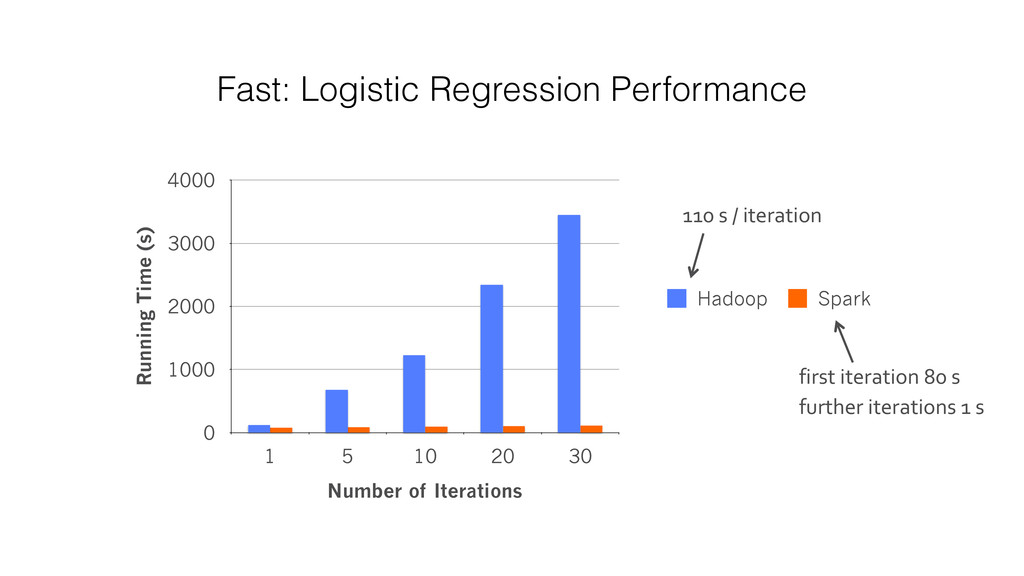
APIs in Java, Scala, Python • Interactive shell Fast to Run • General execution graphs • In-memory storage 2-5 × less code Up to 10 × faster on disk, and 100 × in memory https://amplab.cs.berkeley.edu/benchmark/
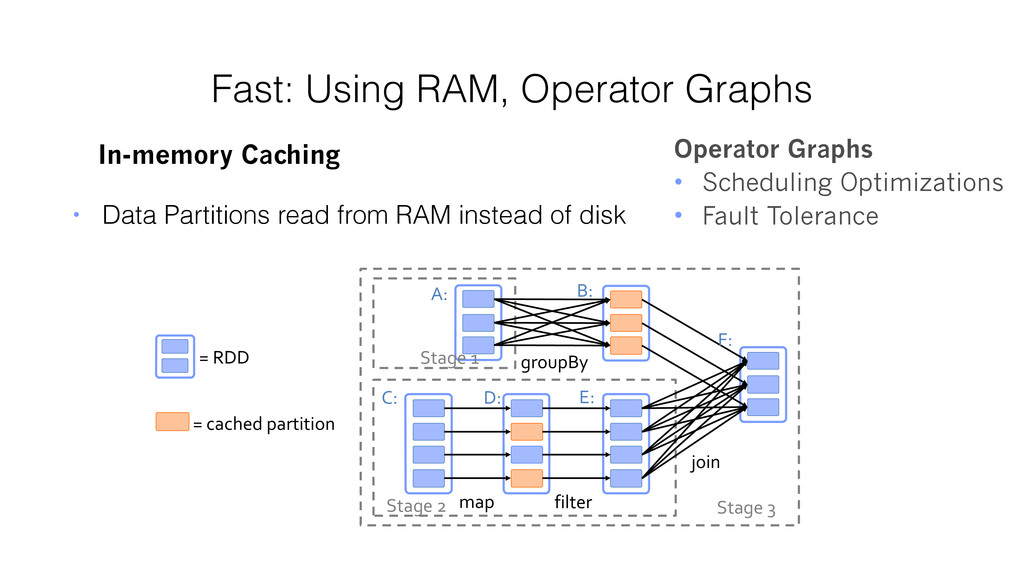
spread across a cluster, stored in RAM or on Disk • Built through parallel transformations • Automatically rebuilt on failure Operations • Transformations (e.g. map, filter, groupBy) • Actions (e.g. count, collect, save) Write programs in terms of transformations on distributed datasets
existing Hadoop data (HDFS, HBase, S3, etc.) • Use the same data formats • Adheres to data locality for efficient processing Deployment Models • “Standalone” deployment • YARN-based deployment • Mesos-based deployment • Deploy on existing Hadoop cluster or side-by-side
the Hive ecosystem: o Support for writing queries in HQL o Catalog for that interfaces with the Hive MetaStore o Tablescan operator that uses Hive SerDes o Wrappers for Hive UDFs, UDAFs, UDTFs
• Columnar storage avoids reading unneeded data. • Currently only supports flat structures (nested data on short-term roadmap). • RDDs can be written to parquet files, preserving the schema. http://parquet.io/
e.action, u.age, u.latitude, u.logitude FROM Users u JOIN Events e ON u.userId = e.userId""")// Since `sql` returns an RDD, the results of can be easily used in MLlib val trainingData = trainingDataTable.map { row => val features = Array[Double](row(1), row(2), row(3)) LabeledPoint(row(0), features) } val model = new LogisticRegressionWithSGD().run(trainingData)
memory columnar representation • hardened spark execution engine Adds • RDD-aware optimizer/ query planner • execution engine • language interfaces. Catalyst/SparkSQL is a nearly from scratch rewrite that leverages the best parts of Shark
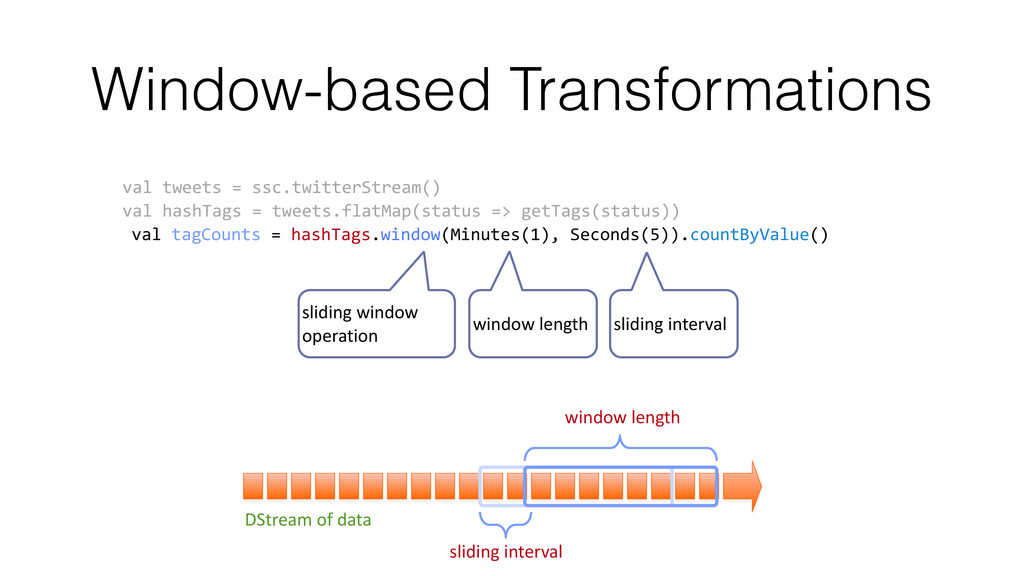
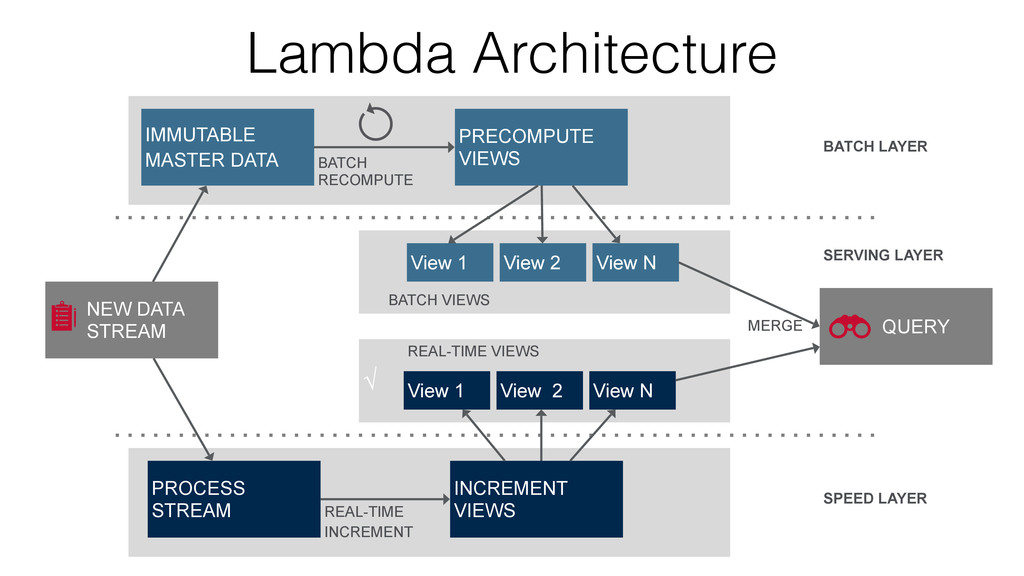
very small, deterministic batch jobs Spark Spark Streaming batches of X seconds live data stream processed results • Chop up the live stream into batches of ½ second or more, leverage RDDs for micro-batch processing • Use the same familiar Spark APIs to process streams • Combine your batch and online processing in a single system • Guarantee exactly-once semantics
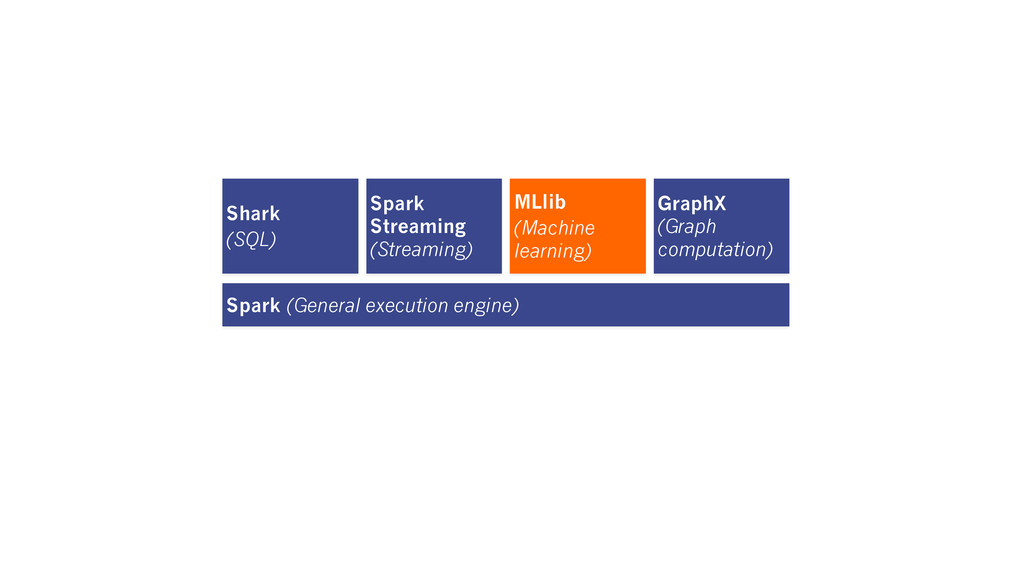
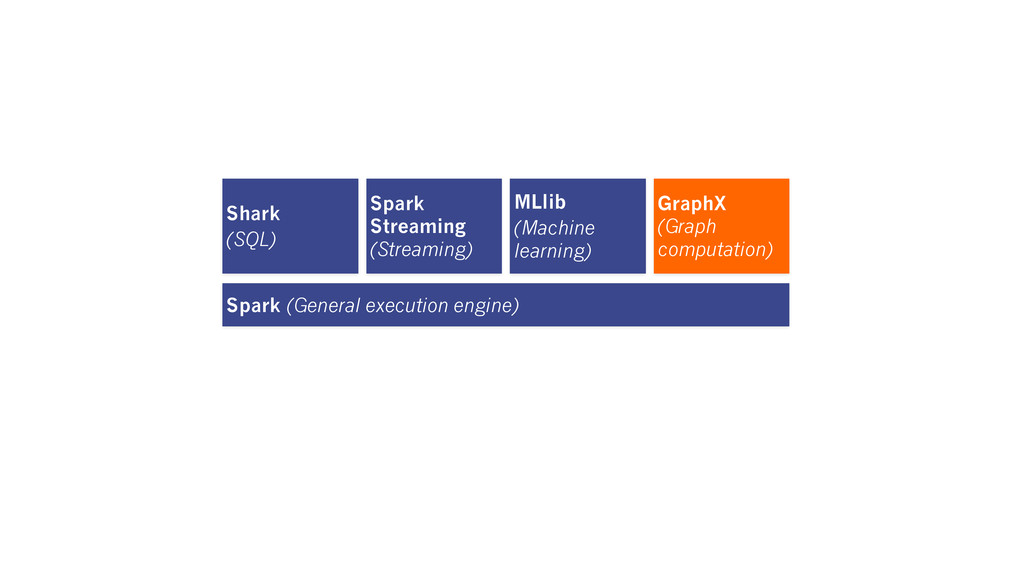
analytics pipeline New API Blurs the distinction between Tables and Graphs New System Combines Data-Parallel Graph-Parallel Systems The GraphX Unified Approach
execution to explore large distributed datasets • Use Spark’s APIs to explore any kind of data (structured, unstructured, semi-structured, etc.) and combine programming models • Execute arbitrary code using a fully-functional interactive programming environment • Connect external tools via SQL Drivers
frequently accessed datasets • Develop programs that are easy to reason using a fully-capable functional programming style • Refine algorithms using the interactive REPL • Use carefully-curated algorithms out-of-the-box with MLlib
window-based aggregations • Combine offline models with streaming data for online clustering and classification within the dashboard • Use Spark’s core APIs and/or Spark SQL to give users large-scale, low-latency drill-down capabilities in exploring dashboard data
I/O on large datasets, and in-memory processing for aggregations, shuffles, and more • Use Spark SQL to perform ETL using a familiar SQL interface • Easily port PIG scripts to Spark’s API • Run existing HIVE queries directly on Spark SQL or Shark
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![MLlib – Machine Learning library Logis]c*Regression,*Linear*SVM*(+L1,*L2),*Decision* Trees,*Naive*Bayes" Linear*Regression*(+Lasso,*Ridge)* Alterna]ng*Least*Squares* KZMeans,*SVD*](https://files.speakerdeck.com/presentations/66bf3fe0b90401310db622637f6c77d3/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Q & A @mhausenblas maprtech [email protected] MapR maprtech mapr-technologies](https://files.speakerdeck.com/presentations/66bf3fe0b90401310db622637f6c77d3/slide_42.jpg){kind=link}