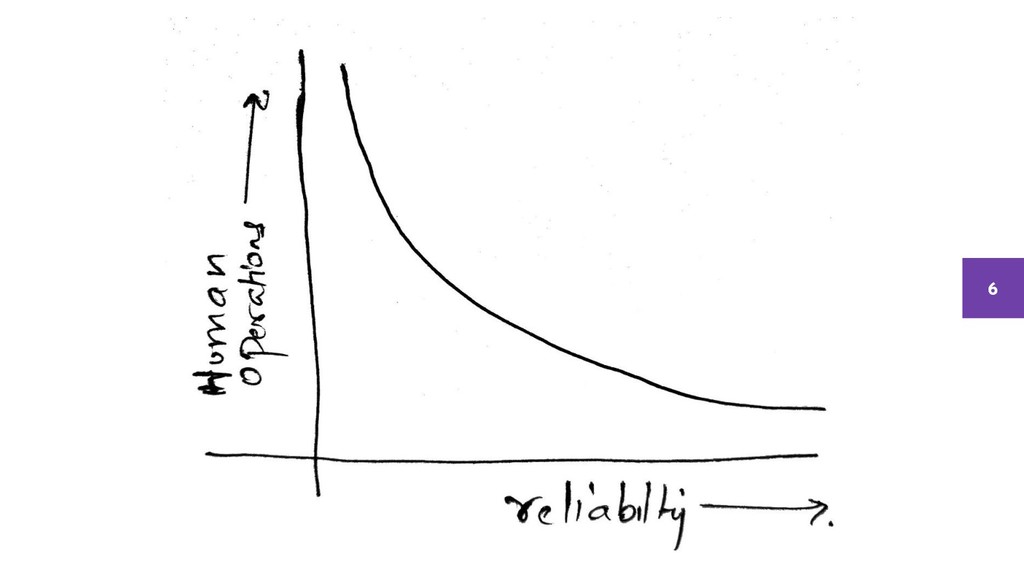
Every product either dies a hero or lives long enough to hit Reliability issues.
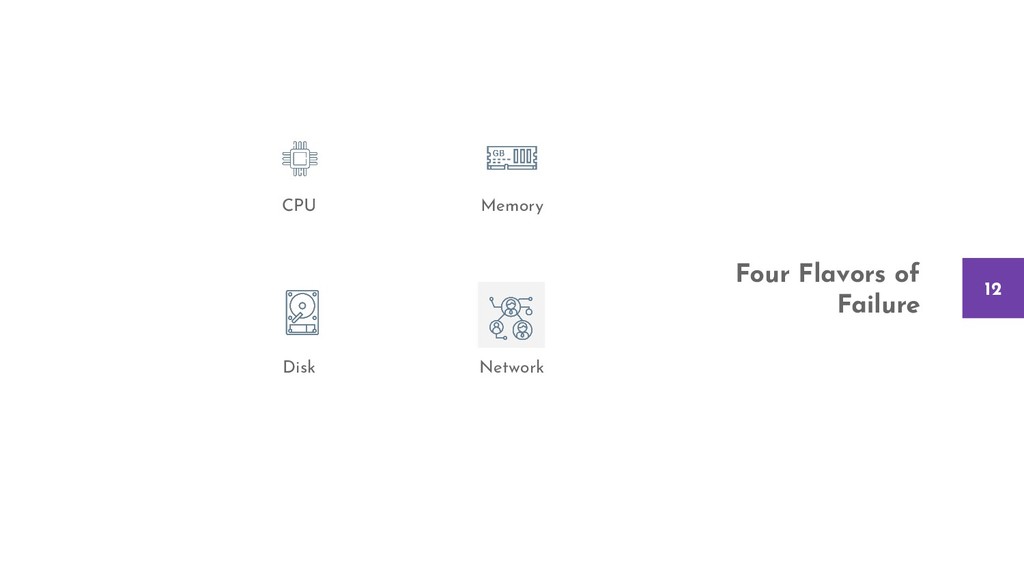
Whether it’s your code or a service that you connect to, there will be a disk that will fail, a network that will experience partition, a CPU that will throttle, or a Memory that will fill up.
While you go about fixing this, What is the cost, both in terms of effort and business lost, of failure and how much does each nine of reliability cost?
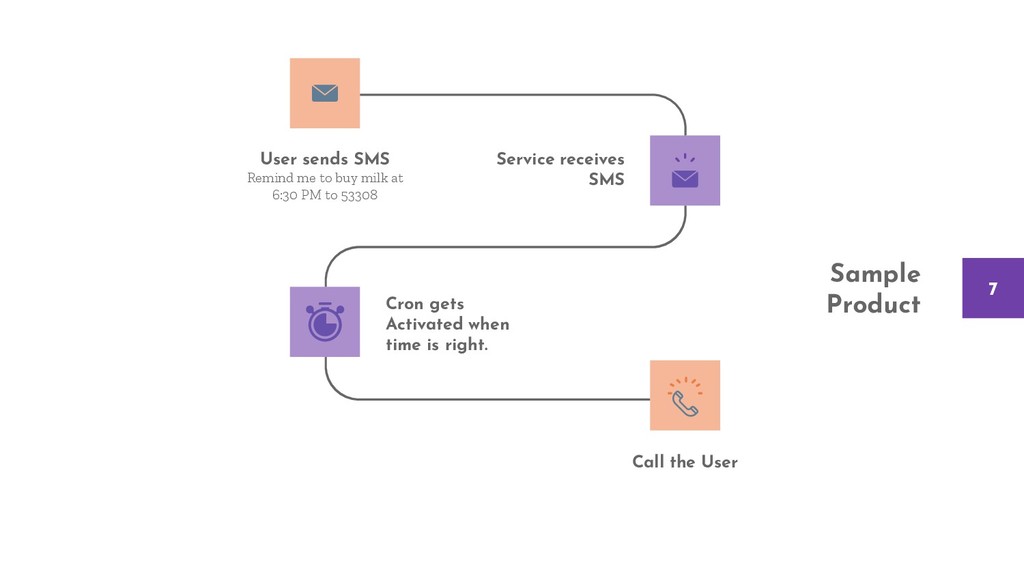
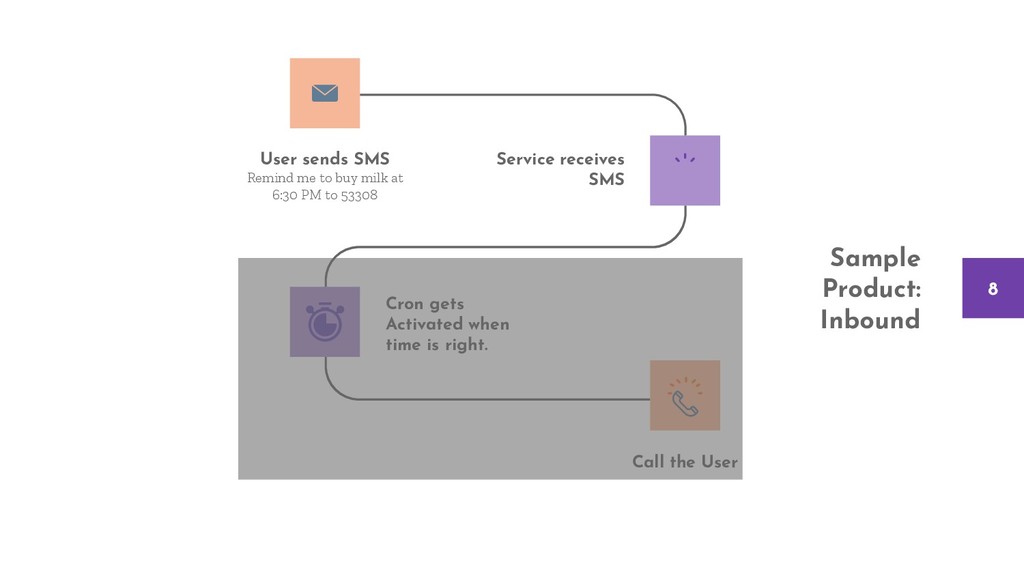
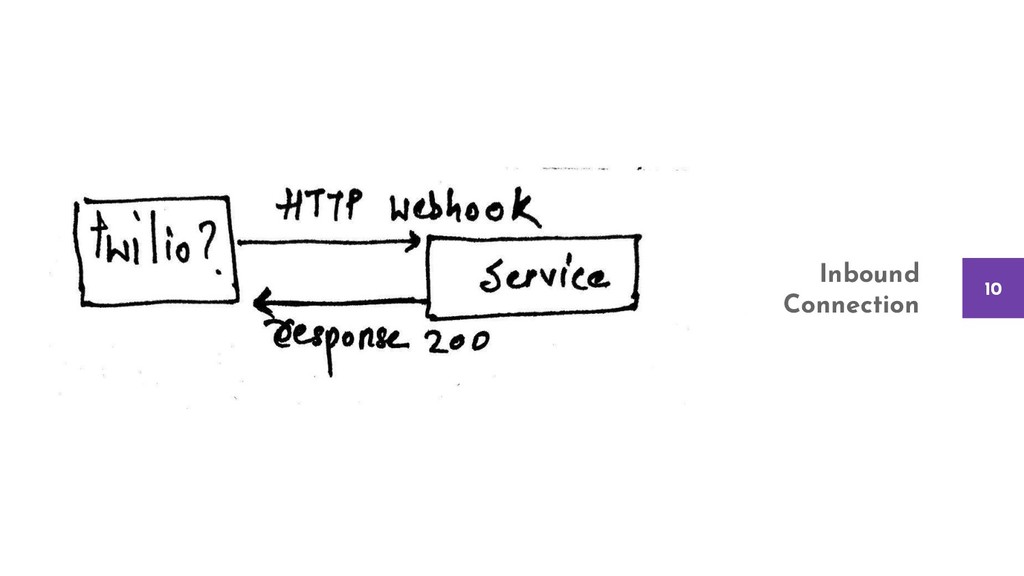
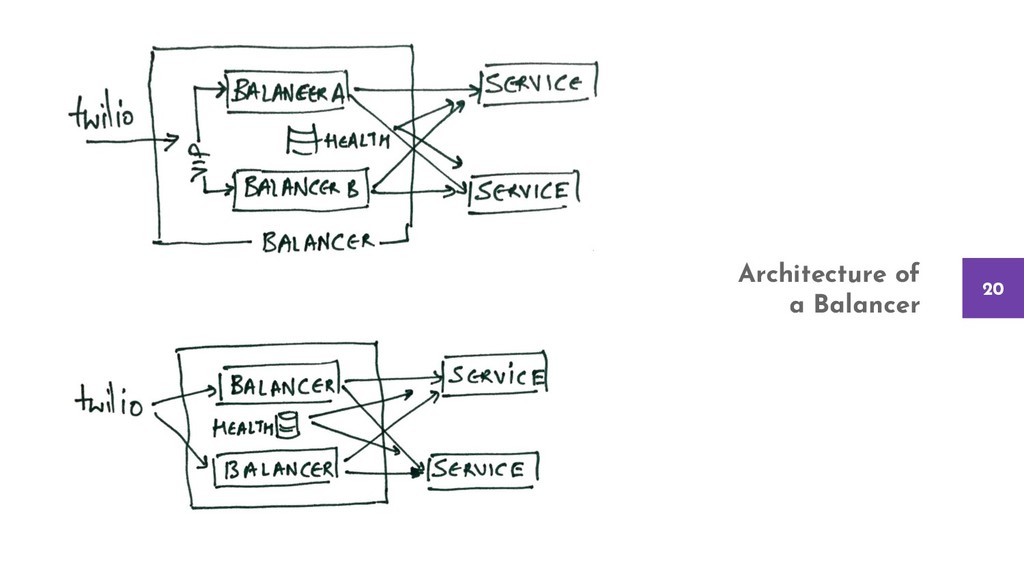
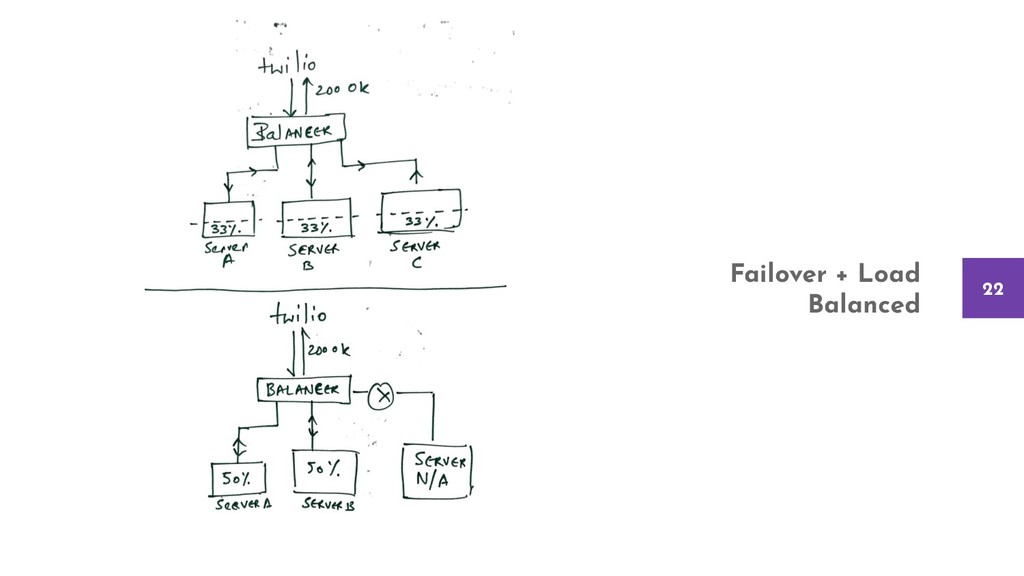
The talk considers a sample and straightforward product and evaluates the depths of each failure point. We take one fault at a time and introduce incremental changes to the architecture, the product, and the support structure like monitoring and logging to detect and overcome those failures.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
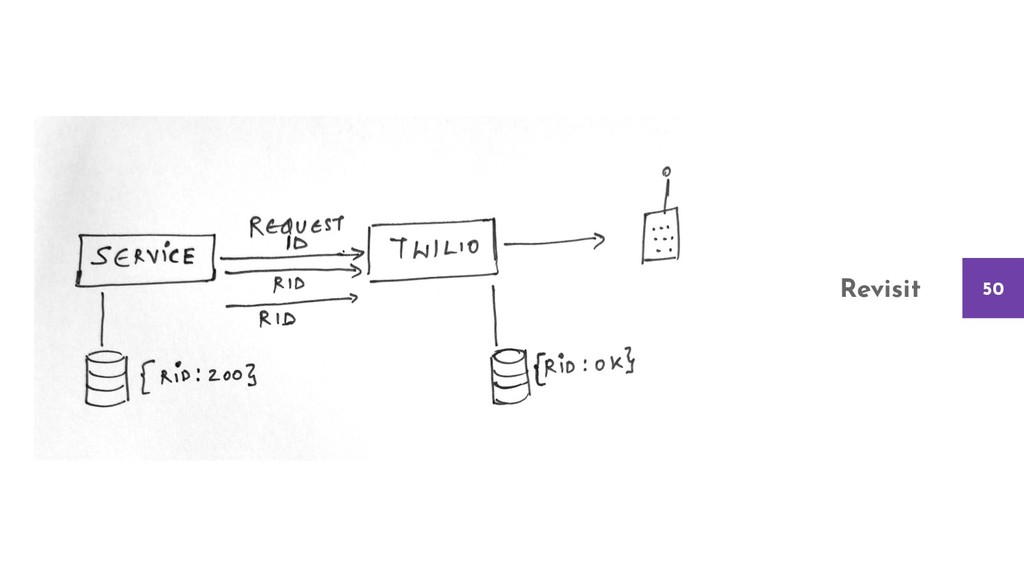{kind=link}
{kind=link}
{kind=link}
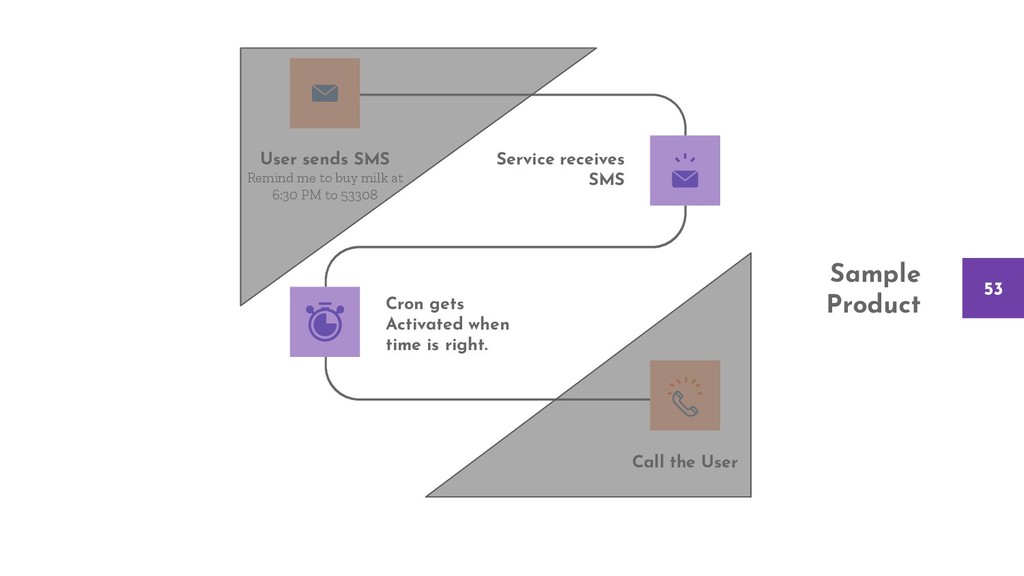{kind=link}
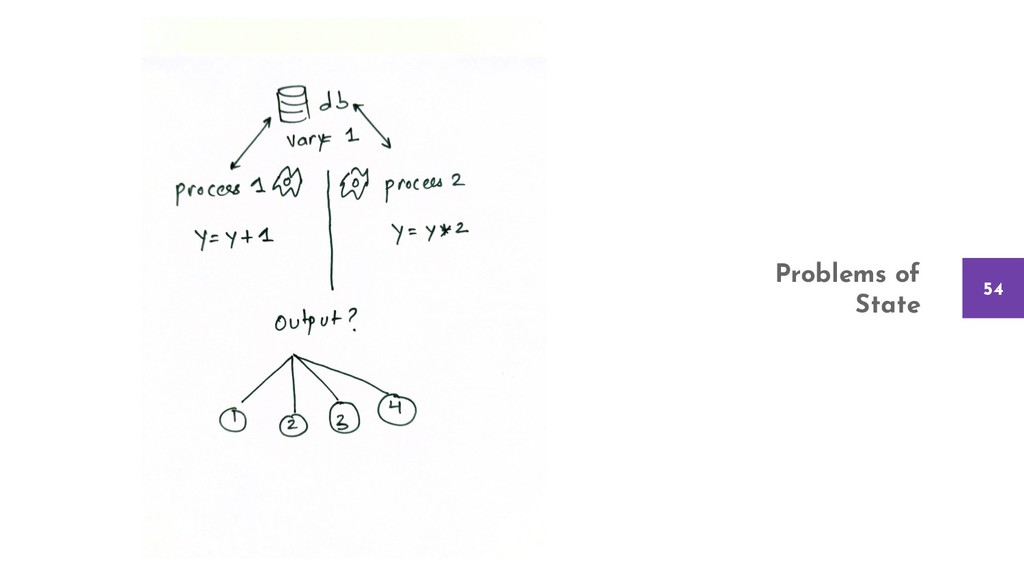{kind=link}
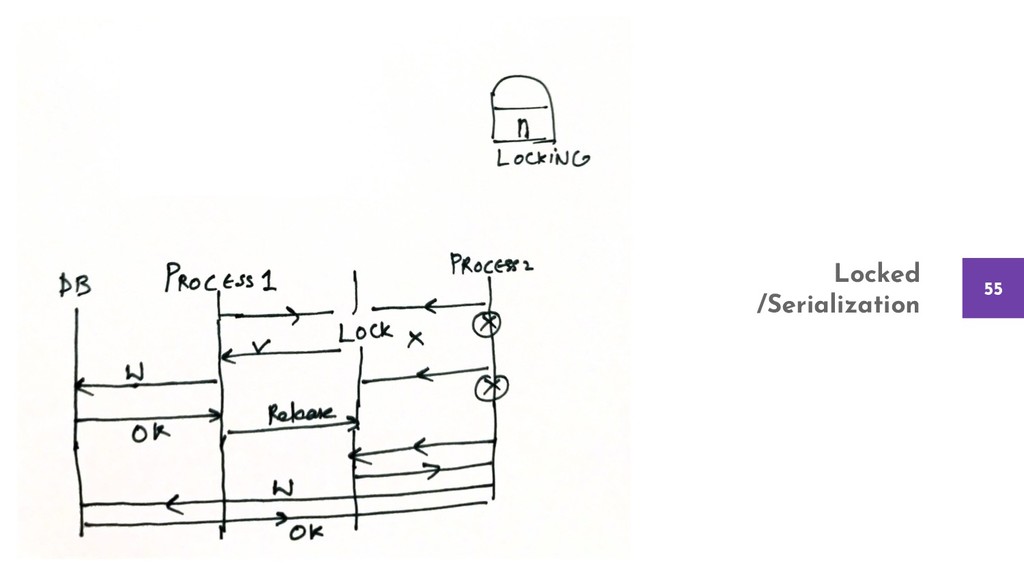{kind=link}
{kind=link}
{kind=link}
{kind=link}
![CAP Theorem [Sab topi pehna rahe] 59](https://files.speakerdeck.com/presentations/542603e9721d4264890ffa40ecb7da7c/slide_58.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Does anyone have any questions? [email protected] Thanks 68](https://files.speakerdeck.com/presentations/542603e9721d4264890ffa40ecb7da7c/slide_67.jpg){kind=link}