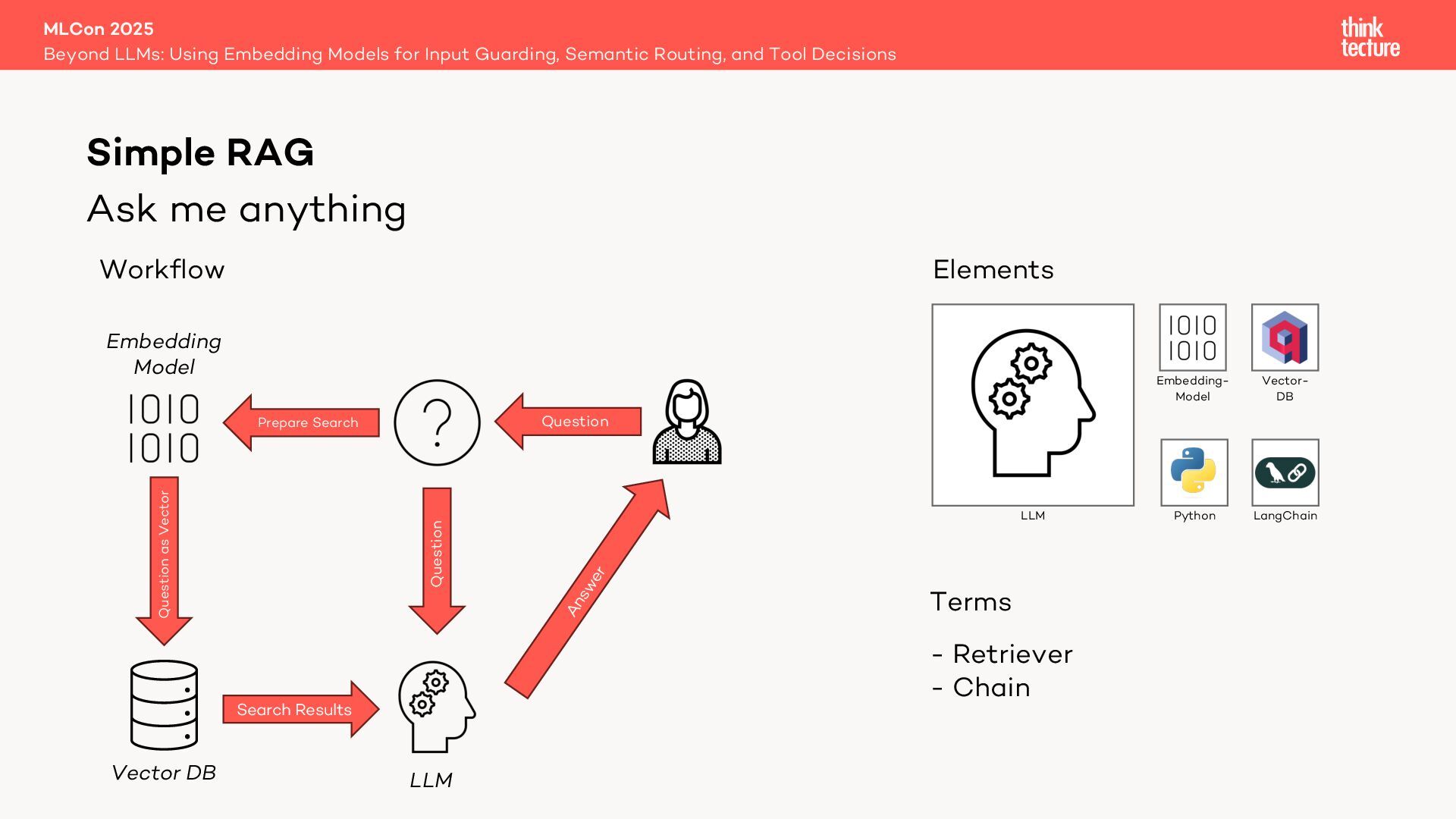
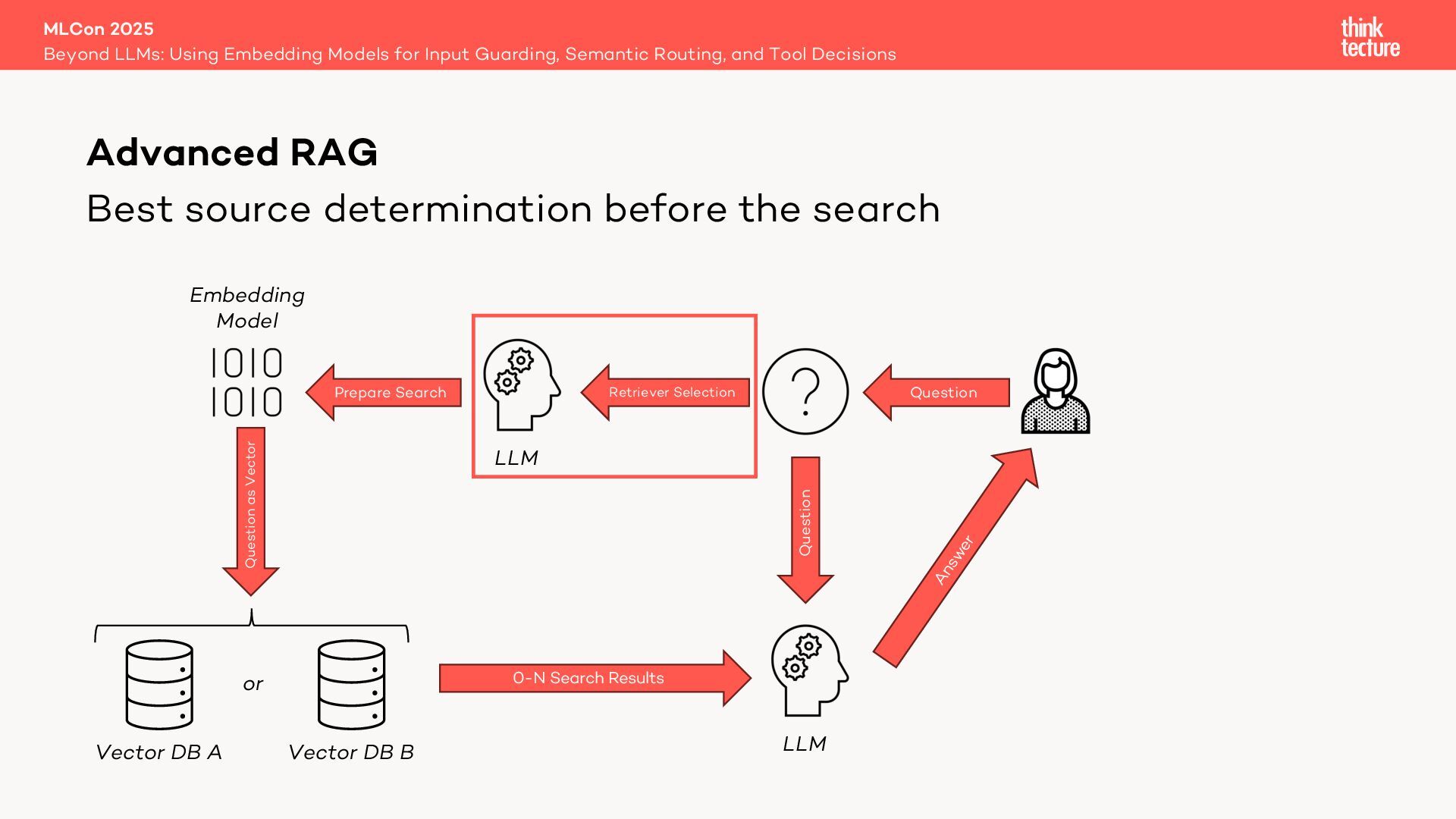
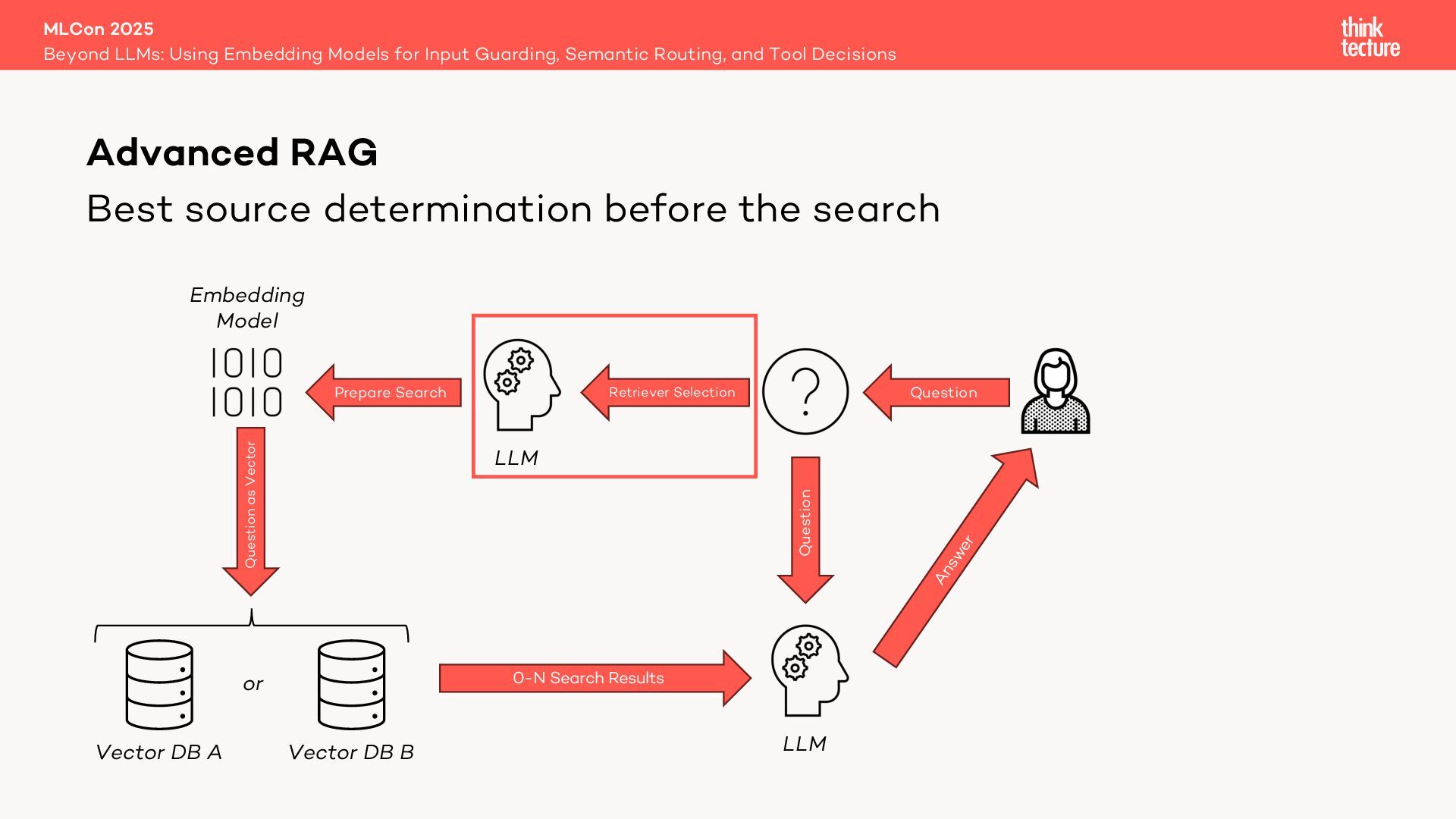
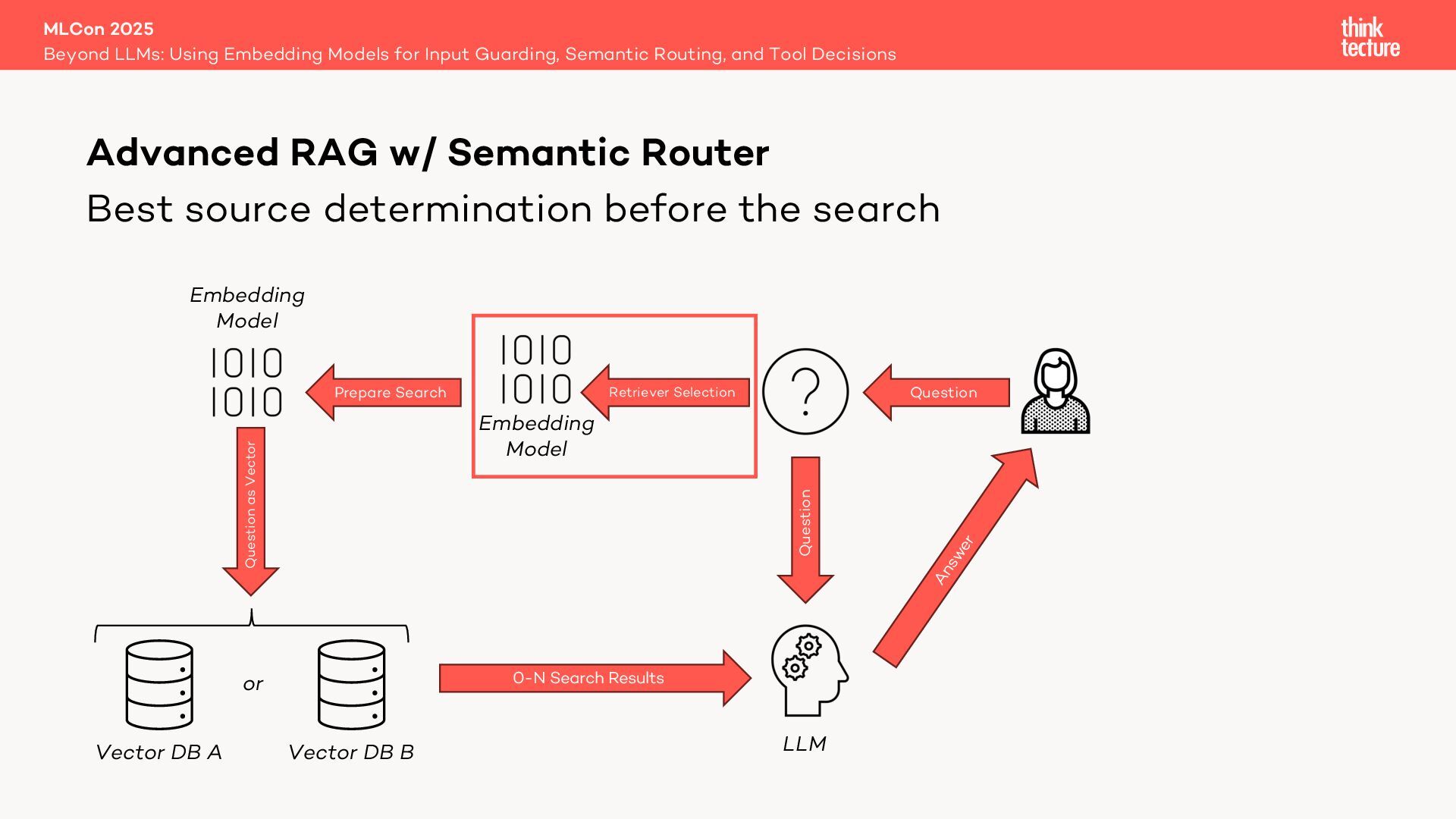
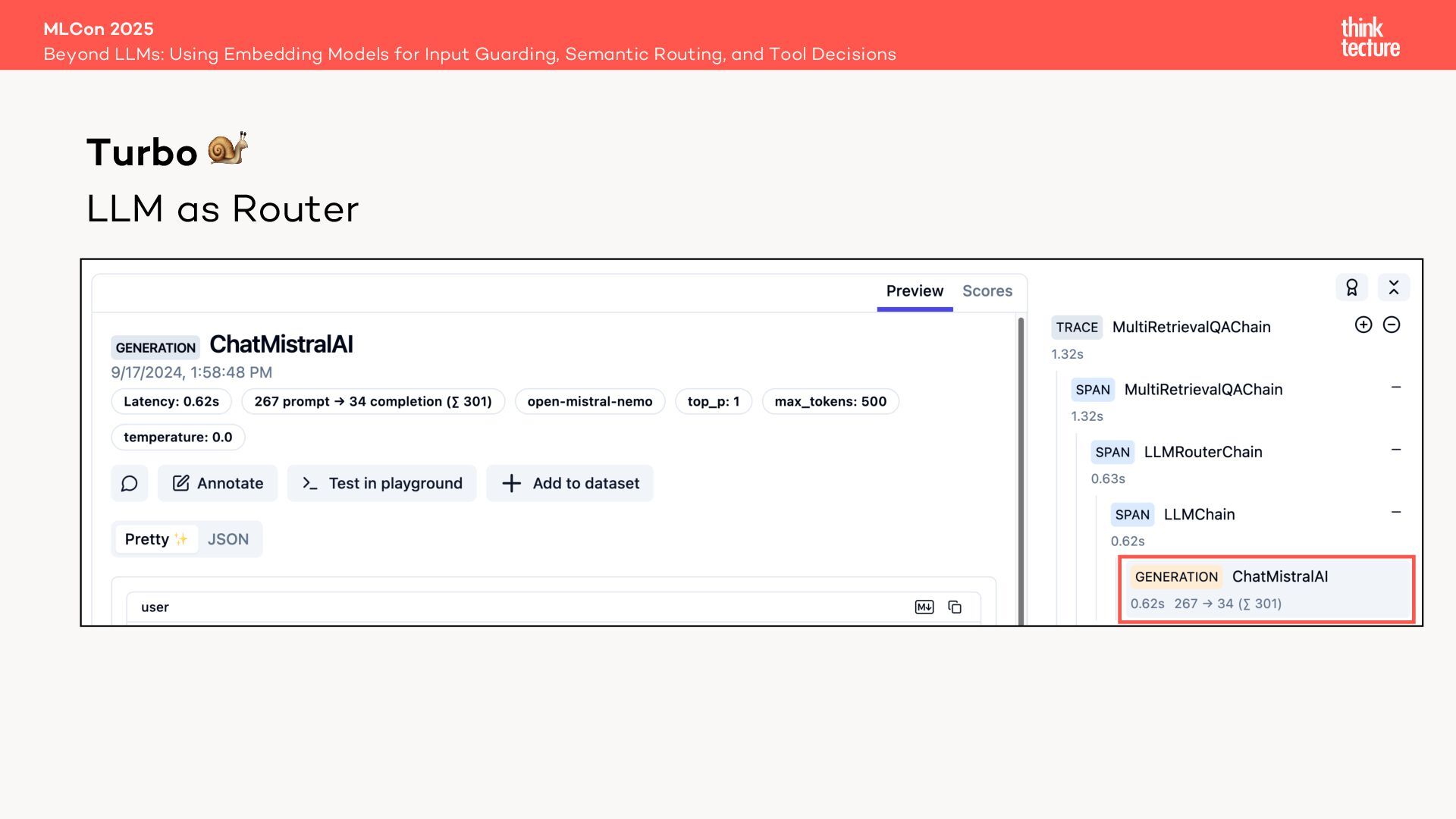
Retrieval Augmented Generation (RAG) leverages retrievers like vector databases to fetch relevant data for answering queries. In advanced RAG setups involving multiple data sources, selecting the best retriever is critical. Traditionally, in LangChain this is handled by a MultiRoute Chain, where a Large Language Model (LLM) dynamically chooses the optimal data source based on semantic fit. However, this approach can be slow, costly, and unpredictable.
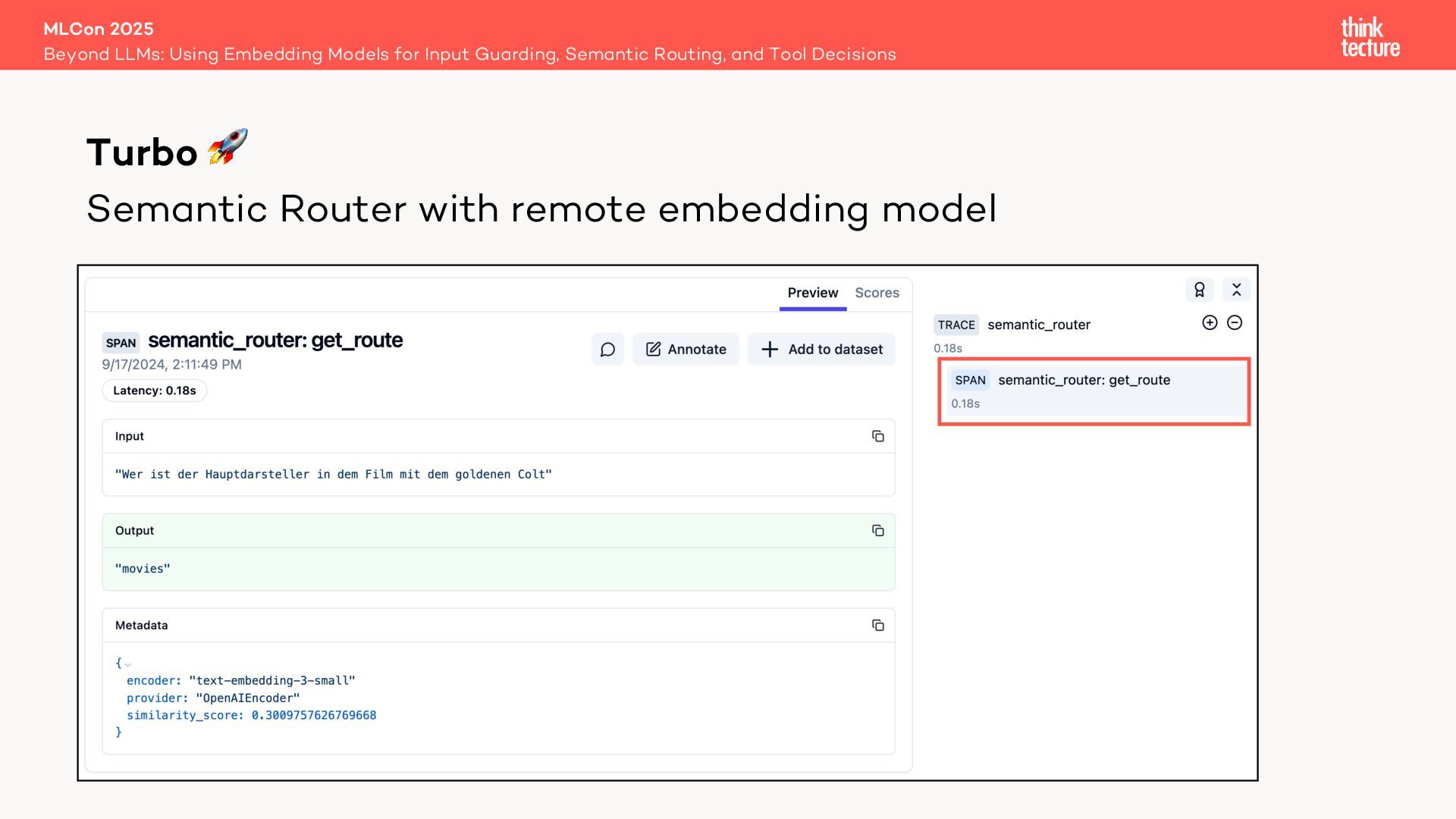
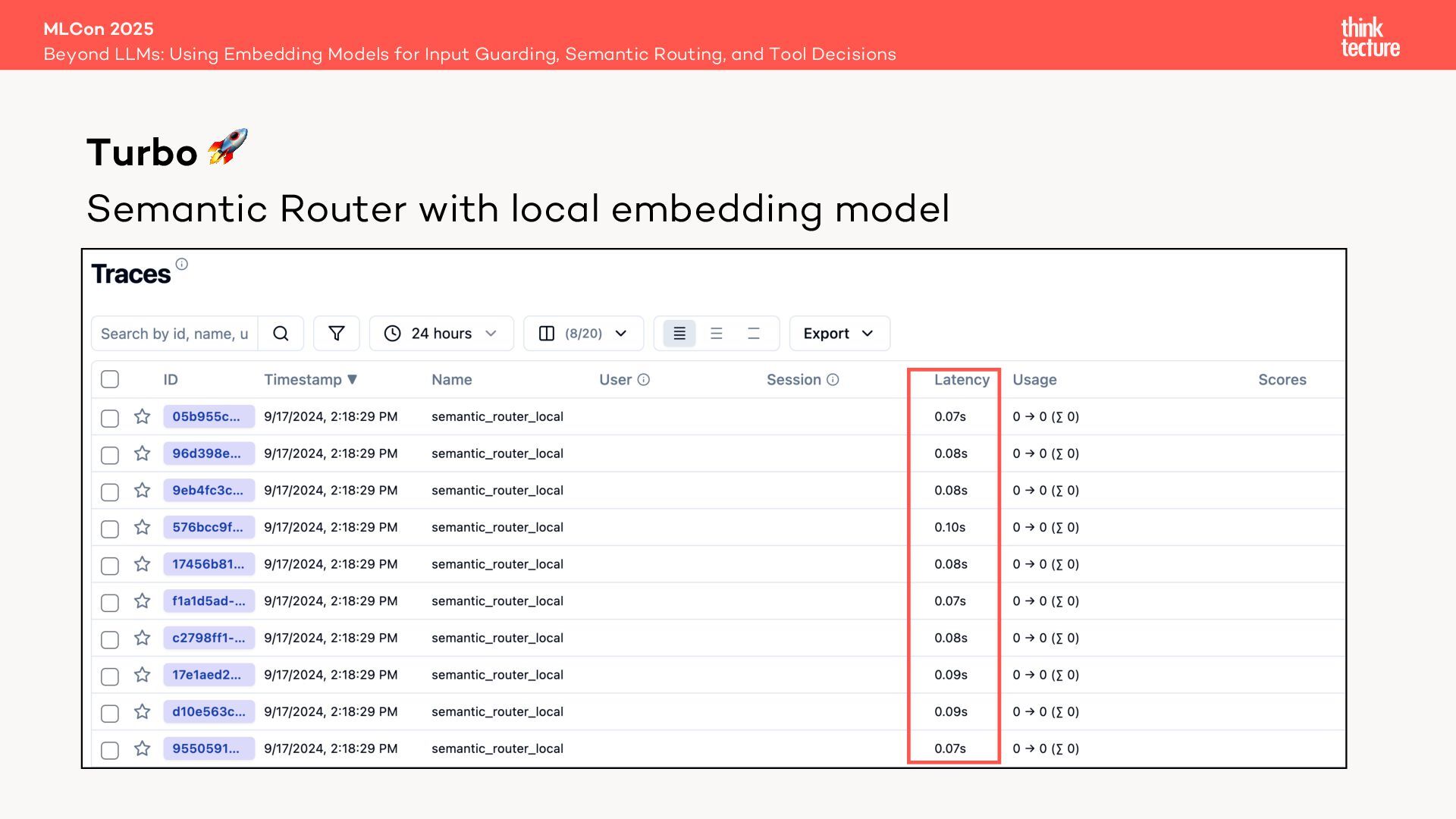
Enter the Open Source library Semantic Router—a faster, cheaper, and deterministic alternative that uses an embedding model for retriever selection without compromising quality.
In this talk, I’ll showcase the Semantic Router’s broader capabilities, including input guarding for AI applications and efficient tool selection for function calling.
Through live coding, we’ll first build a traditional MultiRoute Chain and then optimize it with Semantic Router, illustrating how this transformation can dramatically improve efficiency in RAG workflows.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}