Site Reliability Engineering (SRE) is an expensive proposition for small and large organizations alike. You can mitigate the costs by:
Setting up the right organizational structure for SRE
Hiring for the right team composition
Building the SRE culture
Piyush Verma, co-founder of Last9 Inc shares practical insights and wisdom, from accumulated successful and not-so-successful experiences.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Instead, what we need is... Self-checking software [Michael Lyu] Observability](https://files.speakerdeck.com/presentations/e297b48b89d843438bf84f8bd3879efe/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
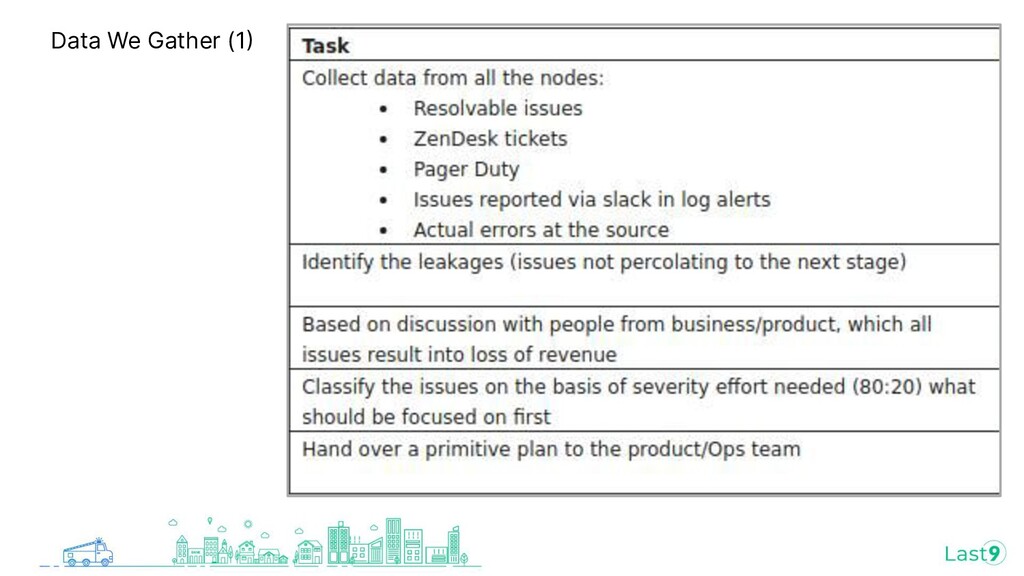{kind=link}
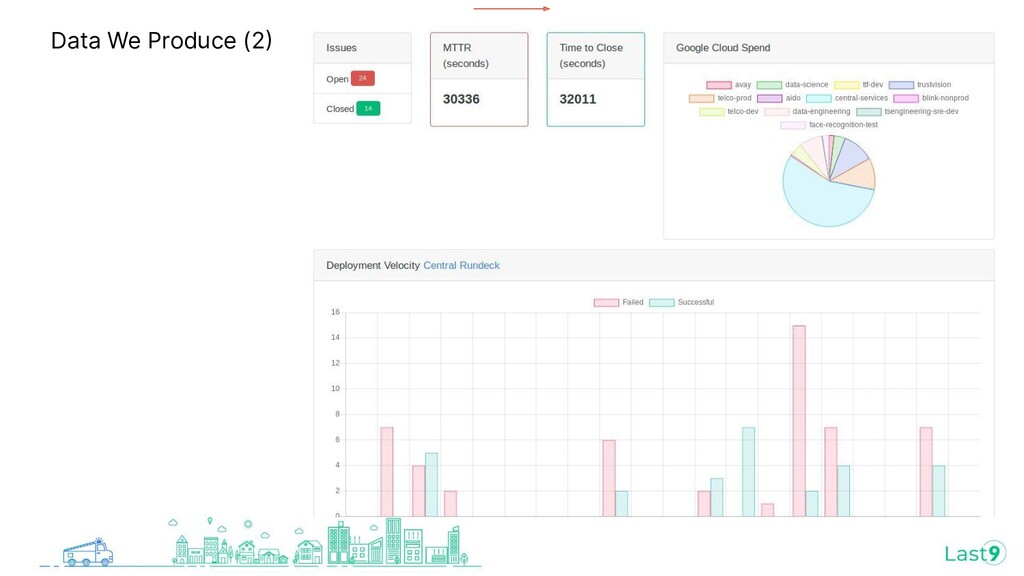{kind=link}
{kind=link}
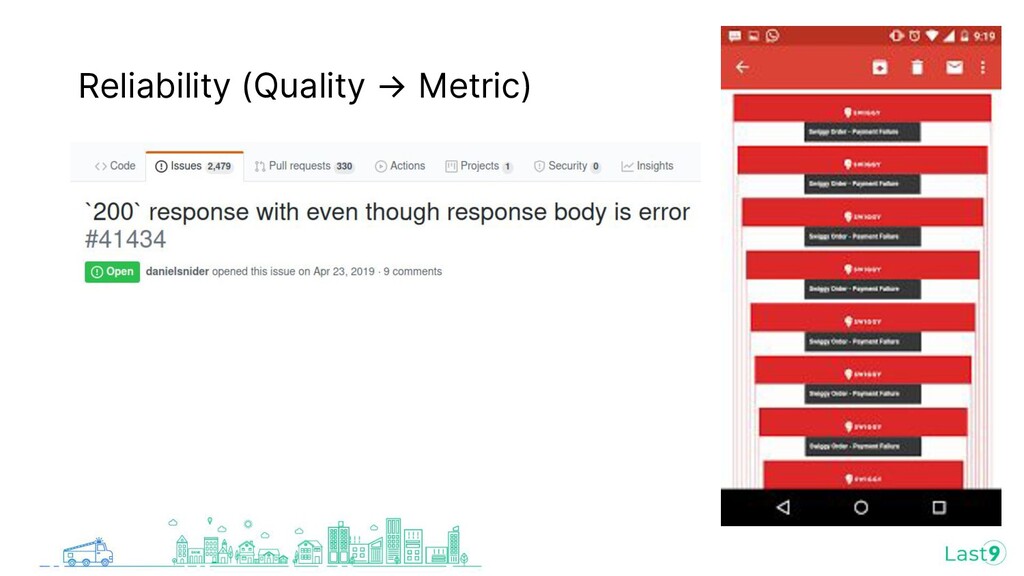{kind=link}
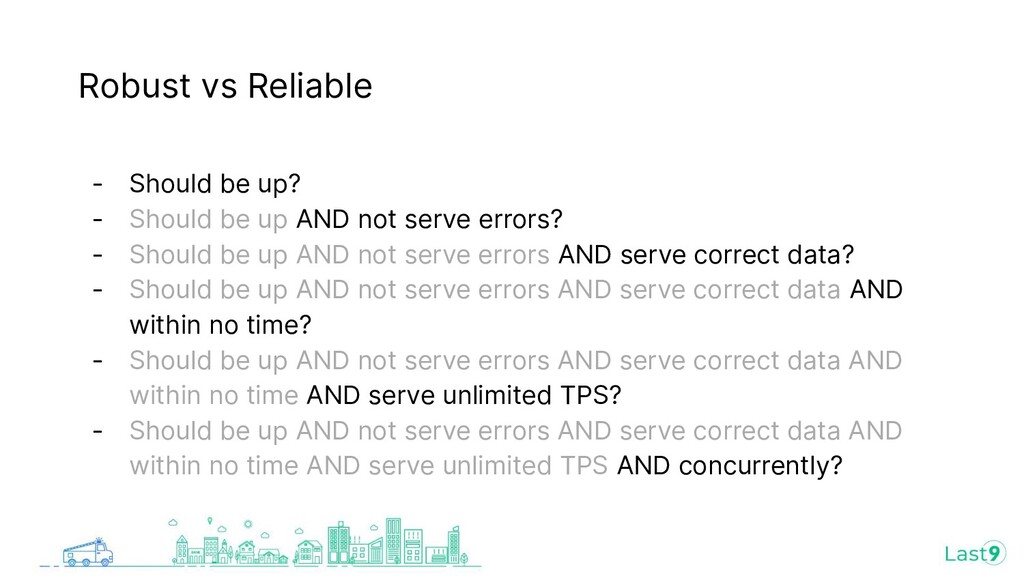{kind=link}
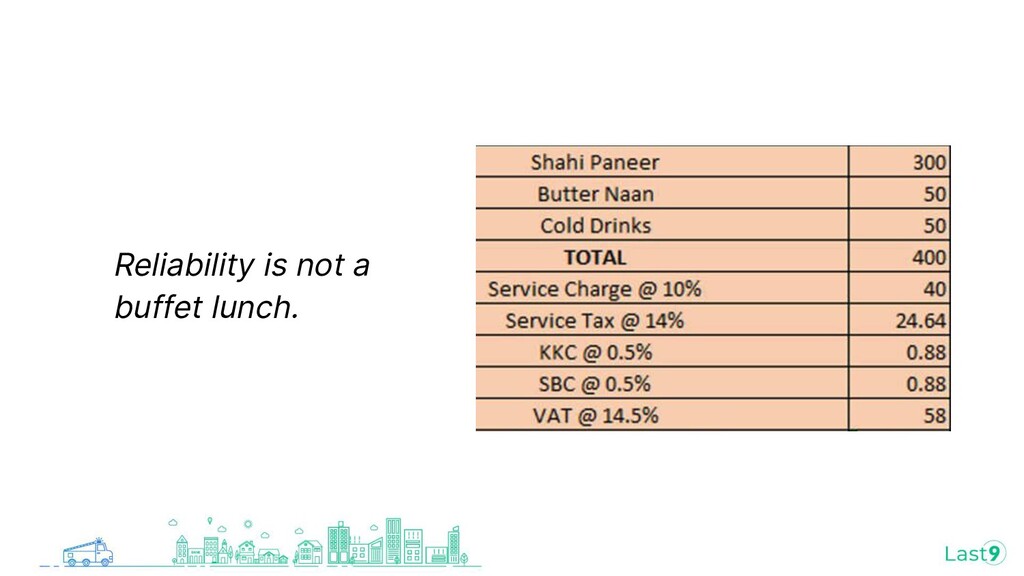{kind=link}
{kind=link}
{kind=link}
{kind=link}
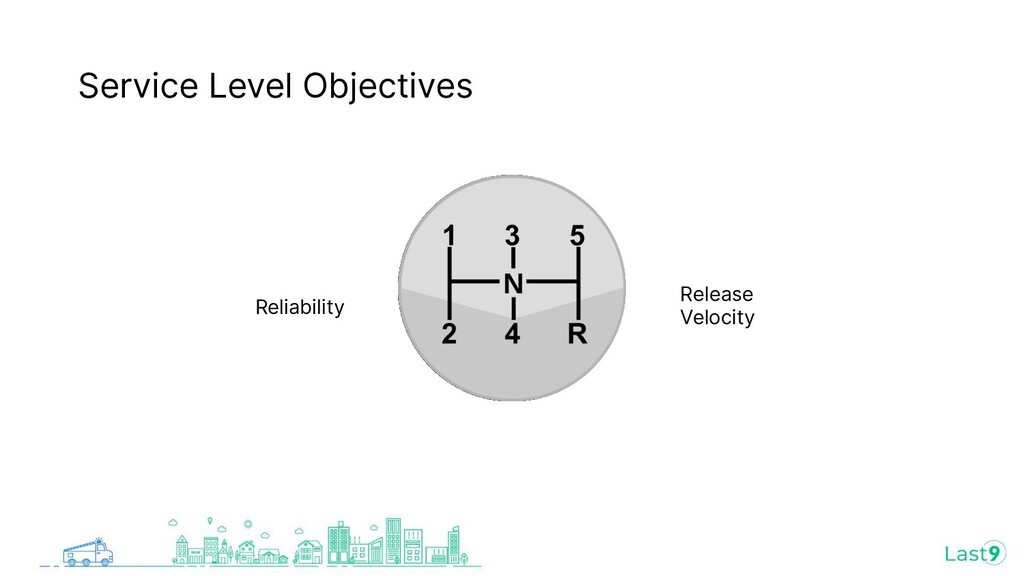{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
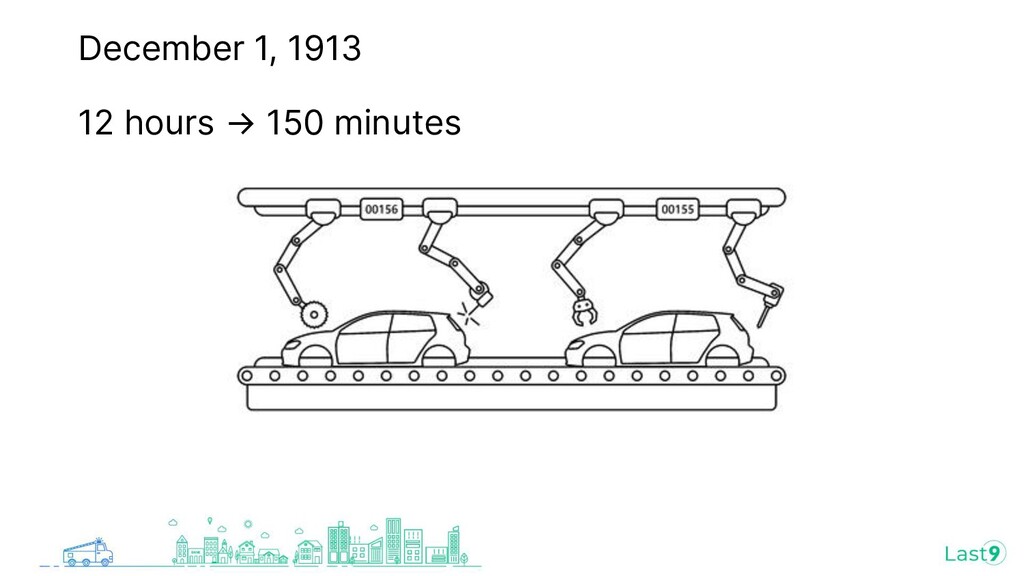{kind=link}
{kind=link}
{kind=link}
{kind=link}
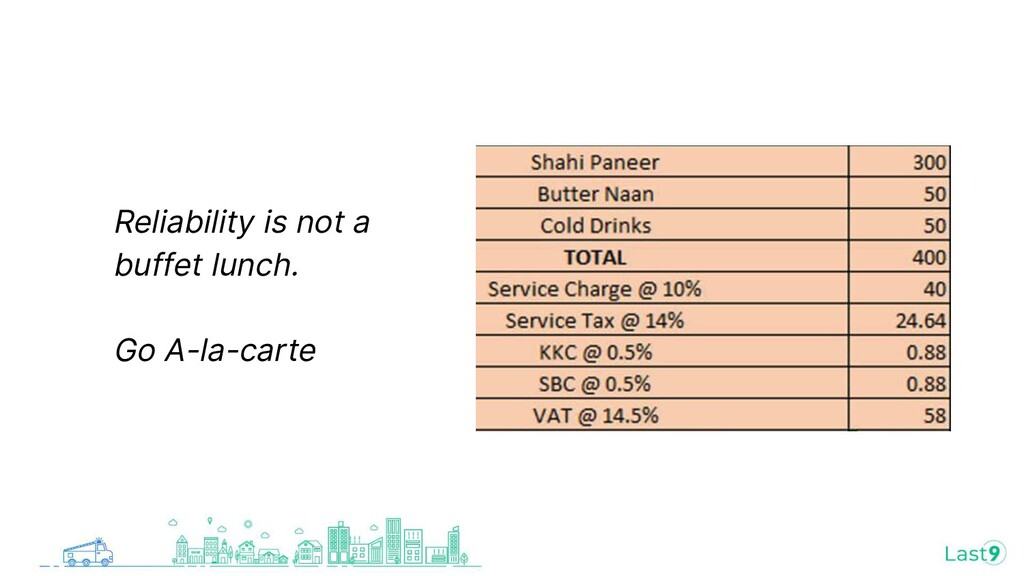{kind=link}
{kind=link}
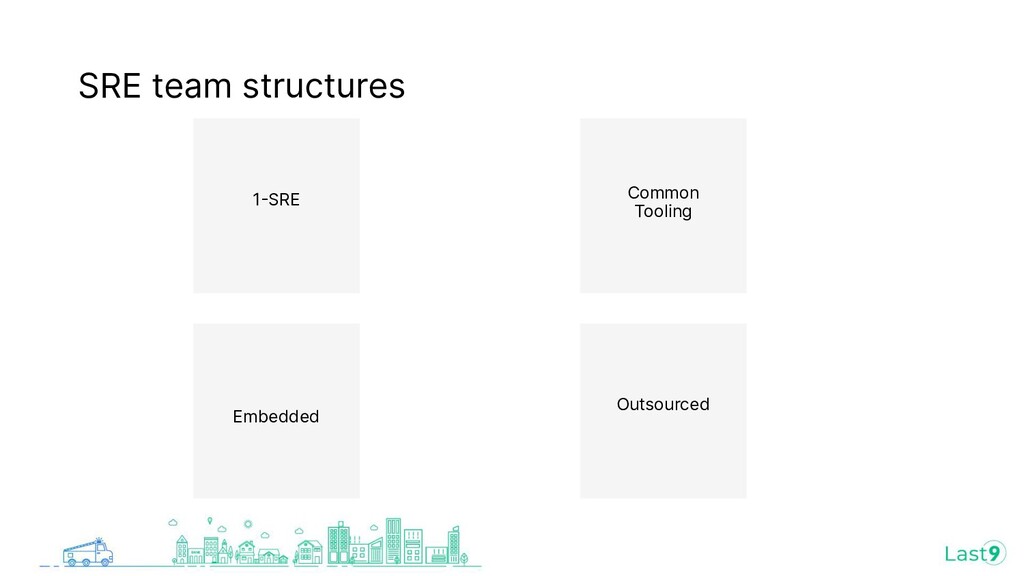{kind=link}
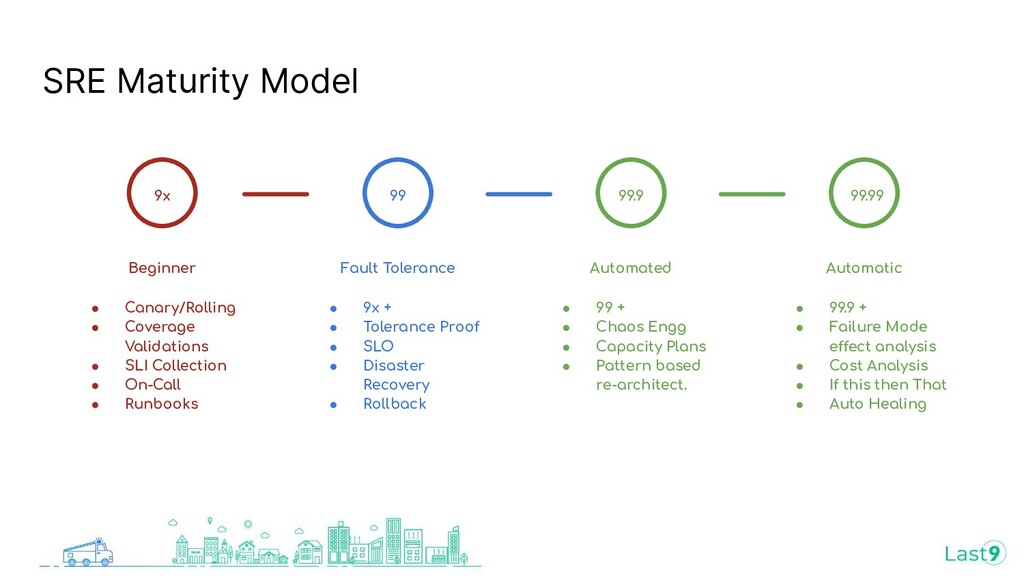{kind=link}
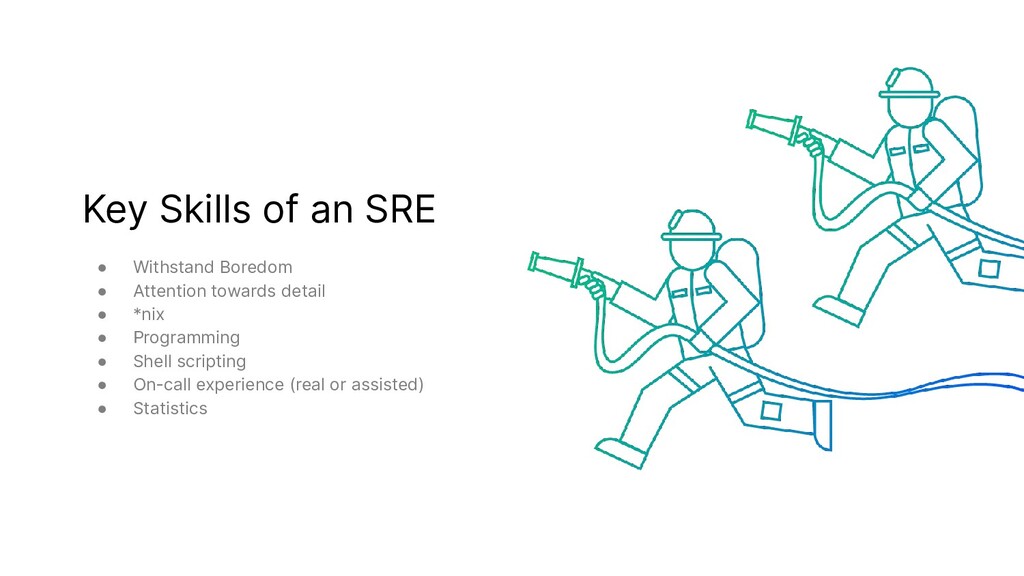{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you [email protected] @realmeson10 last9.io](https://files.speakerdeck.com/presentations/e297b48b89d843438bf84f8bd3879efe/slide_43.jpg){kind=link}