2012 Code pared down and entered the ASF incubator 2015 Graduated from incubator 2016 I joined the Calcite project as a committer 2017 Joined the PMC and was voted as chair 2018 Paper presented at SIGMOD
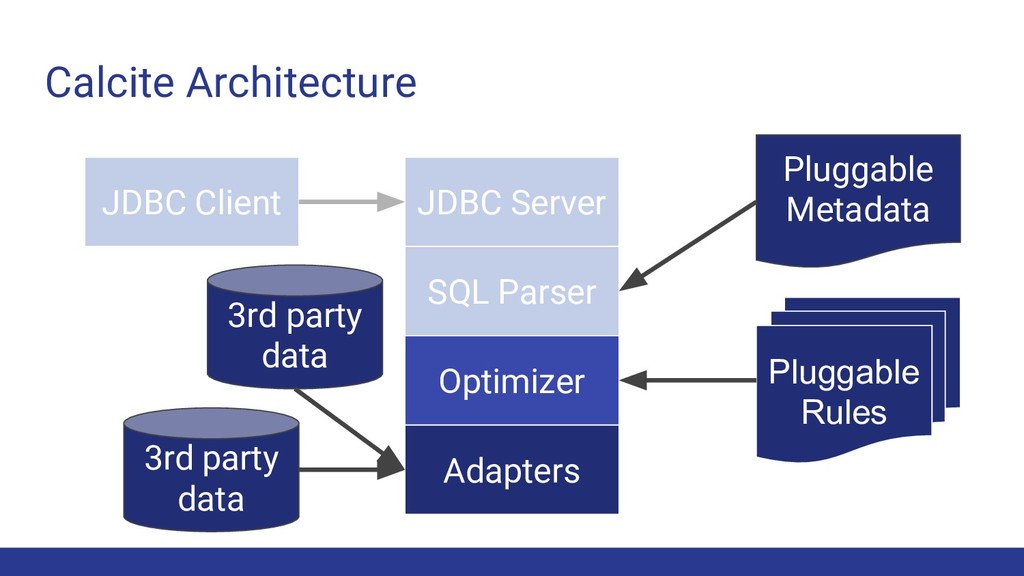
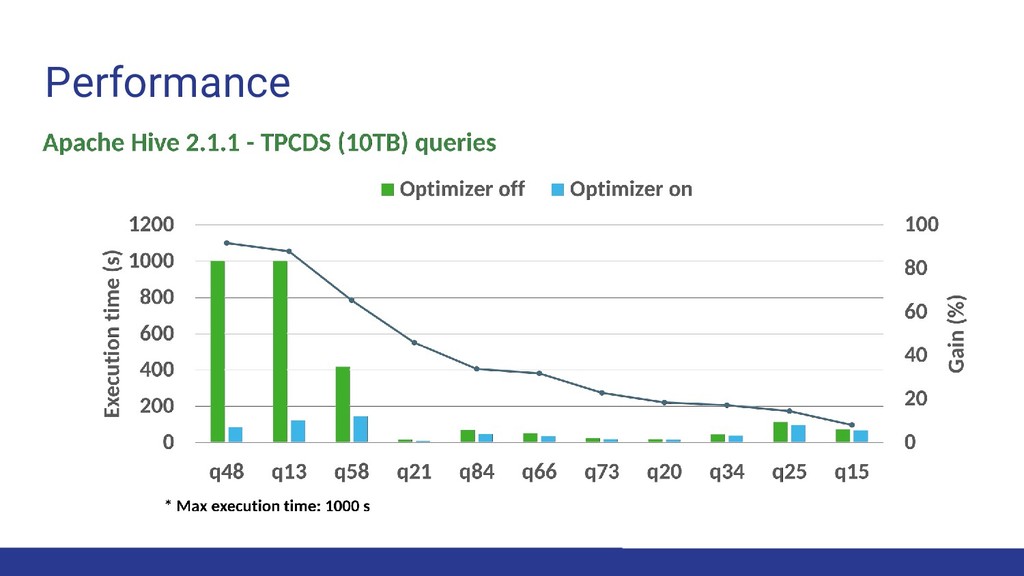
Calcite contains 100+ rewrite rules • Currently working on validating these using Cosette • Optimization is cost-based • “Calling convention” allows optimization across backends
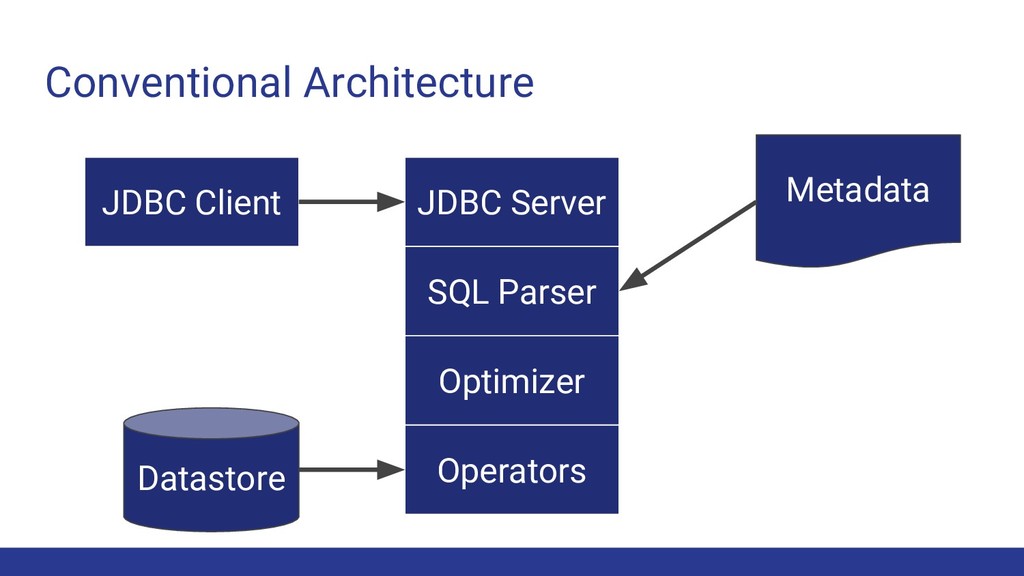
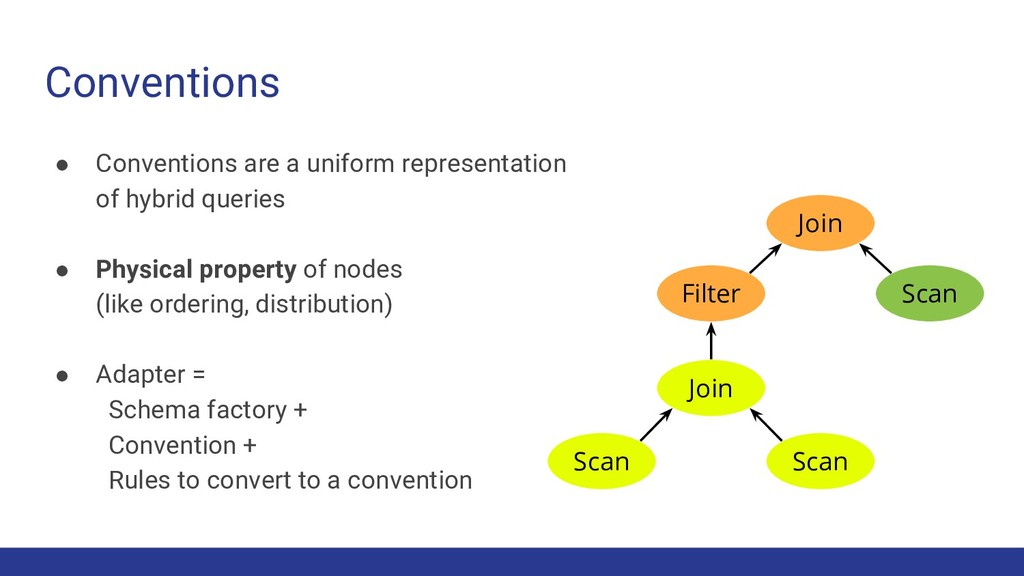
operators are functions (e.g. join) ◦ Physical operators implement logical operators ◦ Physical properties are attributes of the data (e.g. sorting, partitioning) • Start with logical expressions and physical properties • Optimization produces a plan with only physical operators
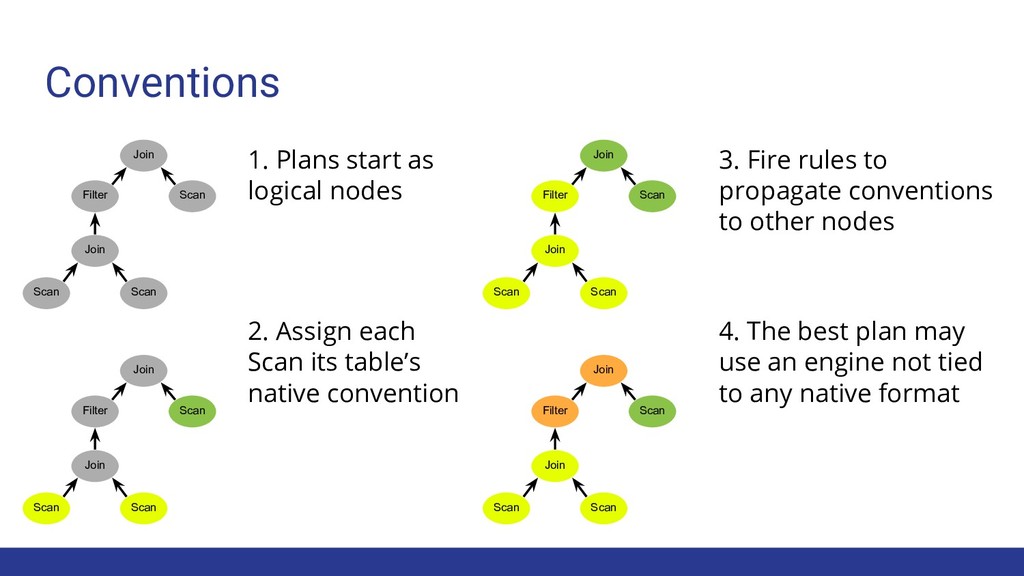
to propagate conventions to other nodes 2. Assign each Scan its table’s native convention 4. The best plan may use an engine not tied to any native format Join Filter Scan Scan Scan Join Join Filter Scan Scan Scan Join Scan Scan Scan Join Filter Join Join Filter Scan Scan Scan Join
uuid, title text, artist text, PRIMARY KEY (id, song_order)); SELECT title FROM playlists WHERE id=62c36092-82a1-3a00-93d1-46196ee77204 AND artist='Relient K' ORDER BY song_order;
Query example Scan Filter Filter Sort Project Project • Push down the project of necessary fields • This is the query sent to Cassandra • Only the filter and project are done by Calcite
and maps) • Add UNNEST operator to relational algebra • New rules can be added to optimize these queries name age pets Sally 29 [{name: Fido, type: Dog}, {name: Jack, type: Cat}] name age pets Sally 29 {name: Fido, type: Dog} Sally 29 {name: Jack, type: Cat}
loc : [ -71.03434799999999, 42.081571 ], pop : 59498, state : MA } { _id : 06902, city : STAMFORD, loc : [ -73.53742800000001, 41.052552 ], pop : 54605, state : CT } • Use one column with the whole document • Unnest attributes as needed • This is very messy, but we have no schema to work with
-71.034348 42.081571 59498 MA 06902 STAMFORD -73.537428 41.052552 54605 CT • Views to the rescue! • Users of adapters can define structured views over semistructured data (or do this lazily! See Apache Drill)
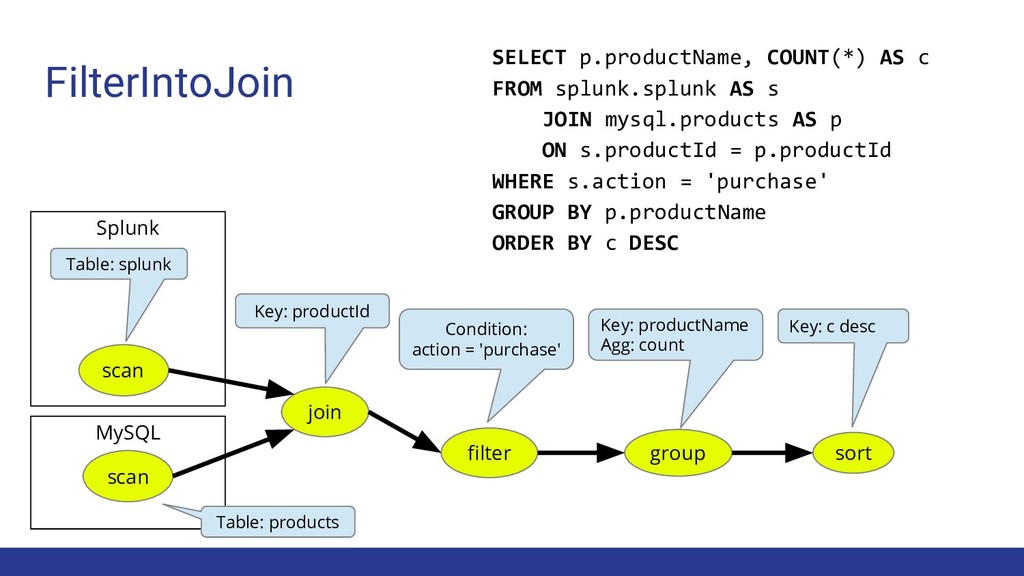
filter Condition: action = 'purchase' sort Key: c desc scan scan Table: products Table: splunk SELECT p.productName, COUNT(*) AS c FROM splunk.splunk AS s JOIN mysql.products AS p ON s.productId = p.productId WHERE s.action = 'purchase' GROUP BY p.productName ORDER BY c DESC FilterIntoJoin
desc FilterIntoJoin join Key: productId filter Condition: action = 'purchase' scan scan Table: splunk Table: products SELECT p.productName, COUNT(*) AS c FROM splunk.splunk AS s JOIN mysql.products AS p ON s.productId = p.productId WHERE s.action = 'purchase' GROUP BY p.productName ORDER BY c DESC
sliding, hopping) • Streaming queries can be combined with tables • Streaming queries can be optimized using the same rules along with new rules specifically for streaming queries
and tables • Calcite is a reference implementation for streaming SQL (still being standardized) SELECT STREAM * FROM Orders AS o WHERE units > (SELECT AVG(units) FROM Orders AS h WHERE h.productId = o.productId AND h.rowtime > o.rowtime - INTERVAL ‘1’ YEAR)
FROM Orders GROUP BY FLOOR(rowtime TO HOUR) SELECT STREAM … FROM Orders GROUP BY TUMBLE(rowtime, INTERVAL ‘1’ HOUR) SELECT STREAM … FROM Orders GROUP BY HOP(rowtime, INTERVAL ‘1’ HOUR, INTERVAL ‘2’ HOUR) SELECT STREAM … FROM Orders GROUP BY SESSION(rowtime, INTERVAL ‘1’ HOUR)
a logical model over a denormalized data store • Denormalized tables are views over (non-materialized) logical tables • Queries can be rewritten from logical tables to the most cost-efficient choice of materialized views
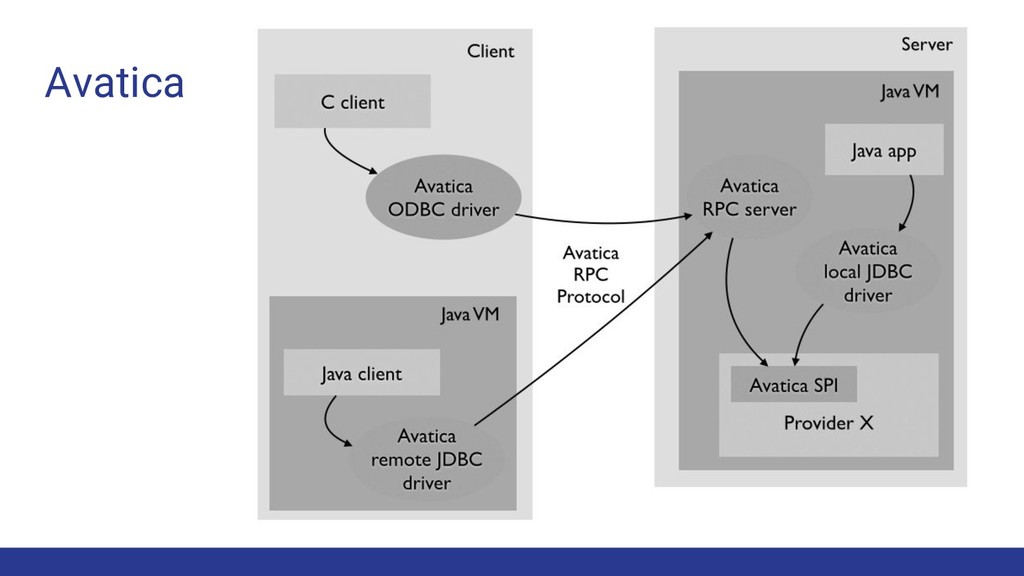
• Adding a relational front end to an existing system • Prototyping new query processing algorithms • Integrating data from multiple backends • Allowing RDBMS tools to work with non-relational DBs
file a new one and start coding! • Mailing list is generally very active • New committers and PMC members regularly added • Many opportunities for projects at various scales
Incorporating state-of-the-art in DB research • Access control across multiple systems • Adapters for new classes of database (eg. array DBs) • Implement missing SQL features (e.g. set operations) …
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}