Die Idee zu diesem Vortrag ist mir während der Diskussion über mögliche Titel auf Visitenkarten gekommen.
Señor Developer ist nur noch so mittel lustig.
An Senior Consultant muss ich mich tatsächlich immer noch gewöhnen.
Am liebsten wäre mir ja „der Typ, der was mit SQL und Spring“ macht.
--
DailyFratze (das ™ ist keine Marotte, ich habe mir die Wortmarke tatsächlich registrieren lassen) entstand 2005 zur Hochzeit der Blogs und lange vor dem Selfie-Trend.
Ich wollte ein tägliches Fototagebuch inklusive einer Blog- und Kommentarplatform sowie einem „Last.FM“ Ersatz schaffen.
Dabei war mir das Thema Privacy immer recht wichtig: Profile und einzelne Bilder sollen so privat sein können, das wirklich nur „Freunde“ darauf zu greifen können.
Der Upload von Bilder soll vollautomatisch erfolgen, sprich über Exif (Exchangable Image File Format) sollen Bilder automatisch den richtigen Tagen zugeordnet werden.
--
Dinge stehen in der Regel nicht alleine im Raum, daher gibt es natürlich Integrationen mit anderen Diensten. Ab und zu seht ihr mal einen Tweet von mir „Fratze Nummer So-und-soviel-in-Folge hochgeladen“, gegebenenfalls mit einem Anreißer zum Blog: Das ist ein automatisierter Tweet von DailyFratze.
Uploads sind über E-Mail und Dropbox möglich.
Foursquare beziehungsweise Swarm-Checkins werden auch geloggt.
Die Facebook-Integration biete ich nur noch über IFTTT und RSS an.
--
Das ist der Stand nach 13 Jahren Betrieb. Bemerkenswert finde ich die rund 100 Benutzer, von denen rund 30 öffentlich sind.
Ein Teil dieser Benutzer ist überwiegend passiv und wurde von anderen Benutzern für Eltern, Großeltern und Freude eingerichtet, die die Seite und die dazugehörige Android-App nutzen, um ihre Enkelkinder aufwachsen zu sehen.
Ich möchte dazu sagen, dass ich niemals eine aktive Registrierung hatte, sondern neue Benutzer nur nach Einladung angelegt habe.
Alle Daten - bis auf die Binaries der Bilder - sind in einer MySQL-Datenbank gespeichert.
--
Seit 2011 ist die dritte Version auf Basis von Java, Spring und Hibernate in Betrieb.
Ganz kurz hatte ich eine PHP-Version, die ganz primitiv regelmässig in einem definiertem Verzeichnis nach Bildern schaute und diese dann speicherte, bevor ich 2006 David Heinemeier Hansons Buch „Agile Web-Development with Rails“ in die Hände bekam: Für mich war dieses Buch und die Gedankenwelt dahinter zu diesem Zeitpunkt wegweisen.
--
Drei sehr unterschiedliche Technologiestacks mit teilweise drastischen Unterschieden im Programmiermodell und eine Konstante: Das Datenbankmodel!
--
Es gibt diese Dinge, die die meisten Entwickler einfach einmal gemacht haben müssen: Eine Datenbankzugriffschicht schreiben. In der PHP Version habe ich genau das getan.
In Ruby on Rails habe ich natürlich Active Record genutzt, mit allen Konsequenzen. Ohne viel darüber nachzudenken habe ich alles mögliche in die Klassen gepackt und das Gegenteil eines Anemic-Domain-Models geschaffen.
Die Hibernate-Klassen sehen ähnlich aus, wissen aber natürlich ihrerseits nichts über Zugriffslogik. In der aktuellen Version geschieht das tatsächlich ohne Spring-Data-JPA, sondern über handgeschriebene Repositories und Services.
Notiz am Rande: Ich finde die Angabe der Beziehungen („has_many“ und „belongs_to“) immer noch intuitiver als OneToMany und ManyToOne und entsprechende Instanzen beziehungsweise Collections.
--
Mir ist ein konsistentes und stabiles Datenbankmodell extrem wichtig. Auch und gerade Entwickler können sich nicht von ihrer Historie frei sprechen: Mein Hintergrund nach 15 Jahren Produkt- und Projektentwicklung im Energiemarkt lässt sich leicht mit „Baut Dinge auf Datenbanktechnologien“ zusammenfassen.
--
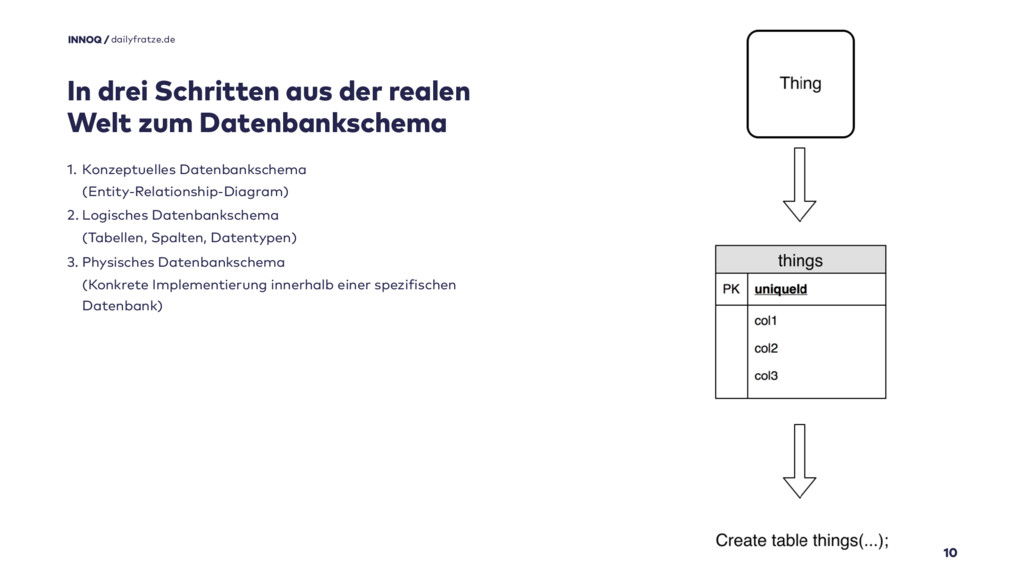
Kern des ganzen war immer eine ganz klassische Datenmodellierung. Dabei spreche ich nicht von dem Versuch, ein kanonisches Datenmodell zu entwickeln, sondern den betrachteten Ausschnitt der Realität zu erfassen.
Die klassische, dreistufige Modellierung von physikalischen Schemata innerhalb relationaler Datenbanken mag nach dem kometenhaften Aufstieg von NoSQL Datenbanken und in Anbetracht verfügbarer Objektdatenbanken etwas aus der Zeit gefallen sein, aber sie hat in meinen Augen immer noch eine Daseinsberechtigung:
Dinge der realen Welt werden in einem konzeptuellem Schema, dem Entity-Relationship-Diagram abgebildet
Aus diesem Schema werden Tabellen abgeleitet (oftmals mehr Tabellen, als es Entitäten gibt).
Tabellen werden in einer konkreten Datenbank manifestiert
Ich verweigere mich bis heute standhaft, JPA das Feld hinsichtlich Definition von Tabellen zu überlassen.
--
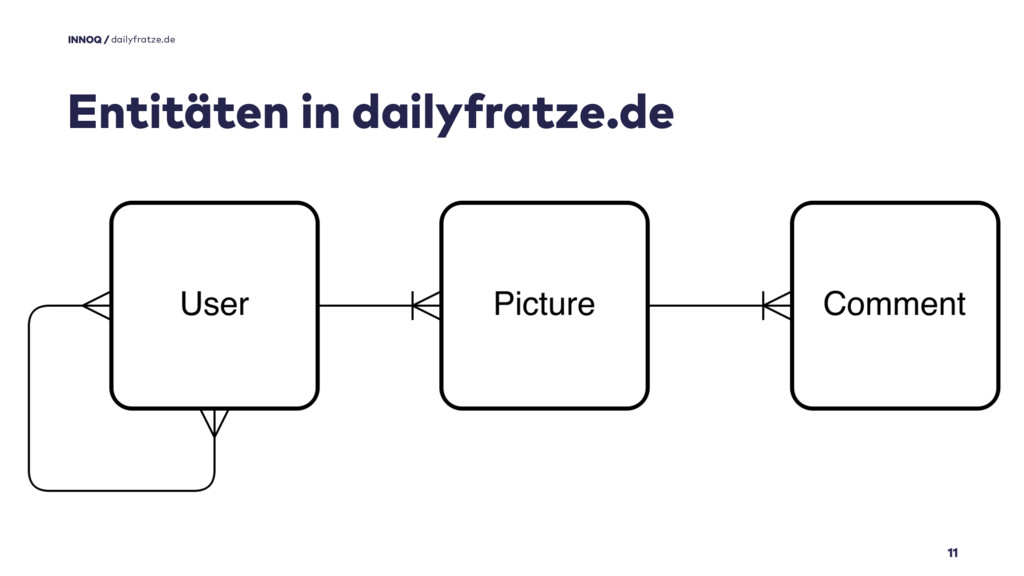
Das hier sind drei meiner Entitäten.
Wie unsere Geschäftsführung ja beim Vorstellungsgespräch richtig anmerkte, machen die Krähenfüße mein fortschreitendes Alter nur allzu deutlich.
Die n:m Beziehung der Benutzer würde mir übrigens als Mechanismus, Freundesbeziehungen zu speichern, auf die Füße fallen, würde dailyfratze.de versehentlich doch mal ein zweites Twitter oder Facebook.
--
Ein kurzer Ausflug in die Geschichte: Edgar Frank Code „erfand“ in den 1970er Jahren das relationale Datenbankmodell. Mein Eindruck im Alltag ist, dass das Wort Relation - Beziehung - oftmals falsche Erwartungen bei der Benutzung einer relationalen Datenbank macht: Während Beziehungen zwischen Entitäten modelliert werden, werden nur Beziehungen zwischen den Attributen von Dingen gespeichert:
Die Relationen einer relationalen Datenbank sind die Tabellen selber, sie beschriebenen Mengenrelationen im mathematischen Sinne.
Auch Foreign-Keys manifestieren keine Beziehungen zwischen Dingen, sondern stellen erstmal nur referentielle Integrität sicher.
--
Relevant wird dieser Fakt dann nicht nur wenn man an das Thema „Object-relational impedance mismatch“ (https://de.wikipedia.org/wiki/Object-relational_impedance_mismatch) denkt, sondern auch an SQL, die Structered Query Language.
SQL dient unter anderem zur Abfrage relationaler Datenbanksysteme und basiert daher natürlich auch auf relationaler Algebra. Das Ergebnis einer Abfrage von Relationen ist immer wieder eine neue Relation.
Für mich ist dies einer der Hauptvorteile einer relationalen Datenbank.
--
Was kann man denn nun mit Daily Fratze machen?
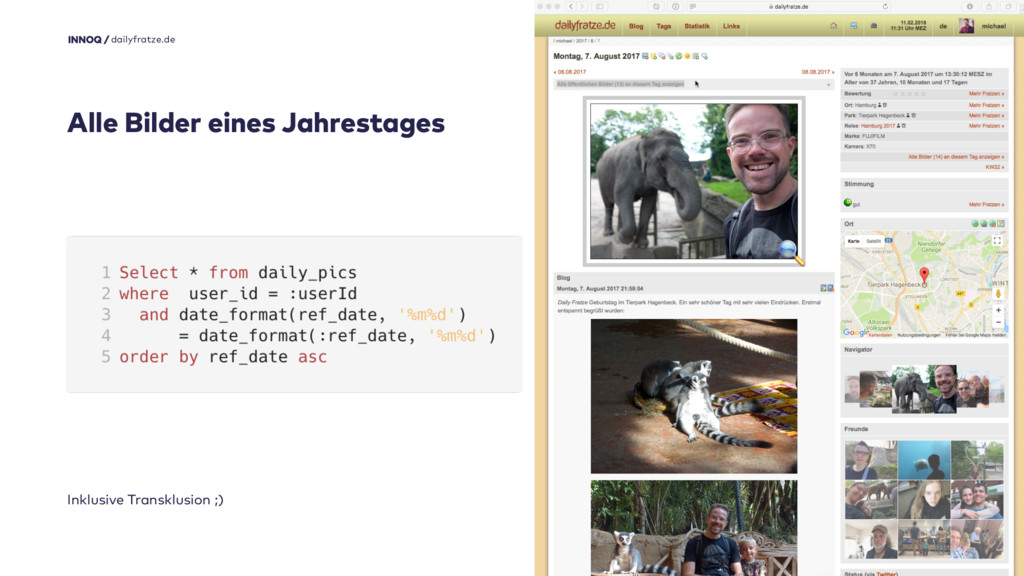
Die Monatsübersicht habt ihr schon gesehen, das hier ist die Tagesansicht und eine sehr einfache Abfrage, die alle Bilder eines Benutzers an einem Jahrestag zurückliefert. Live sieht das dann so aus.
Hinter dem Link steht übrigens eine kleine JavaScript-Funktion, die das Ergebnis einer ganz normalen URL in die Seite einbettet, sehr ähnlich dem Beispiel der ROCA-Versicherung, allerdings schon um 2012 entstanden.
--
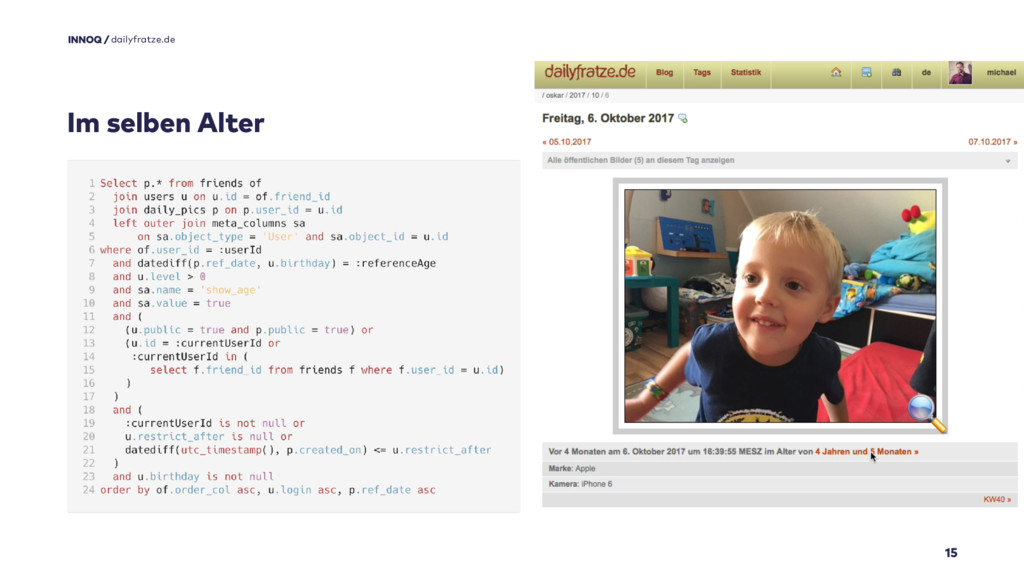
Im Bild seht ihr meinen jüngsten Sohn Oskar sowie einen Link, alle seine „Freunde“ im gleichen Alter anzuzeigen, rechts daneben die dazugehörige Abfrage.
Ich liebe diese Funktion :)
Die Fachlichkeit der Abfrage ist nicht weiterkompliziert und manifestiert sich nach der Herstellung von Beziehungen über einige Joins in nur einer Where-Bedingungen.
Interessanter sind die nachfolgenden Bedingungen. Dort überprüfe ich, ob der angemeldete Benutzer überhaupt berechtigt ist, das Bild zu sehen. Wenn nicht, selektiere ich es gar nicht erst.
Der Ansatz ist vielleicht ebensowenig „hipp“, wie echte Webanwendungen zu bauen, aber meines Erachtens sinnvoll: Etwas, das ich gar nicht erst lade, kann ich auch nicht versehentlich anzeigen.
--
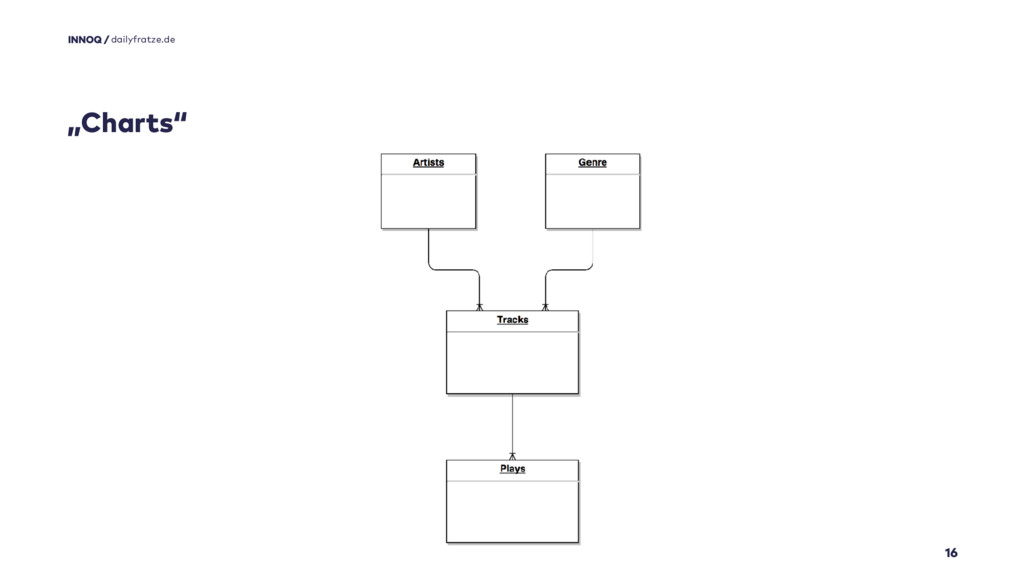
Dann gibt es da noch die „Charts“, die auf einem Datenbankmodell in Normalform 1 basieren…
Ein kleines iTunes-Apple-Script nutzt eine per OAuth geschützte HTTP-RPC-Schnittstelle, um Wiedergaben zu loggen und das Ergebnis stellt sich monatlich so da.
Zu der zugrunde liegenden „Monsterabfrage“ gibt es einen eigenen Vortrag. Diese Abfrage würde ich auf keinen Fall in einer NamedNative-JPA-Query verstecken wollen.
Mein aktuell bevorzugte Technologie ist jOOQ.
Gerne können wir darüber später noch sprechen.
--
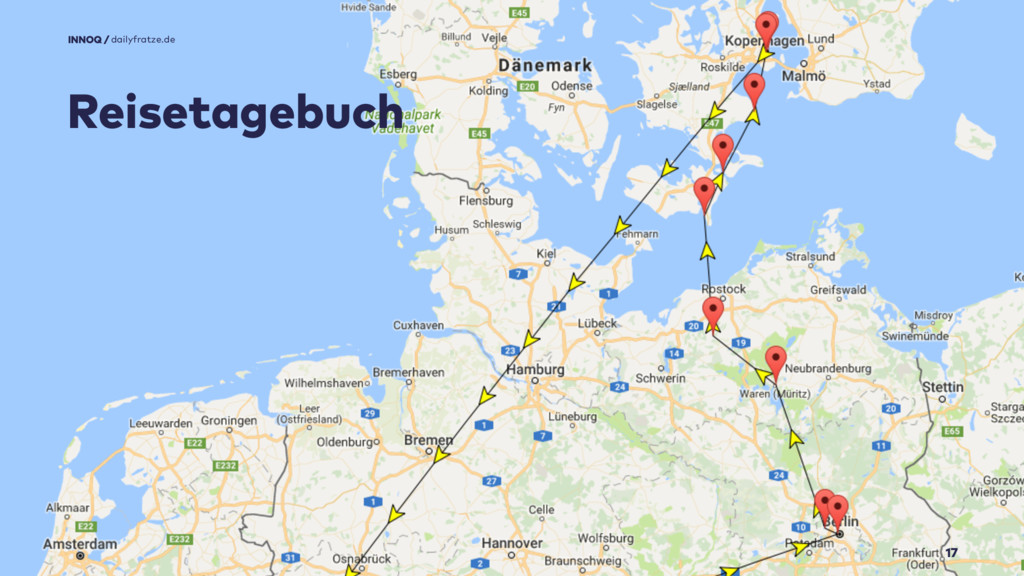
Aus den Exit-Daten der Bilder lese ich nicht nur Datum und Uhrzeit aus, sondern auch die Geo-Tags, Längen und Breitengerade, an denen Bilder gemacht wurden.
Handy-Kameras haben das ja mittlerweile standardmässig, aber auch einige normale Fotoapparate.
Damit kann ich Reisetagebücher generieren, hier im Bild meine Radtour von Berlin nach Kopenhagen 2016.
Funfact: Die Berechnung der räumlichen Distanz habe ich als Stored-Procedure in der SQL-Datenbank abgelegt, damit ich diese auch in Abfragen benutzen kann.
--
Über mein persönliches Twitter-Archiv habe ich vor 2 Jahren mal gebloggt: Ein Job polled regelmässig mein Profil, speichert die Tweets ab und aktualisiert einen Dateibasierten Lucene Index.
Das muss ich nicht manuell machen, sondern nutze die Tatsache, dass ich JPA Entitäten habe, aktiv aus, werfe noch ein paar Annotationen aus dem Hibernate-Search-Projekt drauf und bin fertig.
Mittlerweile funktioniert das nicht nur mit lokalen Indizes, sondern auch mit Elastic-Search im Hintergrund.
--
Wenn Rails doch so super war, warum wechseln?
Die Migration von Rails 2 auf 3 war damals nicht trivial und ich habe mich beim Versuch ziemlich geärgert. Darüber hinaus habe ich auch beruflich nach alternativen für einen überalterten Oracle-Stack gesucht.
Dinge, die ich ausprobiert habe stehen auf der Folie. Grails war damals Rails auf der JVM noch am ähnlichsten, aber ich kannte mich noch nicht gut genau mit dem darunter versteckten Spring-Stack aus, um Fehler schnell und sicher analysieren zu können. Darüber hinaus ist es vielleicht auch nicht immer die beste Idee, eine neue Sprache (Groovy), die man selber cool findet, irgendwo hinzu tragen, wo es ganz andere Probleme gibt.
J2EE kam für uns aus vielerlei Gründen nicht in Frage.
Blieb Spring.
--
Natürlich bedeutete Spring für mein Team damals auch eine Lernkurve: Java. Aber ansonsten war der Einstieg recht flach und aufgrund der hervorragenden Dokumentation auch flach.
Die offene und freundliche Community hat ihr übriges getan.
Für mich aber am interessantesten: Das Action-orientierte Framework eignete sich sowohl für Webseiten als auch für Anwendungen.
Die meisten für mich und meinen Arbeitgeber interessanten Java EE Standards wurden auch unterstützt.
Und dann ist es auch damit bei Spring geblieben.
--
In der Rails-Variante der Anwendung hatte ich noch einige externe Erweiterungen zur Bildverarbeitung genutzt, insbesondere RMagick. Davon wollte ich weg, die Installation war nie einfach.
Probleme bereiteten mir dabei eine gute Skalierung von Bildern und Auslesen von Exifdaten. ImageResize4J habe ich dann für relativ kleines Geld lizenziert und setze es bis heute ein. Mir selber ist es nicht gelungen, einen Skalierungsalgorithmus mit guter Qualität zu entwickeln.
Der Metadata-Extractor von Drew Noakes ist Open Source und steht dem Exiftool in nichts nach.
--
Was hat es mir gebracht?
Ich bin mit der Seite nicht reich geworden, aber sie läuft kostendeckend: Die meisten regelmässigen Nutzer spenden einen kleinen, monatlichen Obolus fürs Hosting und die Domains und das passt für mich.
Ich war mit der Geschichte 2008 und 2013 im Radio, das war beide Male ganz cool, aber das beste daran ist die Tatsache, dass ich sowohl im „realen“ Leben als auch in der Java, Spring und SQL-Community über das Projekt viele neue Freunde kennen gelernt habe.
Davon abgesehen, konnte ich das meiste davon irgendwann auch im Projekt sinnvoll einsetzen.
--
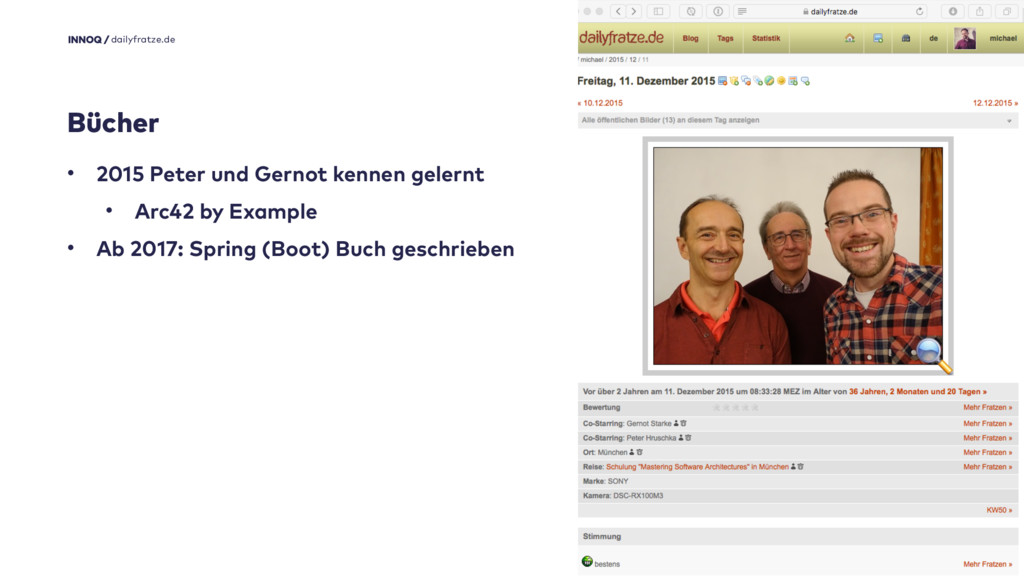
Es sind Bücher entstanden. Ende 2015 habe ich Peter und Gernot in München auf der ISAQB Schulung kennen gelernt und Gernot hat mich dazu animiert, das Projekt doch einmal mit dem Arc42-Template zu dokumentieren. Schlussendlich habe ich mich - unter anderem wegen der geringen Aufwandes - für ein anderes Projekt entschieden, aber trotzdem.
Das angesammelte Spring Know-How habe ich seit letztem Jahr in ein Spring Buch geschüttet, was dann hoffentlich nächsten Monat erscheint.
--
Meine Pläne für die Zukunft? Vielleicht mal so etwas wie „Kunst“ damit machen. Der Screenshot zeigt eine Tower-Ähnliche JavaFX 3D Anwendung, in der ich die Bilder zum einen als farbliches Mosaik und zum anderen auf der Zeitachse von vorne nach hinten sortiert habe.
Ich werde die Anwendung sicherlich bald auf Postgres migrieren und wenn es dann die Zeit hergibt, eine Version 4 schreiben, die dann kein Monolith mehr sein wird, sondern aus drei bis vier SCS-Vertikalen bestehen wird.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}