with changing data or with unstructured data We require sub-second responses to queries 4 Source: Mike Loukides, VP Content Strategy, O’Reilly Media Relational databases are not always sufficient for these uses
applications on top of relational databases -- there are patterns. With NoSQL today, we have no cookie cutters. We don't have any blueprints.” --Ravi Krishnappa, NetApp solutions architect 5 Source: TechTarget, 2015
with entities and relationships, if you can De-normalize and duplicate for read performance But don’t de-normalize if you don’t need to Leverage wide rows for ordering, grouping, and filtering But don’t go too wide Schema Design Best Practices Source: http://www.ebaytechblog.com/2012/07/16/cassandra-data-modeling-best-practices-part-1/ But But But ? ? ? 8
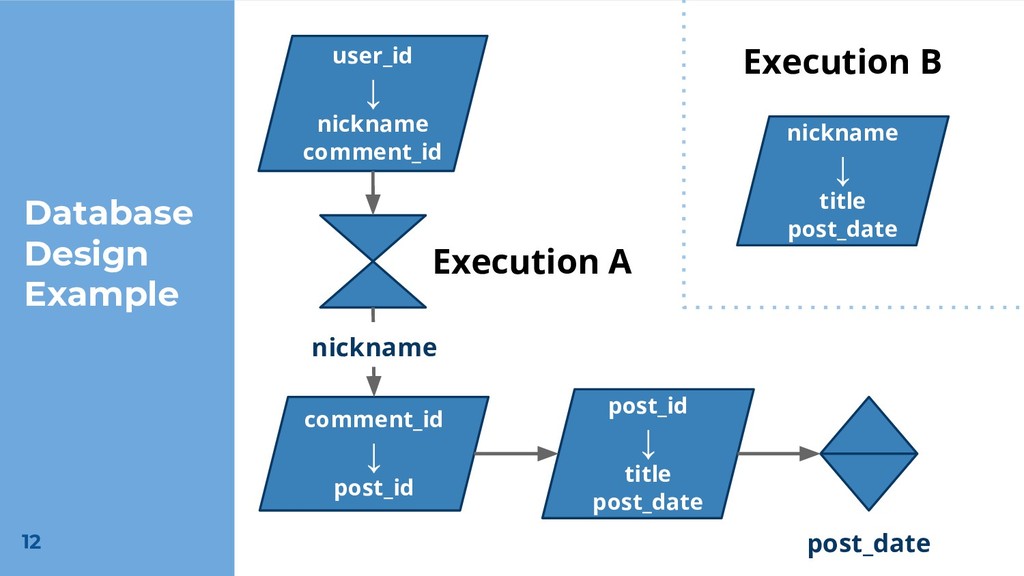
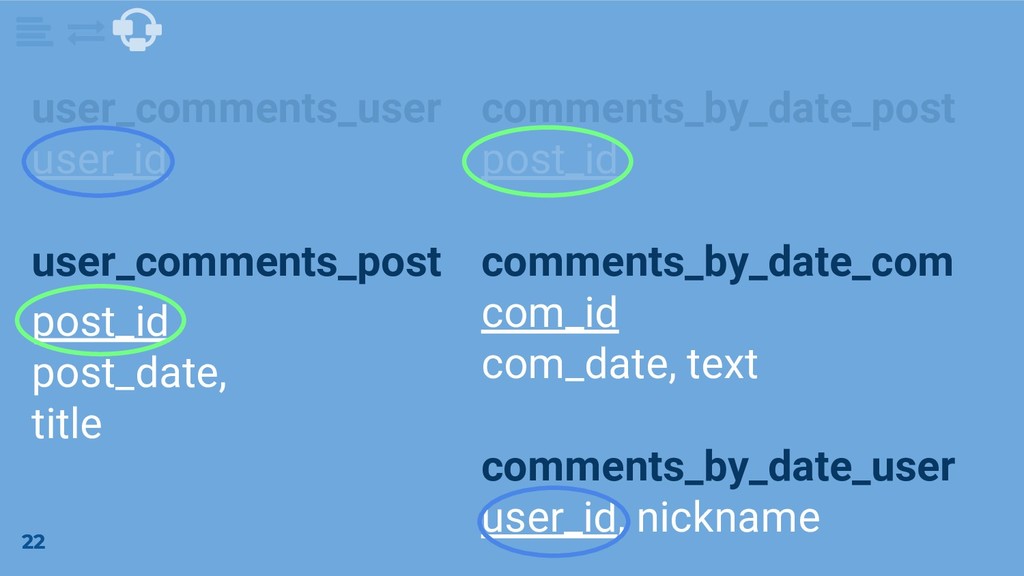
JOIN comments c ON u.user_id = c.user_id JOIN posts p ON p.post_id = c.post_id ORDER BY p.post_date Query Find information on all posts a user has commented on in order by post date
░░░░░░░░░: "░░░░░░░░░░", ░░░░░░: ░, …} comments_by_date {░░░░░░░: ░, ░░░░░░░░: "░░░░░░░░░░", ░░░░░░: ░, ░░░░░░░: ░, …} {░░░░░░░: ░, ░░░░░░░░: "░░░░░░░░░░", ░░░░░░: ░, ░░░░░░░: ░, …} We want to go from raw data to a logical model Comment User Post 19 [MS, ER ‘18] (to appear)
followed by actions that force evaluation of all transformations ▸ Each step produces a resilient distributed dataset (RDD) ▸ Intermediate results can be cached on memory or disk, optionally serialized 25
multiple times. Caching all of the generated RDDs is not a good strategy… Caching is very useful for applications that re-use an RDD multiple times. Caching all of the generated RDDs is not a good strategy… …deciding which ones to cache may be challenging. Spark Caching Best Practices Source: https://unraveldata.com/to-cache-or-not-to-cache/ 26
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}