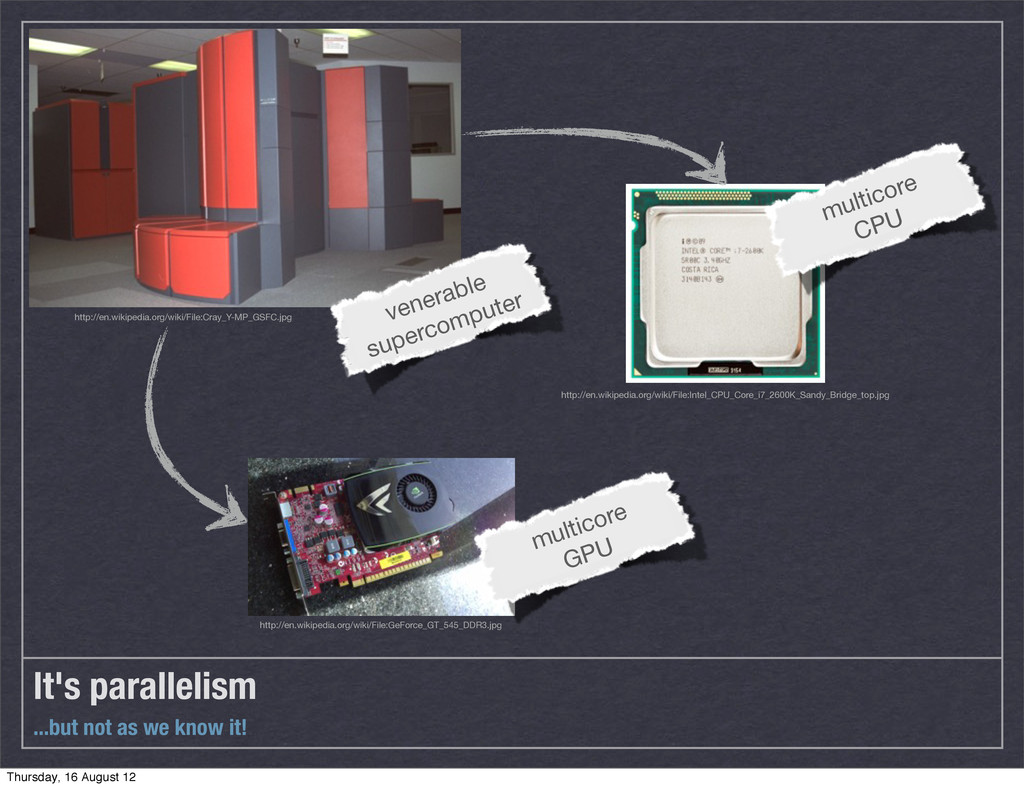
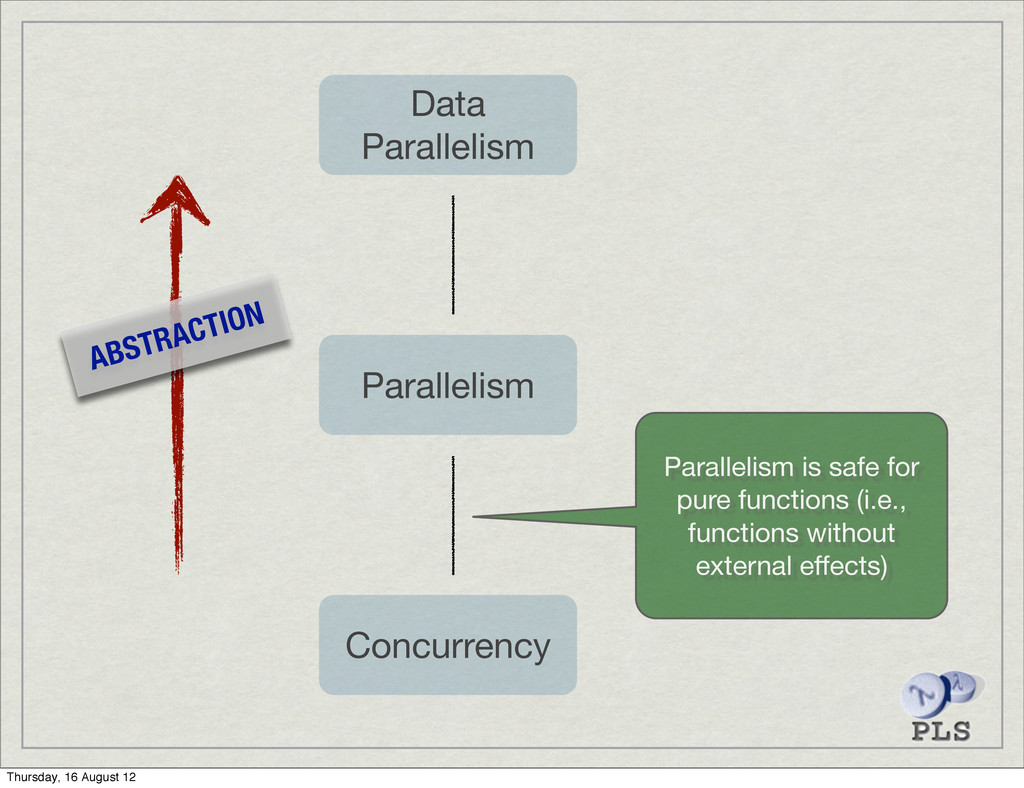
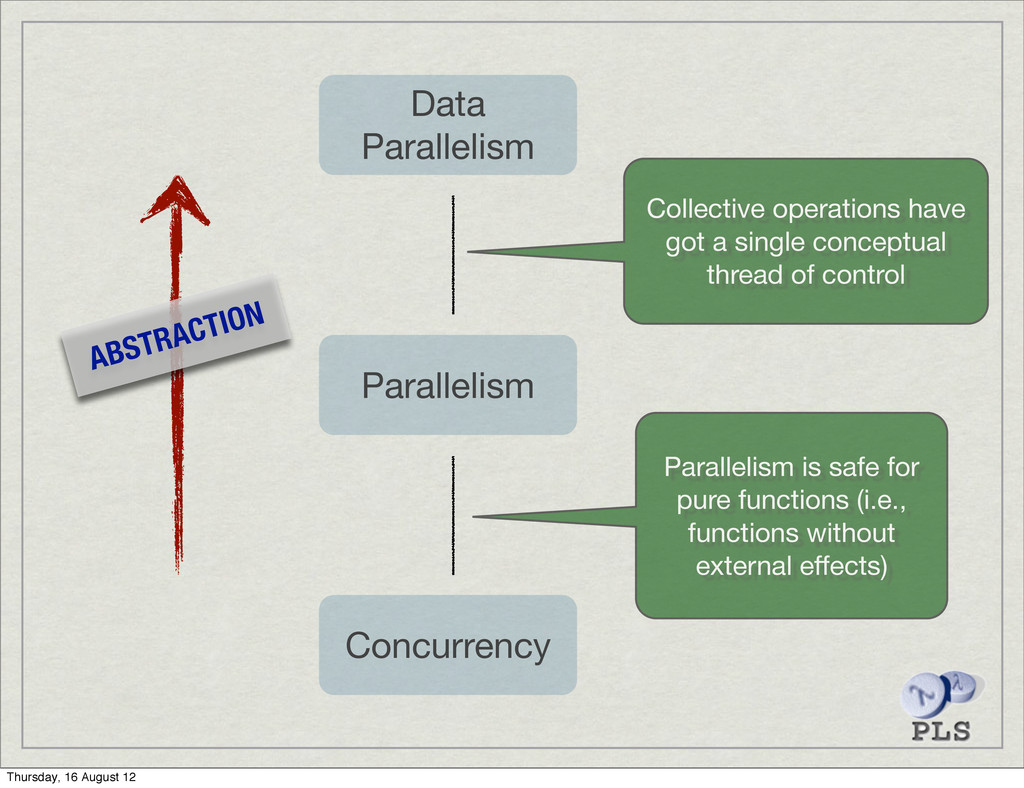
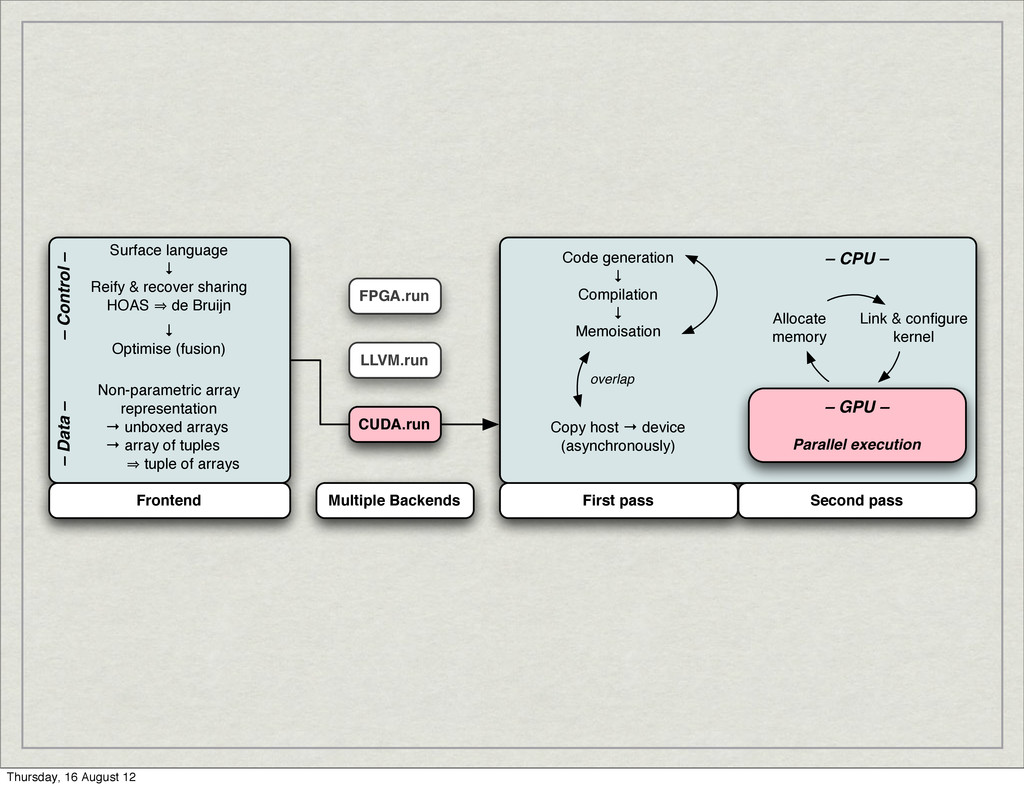
is important, but… ‣ …productivity is more important. Semi-automatic parallelism ‣ Programmer supplies a parallel algorithm ‣ No explicit concurrency (no concurrency control, no races, no deadlocks) Thursday, 16 August 12
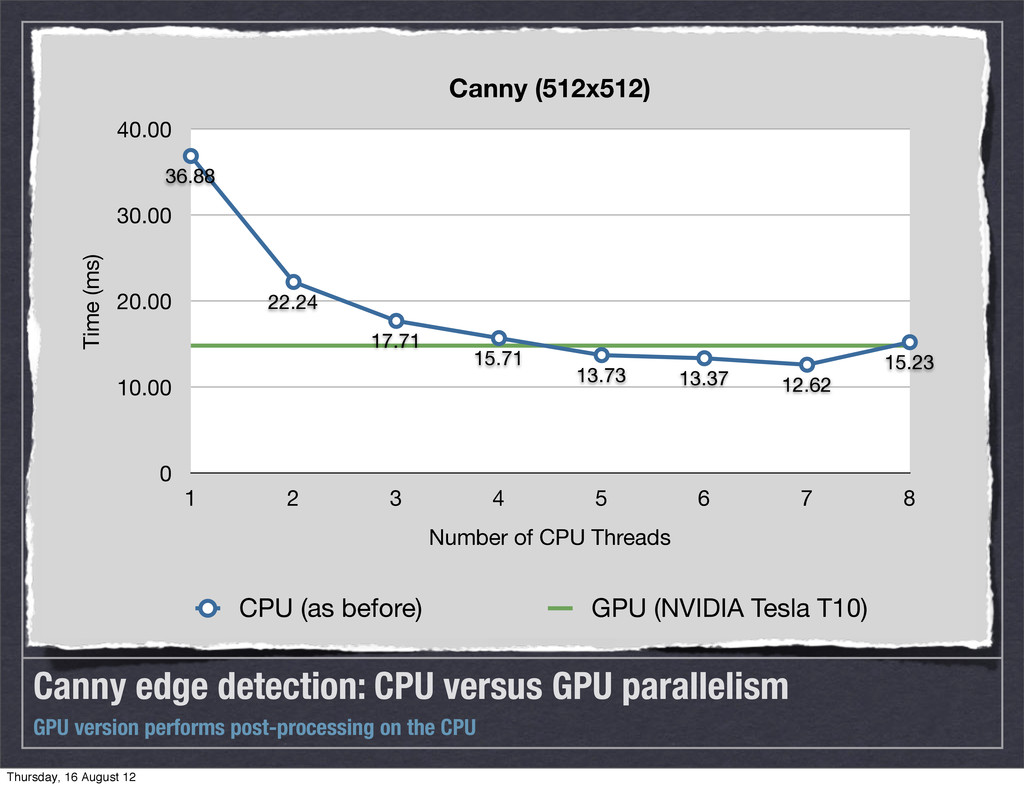
post-processing on the CPU 0 10.00 20.00 30.00 40.00 1 2 3 4 5 6 7 8 36.88 22.24 17.71 15.71 13.73 13.37 12.62 15.23 Canny (512x512) Time (ms) Number of CPU Threads CPU (as before) GPU (NVIDIA Tesla T10) Thursday, 16 August 12
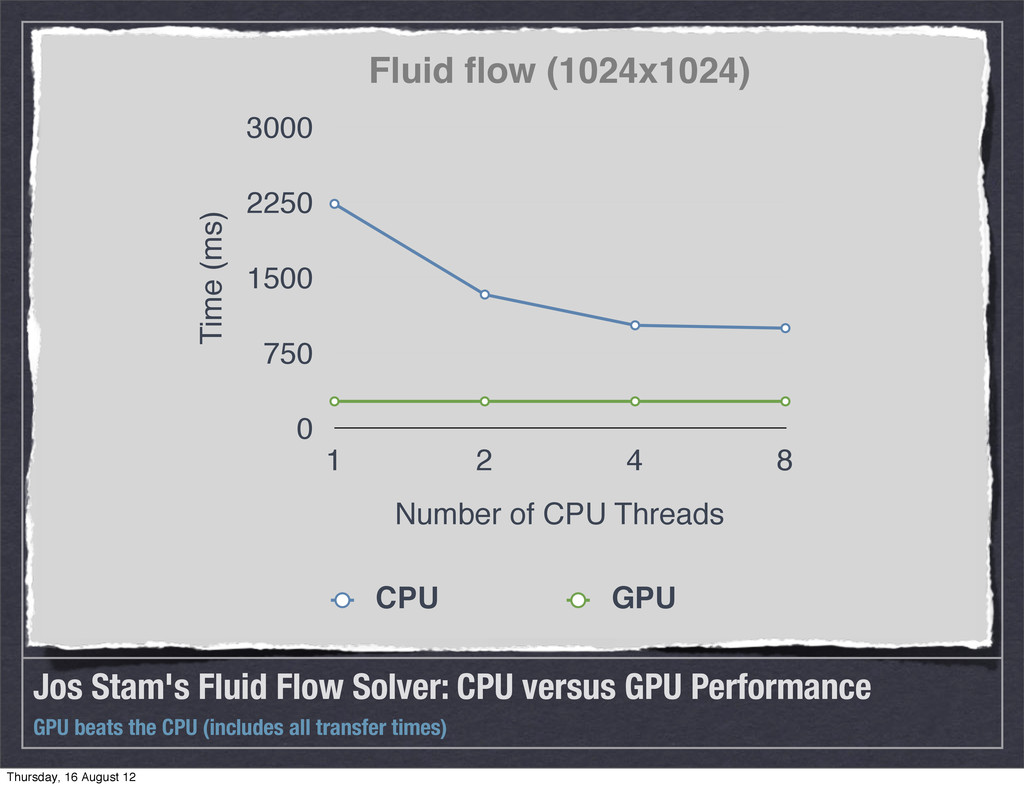
beats the CPU (includes all transfer times) 0 750 1500 2250 3000 1 2 4 8 Fluid flow (1024x1024) Time (ms) Number of CPU Threads CPU GPU Thursday, 16 August 12
and behaviour Bulk-parallel aggregate operations Haskell is by default pure Declarative control of operational pragmatics Data parallelism Thursday, 16 August 12
i7 970 CPU NVIDIA GF100 GPU 12 THREADS 24,576 THREADS ✴SIMD: groups of threads executing in lock step (warps) ✴Need to be careful about control flow Thursday, 16 August 12
i7 970 CPU NVIDIA GF100 GPU 12 THREADS 24,576 THREADS ✴Latency hiding: optimised for regular memory access patterns ✴Optimise memory access ✴SIMD: groups of threads executing in lock step (warps) ✴Need to be careful about control flow Thursday, 16 August 12
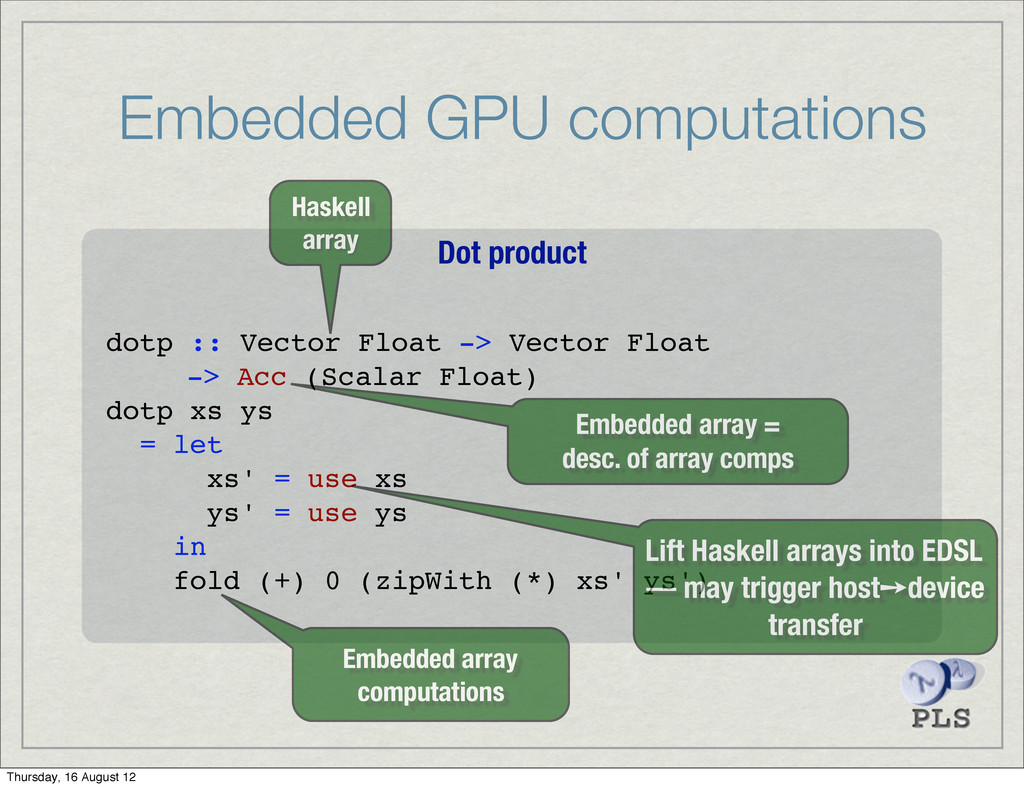
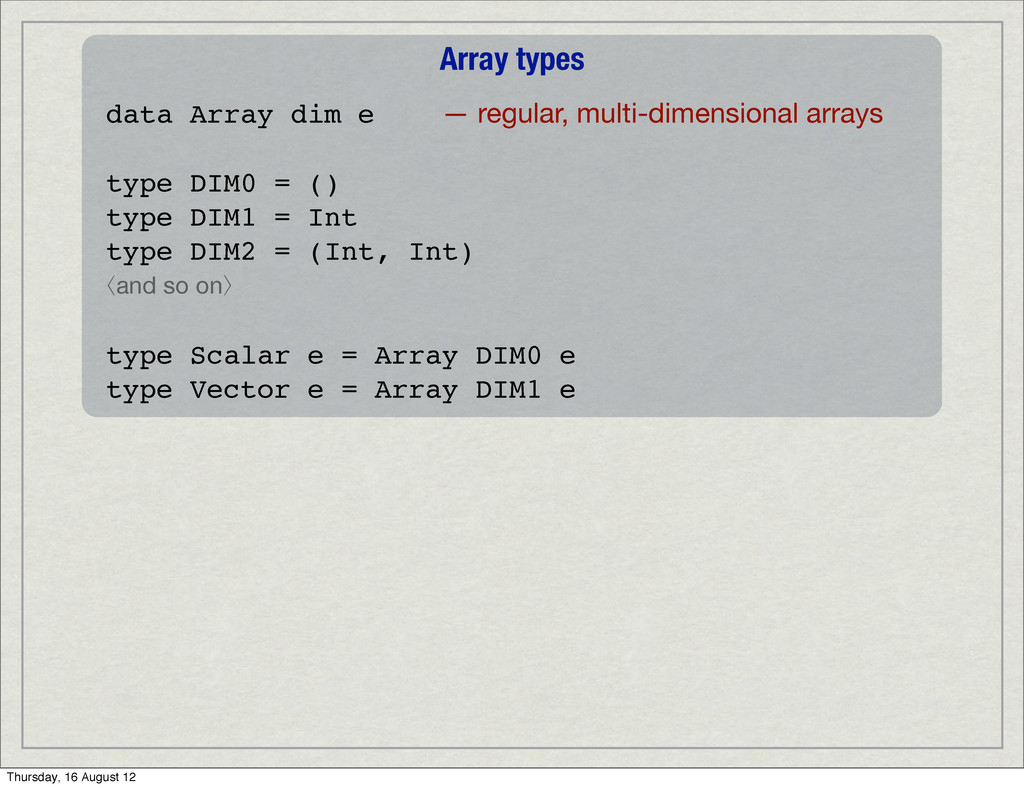
type DIM0 = () type DIM1 = Int type DIM2 = (Int, Int) ⟨and so on⟩ type Scalar e = Array DIM0 e type Vector e = Array DIM1 e EDSL forms data Exp e — scalar expression form data Acc a — array expression form Thursday, 16 August 12
type DIM0 = () type DIM1 = Int type DIM2 = (Int, Int) ⟨and so on⟩ type Scalar e = Array DIM0 e type Vector e = Array DIM1 e EDSL forms data Exp e — scalar expression form data Acc a — array expression form Classes class Elem e — scalar and tuples types class Elem ix => Ix ix — unit and integer tuples Thursday, 16 August 12
a, Elem b) => (Exp a -> Exp b) -> Acc (Array dim a) -> Acc (Array dim b) zipWith :: (Ix dim, Elem a, Elem b, Elem c) => (Exp a -> Exp b -> Exp c) -> Acc (Array dim a) -> Acc (Array dim b) -> Acc (Array dim c) Thursday, 16 August 12
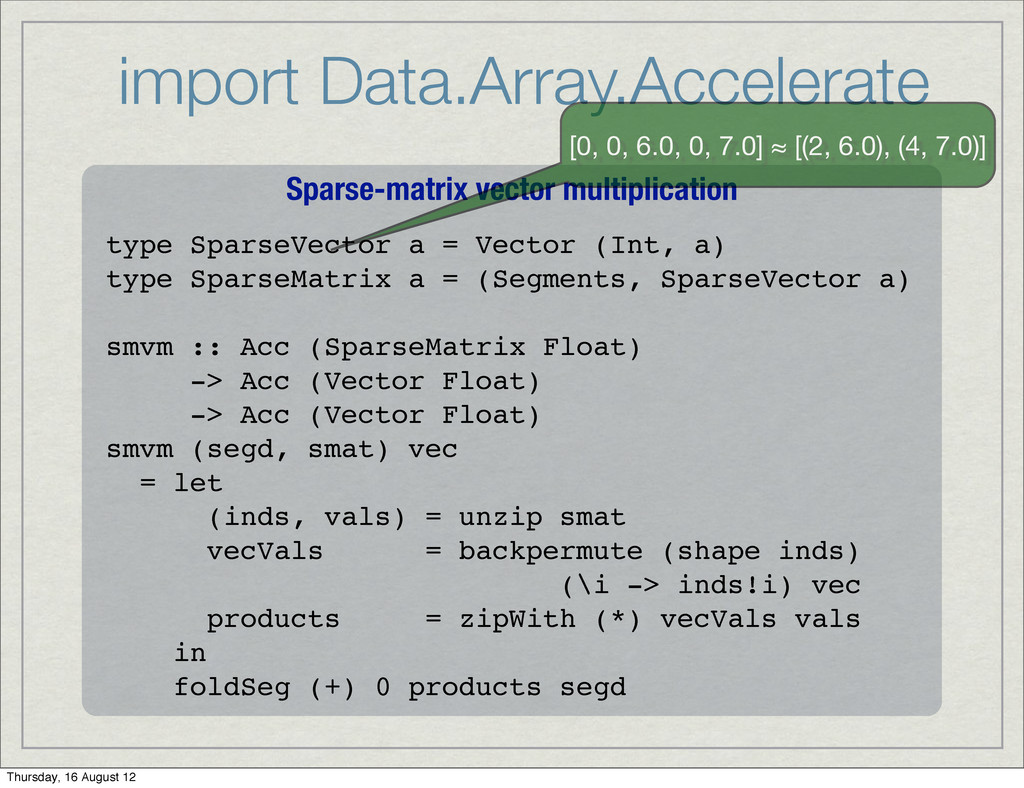
a) => (Exp a -> Exp a -> Exp a) — associative -> Exp a -> Acc (Array dim a) -> Acc (Scalar a) scan :: Elem a => (Exp a -> Exp a -> Exp a) — associative -> Exp a -> Acc (Vector a) -> (Acc (Vector a), Acc (Scalar a)) Thursday, 16 August 12
dim', Elem a) => (Exp a -> Exp a -> Exp a) -> Acc (Array dim' a) -> (Exp dim -> Exp dim') -> Acc (Array dim a) -> Acc (Array dim' a) backpermute :: (Ix dim, Ix dim', Elem a) => Exp dim' -> (Exp dim' -> Exp dim) -> Acc (Array dim a) -> Acc (Array dim' a) Thursday, 16 August 12
data parallel) Support for multiple backends Status: ‣ On GitHub: https://github.com/AccelerateHS/accelerate ‣ Under active development Thursday, 16 August 12
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Computer Vision [Haskell 2011] Edge detection Thursday, 16 August 12](https://files.speakerdeck.com/presentations/d0b250202aef0130898a12313d035c57/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
![Physical Simulation [Haskell 2012a] Fluid flow Thursday, 16 August 12](https://files.speakerdeck.com/presentations/d0b250202aef0130898a12313d035c57/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}