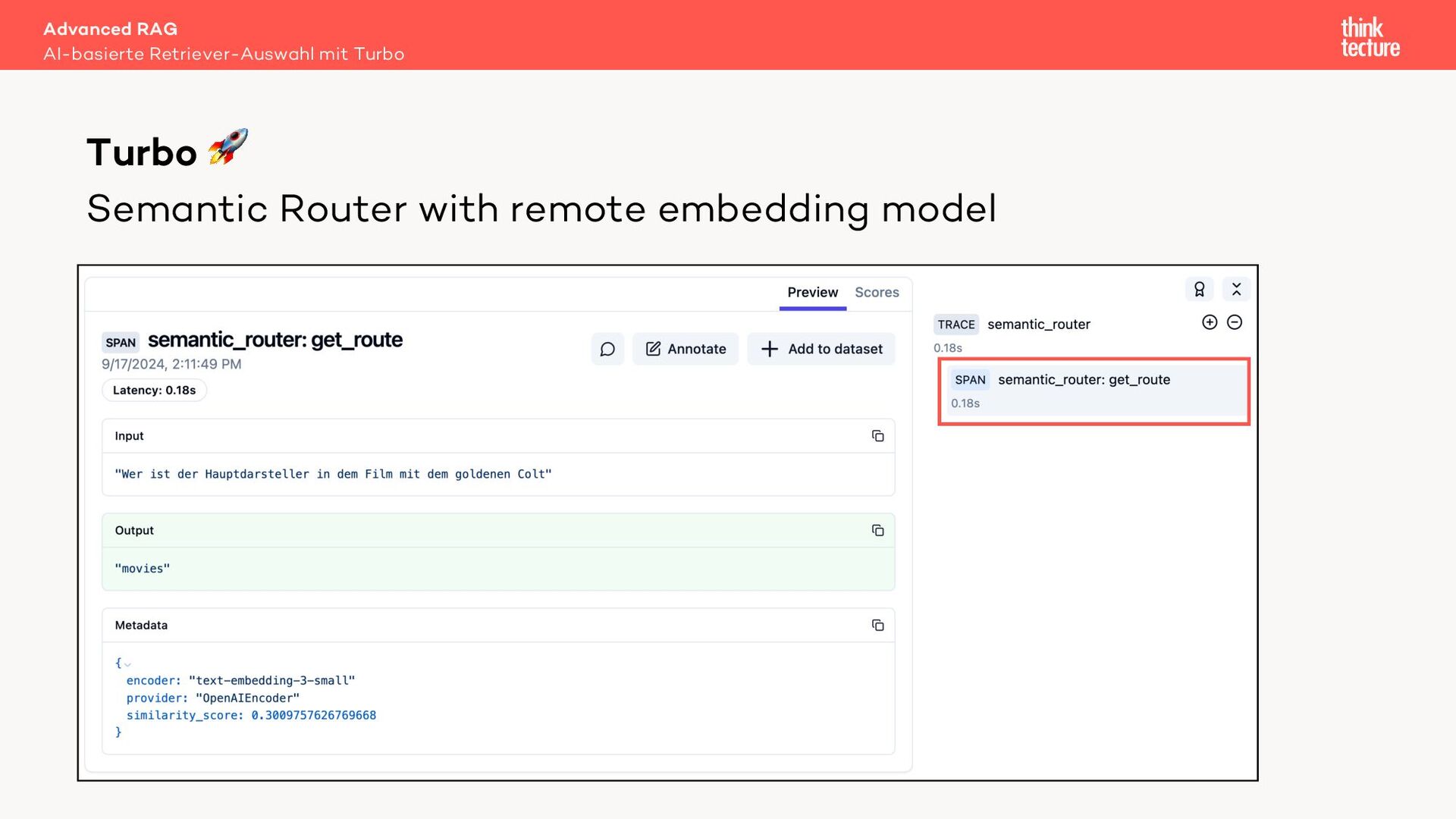
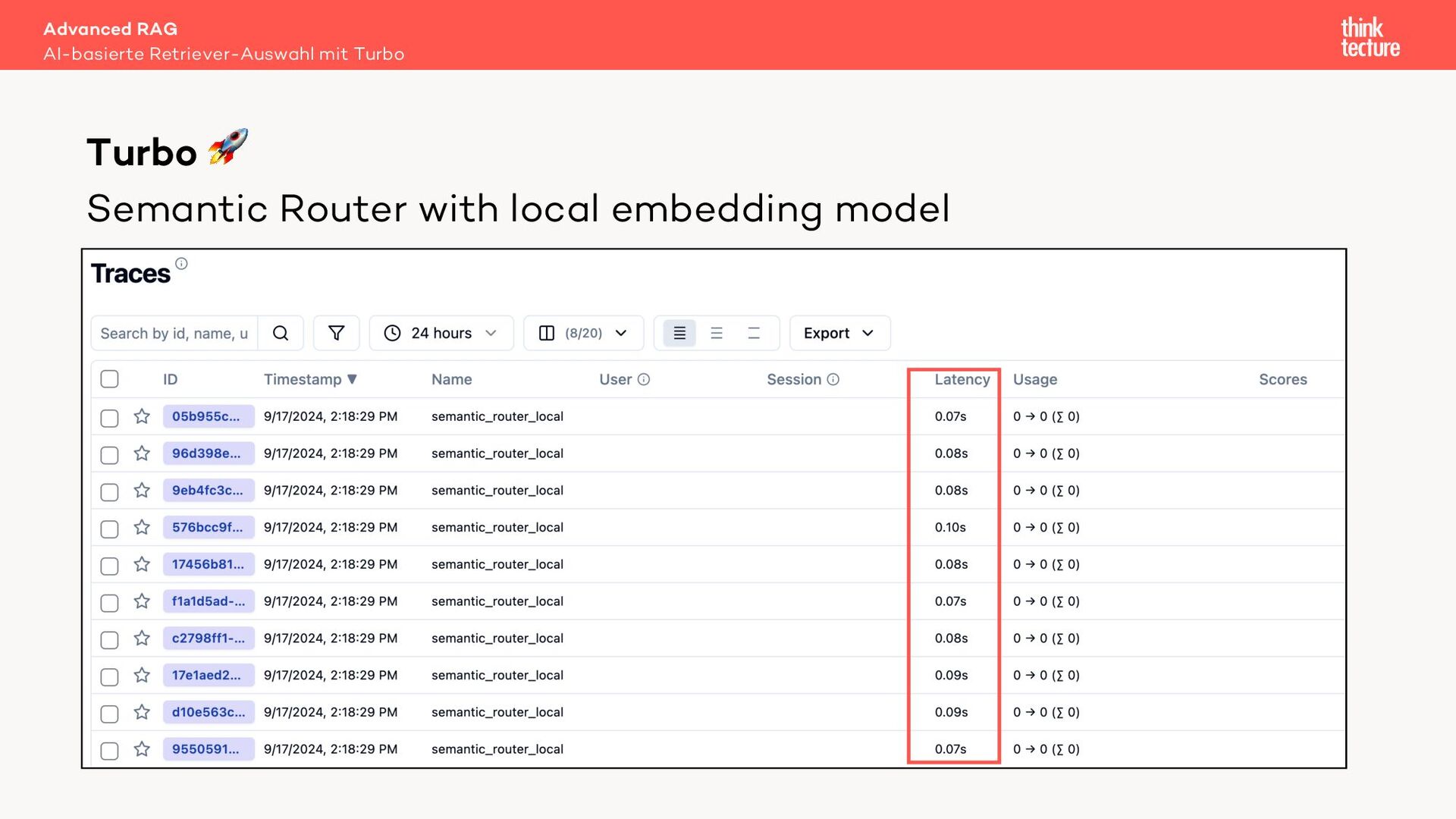
Geht das auch schneller und günstiger? Ja! Ein Semantic Router nutzt für die Quellenauswahl kein LLM sondern ein Embedding Modell. Dieser Ansatz liefert eine mit einem LLM vergleichbare Qualität bei der Quellenauswahl, jedoch in Millisekunden und zu einem Bruchteil der Kosten.
Mit Live-Coding implementieren wir in einem Sample unter Verwendung des LangChain-Frameworks zuerst eine MultiRoute-Chain und optimieren dann auf eine Variante mit Semantic Router. Letztendlich zeigen beide Ansätze, wie die Leistung von RAG bei der Beantwortung von Benutzeranfragen deutlich verbessert werden kann.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}