data. • Broad world knowledge, attempt diverse tasks. • Aim for broad competence. SLMs (Often Specialists) • More focused training/fine-tuning possible. • Good at specific, well-defined tasks (e.g., log analysis, summarization, data extraction). • Can outperform LLMs on narrow domains more efficiently.
agents" https://cdn.openai.com/business-guides-and-resources/a-practical-guide-to-building-agents.pdf • Establish a baseline: Start with robust evaluations to measure performance. • Iterate on accuracy: Focus development on meeting specific accuracy targets. • Optimize for efficiency: Once accuracy is met, improve cost and latency by swapping in smaller, faster models where appropriate.
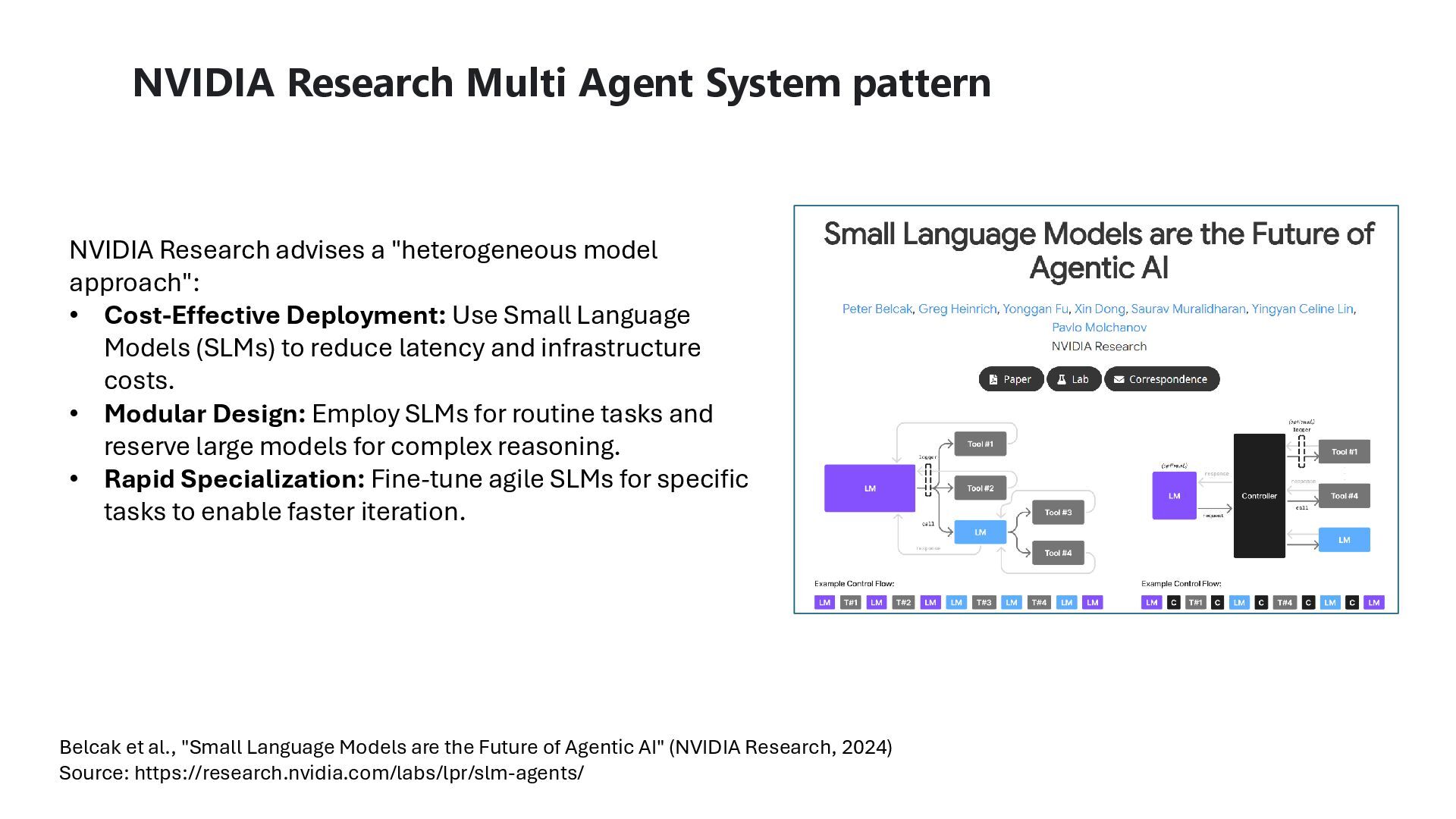
"heterogeneous model approach": • Cost-Effective Deployment: Use Small Language Models (SLMs) to reduce latency and infrastructure costs. • Modular Design: Employ SLMs for routine tasks and reserve large models for complex reasoning. • Rapid Specialization: Fine-tune agile SLMs for specific tasks to enable faster iteration. Belcak et al., "Small Language Models are the Future of Agentic AI" (NVIDIA Research, 2024) Source: https://research.nvidia.com/labs/lpr/slm-agents/
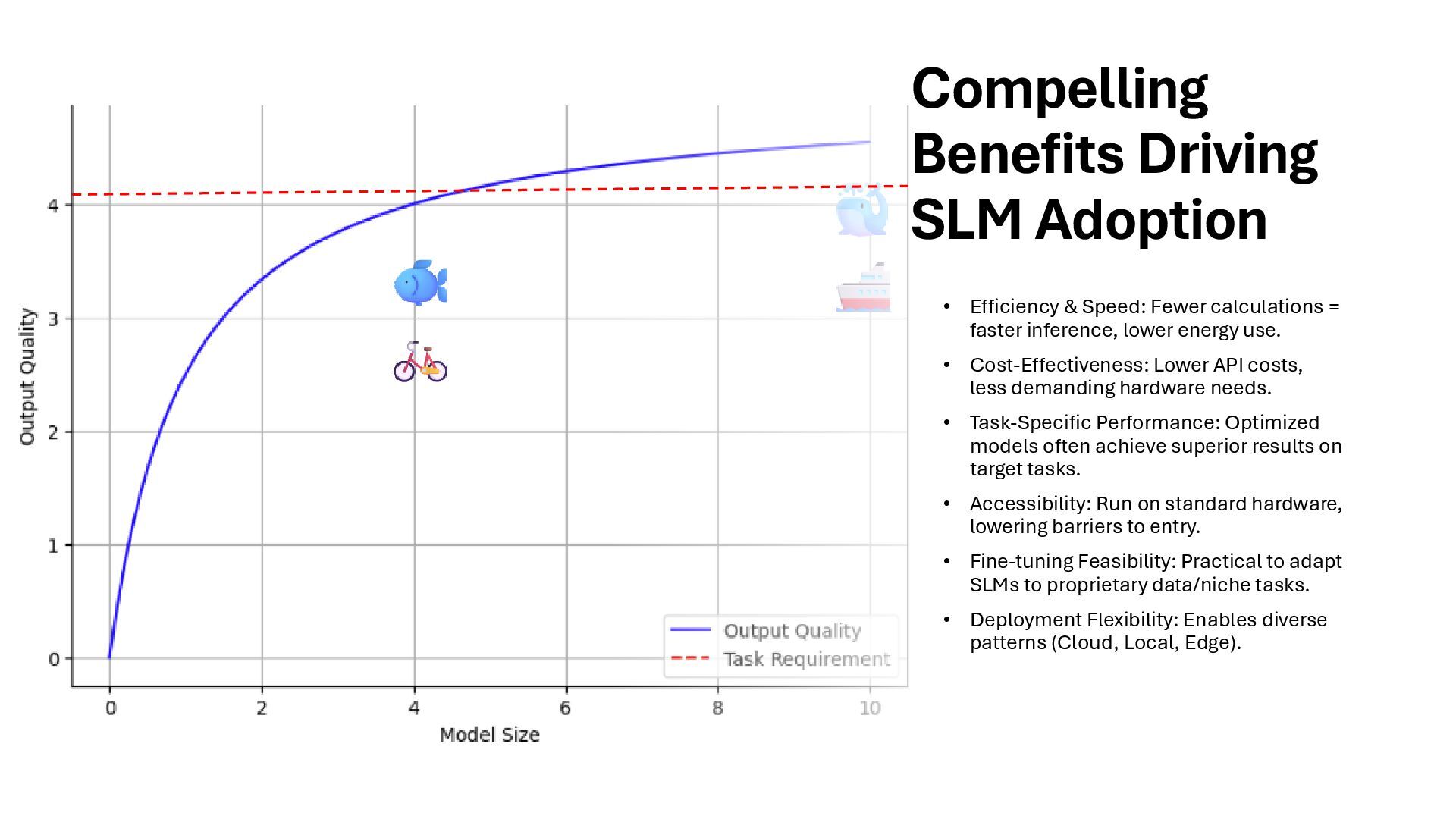
calculations = faster inference, lower energy use. • Cost-Effectiveness: Lower API costs, less demanding hardware needs. • Task-Specific Performance: Optimized models often achieve superior results on target tasks. • Accessibility: Run on standard hardware, lowering barriers to entry. • Fine-tuning Feasibility: Practical to adapt SLMs to proprietary data/niche tasks. • Deployment Flexibility: Enables diverse patterns (Cloud, Local, Edge).
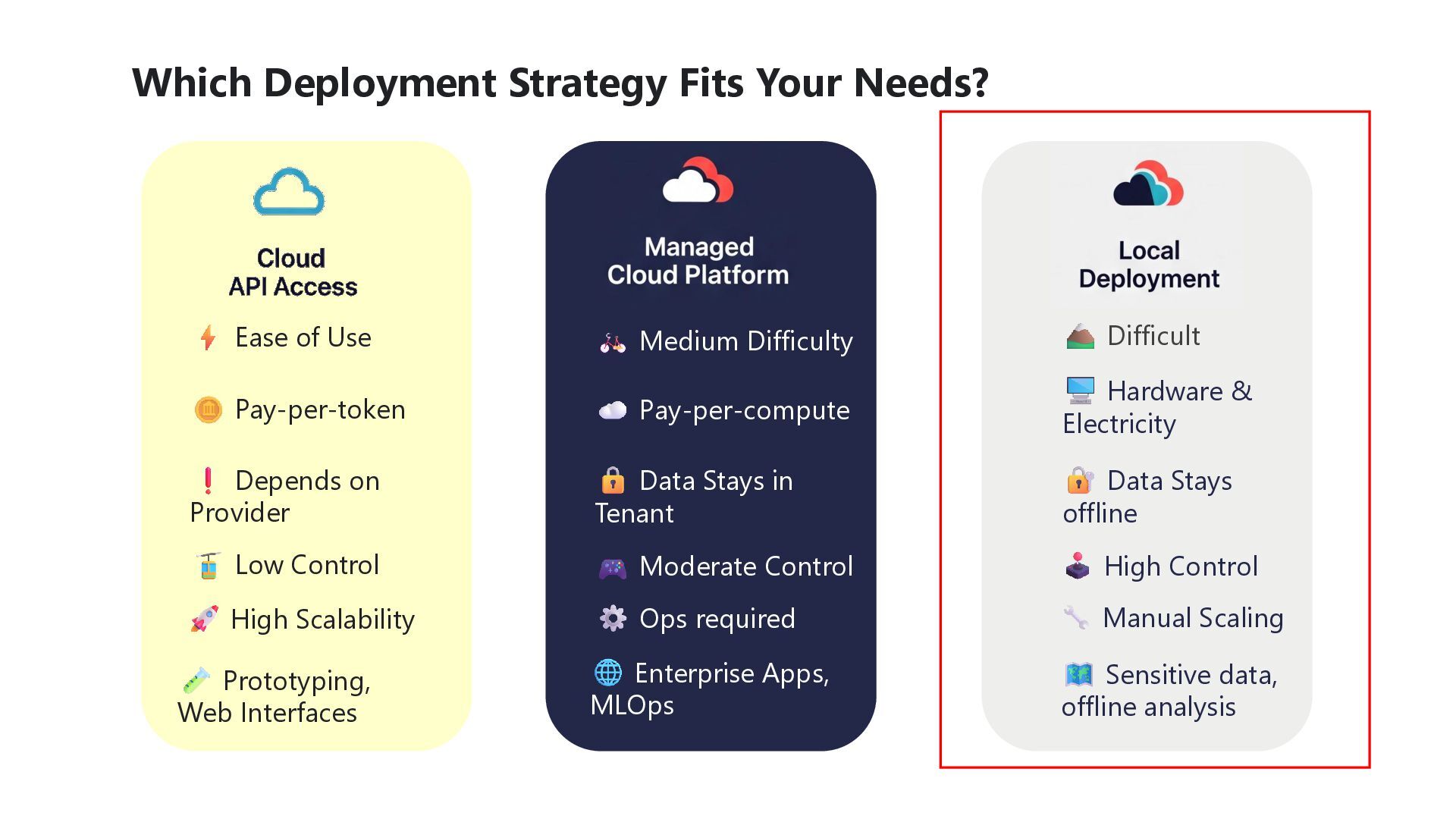
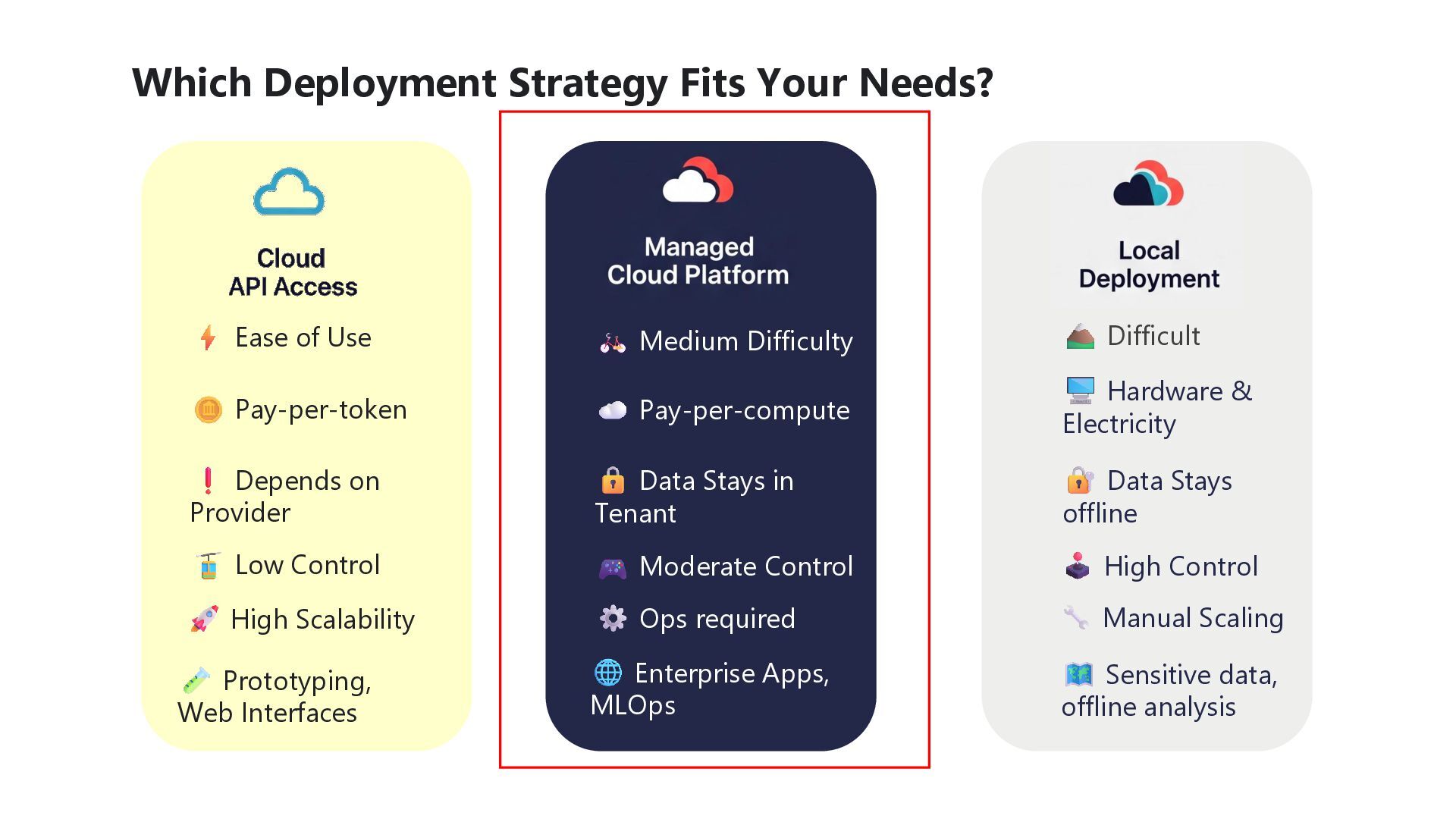
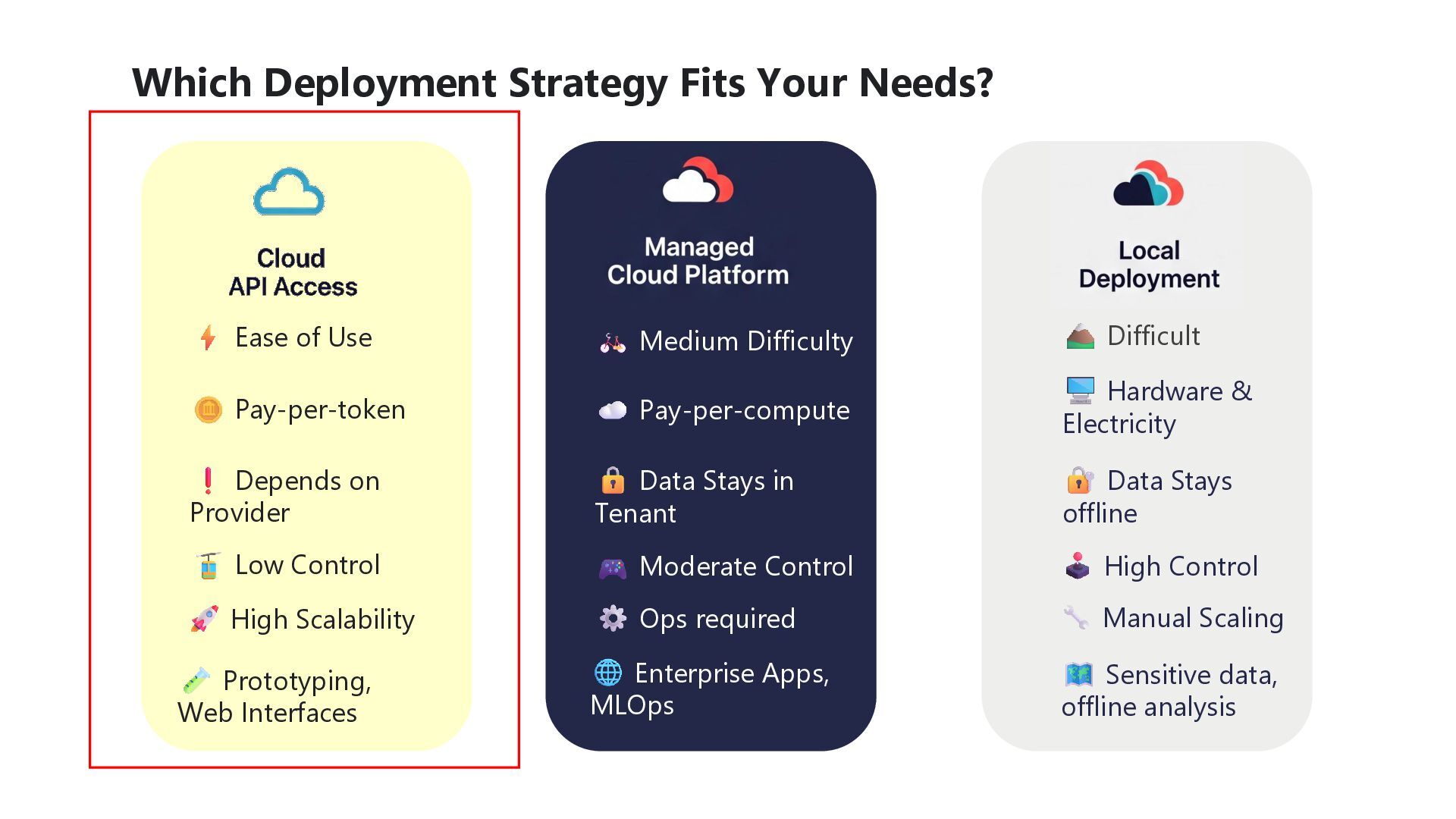
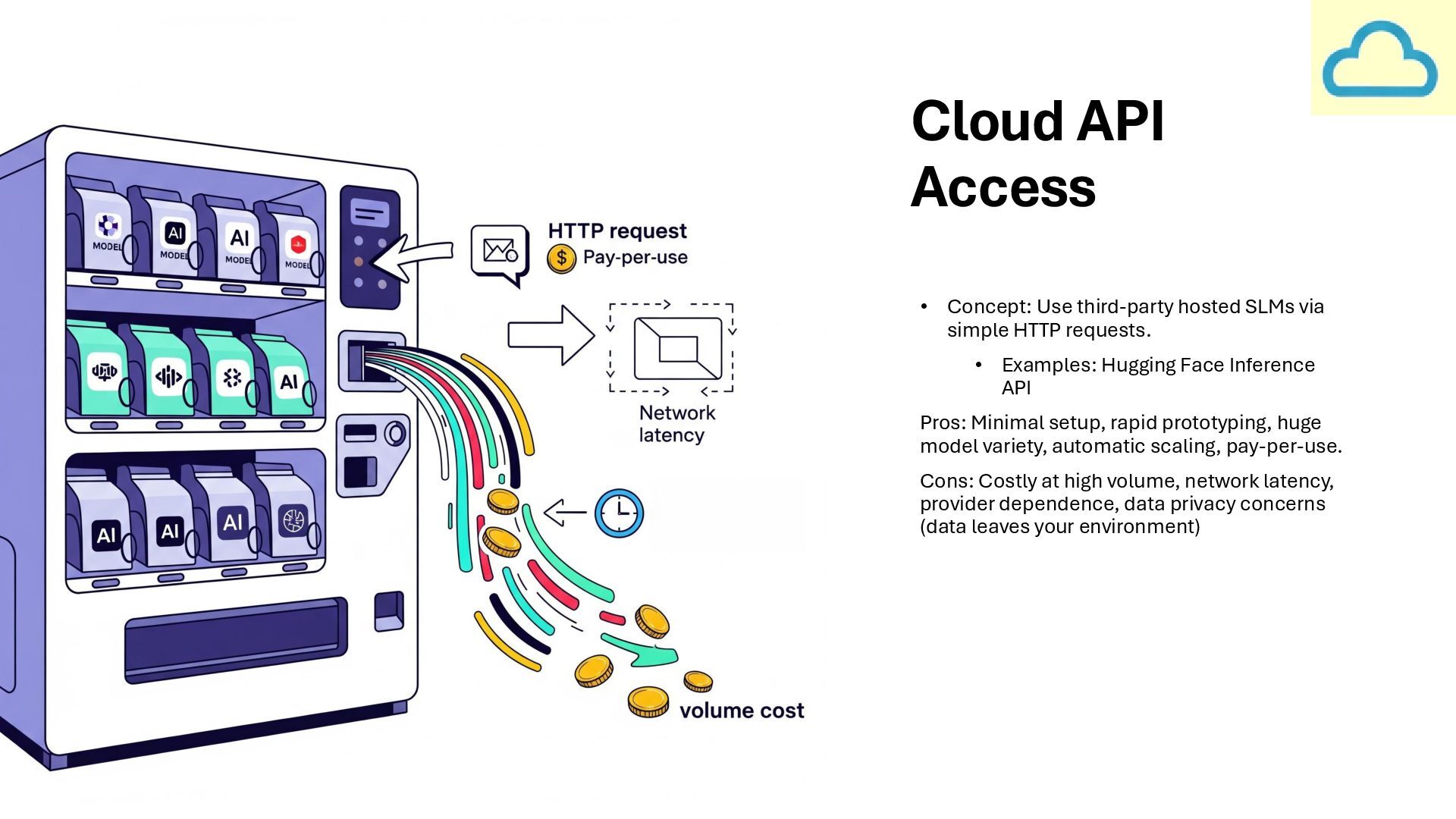
Difficulty Difficult Pay-per-token Depends on Provider Low Control High Scalability Prototyping, Web Interfaces Pay-per-compute Data Stays in Tenant Moderate Control Ops required Enterprise Apps, MLOps Hardware & Electricity Data Stays offline High Control Manual Scaling Sensitive data, offline analysis
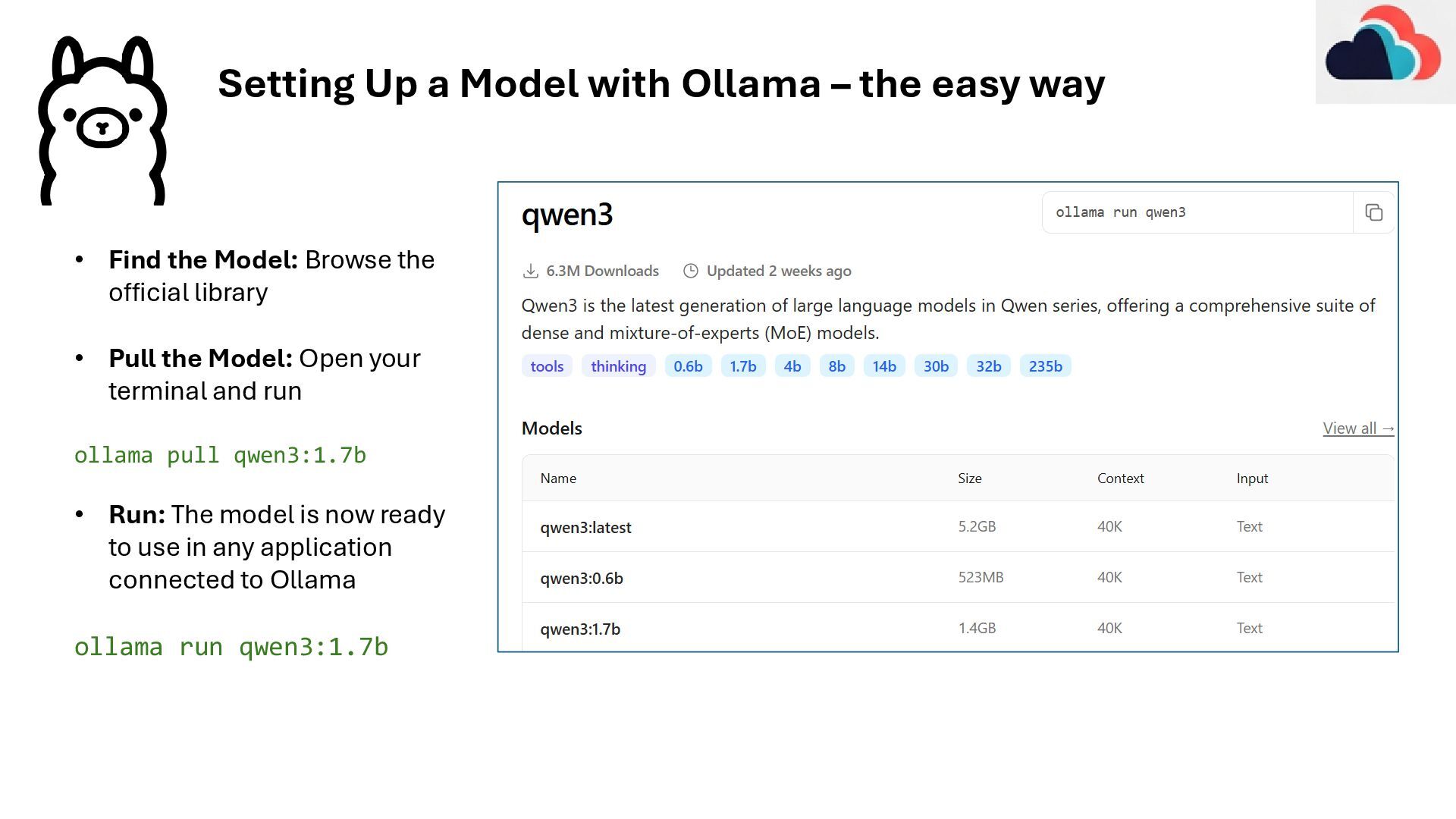
• Find the Model: Browse the official library • Pull the Model: Open your terminal and run ollama pull qwen3:1.7b • Run: The model is now ready to use in any application connected to Ollama ollama run qwen3:1.7b
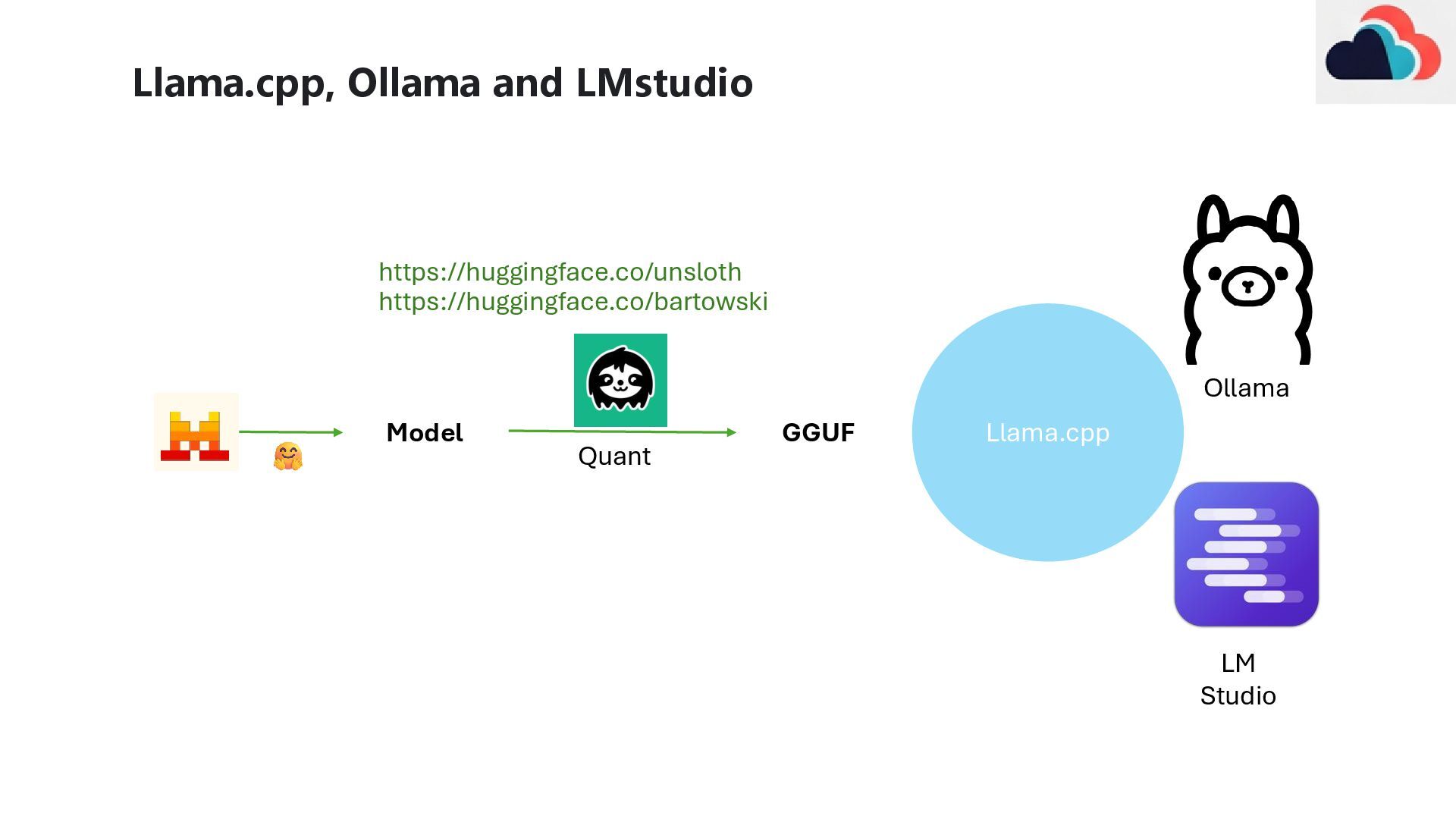
• Download a GGUF File From Huggingface • Create a Model File • Create the Model in Ollama ollama create my-custom-model -f C:\path\to\Modelfile # 1. Base Model FROM C:\Path\unsloth-Qwen2.5-Coder-7B-Instruct- 128K-GGUF\Qwen2.5-Coder-7B-Instruct-Q6_K.gguf # 2. Chat Template TEMPLATE """ <|im_start|>system {{ .System }}<|im_end|> <|im_start|>user {{ .Prompt }}<|im_end|> <|im_start|>assistant """ # 3. System Prompt SYSTEM """ You are an … """ # 4. Parameters# --- Generation Control --- PARAMETER temperature 0.7 PARAMETER top_p 0.9 Model File
Difficulty Difficult Pay-per-token Depends on Provider Low Control High Scalability Prototyping, Web Interfaces Pay-per-compute Data Stays in Tenant Moderate Control Ops required Enterprise Apps, MLOps Hardware & Electricity Data Stays offline High Control Manual Scaling Sensitive data, offline analysis
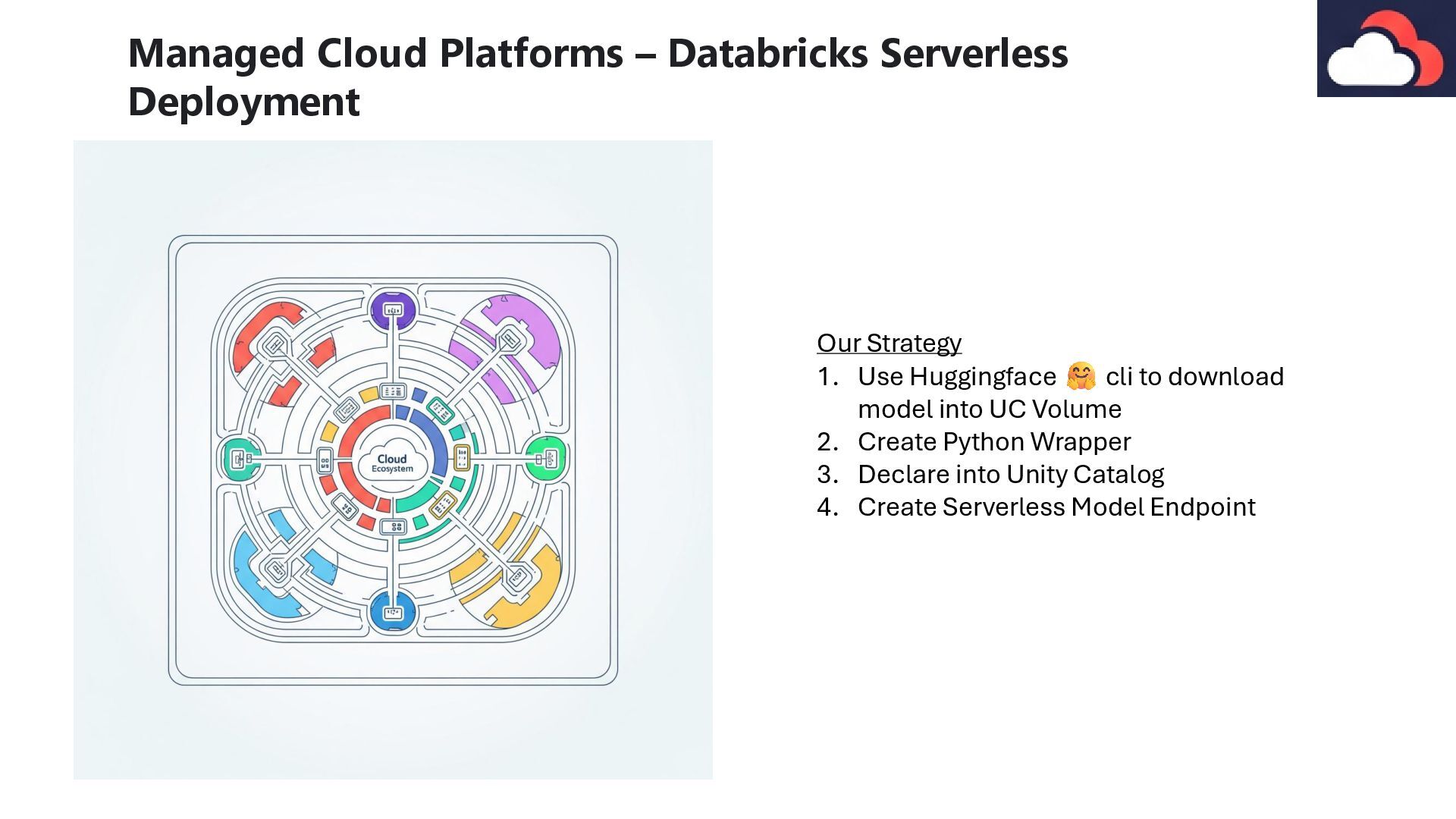
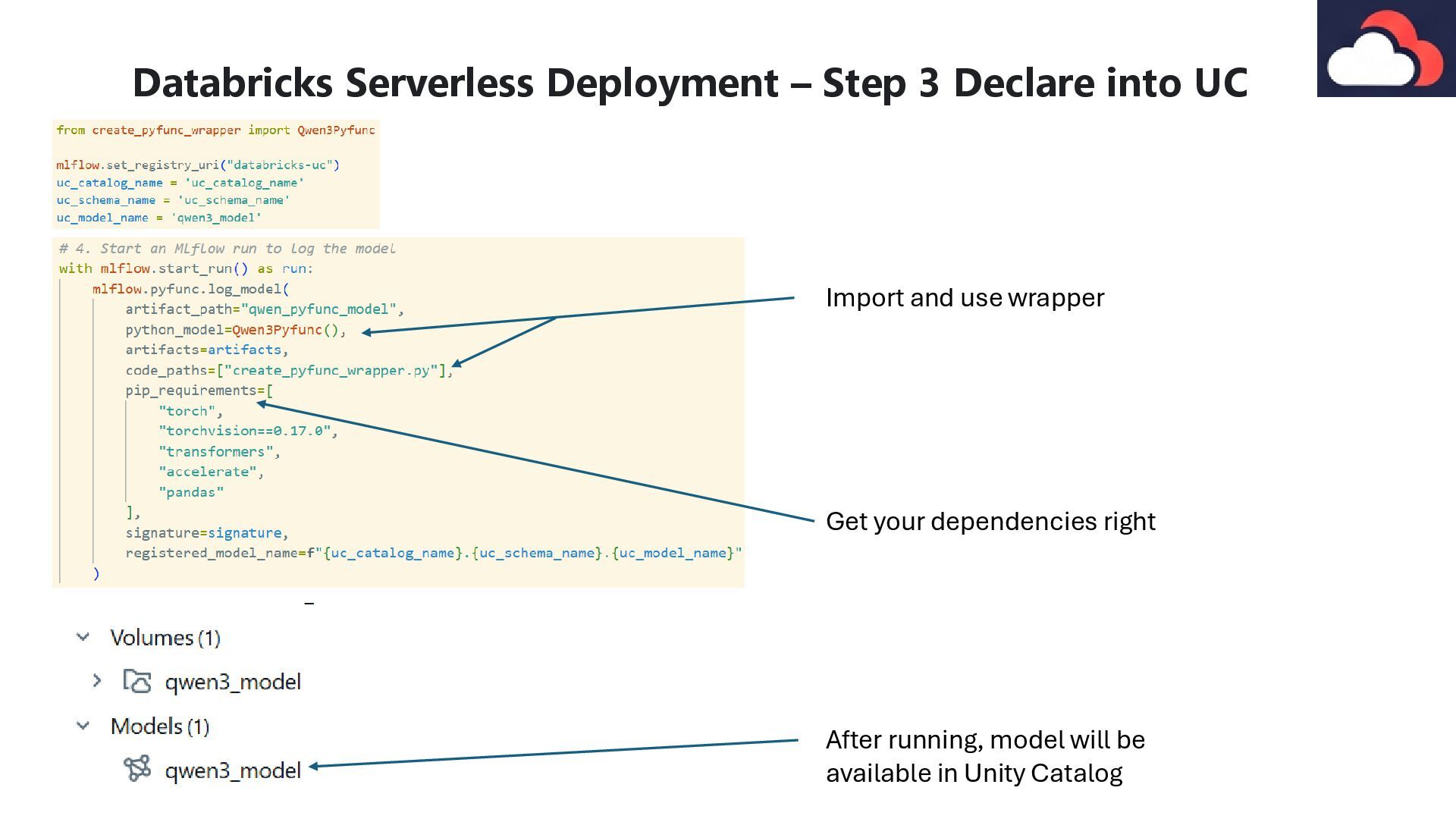
script defines an MLflow PyFunc model wrapper for serving the Qwen3 large language model, handling model loading and text generation The transformers library is crucial for loading the Qwen3 model and its tokenizer, preparing input text for the model (tokenization and chat templating), and performing the actual text generation and decoding the output
Difficulty Difficult Pay-per-token Depends on Provider Low Control High Scalability Prototyping, Web Interfaces Pay-per-compute Data Stays in Tenant Moderate Control Ops required Enterprise Apps, MLOps Hardware & Electricity Data Stays offline High Control Manual Scaling Sensitive data, offline analysis
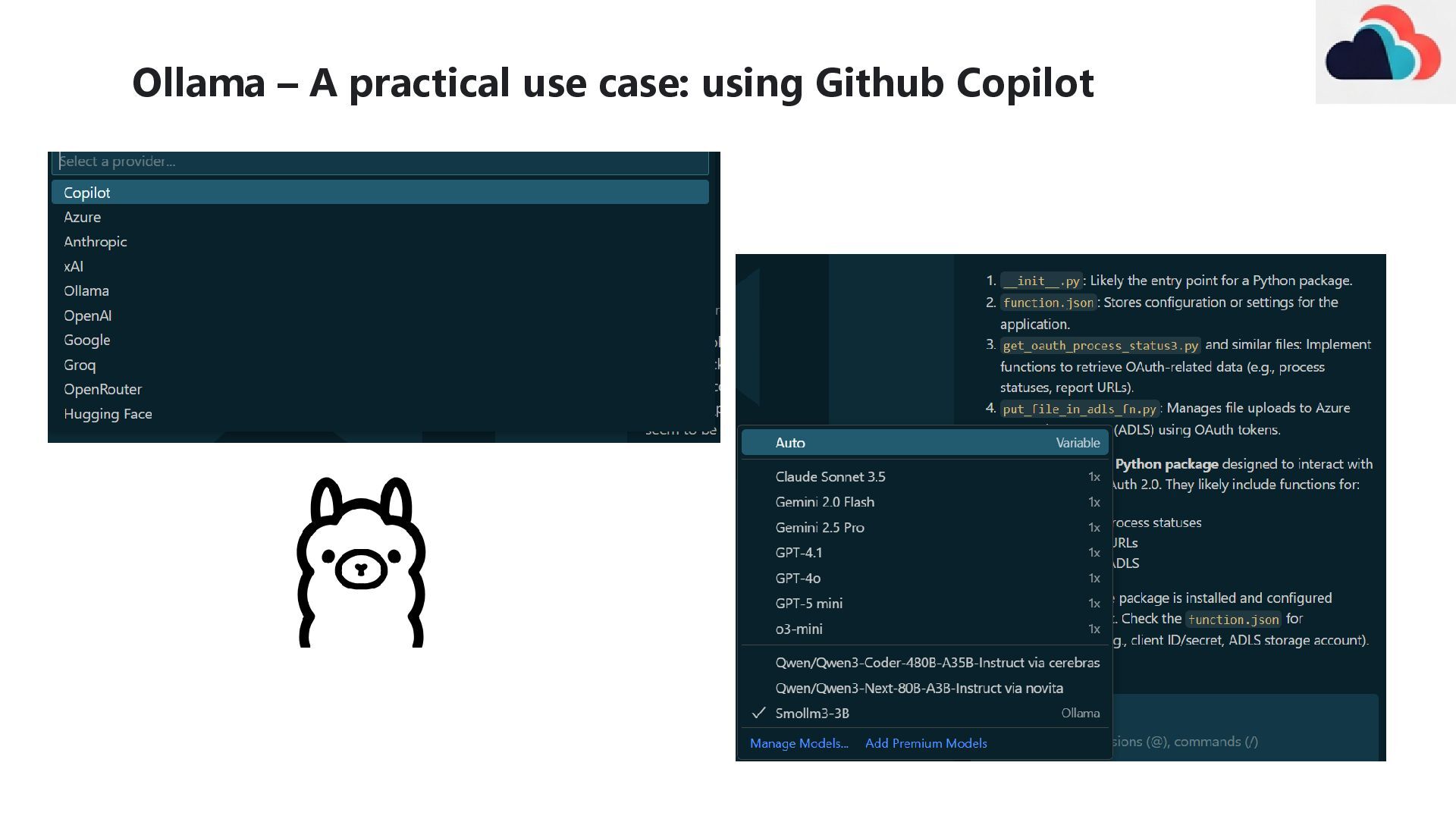
alternatives: • Claude Code • Gemini CLI • Qwen3-Coder • Most have a good “free” tier where you can tap into their SOTA models Why it’s great • Open in VSCode terminal • Mention (with an @) entire files or folders from your workspace • Creates or modifies code files for you
1: Open VSCode and Install the Gemini CLI with npm npm install -g @google/gemini-cli This command downloads the official CLI package and makes the gemini command available on your system. Step 2: Run the Gemini CLI gemini On the first run, the CLI will guide you through a quick setup process. Pre-requirement: install NodeJS
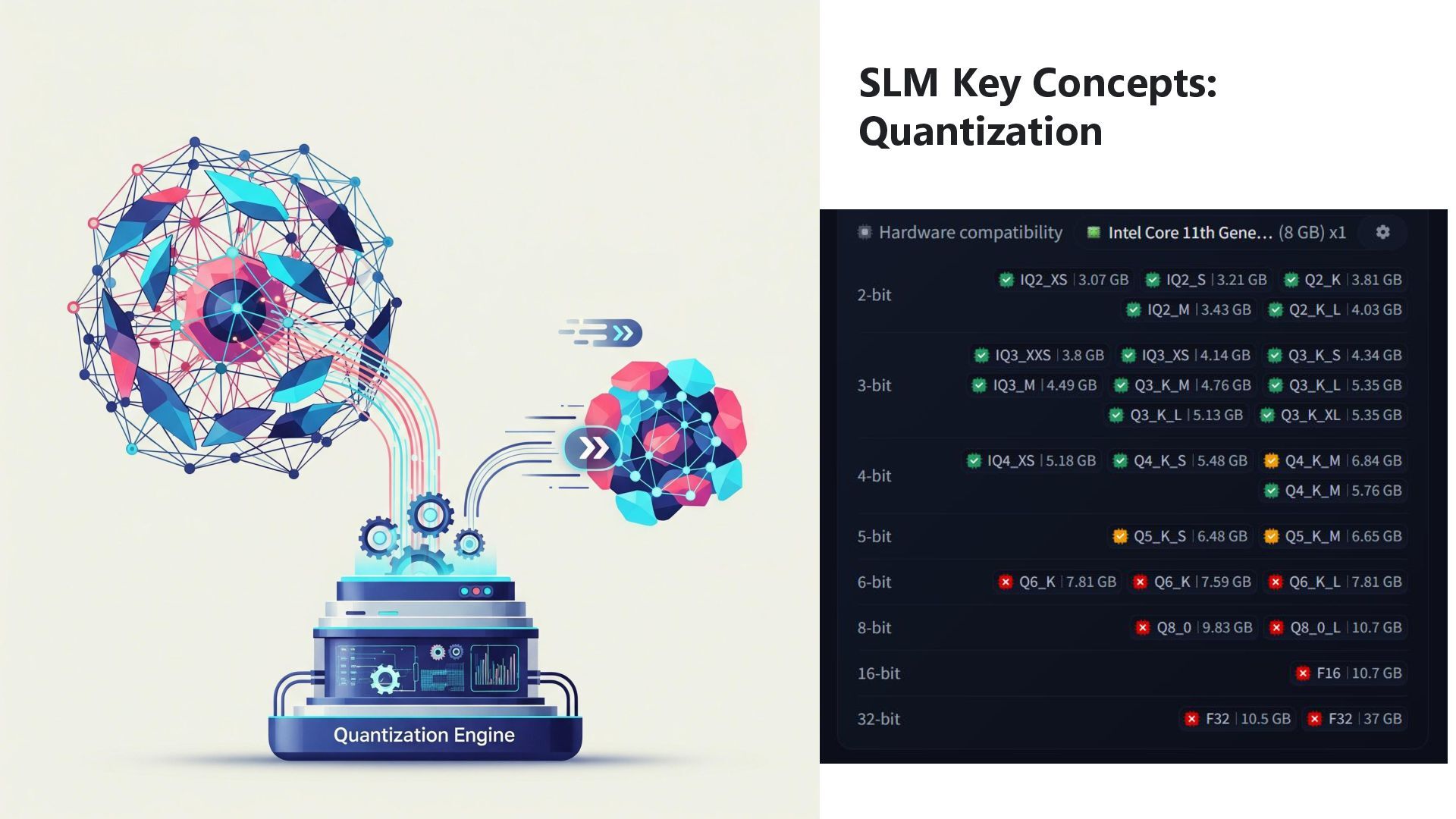
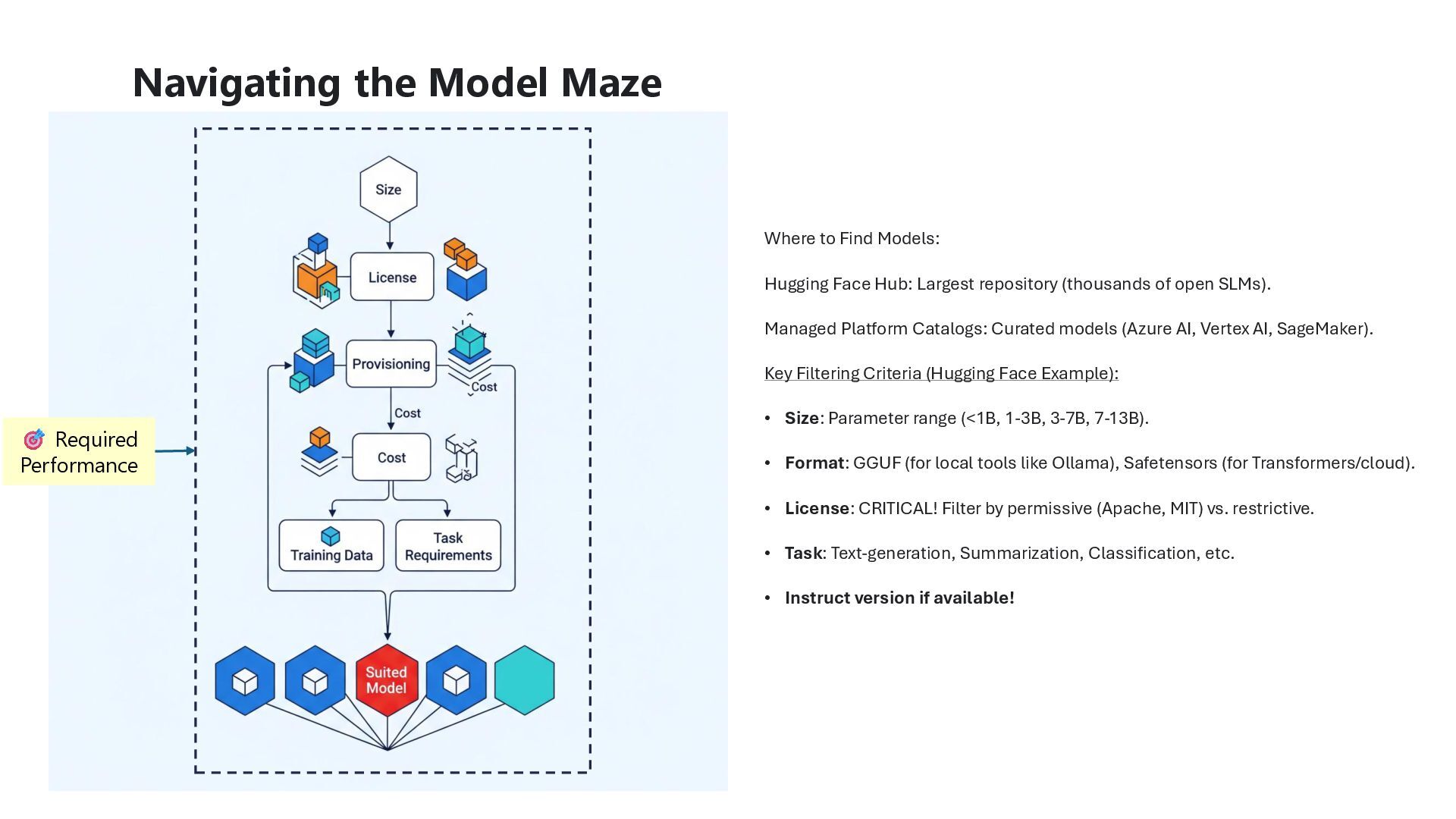
of open SLMs). Managed Platform Catalogs: Curated models (Azure AI, Vertex AI, SageMaker). Key Filtering Criteria (Hugging Face Example): • Size: Parameter range (<1B, 1-3B, 3-7B, 7-13B). • Format: GGUF (for local tools like Ollama), Safetensors (for Transformers/cloud). • License: CRITICAL! Filter by permissive (Apache, MIT) vs. restrictive. • Task: Text-generation, Summarization, Classification, etc. • Instruct version if available! Navigating the Model Maze Required Performance
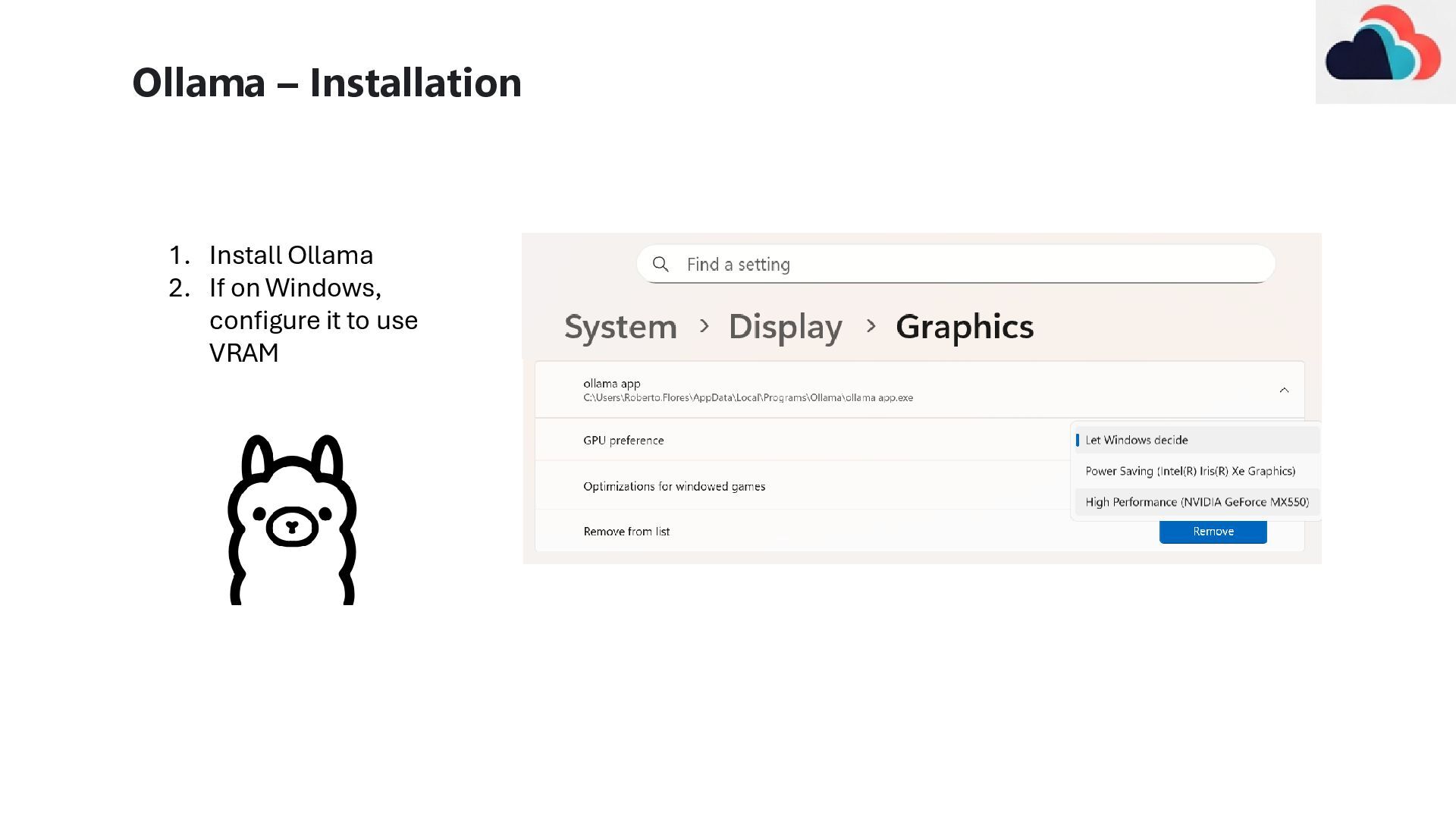
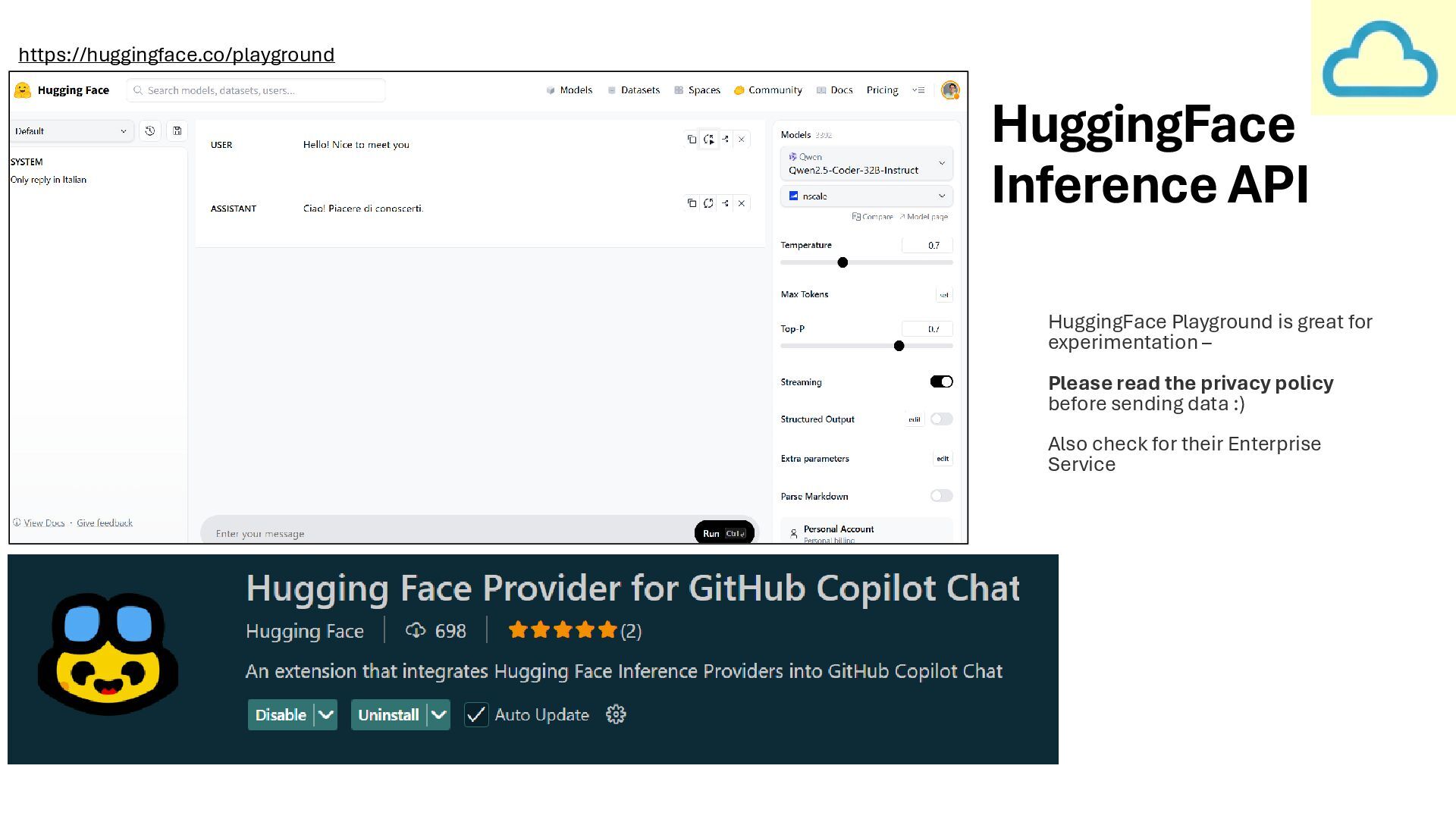
find the smallest model that can meet that requirement. It will be less expensive and better for the environment • Leverage credible players from the SLM ecosystem (Smol, Mistral, Qwen, Gemma, Phi) • Ollama and Lmstudio provide great engines to run SLMs on local hardware. Provides Maximum Privacy and works offline, but requires investment in equipment and maintenance • Leverage the cloud to access a wide array of models securely. Keeping data within your company’s tenant. Requires setting up Deployment Pipelines and supporting any custom endpoints made • Available like tap water but beware of the privacy policy of the provider. Also beware of the token pricing, which can grow exponentially for long contexts
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}