Share
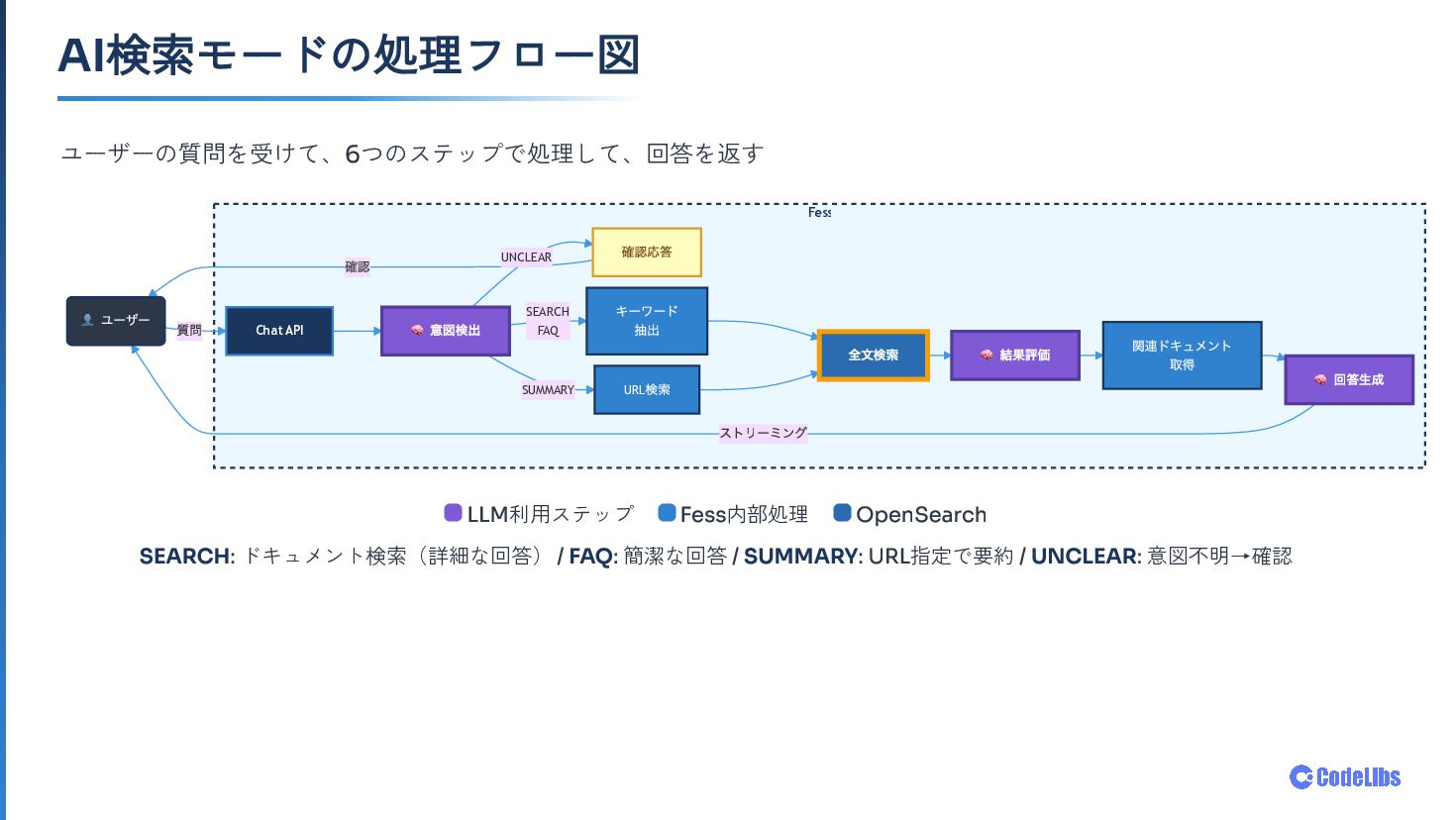
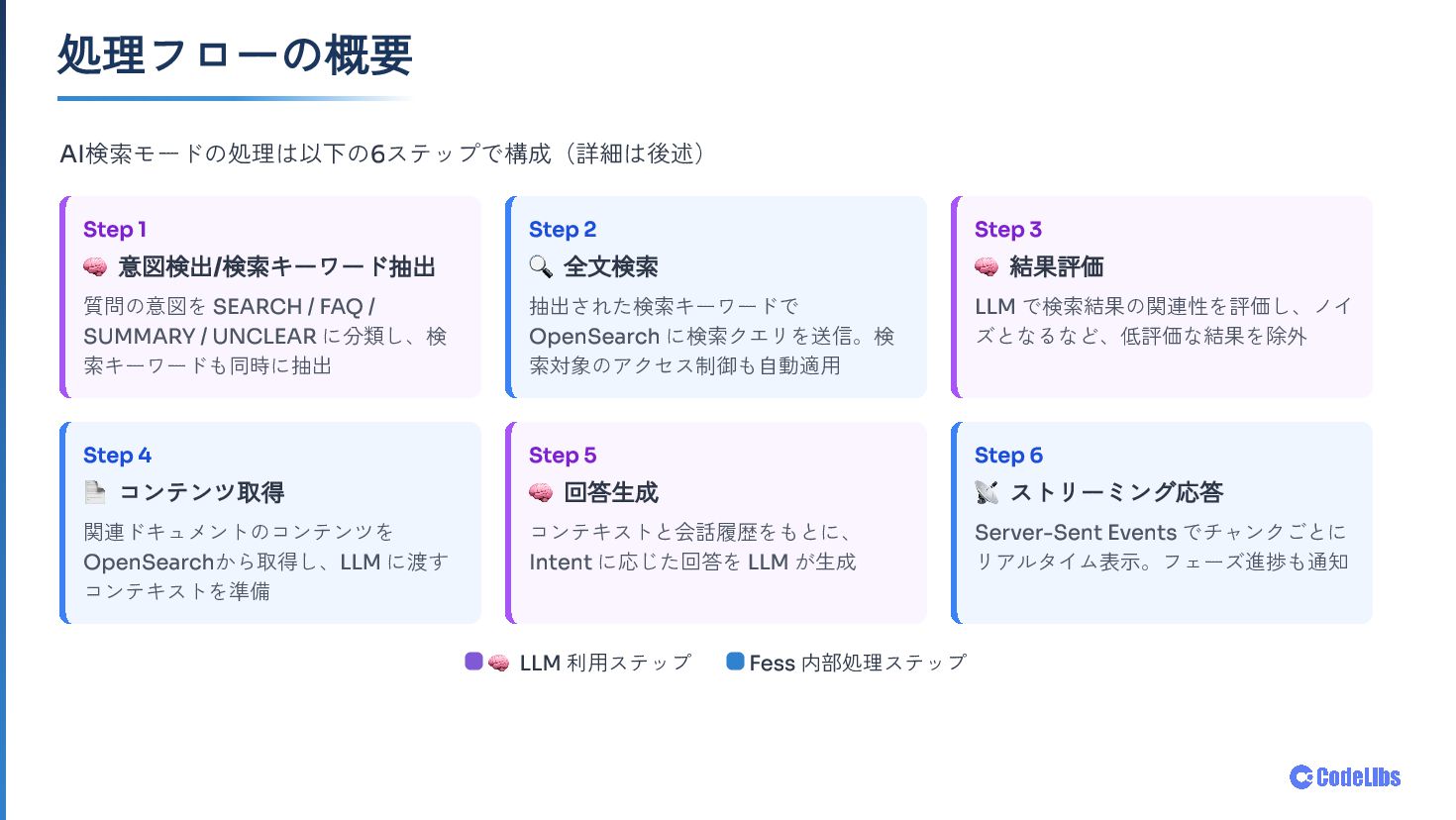
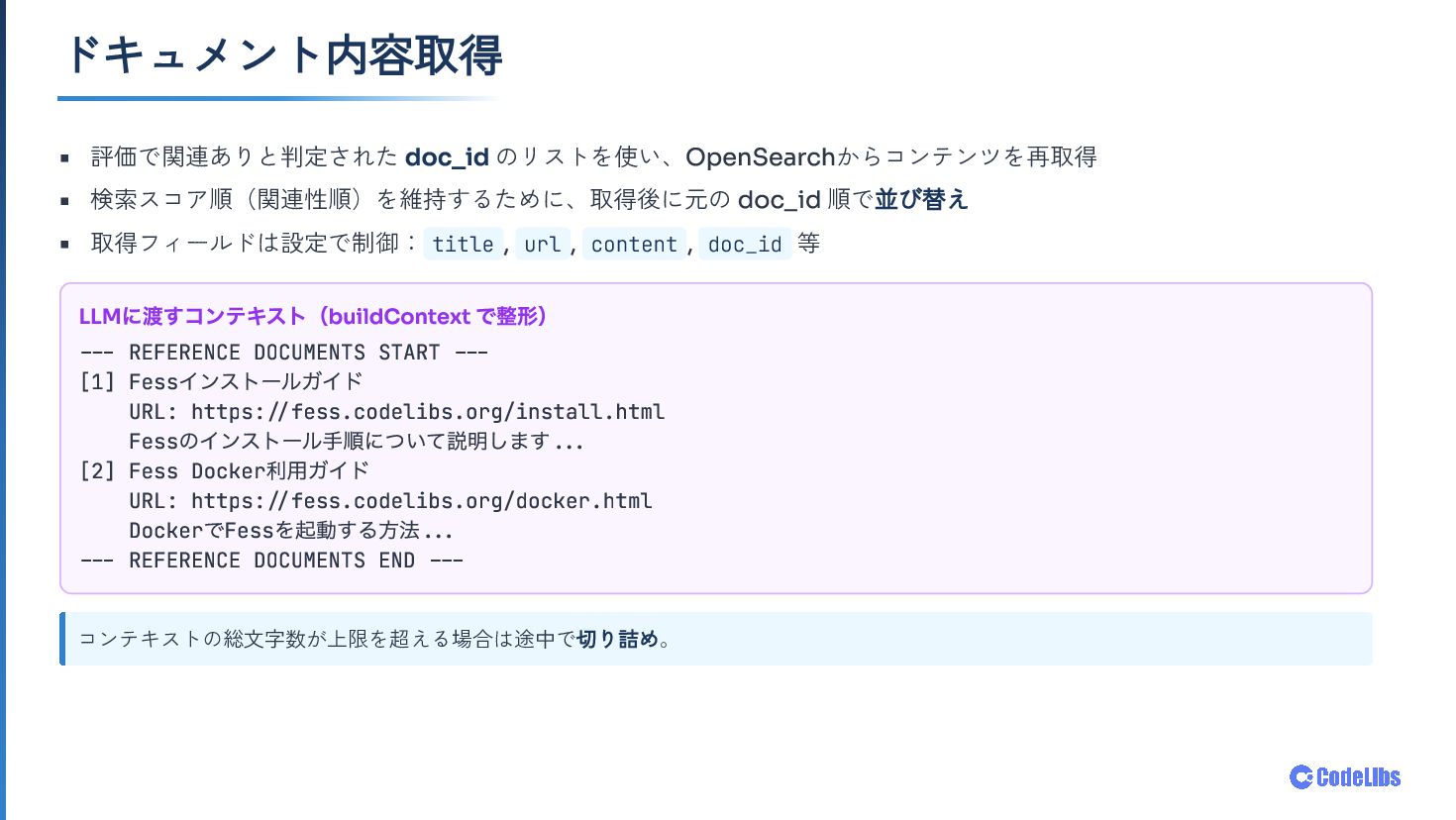
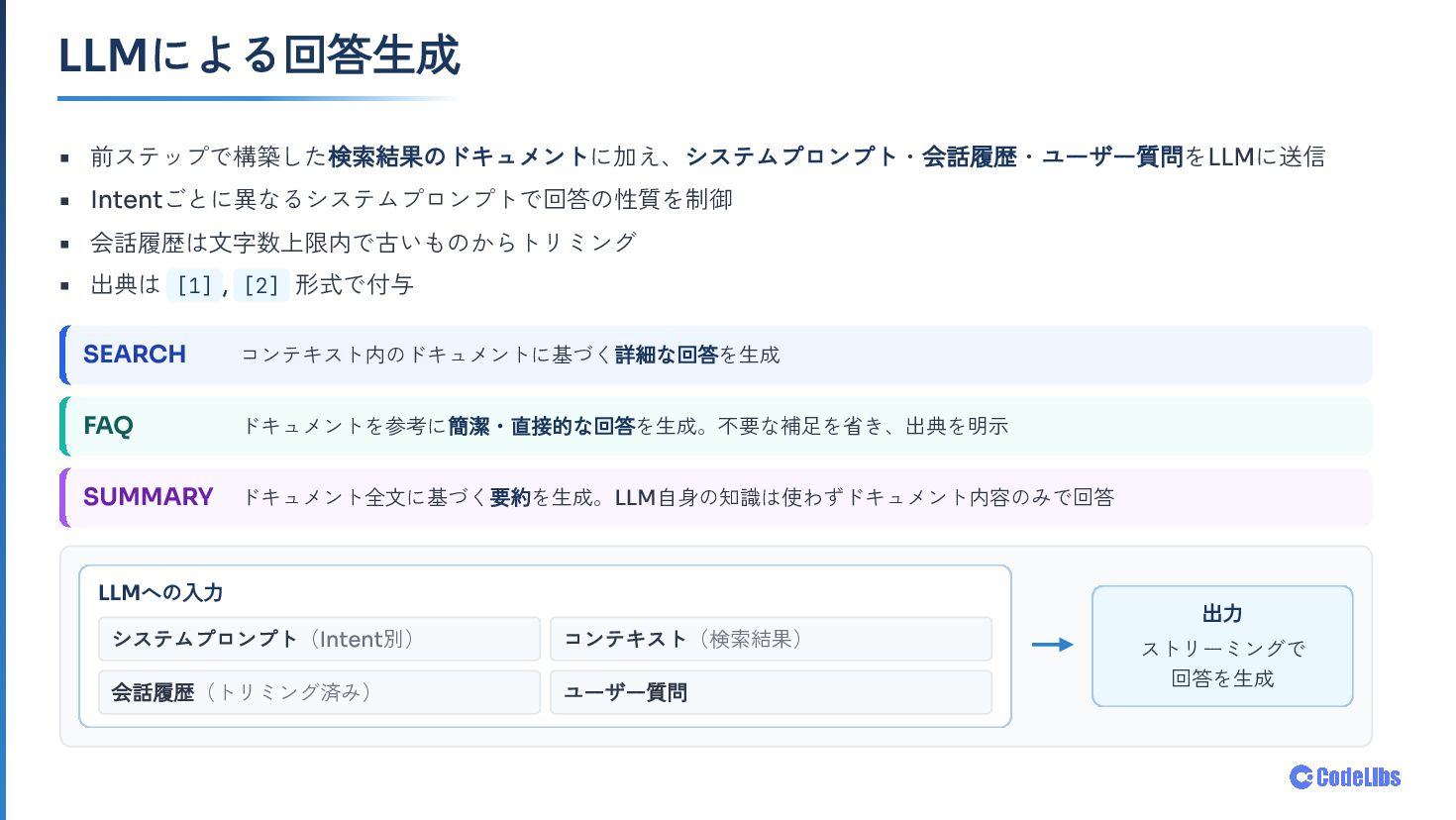
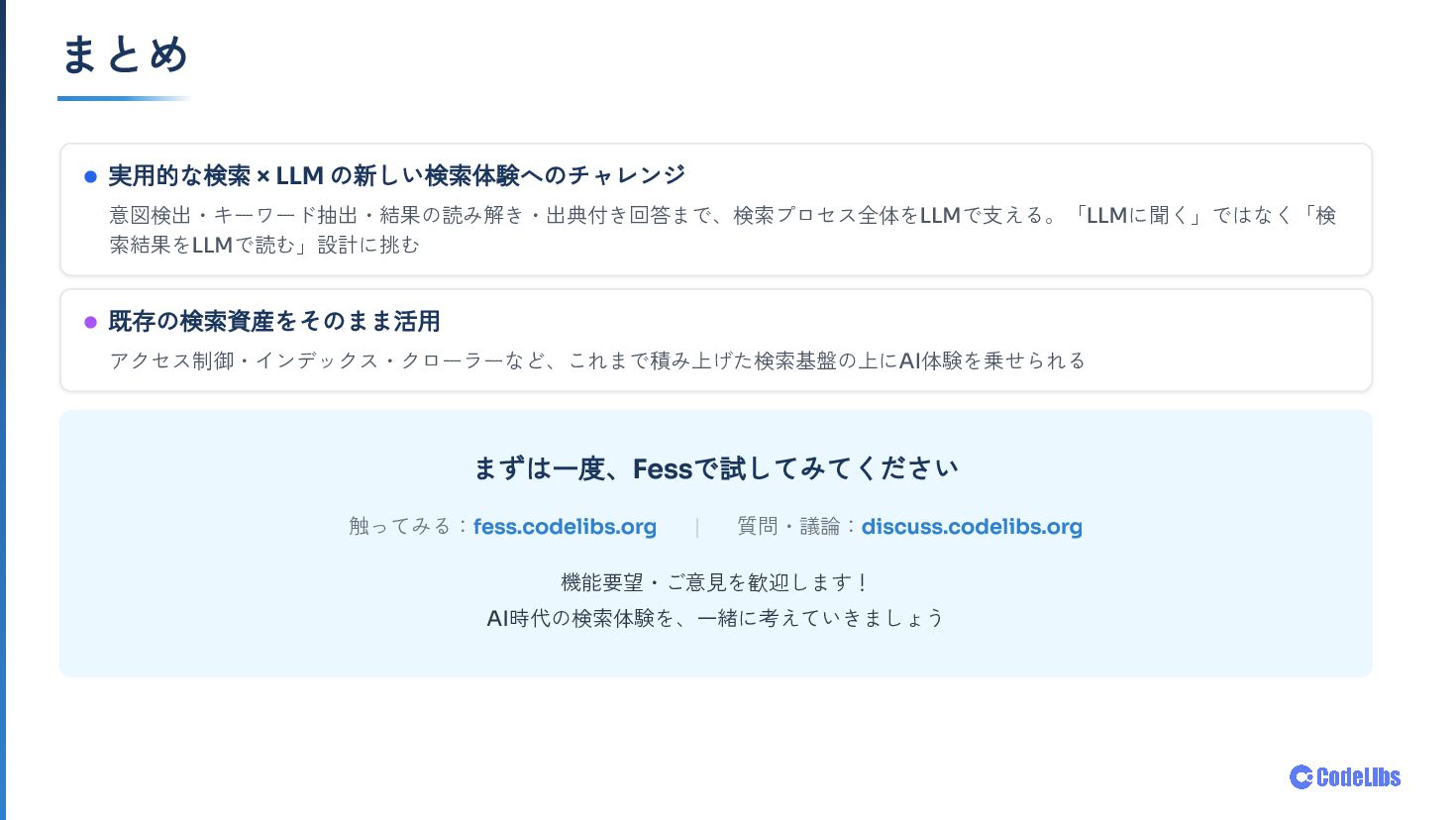
OSS全文検索サーバー Fess に搭載した AI検索モード について、検索システムとLLMの組み合わせ方を紹介します。意図検出・クエリ生成・関連性評価・回答生成まで、6ステップで構成される処理フローと、「LLMに聞く」ではなく 「検索結果をLLMで読む」 という設計思想を中心にお話しします。OpenAI/Gemini/Ollama などのLLMプロバイダー対応や、既存ACLをそのまま活かすセキュリティ設計、コンテキスト管理・UXの工夫にも触れます。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}