Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
PredictionIOのPython対応計画
Search
Shinsuke Sugaya
July 03, 2017
Technology
4.2k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
PredictionIOのPython対応計画
PredictionIOでPythonをどのように利用できるようにするかを説明します。
Shinsuke Sugaya
July 03, 2017
More Decks by Shinsuke Sugaya
See All by Shinsuke Sugaya
FessのAI検索モード:検索システムとLLMへの取り組み
marevol
0
770
社内ドキュメント検索システム構築のノウハウ
marevol
0
450
LastaFluteでKotlinをはじめよう
marevol
0
490
日本最大級の求人検索エンジン「スタンバイ」を支える技術
marevol
2
1k
Fess/Elasticsearchを使った業務で使える?全文検索への道
marevol
0
1.3k
PredictionIO構築入門
marevol
0
4.3k
全文検索システムFessを用いた 検索システム構築入門
marevol
0
3.1k
ESFluteによるElasticsearchでのO/Rマッパーを用いた開発
marevol
0
330
Elasticsearchベースの全文検索システムFess
marevol
0
290
Other Decks in Technology
See All in Technology
Control Planeで育てるBtoB SaaSの認証基盤 - SRE NEXT 2026
pokohide
1
2.6k
10年目を迎えた「ABEMA」がどのように AI 活用を推進して、AI 駆動開発にシフトしているのか / How ABEMA, entering its 10th year, is promoting the use of AI and shifting toward AI-driven development
miyukki
0
290
脱金融のフューチャー・デザイン / Future Design Beyond Finance
ks91
PRO
0
160
凡エンジニアがこの先生きのこるためには。〜TypeScript完全に理解したい〜
alchemy1115
2
310
AI時代のPlaywright活用(システムテストを自動化する ー 実行エンジンにPla ywrightを選んだ理由)
ynisqa1988
1
500
最適な自走を最小限の支援で — M&Aで拡大する組織で少人数SREが挑んだ1年 / SRE NEXT 2026
genda
0
1.5k
AI Driven AI Governance
pict3
0
490
Kaggleで成長するために意識したこと
prgckwb
2
420
ゴールデンパスは敷いただけでは道にならない ─ 企画部門のエンジニアが技術標準を事業価値に変えるまで
mhrtech
1
230
AI時代のYAGNI:「爆速で無駄になった機能」からの学び / 20260720 Naoki Takahashi
shift_evolve
PRO
3
320
AIコード生成×サプライチェーン攻撃 — PHPが直面する“二重の信頼問題
shinyasaita
0
210
型は壁、Rustでもバグを直すな、表現できなくせよ
nwiizo
14
2.1k
Featured
See All Featured
The Pragmatic Product Professional
lauravandoore
37
7.4k
YesSQL, Process and Tooling at Scale
rocio
174
15k
Music & Morning Musume
bryan
47
7.3k
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
460
Optimizing for Happiness
mojombo
378
71k
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
Information Architects: The Missing Link in Design Systems
soysaucechin
0
1k
Joys of Absence: A Defence of Solitary Play
codingconduct
1
410
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
Design and Strategy: How to Deal with People Who Don’t "Get" Design
morganepeng
133
19k
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
CoffeeScript is Beautiful & I Never Want to Write Plain JavaScript Again
sstephenson
162
16k
Transcript
Apache BizReach, Inc. Shinsuke Sugaya PredictionIO勉強会 第2回 Python対応計画
自己紹介 名前:菅谷 信介 会社:株式会社ビズリーチ AI室 興味があること: ・機械学習やDeep Learning等で解決方法を考える ・オープンソースのプロダクトを作る
Topics ・PredictionIOのPython対応を考える
PredictionIOの Python対応状況
Pythonを使えません…
がしかし… ・Pythonの機械学習系ライブラリは多い →scikit-learn, TensorFlow, Chainer,... ・Jupyterとかで分析したい →matplotlibで普通にグラフを書きたい この手のニーズは普通にあるのでは?
どう実現するか? PredictionIOは主に以下の機能がある ・イベントサーバ →RESTでデータを登録するので、Python対応不要 ・学習処理 →Spark上で動くので、Python対応必要 ・予測サーバ →Spark MLであれば、対応不要 →scikit-learnなどのモデルを作った場合は要対応
対応する箇所 ・学習処理 →PySparkを使えるようにする ・予測サーバ →Python独自のモデルへの対応 →(学習処理対応後に考える…)
PySpark
PySparkとは ・Sparkを実行するためのPython API ・pysparkを実行するとインタラクティブモードで起動 $ ./bin/pyspark Welcome to ____ __
/ __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 2.1.1 /_/ Using Python version 3.5.2 (default, Oct 31 2016 16:46:00) SparkSession available as 'spark'. >>>
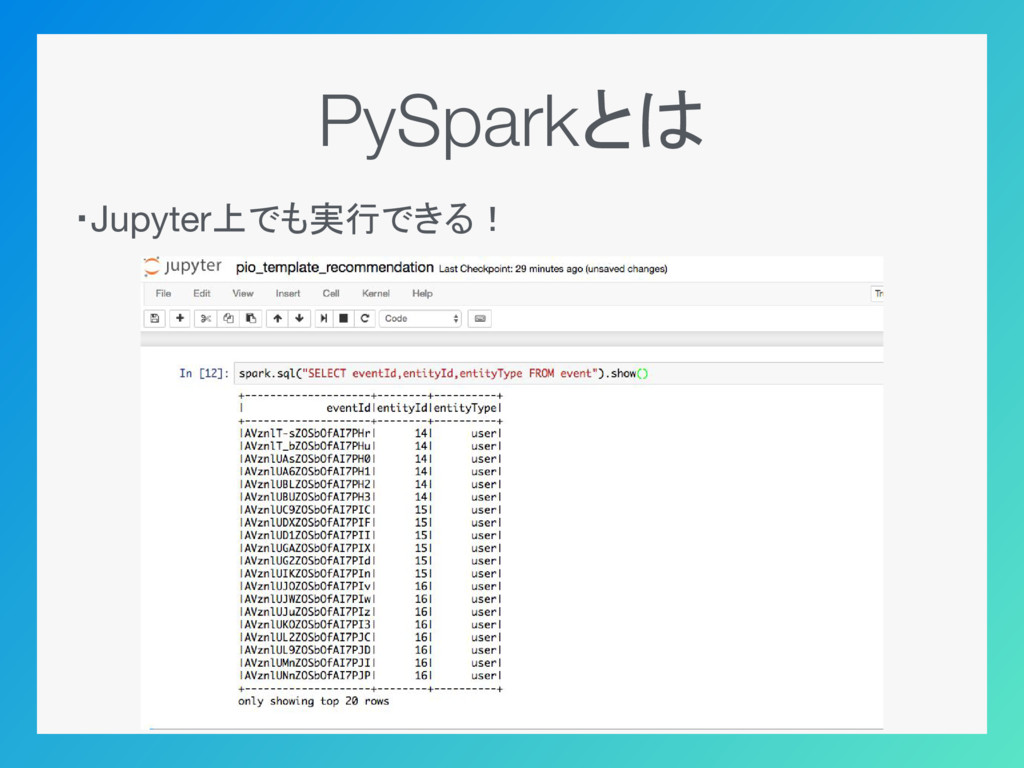
PySparkとは ・Jupyter上でも実行できる!
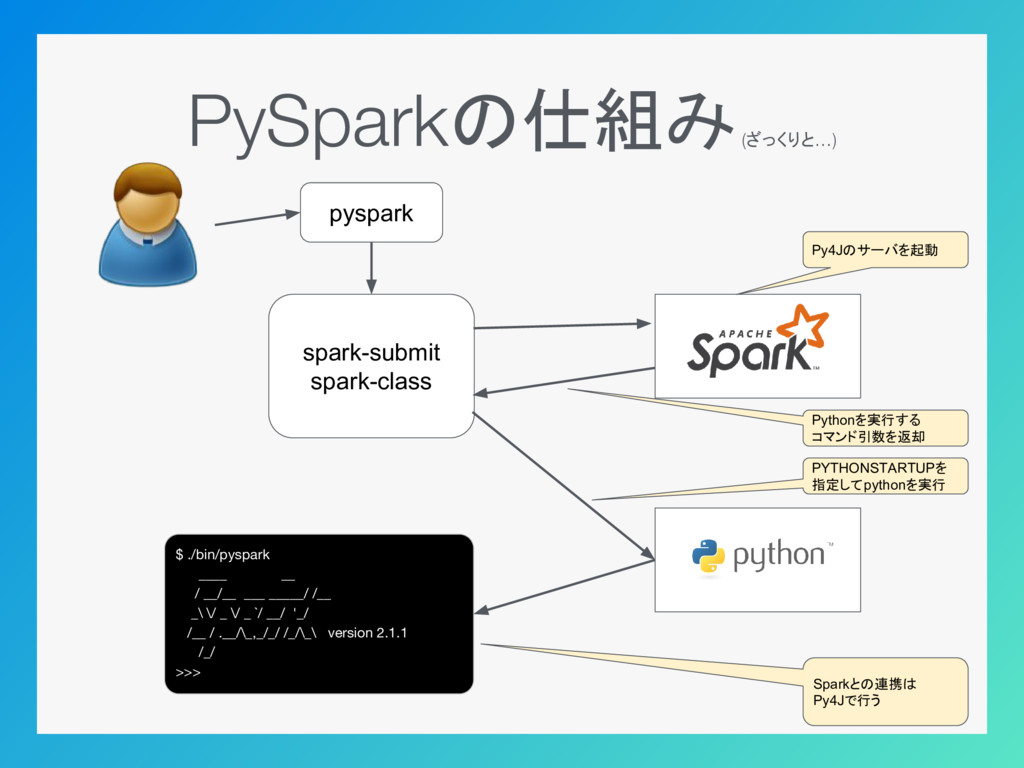
PySparkの仕組み (ざっくりと…) pyspark spark-submit spark-class $ ./bin/pyspark ____ __ /
__/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 2.1.1 /_/ >>> PYTHONSTARTUPを 指定してpythonを実行 Pythonを実行する コマンド引数を返却 Py4Jのサーバを起動 Sparkとの連携は Py4Jで行う
PIOとPySpark
前提 ・データはイベントサーバ上にある →RDDやDataFrameはPEventStoreから取る ・実行しているテンプレートの情報が必要 →pioコマンド経由で実行する
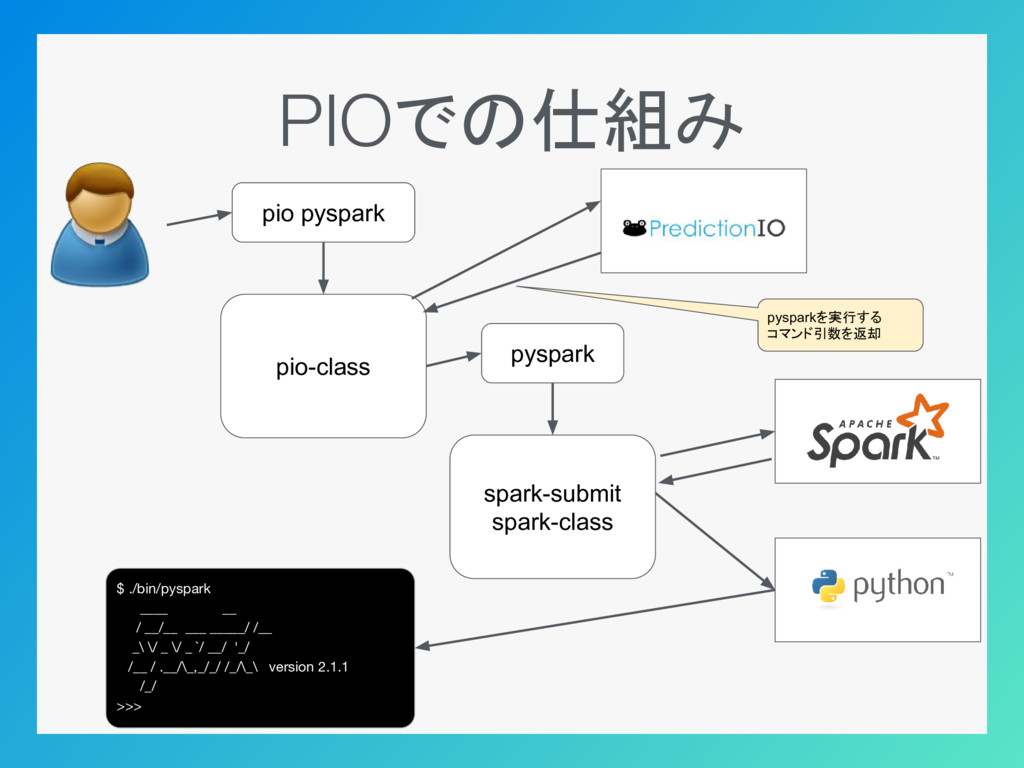
PIOでの仕組み pio pyspark pio-class $ ./bin/pyspark ____ __ / __/__
___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 2.1.1 /_/ >>> pysparkを実行する コマンド引数を返却 pyspark spark-submit spark-class
開発 ・以下のブランチで開発を始めました https://github.com/jpioug/incubator-predictionio/tree/pyspark ・将来的にはApacheに入れる予定
課題 作業を始めると様々な壁に遭遇… ・Python上ではSpark上のPy4Jの参照 →pysparkは参照をラップして使いやすくしてる ・Python-Py4J-Java-Scalaでのアクセスが必要 →Pythonからアクセスしにくい ・PIOは主にRDDを使っている →DataFrameでない不便
これらの壁を乗り越えて pio pysparkを実行 $ export PYSPARK_PYTHON=$PYENV_ROOT/shims/python $ export PYSPARK_DRIVER_PYTHON=$PYENV_ROOT/shims/jupyter $
export PYSPARK_DRIVER_PYTHON_OPTS="notebook" $ ./bin/pio pyspark せっかくなので、Jupyterで実行する
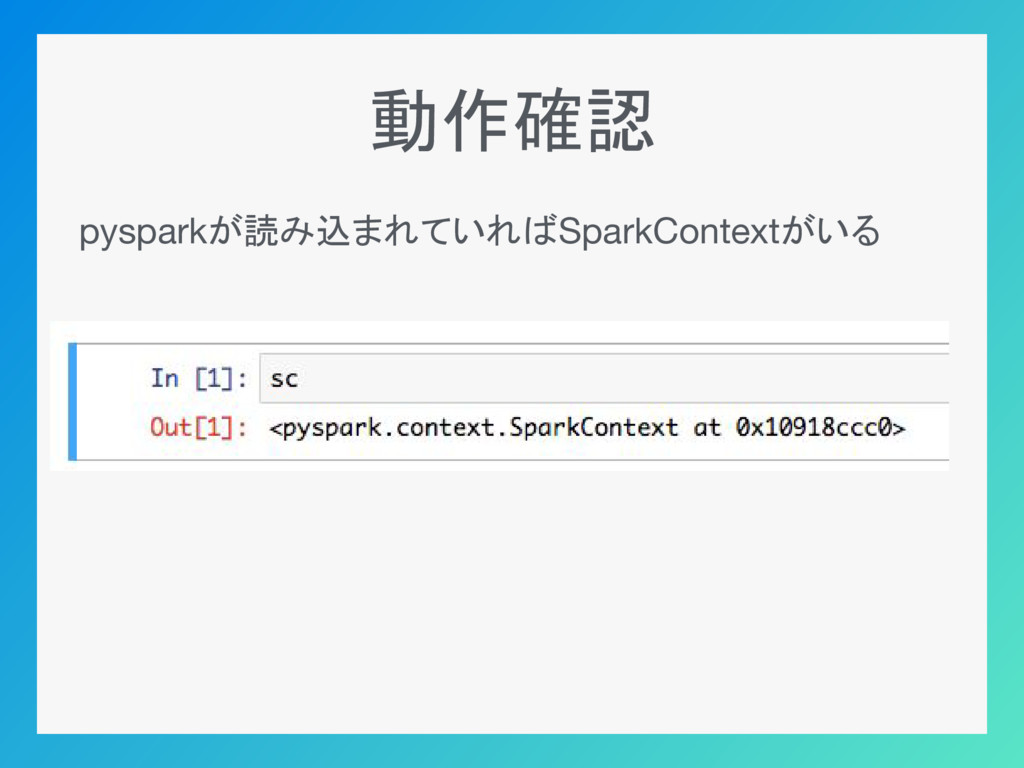
動作確認 pysparkが読み込まれていればSparkContextがいる
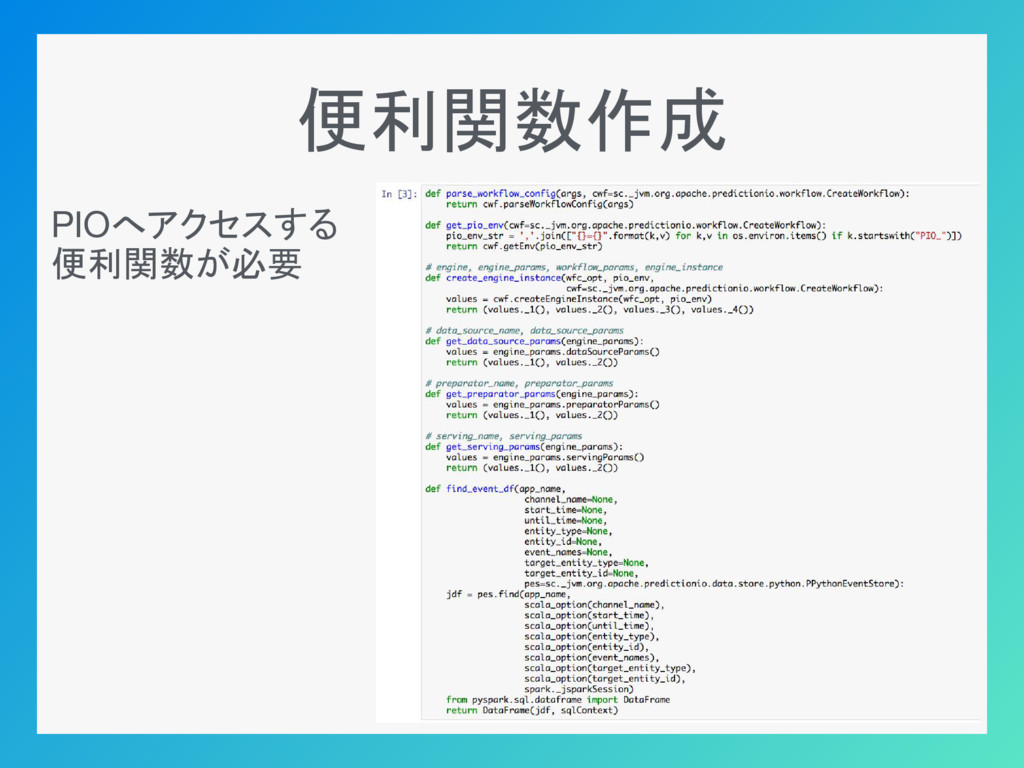
便利関数作成 Scalaへアクセスする便利関数が必要
便利関数作成 PIOへアクセスする 便利関数が必要
PIOの初期化 pio trainの処理と同じように実行して初期化
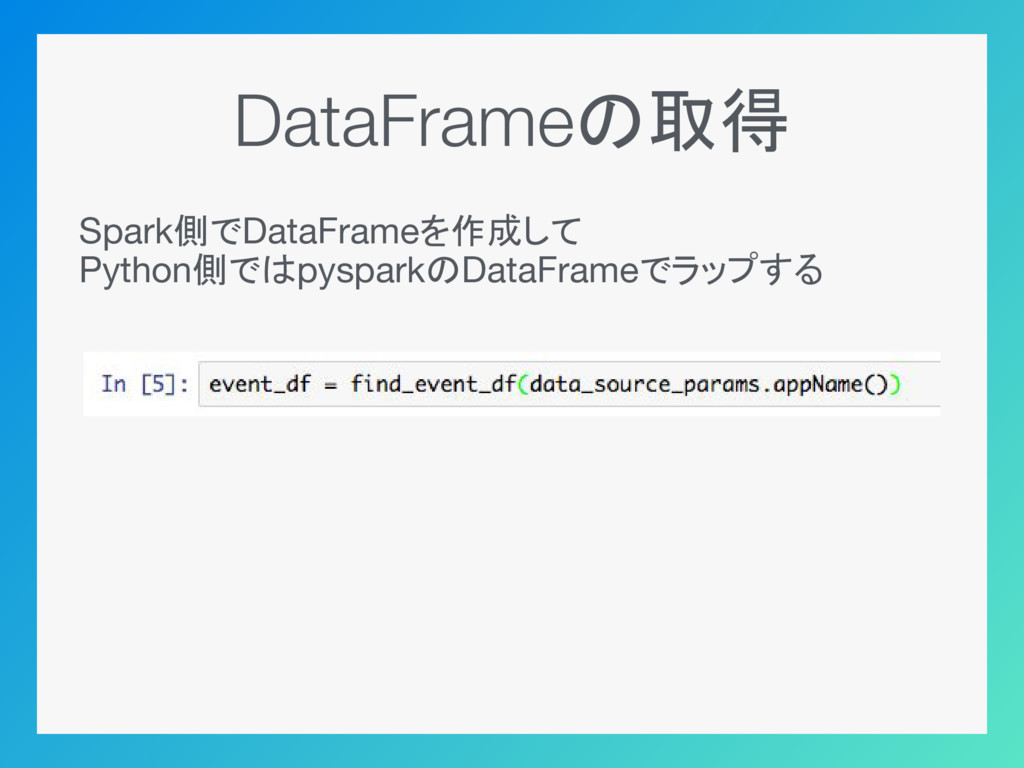
DataFrameの取得 Spark側でDataFrameを作成して Python側ではpysparkのDataFrameでラップする
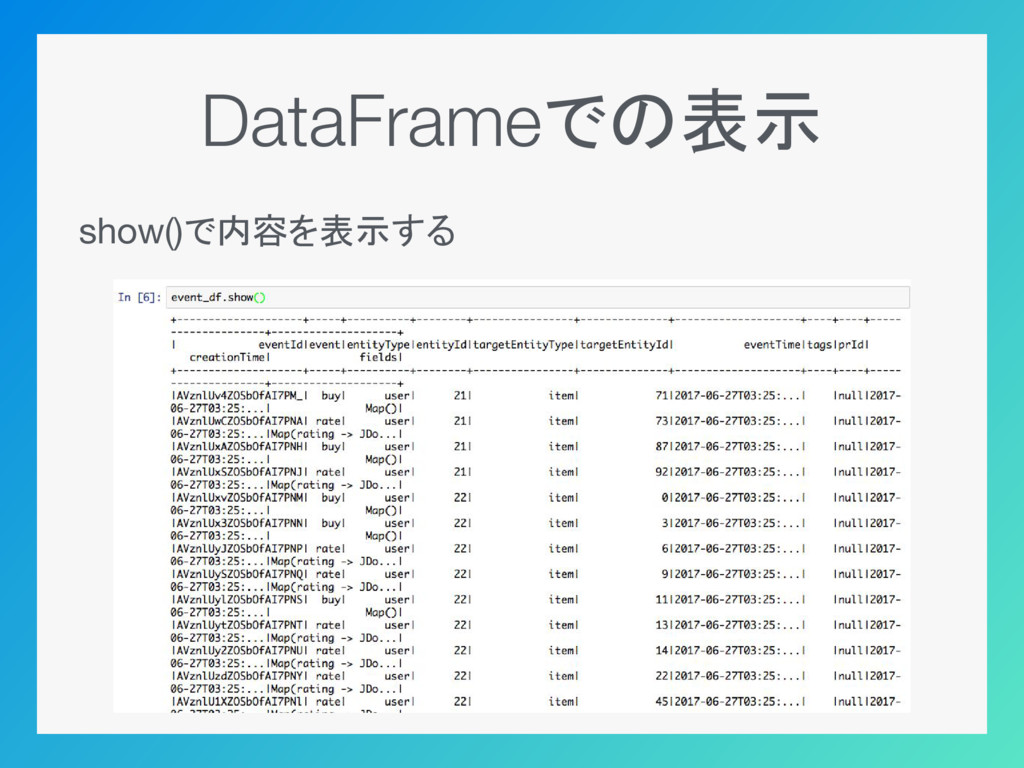
DataFrameでの表示 show()で内容を表示する
SQLでの表示 Viewを作成して、Spark SQLで取得
今後 ・コードを整理して、Apacheに入れたい ・予測サーバでの対応を考える ・続きはPIO勉強会#3で…
Apache Thank You
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}