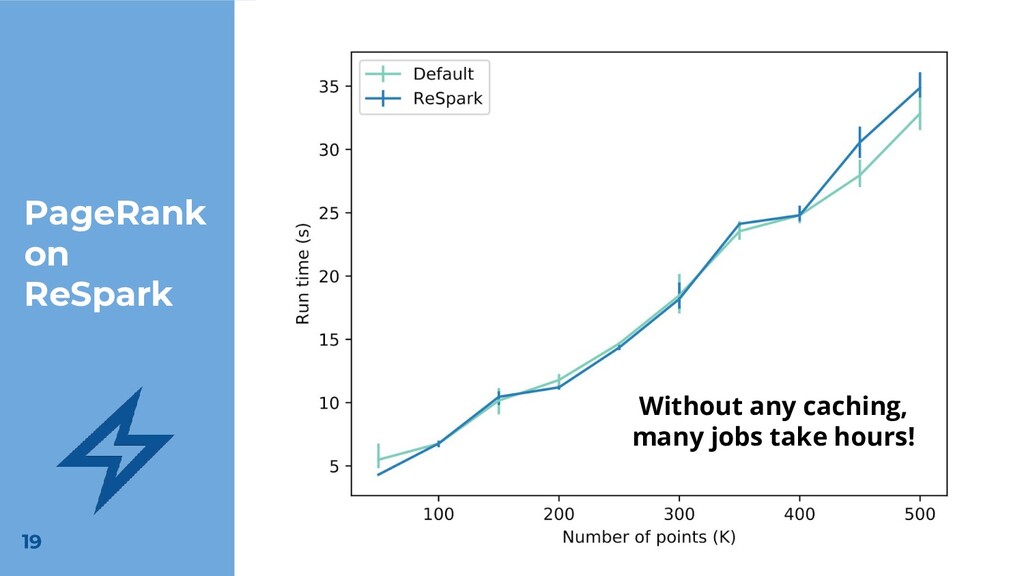
Apache Spark is a distributed computing framework used for big data processing. A common pattern in many Spark applications is to iteratively evolve a dataset until reaching some user-specified convergence condition. Unfortunately, some aspects of Spark’s execution model make it difficult for developers who are not familiar with the implementation-level details of Spark to write efficient iterative programs.Since results are constructed iteratively and results from previous iterations may be used multiple times, effective use of caching is necessary to avoid recomputing intermediate results. Currently, developers of Spark applications must manually indicate which intermediate results should be cached. We present a method for using metadata already captured by Spark to automate caching decisions for many Spark programs. We show how this allows Spark applications to benefit from caching without the need for manual caching annotations.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}