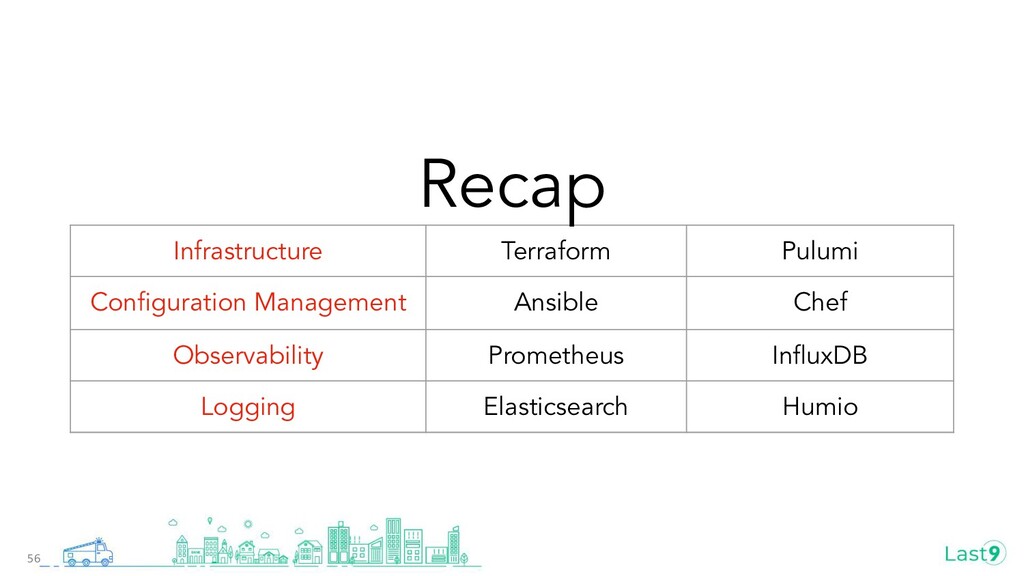
Pulumi or Terraform?
How much and what all to automate?
Automated vs automatic?
Ansible or K8s?
Serverless or needless?
Choices, choices, choices - and very expensive these choices are.
In session 2, speaker Piyush Verma, co-founder of Last9 Inc will lay out facts (from popular tech fiction) + trade-offs associated with these choices.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Would this? meson10@meson10-xps-9370$: LAST9_ORG=last9 make launch [2020/06/20 11:27:40:2869] N: liblast9](https://files.speakerdeck.com/presentations/2820e21b010c417b9679405fffecf256/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}