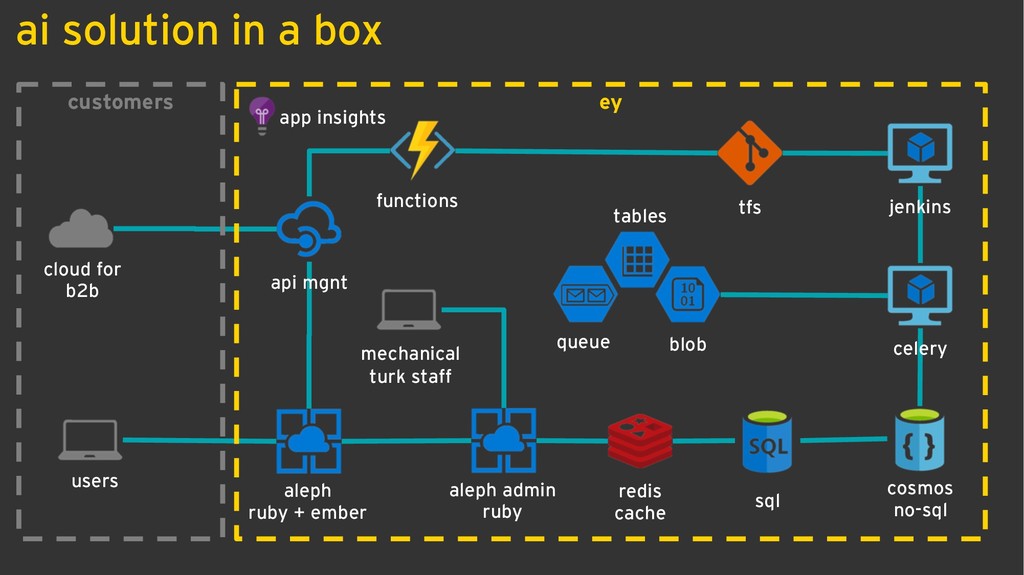
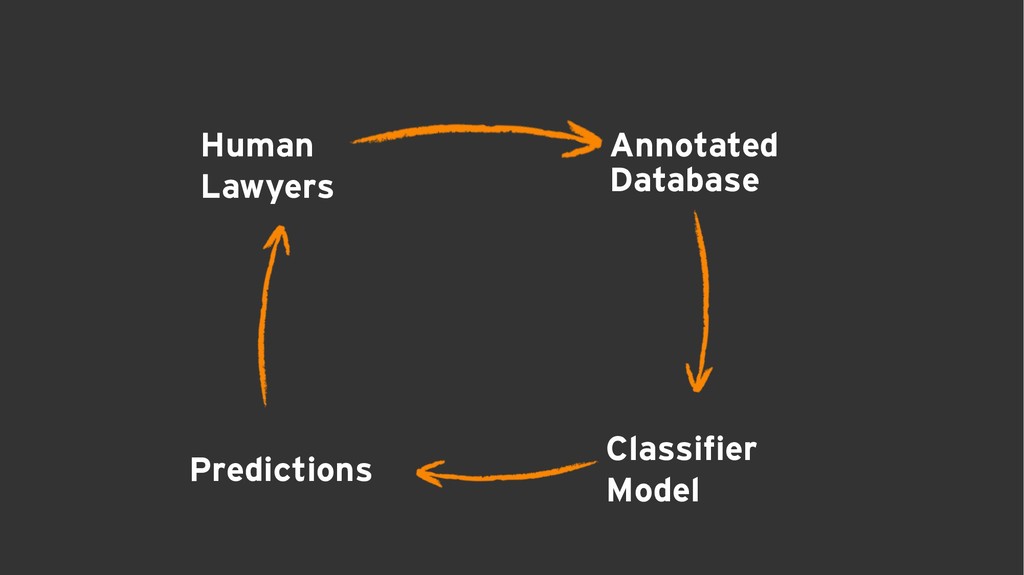
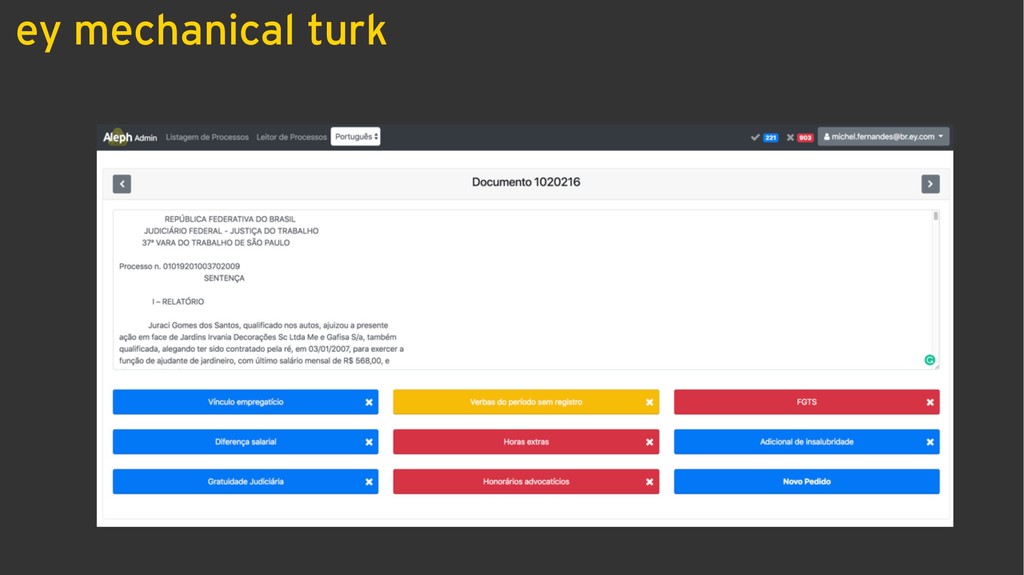
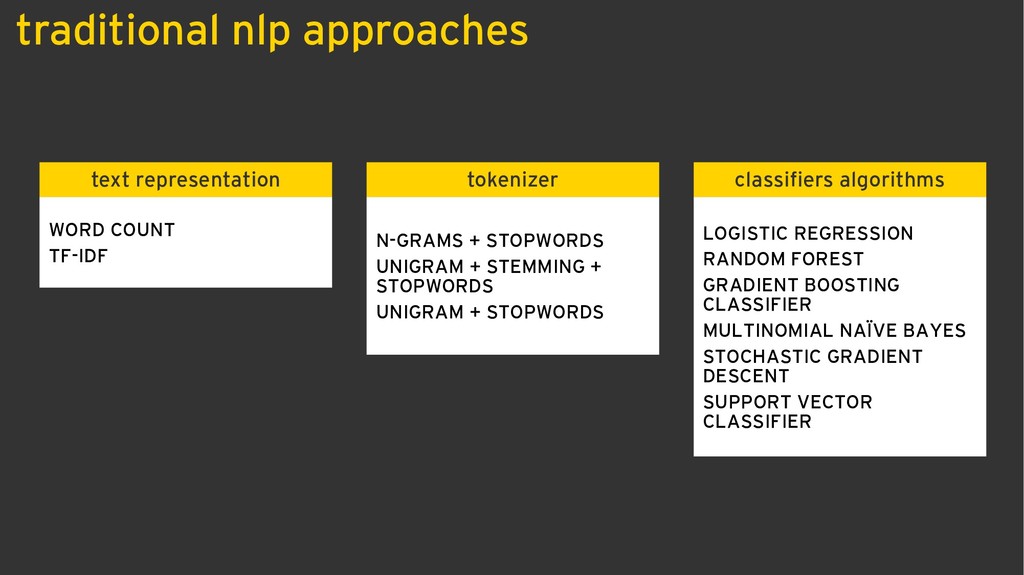
The jurimetrics practice in Brazil, when exists, usually is done with local data from legal offices using data collected from its own cases maintained using time-consuming manual processes. Our approach is based on data collection of all public data (not only cases that we work) combined with our workforce of lawyers to create trained datasets in order to use in natural language processing deep learning models for attributes extraction, such as judge, lawyer, plaintiff, a defendant, requests, and jurisprudence. The organization of unstructured data gathered enabled EY to deliver unprecedented analysis of litigation amounts deposits aiming to drastically reduce the provisions, besides other benefits in the legal chain, especially in labor law.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Michel Fernandes [email protected] Rafael Kenski [email protected] THANK YOU](https://files.speakerdeck.com/presentations/7f8f20eca85e43229746132164eb3057/slide_42.jpg){kind=link}