Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
100マイクロサービスのTerraform/Kubernetes管理地獄から抜け出すためのAI活用術
Search
Masaki Ishigaki
May 12, 2026
Technology
690
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
100マイクロサービスのTerraform/Kubernetes管理地獄から抜け出すためのAI活用術
クラウドネイティブ会議の資料になります。
Masaki Ishigaki
May 12, 2026
More Decks by Masaki Ishigaki
See All by Masaki Ishigaki
SRE Enabling戦記 - 急成長する組織にSREを浸透させる戦いの歴史
markie1009
0
1.2k
Other Decks in Technology
See All in Technology
Agentic AI 時代のテスト手法: Kiro とはじめるプロパティベーステスト (AWS Summit Japan 2026 | DEV212)
ymhiroki
0
220
Control Planeで育てるBtoB SaaSの認証基盤 - SRE NEXT 2026
pokohide
1
1.4k
なぜ私たちのSREプラクティスはなかなか機能しないのか 〜システムより先に組織を見る〜 / Why our SRE practices aren't really working
vtryo
1
2.4k
ゼロをイチにする仕事が終わったあと
smasato
0
310
知らん間に、回ってる
ming_ayami
0
310
美しいコードを書くためにF#を学んでみた話
yud0uhu
1
310
AIペネトレーションテスト・ セキュリティ検証「AgenticSec」紹介資料
laysakura
2
8.1k
人を動かすのは時間ではなく、納得感 〜新任EMが入社3ヶ月、組織を2回変えた話〜
kakehashi
PRO
2
150
生成AIの活用/high_school2026
okana2ki
0
110
Claude Code 珍プレー好プレー
shinyasaita
0
280
LiDAR SLAMの実装とセンサ融合 ~Lie群からContinuous-Time LIOまで~
naokiakai
1
1k
AI時代のエンジニアキャリアについて今一度考える
sakamoto_582
2
1.3k
Featured
See All Featured
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
Side Projects
sachag
455
43k
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.2k
Evolving SEO for Evolving Search Engines
ryanjones
0
240
Balancing Empowerment & Direction
lara
6
1.2k
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.7k
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
750
Discover your Explorer Soul
emna__ayadi
2
1.2k
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
590
The Mindset for Success: Future Career Progression
greggifford
PRO
0
410
Tell your own story through comics
letsgokoyo
1
990
Transcript
100マイクロサービスの Terraform/Kubernetes管理地獄から 抜け出すためのAI活用術 Masaki Ishigaki / Akihisa Wada 株式会社LegalOn Technologies
2026/5/14
登壇者プロフィール ⽯垣 雅基 (いしがき まさき) @magicalgakisan 株式会社LegalOn Technologies SRE 和⽥ 明久 (わだ あきひさ) 株式会社LegalOn
Technologies SRE
会社・事業紹介
Our Purpose 法とテクノロジーの力で、 安心して前進できる社会を創る。 LegalOn Technologiesは、AI分野における⾼度な技術⼒と法律‧契約の専⾨知識を兼ね備えたグローバルリーガルAIカン パニーです。設⽴当初から、AIを活⽤したリーガルAIサービスの開発に注⼒し、⼤規模⾔語モデル(LLM)やAIエージェン トなど最先端のAI技術を製品開発に取り⼊れ、多様な企業課題に応えるソリューションでお客様のビジネスを⽀援しま す。 会社名
株式会社LegalOn Technologies 設⽴ 2017年4⽉21⽇ 従業員数 639名(役員含む∕2026年3⽉時点) 所在地 〒150-6219 東京都渋⾕区桜丘町1-1 渋⾕サクラステージSHIBUYAタワー19F 資本⾦ 201.5億円(資本準備⾦等含)
法務AIのグローバルリーダー 8,500+ 顧客数グローバル8,500社を突破 639人 従業員数 7拠点合計 (東京‧⼤阪‧福岡‧名古屋‧サンフラン シスコ‧ロンドン‧ミュンヘン) 20人 弁護⼠資格保有者数
⽇本、NY州、CA州、ドイツの資格者を含む 1000+ 導⼊上記業者数 / 前上場企業者数 3,800社 200人 開発チーム⼈数 286億円 ゴールドマン‧サックス、ソフト バンクなどが出資。全調達ラウン ド累計
弊社が提供するProfessional AI
LegalOn Technologies におけるSREの苦悩
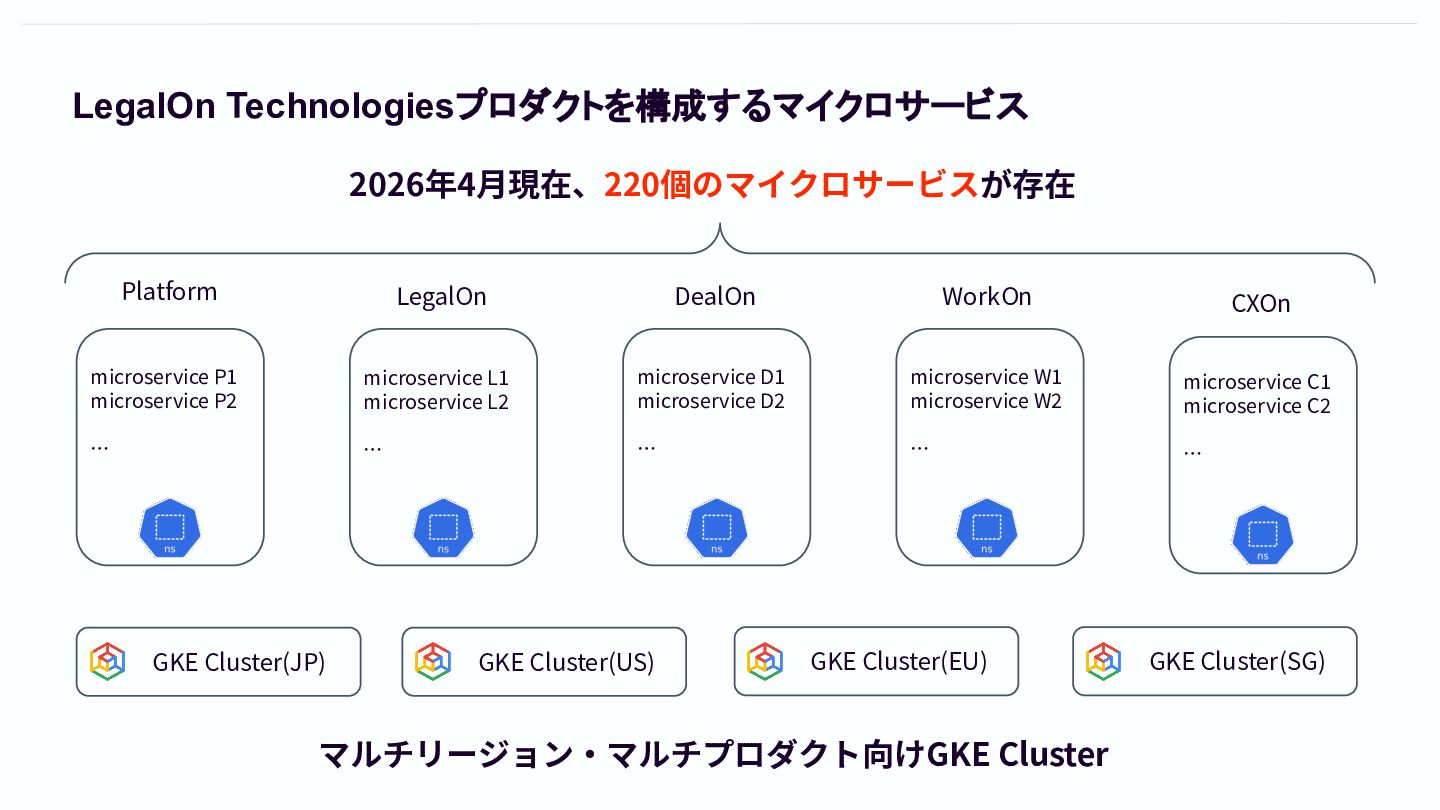
LegalOn Technologiesプロダクトを構成するマイクロサービス GKE Cluster(JP) GKE Cluster(US) GKE Cluster(EU) GKE Cluster(SG)
Platform LegalOn DealOn WorkOn microservice P1 microservice P2 … microservice D1 microservice D2 … microservice L1 microservice L2 … microservice W1 microservice W2 … CXOn microservice C1 microservice C2 … マルチリージョン‧マルチプロダクト向けGKE Cluster 2026年4⽉現在、220個のマイクロサービスが存在
220個のマイクロサービスを管理するための Terraform、k8s manifest マイクロサービスの数だけGoogle Cloud Project、k8s namespaceが存在するので、 管理すべきtfファイル、k8s manifest yamlファイルの数も膨⼤、、、
Platformによってかなり抽象化はされているものの、これだけの規模感になるとメン テに割く⼯数も⾺⿅にならない、、、
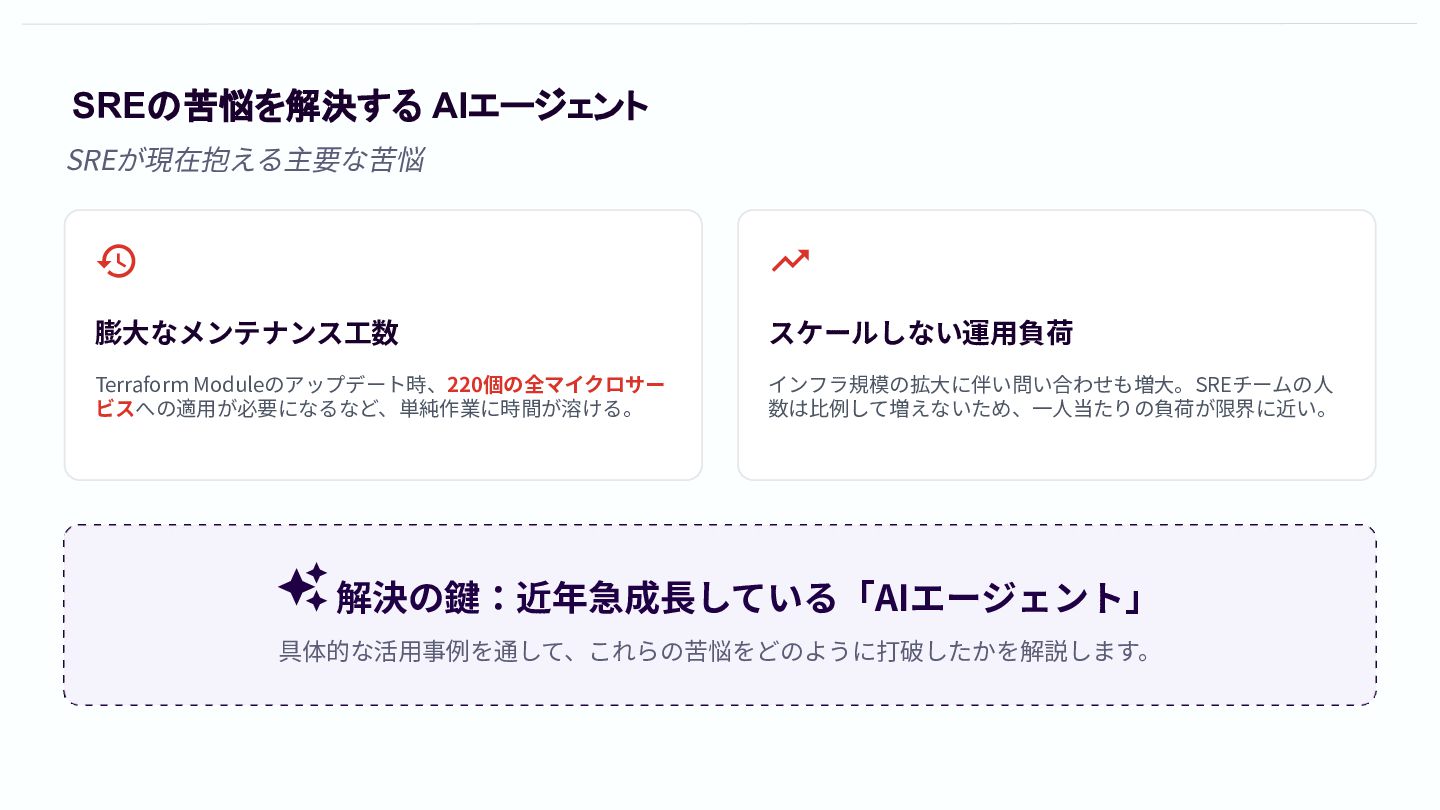
SREの苦悩を解決する AIエージェント SREが現在抱える主要な苦悩 膨⼤なメンテナンス⼯数 Terraform Moduleのアップデート時、220個の全マイクロサー ビスへの適⽤が必要になるなど、単純作業に時間が溶ける。 スケールしない運⽤負荷
インフラ規模の拡⼤に伴い問い合わせも増⼤。SREチームの⼈ 数は⽐例して増えないため、⼀⼈当たりの負荷が限界に近い。 解決の鍵:近年急成⻑している「AIエージェント」 具体的な活⽤事例を通して、これらの苦悩をどのように打破したかを解説します。
Linear x Codexで全マイクロ サービスのTerraform/k8s manifest Updateを 効率よく行う
事例: 全マイクロサービスの HPA → KEDA 移行 サービス × 環境の物量勝負 680
HPA manifests 134 + 50 services / platform folders × 2 環境 (Sandbox / Live) AI エージェントを使わない場合は、 ブランチ分け / 共通の変更 / PR 作成を、 サービ ス × 環境の組み合わせで⼈⼒で繰り返す必要があった。
HPA から KEDA への移行: 3 つの理由 1. ゼロスケール Sandbox を
夜間‧休⽇に⽌めたい コスト削減 2. 多様な scaler Pub/Sub Cron / Datadog 柔軟なスケーリング⼿段 3. 共通インターフェース ScaledObject が 後続施策の⼊⼝ 中央管理が容易になる 単なる KEDA のインストールだけでなく、 全マイクロサービス × 環境分をどのように適⽤する かが本題。
スケーリング権限を 5 段階で切り替えた 技術的前提 KEDA は内部的に HPA を⽣成 → 既存
HPA と ScaledObject の併存は競合する External Metrics API は cluster に 1 つしか登録できない → ⼀気切替で Pub/Sub 系スケールが⼀時停⽌ HPA ScaledObject Phase 1 KEDA controller / CRD だけ⼊れる active 未配布 Phase 2 全マイクロサービスに paused の ScaledObject を配布 active paused Phase 3 external metric の権限を KEDA へ active (CPU/Mem) active (external) Phase 4 CPU / Memory も KEDA へ 削除中 active Phase 5 旧 HPA / 旧 tool の cleanup 削除済 active
ツール開発も人間と AI で分業 AI への指⽰だけ⼈間が書く。 spec.md とツール更新は AI が回す ⼈間
1. 変換ルールの草稿を書く やりたい挙動を⾃然⾔語で AI 2. spec.md にルール∕例外を 書く Codex が⽂書化 AI 3. spec.md からツール実装を ⽣成 Go CLI のコード⽣成‧修正 ⼈間 4. PR レビューで最終判断 spec / 実装の妥当性確認 LOOP ⼈間と AI で 役割を分けて回す 3 つの Go CLI: hpa2scaledobject / switch-hpa2so / fix-cpu — どれもこのループで回した
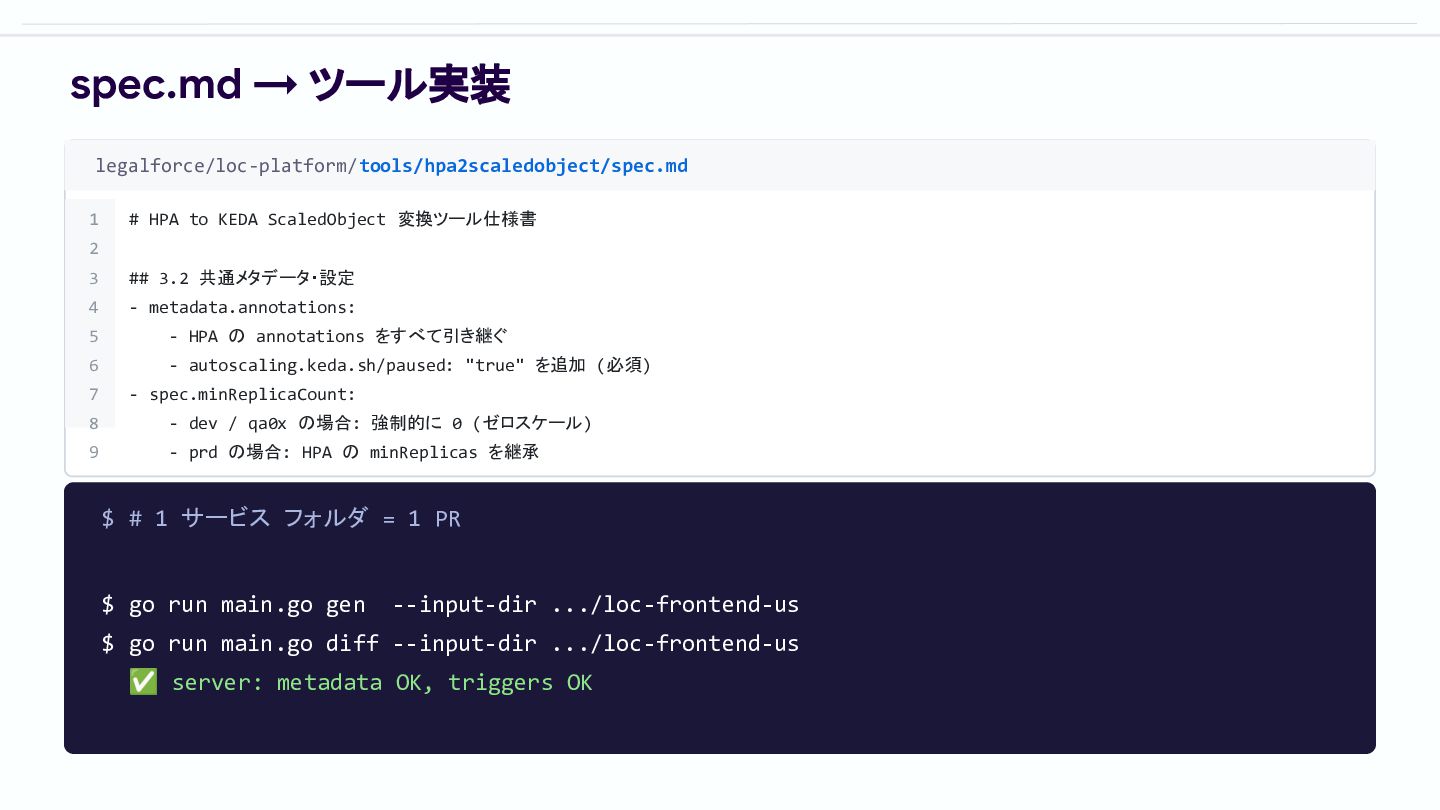
spec.md → ツール実装 legalforce/loc-platform/tools/hpa2scaledobject/spec.md 1 # HPA to KEDA ScaledObject
変換ツール仕様書 2 3 ## 3.2 共通メタデータ・設定 4 - metadata.annotations: 5 - HPA の annotations をすべて引き継ぐ 6 - autoscaling.keda.sh/paused: "true" を追加 (必須) 7 - spec.minReplicaCount: 8 - dev / qa0x の場合: 強制的に 0 (ゼロスケール) spec.md に書いた実際の除外‧例外条件 (抜粋) prd 環境はゼロスケール除外 HPA の minReplicas を継承 (dev / qa0x は強制 0) Pub/Sub trigger は書き換え HPA External (Pub/Sub) → KEDA prometheus へ統⼀ Frontend のフラット構成は別ルート loc-frontend-{jp,us} と base-frontend-app は専⽤ロジッ ク $ # 1 サービス フォルダ = 1 PR $ go run main.go gen --input-dir .../loc-frontend-us $ go run main.go diff --input-dir .../loc-frontend-us ✅ server: metadata OK, triggers OK
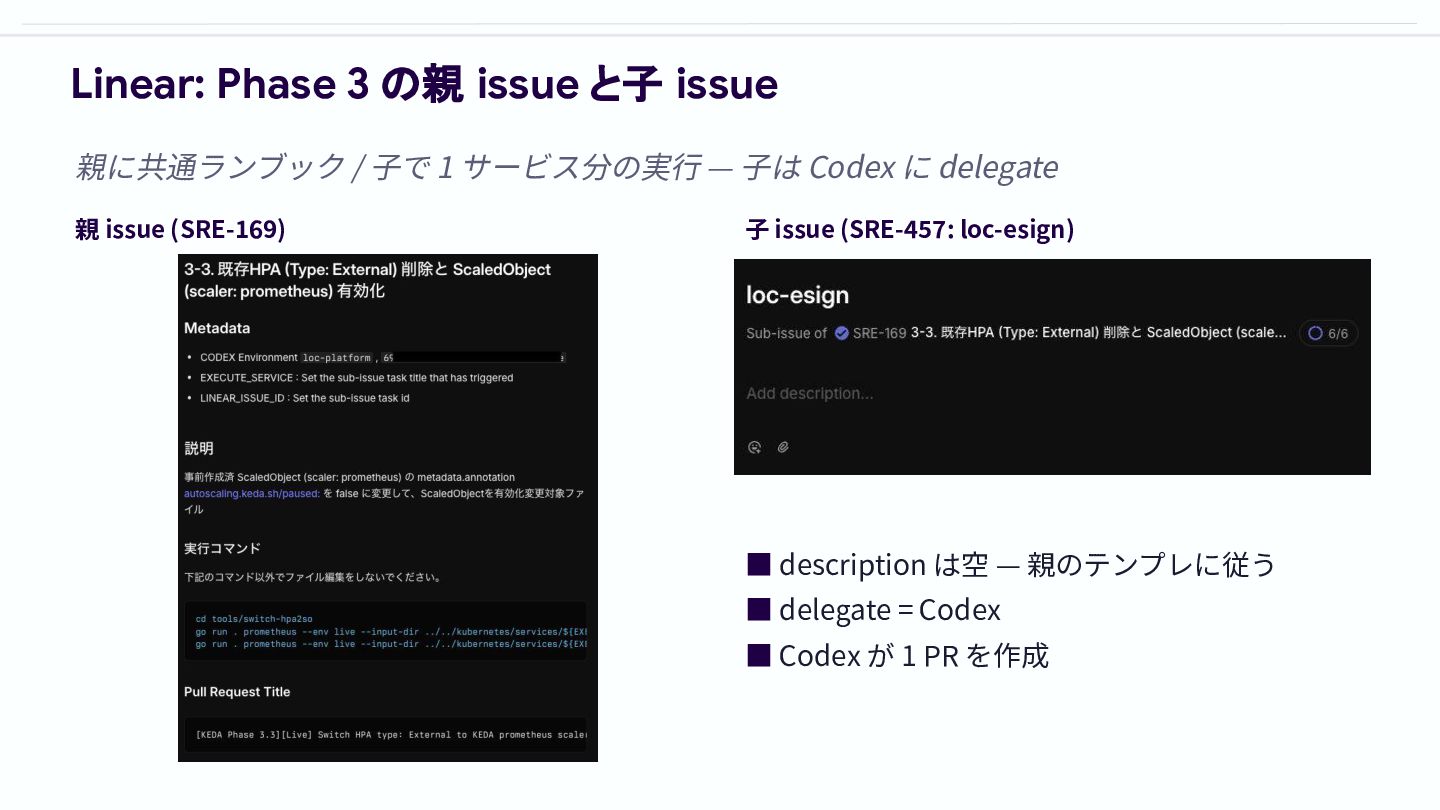
Linear: Phase 3 の親 issue と子 issue 親に共通ランブック / ⼦で
1 サービス分の実⾏ — ⼦は Codex に delegate 親 issue (SRE-169) ⼦ issue (SRE-457: loc-esign) ⼦ issue assign 後の流れ 1 Linear Issue に Codex agent をアサイン 2 Codex Web で タスク実⾏ 3 PR ⽣成 4 レビュー & マージ
親 issue 本文に書くもの ⼦ issue は空 description で良い。 全テンプレは親 1
か所に集約する EXECUTE_SERVICE / EXECUTE_PATH 対象パスの placeholder CODEX ENV ID agent ⾃⾛のための紐付け 実⾏コマンド go run … (これだけで実⾏) PR title / body template PR template に揃える 観測ポイント ArgoCD URL / metric URL 別フェーズの親 issue (SRE-1565 / Phase 5)
マニフェスト大量生成とマージによる運用ボトルネック 100+ PR / 1 day 250+ Linear child issues
JP→US sandbox → live AI エージェントの並列実⾏により、 PR マージ後の後続処理で詰まった ArgoCD OutOfSync の同時多発 100+ サービスの ScaledObject / HPA を同時に sync しようとして reconcile が連鎖 HPA prune の競合 paused 解除と HPA delete の間に ArgoCD sync が rebound、 desired / live の整合が⼀瞬ずれる 律速は受け側 (GitOps / CI) のスループット agent の並列度を上げる前に、 ApplicationSet の rollout やキューの broaden が必要
Part 1 まとめ 全マイクロサービス × 環境の autoscaling 移⾏を、 ⼈間と AI
で分業 全マイクロサービスの HPA → KEDA を完遂 Phase 1 → Phase 5 を 2025-11 〜 2026-04 で実⾏ 決定論差分は spec.md + Go CLI に固定 ツールの実装も Codex が書いた Linear x Codex / Devin で 1 issue = 1 PR 親に共通ランブック、 ⼦で実⾏、 並列化 並列化の律速は受け側 (GitOps / CI) agent の能⼒ではなく、 運⽤側のスループット設計が要
AIによるレビューで200 PR /dayの50%は自動化
Part 2 背景: ガイドラインと AI エージェントコンテキストのギャップ Notion: Akupara ガイドライン プラットフォームルールの
SoT (Source of Truth) サービス‧プロダクト数の増加で、 Notion の存在を知らない利⽤者も増加 → ガイドラインが守られない ⽬指したい状態 PR レビューコンテキストに ガイドラインを強制的に注⼊ Notion は SoT として残し、 レビュー⽤コンテキストを派⽣⽣成 Agent Skill 単体で完結 (外部リソース依存なし)
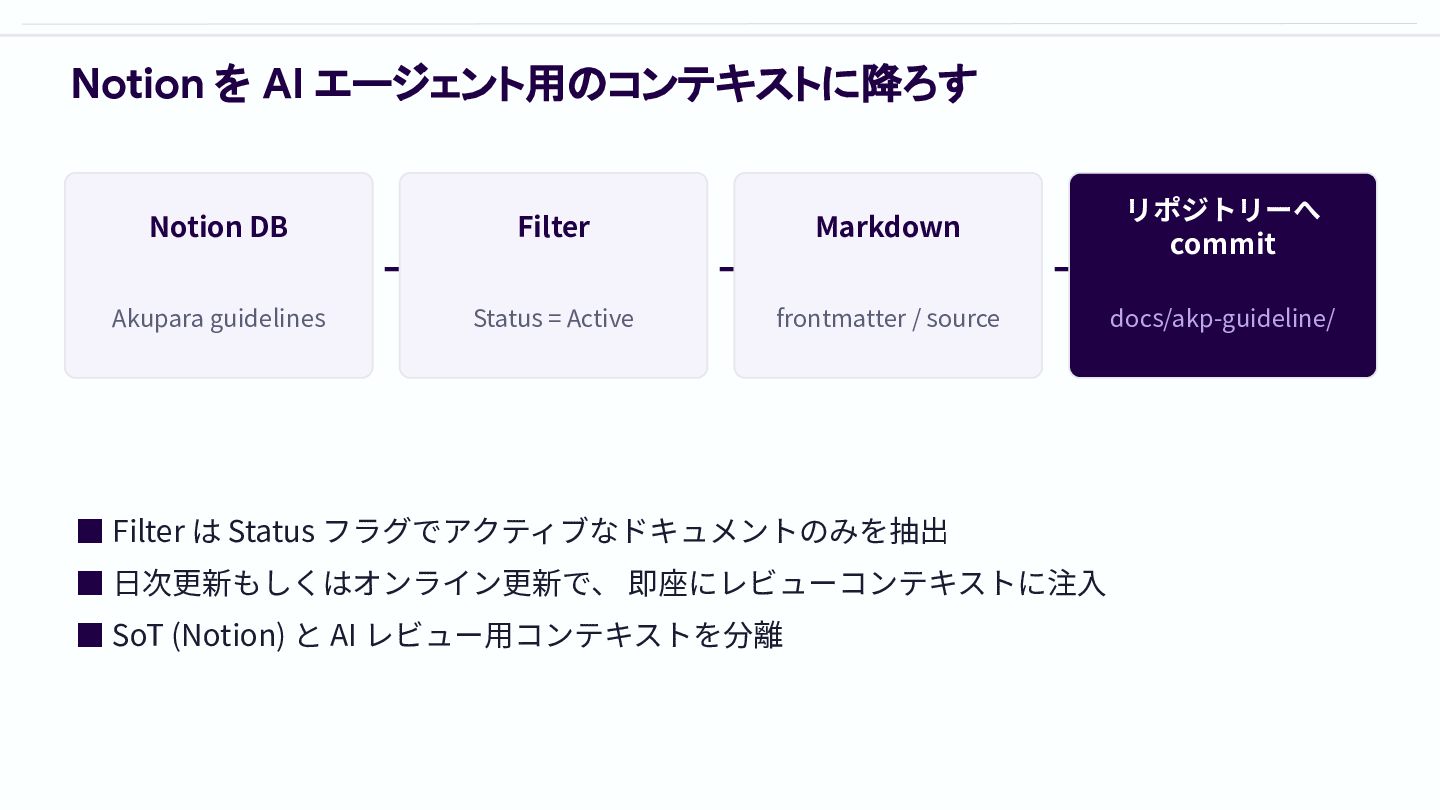
Notion を AI エージェント用のコンテキストに降ろす Notion DB Akupara guidelines → Filter
Status = Active → Markdown frontmatter / source → リポジトリーへ commit docs/akp-guideline/ ▪ Filter は Status フラグでアクティブなドキュメントのみを抽出 ▪ ⽇次更新もしくはオンライン更新で、 即座にレビューコンテキストに注⼊ ▪ SoT (Notion) と AI レビュー⽤コンテキストを分離
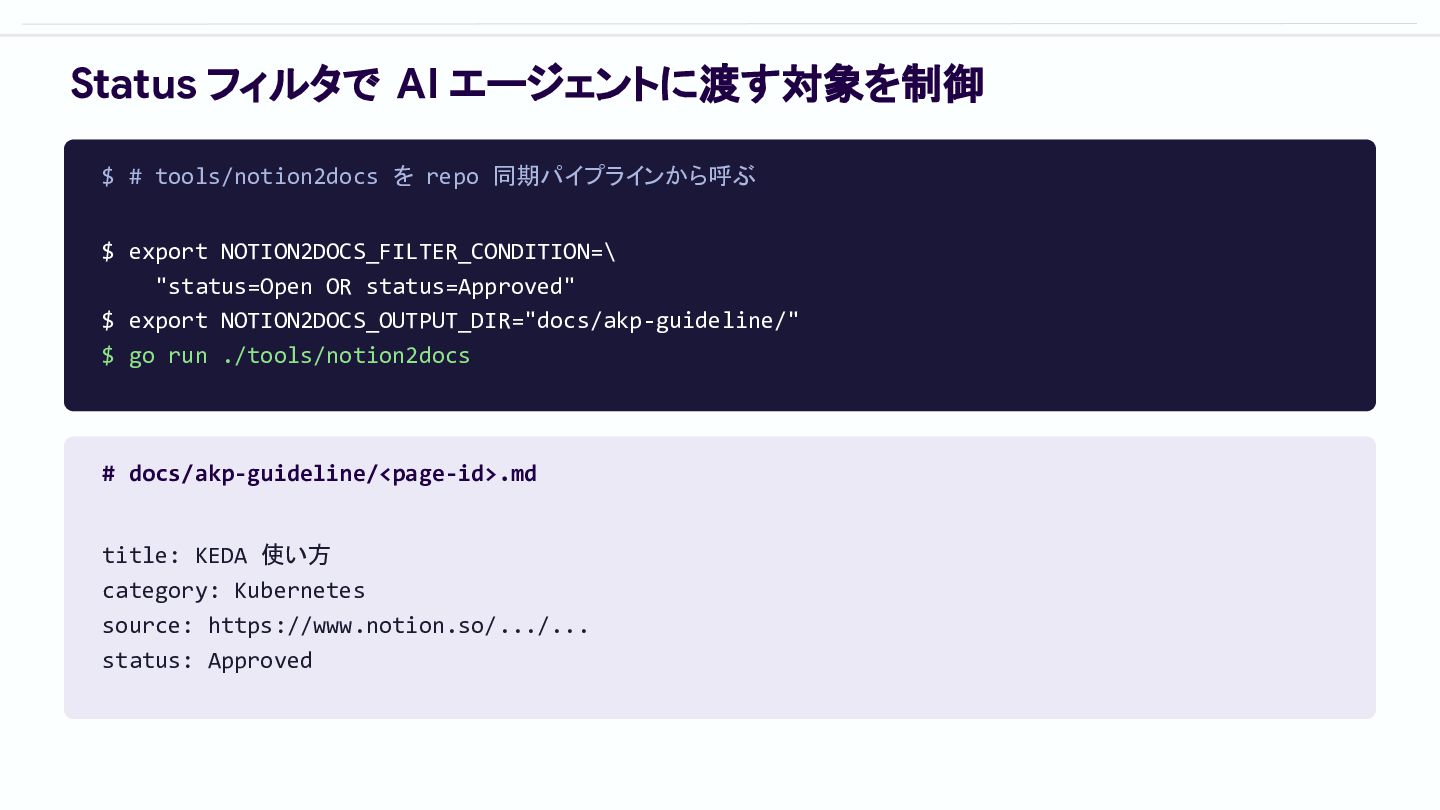
Status フィルタで AI エージェントに渡す対象を制御 $ # tools/notion2docs を repo 同期パイプラインから呼ぶ
$ export NOTION2DOCS_FILTER_CONDITION=\ "status=Open OR status=Approved" $ export NOTION2DOCS_OUTPUT_DIR="docs/akp-guideline/" $ go run ./tools/notion2docs # docs/akp-guideline/<page-id>.md title: KEDA 使い方 category: Kubernetes source: https://www.notion.so/.../... status: Approved
レビューコンテキストをリポジトリーに固定する 3 箇所 1. docs/akp-guideline/ Notion から降ってくる Markdown スナップショッ ト
AI レビューの根拠 2. AGENTS.md / Skill ガイドラインスナップ ショット を references として読む codex /review @codex review 3. PR template Notion / spec.md / Linear issue を必須 ⼈間 と AI が 同じ frame で読む レビューコンテキストはリポジトリーにコミットする。
実例: Codex Review が社内ガイドラインを引用 PR #36120 — ast-metrics-jp の GAR
IAM 設定追加 ▪ Codex が P1 (⾼優先度) として指摘 ▪ 重複した IAM 設定を別 state で管理している, という社内ガ イドライン違反を指摘 ▪ skills/akupara-guideline-review/references/docs/... までファイルパスを引⽤ → ⼀般論ではなく、 社内ルールに照らした具体的指摘
AI レビューで SRE が楽になったこと / 変わらなかったこと SRE が楽になったこと ガイドラインに照らした指摘が PR
に⾃動で出る ガイドライン外の議論に集中できる 指摘されない = 暗黙知の発⾒ 引き続き変わらなかったこと ⼈間レビュワーは不要にならない ロールアウト‧トレードオフ判断は⼈間 prd 環境への適⽤は⼈間がみる (イレギュラーな PR も同じく)
Part 2 まとめ AI レビューを社内⽂脈に接続するために、 ガイドラインを repo に降ろした Notion ガイドラインをリポジトリーへ同期
Status フィルタでアクティブなものだけ Agent Skill 単体でレビューが完結 外部リソース依存なし、 強制注⼊ レビューコンテキストはリポジトリーの 3 箇所に固定 docs / AGENTS / PR template 気づき: 暗黙知は AI に指摘されない 「指摘されない部分」が暗黙知の発⾒
問い合わせ・トラブルシュー ティングをAIにやってもらう
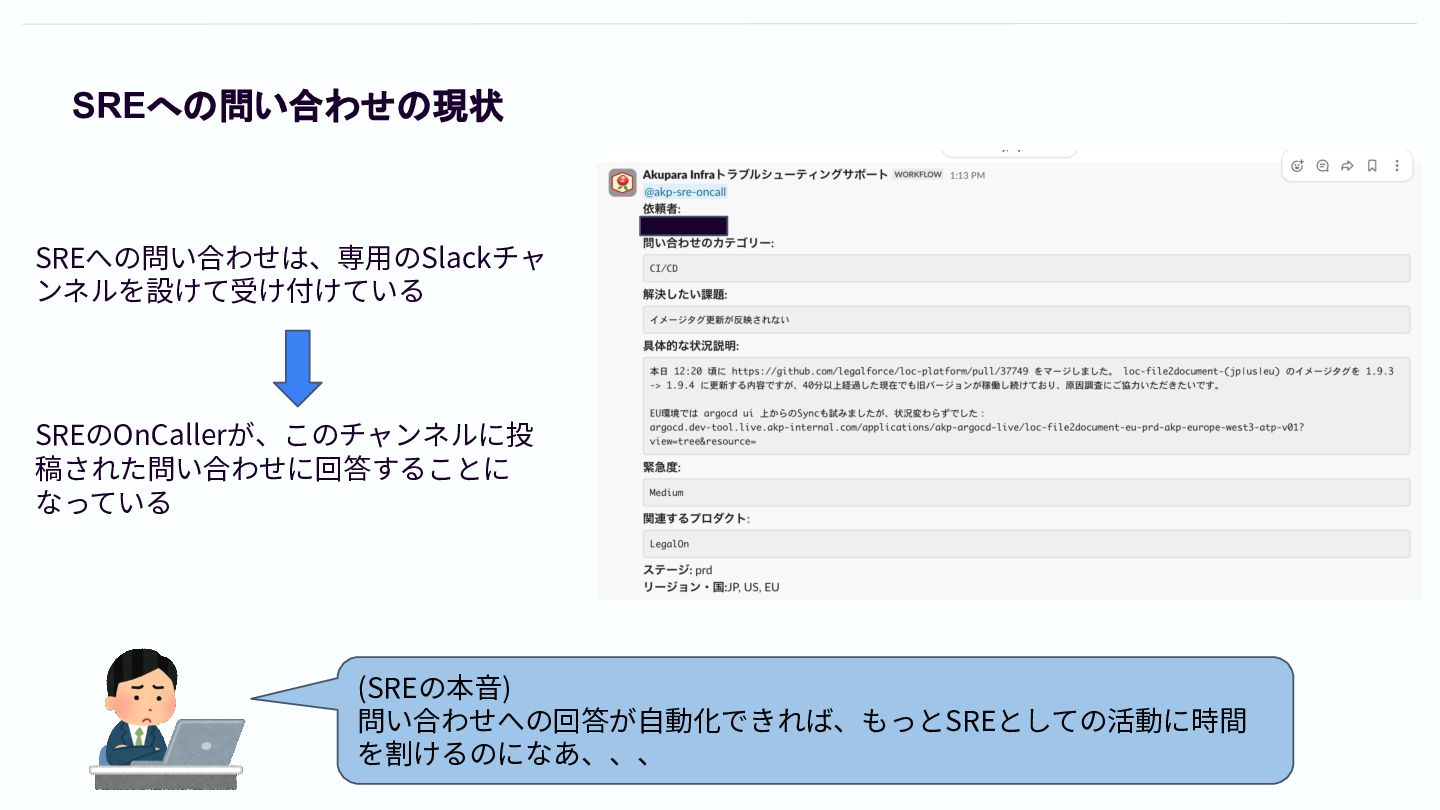
SREへの問い合わせの現状 SREへの問い合わせは、専⽤のSlackチャ ンネルを設けて受け付けている SREのOnCallerが、このチャンネルに投 稿された問い合わせに回答することに なっている (SREの本⾳) 問い合わせへの回答が⾃動化できれば、もっとSREとしての活動に時間 を割けるのになあ、、、
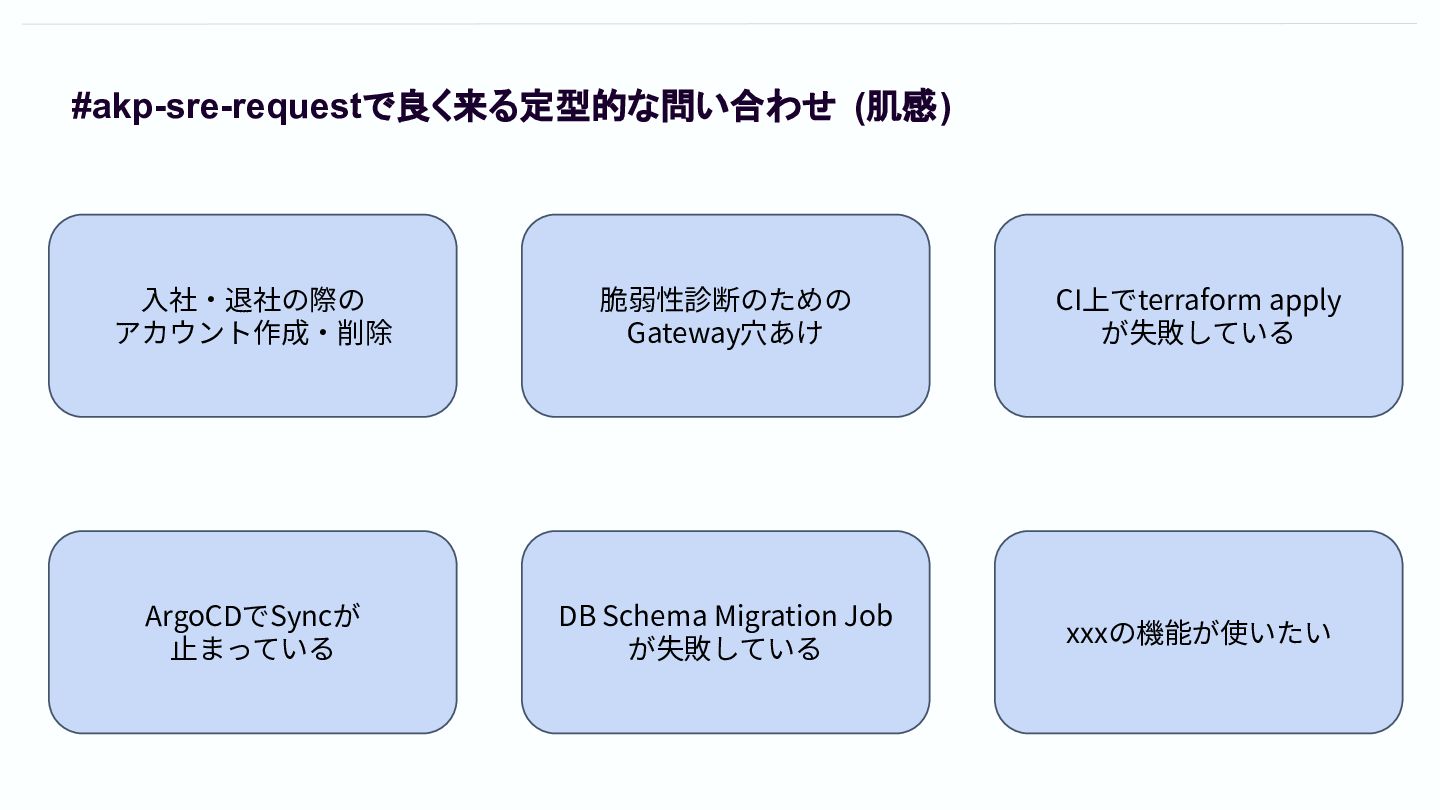
#akp-sre-requestで良く来る定型的な問い合わせ (肌感) ⼊社‧退社の際の アカウント作成‧削除 脆弱性診断のための Gateway⽳あけ CI上でterraform apply が失敗している ArgoCDでSyncが
⽌まっている DB Schema Migration Job が失敗している xxxの機能が使いたい
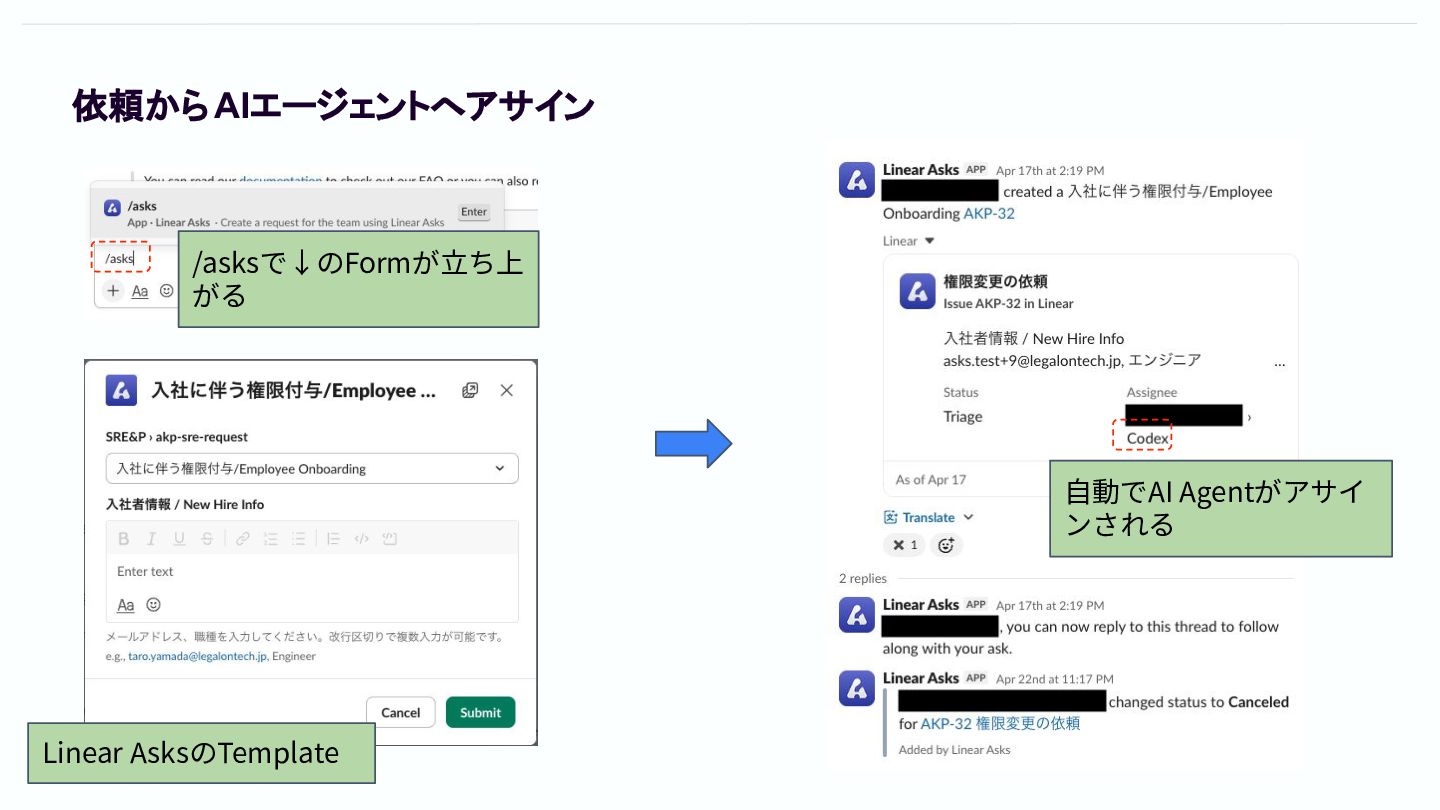
問い合わせ回答の自動化を試みる 問い合わせ回答の⾃動化の試みとして、Linear Asksの導⼊を検討しました。 Linear Asksって? • Slackやメールで受けた依頼をLinearのissue として受け付けて運⽤できる機能 • Linearで作成されるissueは、AI
エージェント をアサインできるので、Linear Asksで質問を 受ける → issueを作成する → AI エージェント をアサインして作業させるという⼀連の流れ を作れる ※ Linear Asksは、LinearのBusiness/Eneterprise plan両⽅で使えますが、Business Planだと機 能にやや制限があります(privateチャンネル使えない、など)
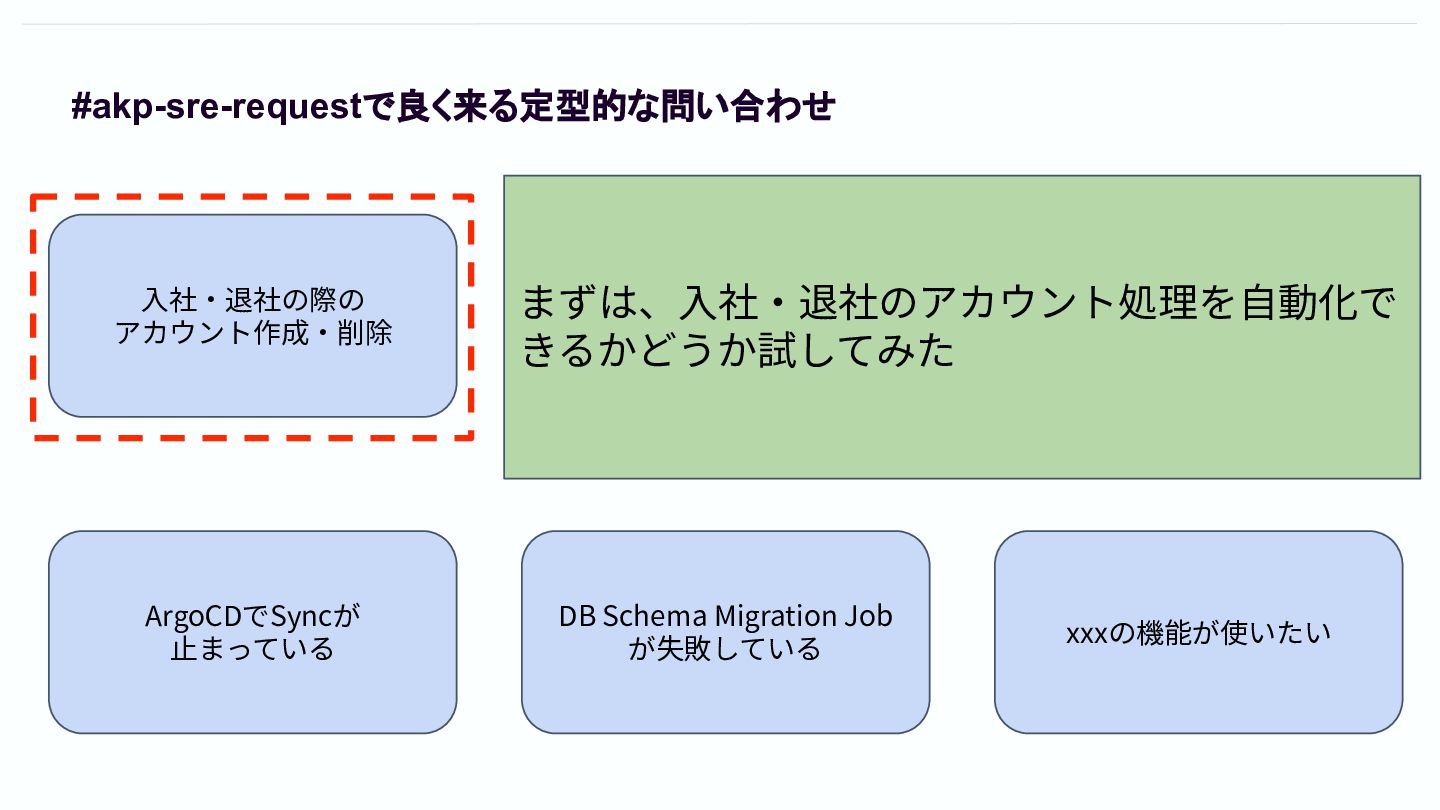
#akp-sre-requestで良く来る定型的な問い合わせ ⼊社‧退社の際の アカウント作成‧削除 脆弱性診断のための Gateway⽳あけ CI上でterraform apply が失敗している ArgoCDでSyncが ⽌まっている
DB Schema Migration Job が失敗している xxxの機能が使いたい まずは、⼊社‧退社のアカウント処理を⾃動化で きるかどうか試してみた
依頼からAIエージェントへアサイン /asksで↓のFormが⽴ち上 がる ⾃動でAI Agentがアサイ ンされる Linear AsksのTemplate
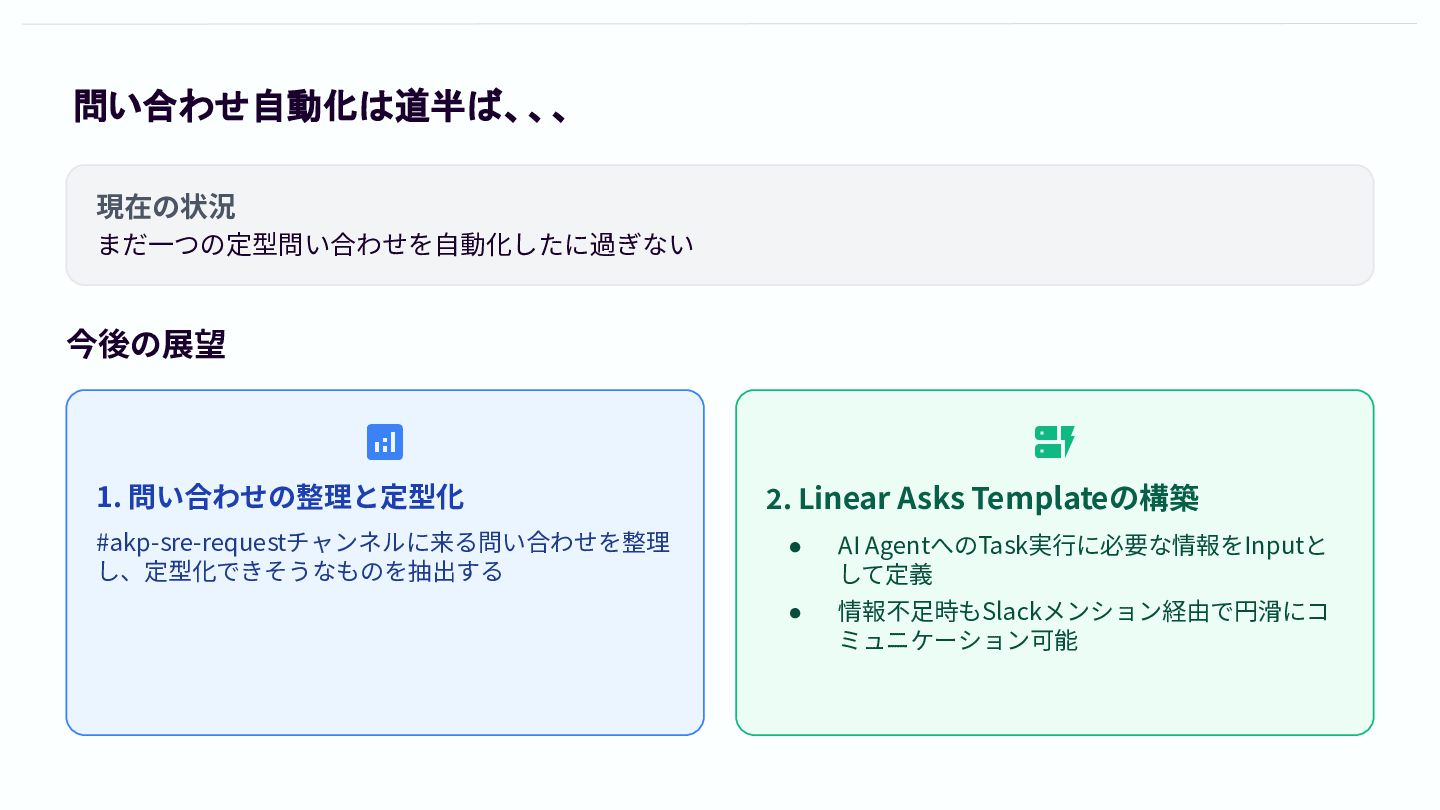
問い合わせ自動化は道半ば、、、 現在の状況 まだ⼀つの定型問い合わせを⾃動化したに過ぎない 今後の展望 1. 問い合わせの整理と定型化 #akp-sre-requestチャンネルに来る問い合わせを整理 し、定型化できそうなものを抽出する
2. Linear Asks Templateの構築 • AI AgentへのTask実⾏に必要な情報をInputと して定義 • 情報不⾜時もSlackメンション経由で円滑にコ ミュニケーション可能
Production Readiness Check のEvidence確認もAIにやって もらおう
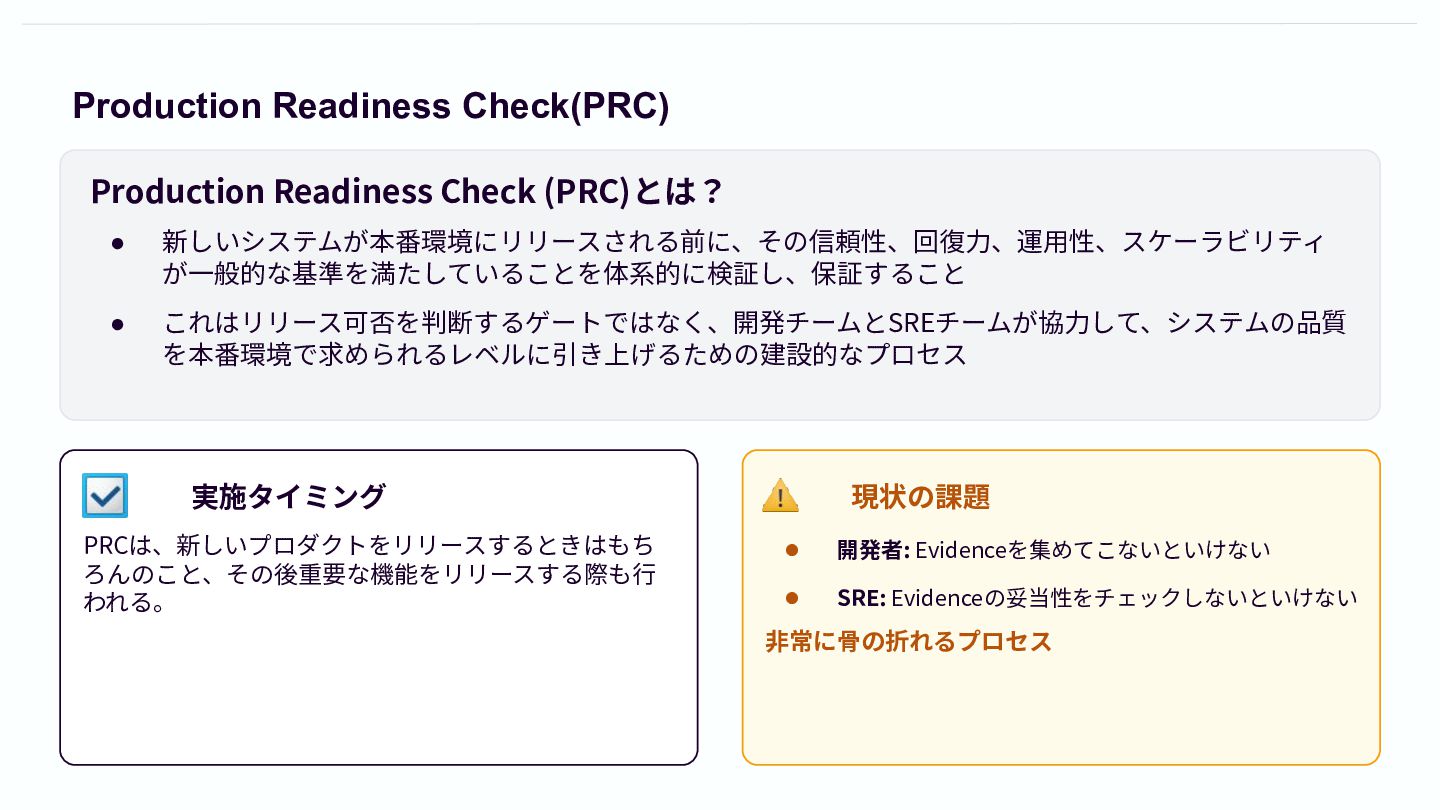
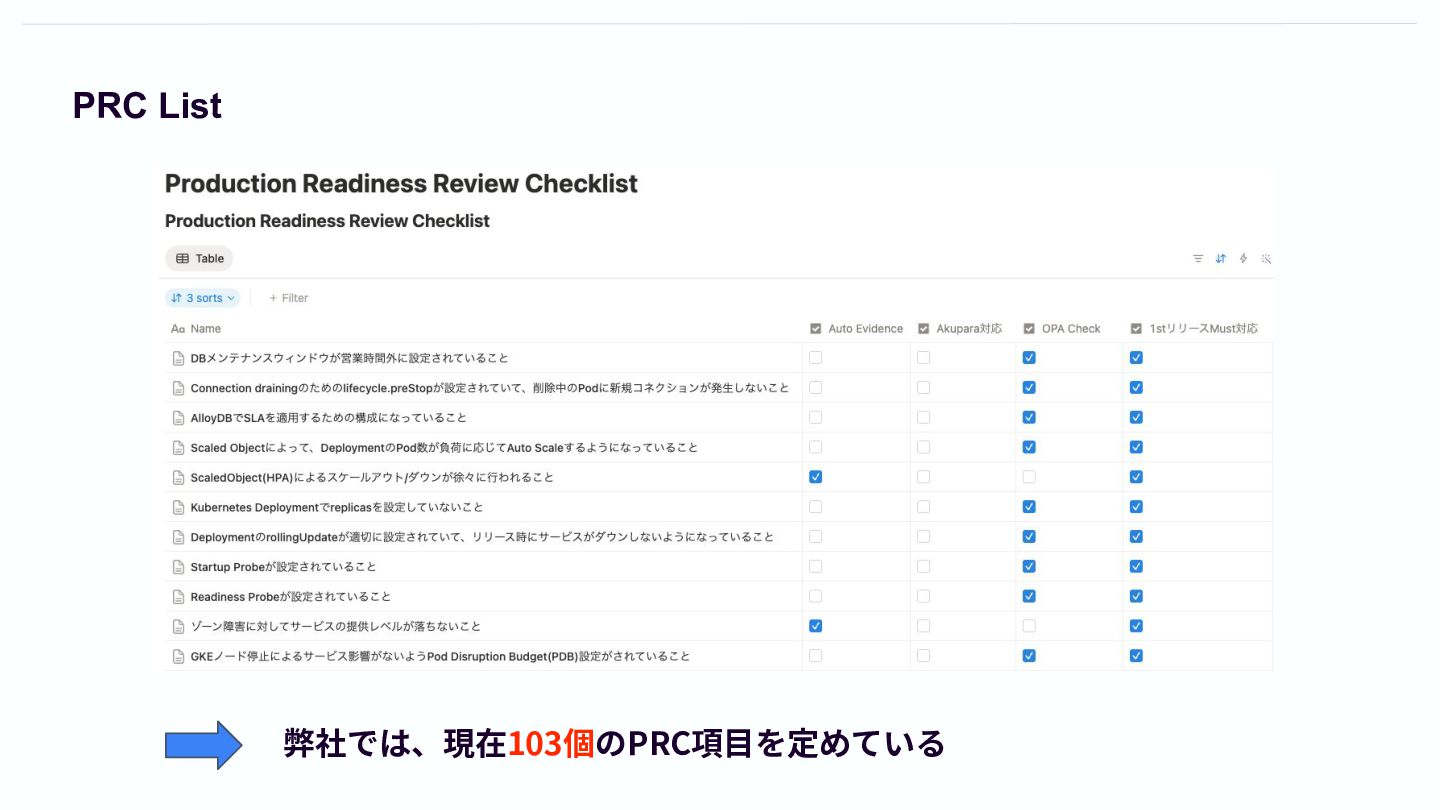
Production Readiness Check(PRC) Production Readiness Check (PRC)とは? • 新しいシステムが本番環境にリリースされる前に、その信頼性、回復⼒、運⽤性、スケーラビリティ が⼀般的な基準を満たしていることを体系的に検証し、保証すること
• これはリリース可否を判断するゲートではなく、開発チームとSREチームが協⼒して、システムの品質 を本番環境で求められるレベルに引き上げるための建設的なプロセス 実施タイミング PRCは、新しいプロダクトをリリースするときはもち ろんのこと、その後重要な機能をリリースする際も⾏ われる。 現状の課題 • 開発者: Evidenceを集めてこないといけない • SRE: Evidenceの妥当性をチェックしないといけない ⾮常に⾻の折れるプロセス
PRC List 弊社では、現在103個のPRC項⽬を定めている
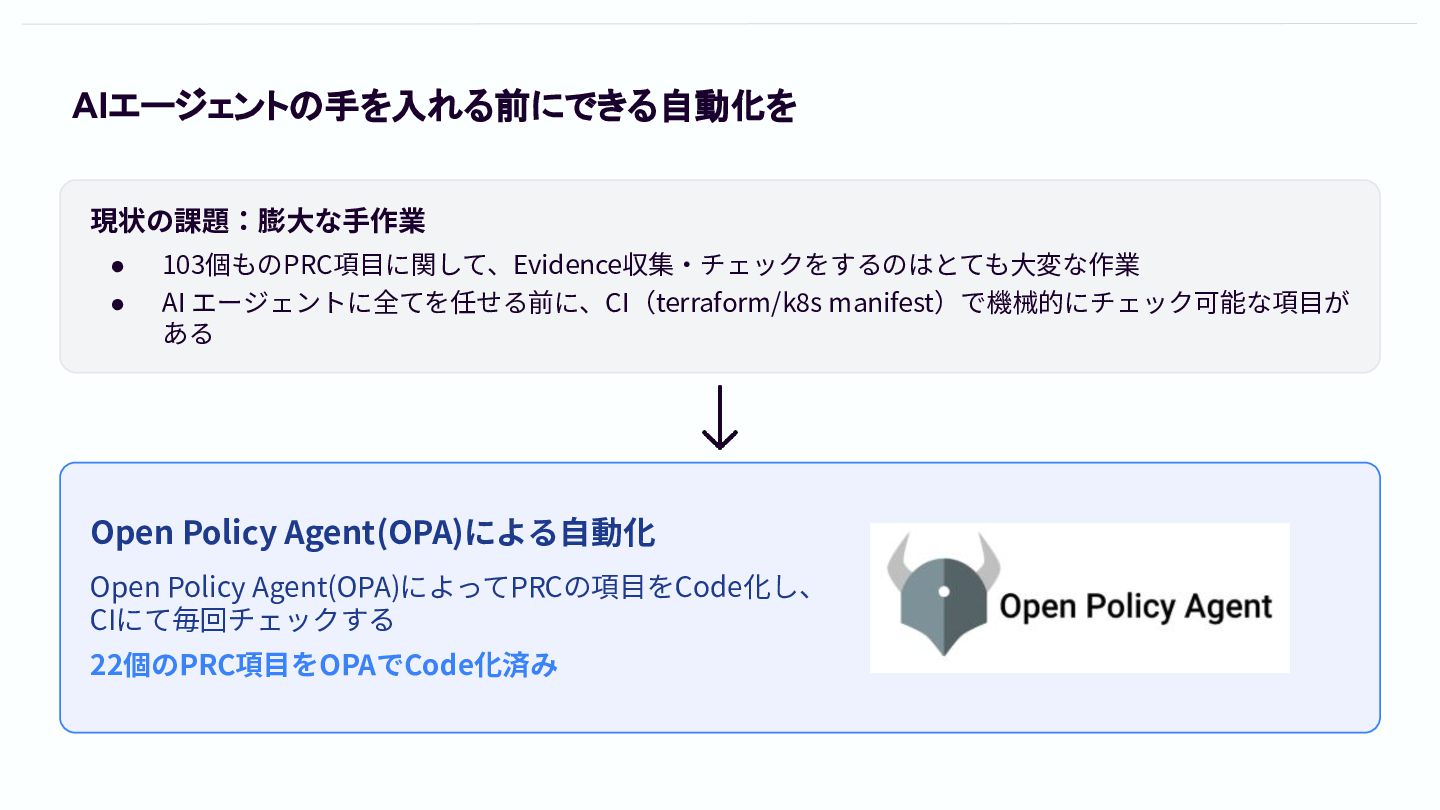
PRC作業自動化のための方針 AIに任せるべき項⽬とそうでないものを篩い分ける AIが解釈しやすいようなPRCの内容にする
AIエージェントの手を入れる前にできる自動化を 現状の課題:膨⼤な⼿作業 • 103個ものPRC項⽬に関して、Evidence収集‧チェックをするのはとても⼤変な作業 • AI エージェントに全てを任せる前に、CI(terraform/k8s manifest)で機械的にチェック可能な項⽬が ある Open
Policy Agent(OPA)による⾃動化 Open Policy Agent(OPA)によってPRCの項⽬をCode化し、 CIにて毎回チェックする 22個のPRC項⽬をOPAでCode化済み
(ちょっと脱線 ) regoとAIエージェントとの親和性 regoはなかなかとっつきにくい⾔語なので、これこそAIに書かせるべきものです! 弊社では、regoを⾃⼒で書くことは⽌めました AI AgentにPRC項⽬のNotionページリンク渡し て、「これOPA化して」でパパっとCode化 Codex, Claude
Code
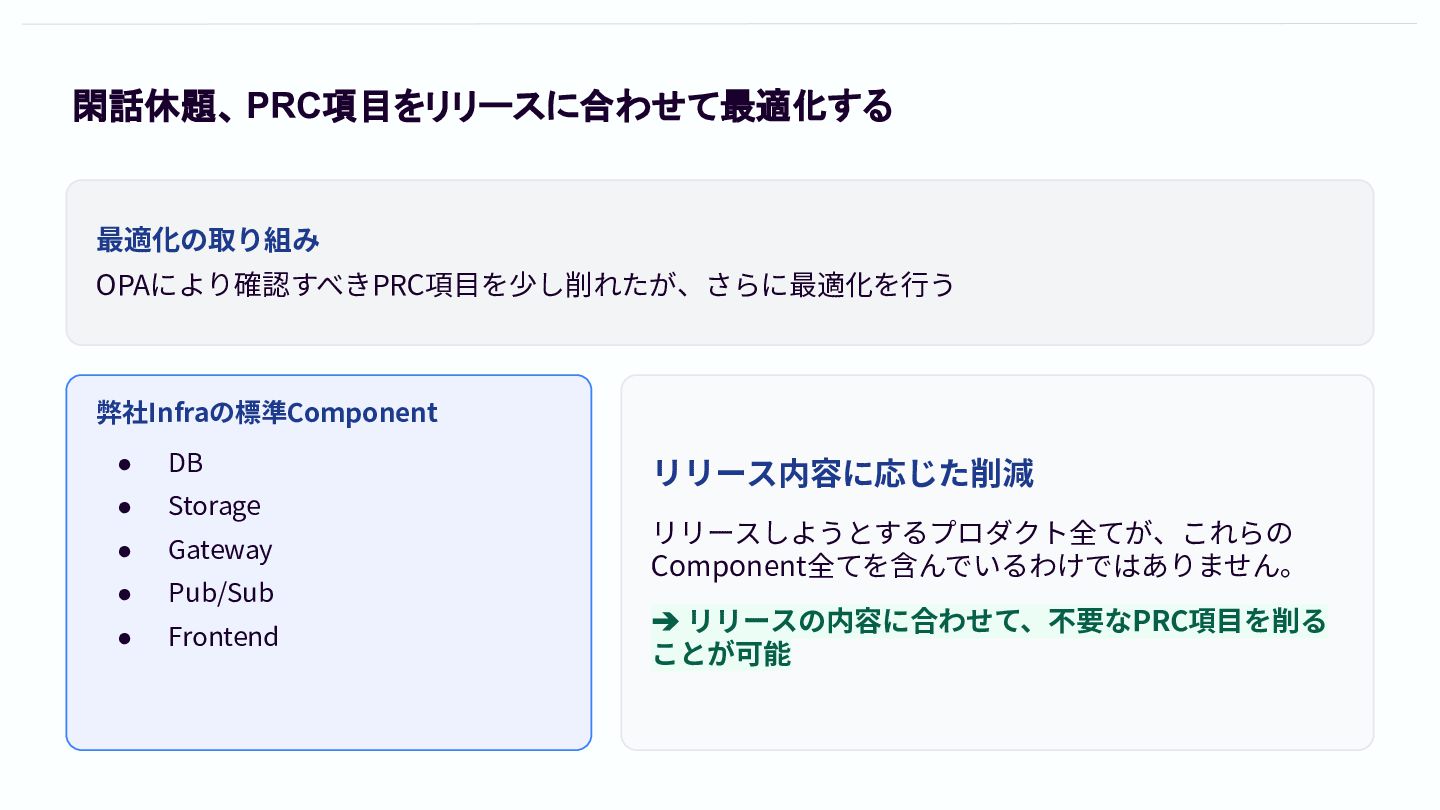
閑話休題、 PRC項目をリリースに合わせて最適化する 最適化の取り組み OPAにより確認すべきPRC項⽬を少し削れたが、さらに最適化を⾏う 弊社Infraの標準Component • DB • Storage •
Gateway • Pub/Sub • Frontend リリース内容に応じた削減 リリースしようとするプロダクト全てが、これらの Component全てを含んでいるわけではありません。 ➔ リリースの内容に合わせて、不要なPRC項⽬を削る ことが可能
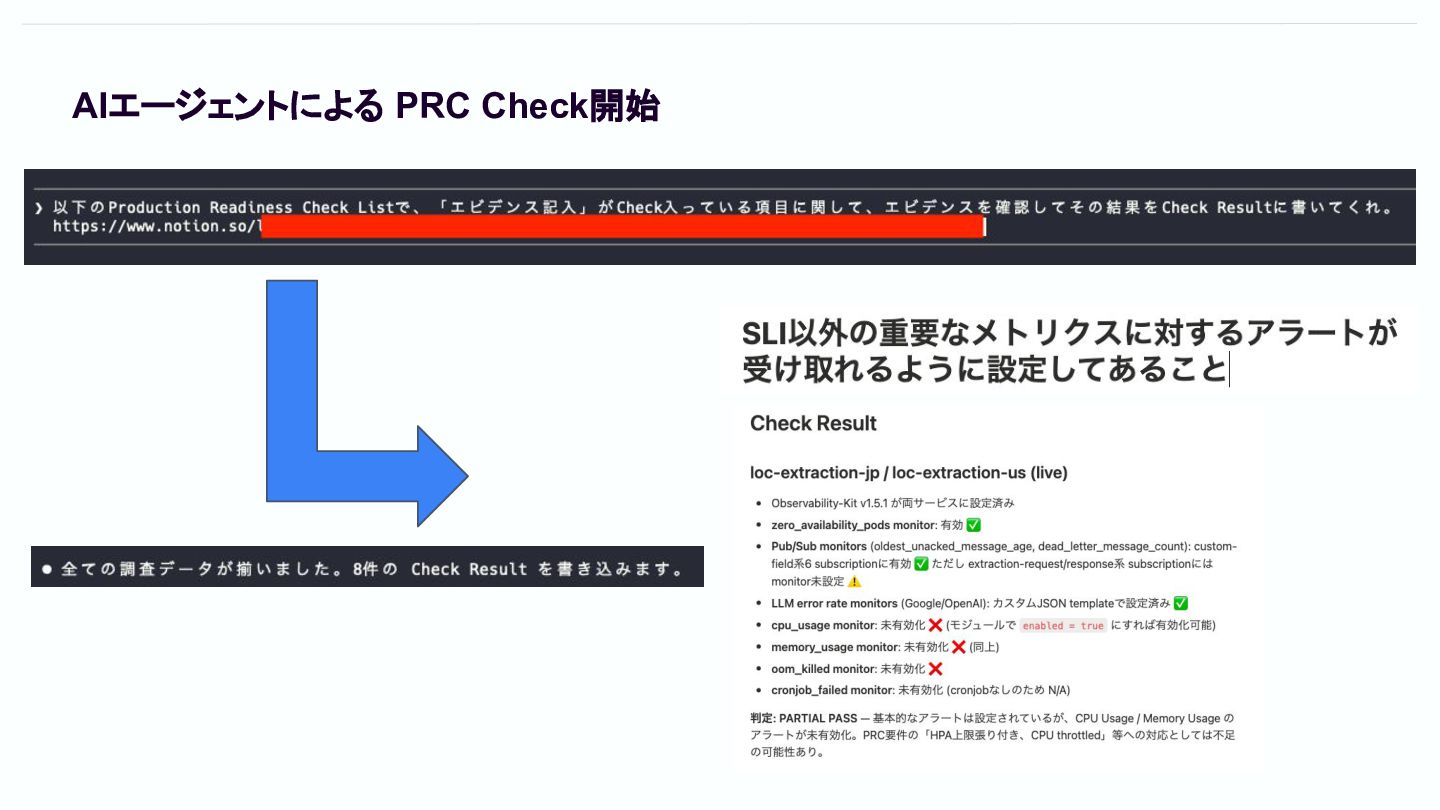
AIエージェントが Checkしやすいように PRC項目のフォーマットを決めておく • 以前はやや解釈が難しいようなPRC項⽬が含まれていたが、⾃動化に向けて解釈がブレないよ うにした • 各項⽬のフォーマットも整理 Detailsに確認する項⽬の詳細について記載 Evidenceに証跡のリンクを貼る
ここにAIにはEvidence確認結果を貼ってもらう
AIエージェントによる PRC Check開始
まとめ
まとめ AIに任せる領域を⾒定める • AIが得意とするタスクは、⾮決定論的なタスク • 逆に、やるべきことが明確なタスクは、ツールを使って⾏った⽅がコスト的にも良 ◦ AI使うにもやはりお⾦はかかるので、ツールで達成できてしまうのであれば、そち らのが良い、という意味 •
よって、タスクは徹底的に整理する必要がある ◦ そうすると、AIに任せるべきかどうかが⾒えてくる
• コーディング規約やTerraform Moduleなどのツールの使い⽅などをしっかり⽂書化して おくことが⼤事 ◦ 弊社の例では、PlatformのInterfaceとしてのドキュメント作りを意識していたの で、それがAI活⽤においても活きた • 作成した⽂書は、AIが利⽤しやすい形にしておくことも意識する •
暗黙知の発⾒ -> 明⽂化のループを回す まとめ 社内ナレッジを整理すればするほどAIは優秀な同僚と なってくれる
株式会社LegalOn Technologies https://legalontech.jp/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}