Un agent IA n'est pas une app web comme les autres. A P P C L A S S I Q U E Requête → Réponse • Latence : millisecondes • Coût : CPU / mémoire • Échec : binaire (200 ou 500) • Scaling : signal CPU fiable • Comportement : déterministe A G E N T I A Boucle LLM + Tools + Retries • Latence : secondes à minutes • Coût : tokens = $ à chaque appel • Échec : partiel, silencieux, coûteux • Scaling : CPU ment, il faut autre chose • Comportement : non déterministe L'infra doit être repensée. Pas juste dimensionnée plus grand. 2 / 12
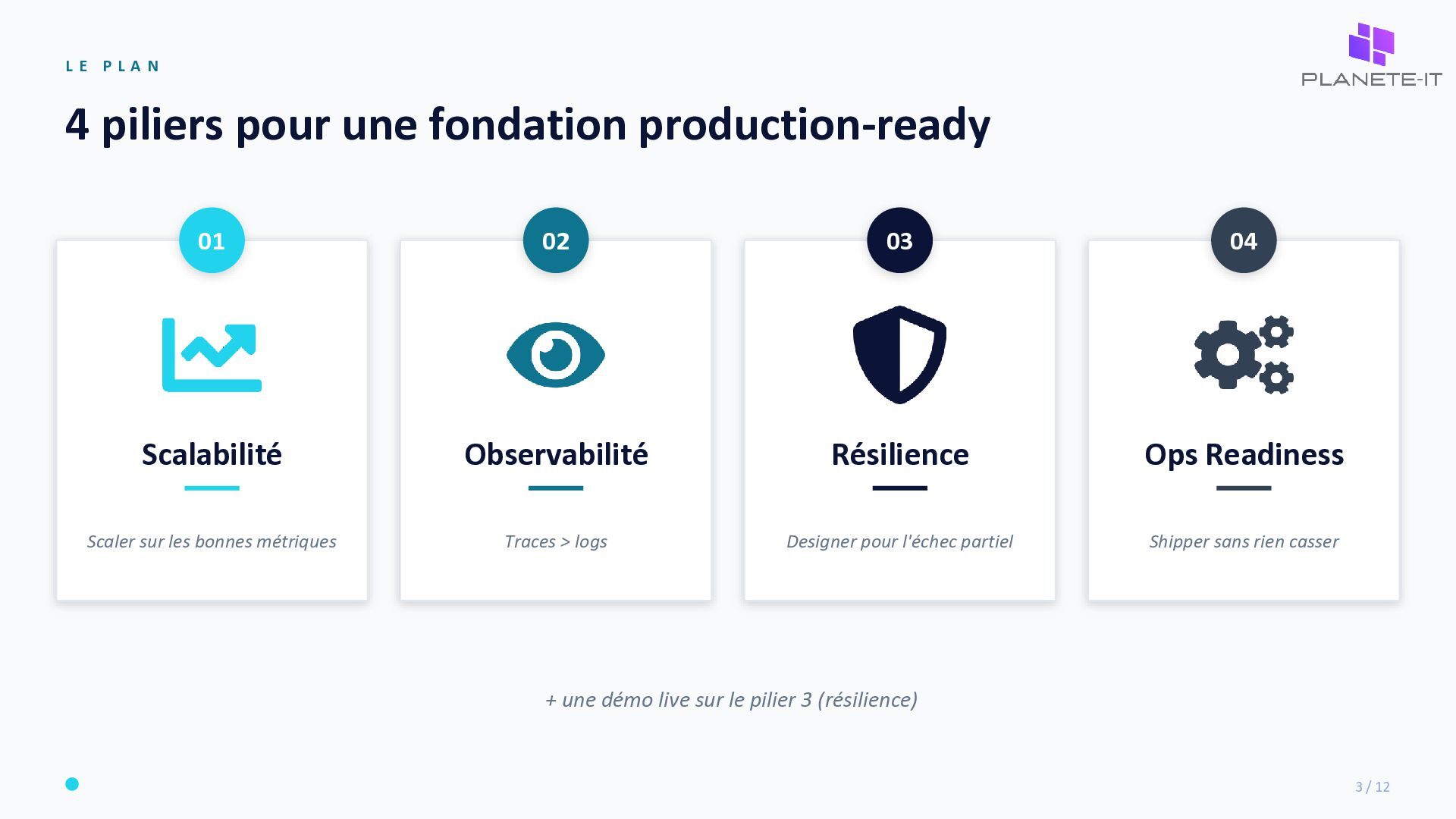
fondation production-ready 01 Scalabilité Scaler sur les bonnes métriques 02 Observabilité Traces > logs 03 Résilience Designer pour l'échec partiel 04 Ops Readiness Shipper sans rien casser + une démo live sur le pilier 3 (résilience) 3 / 12
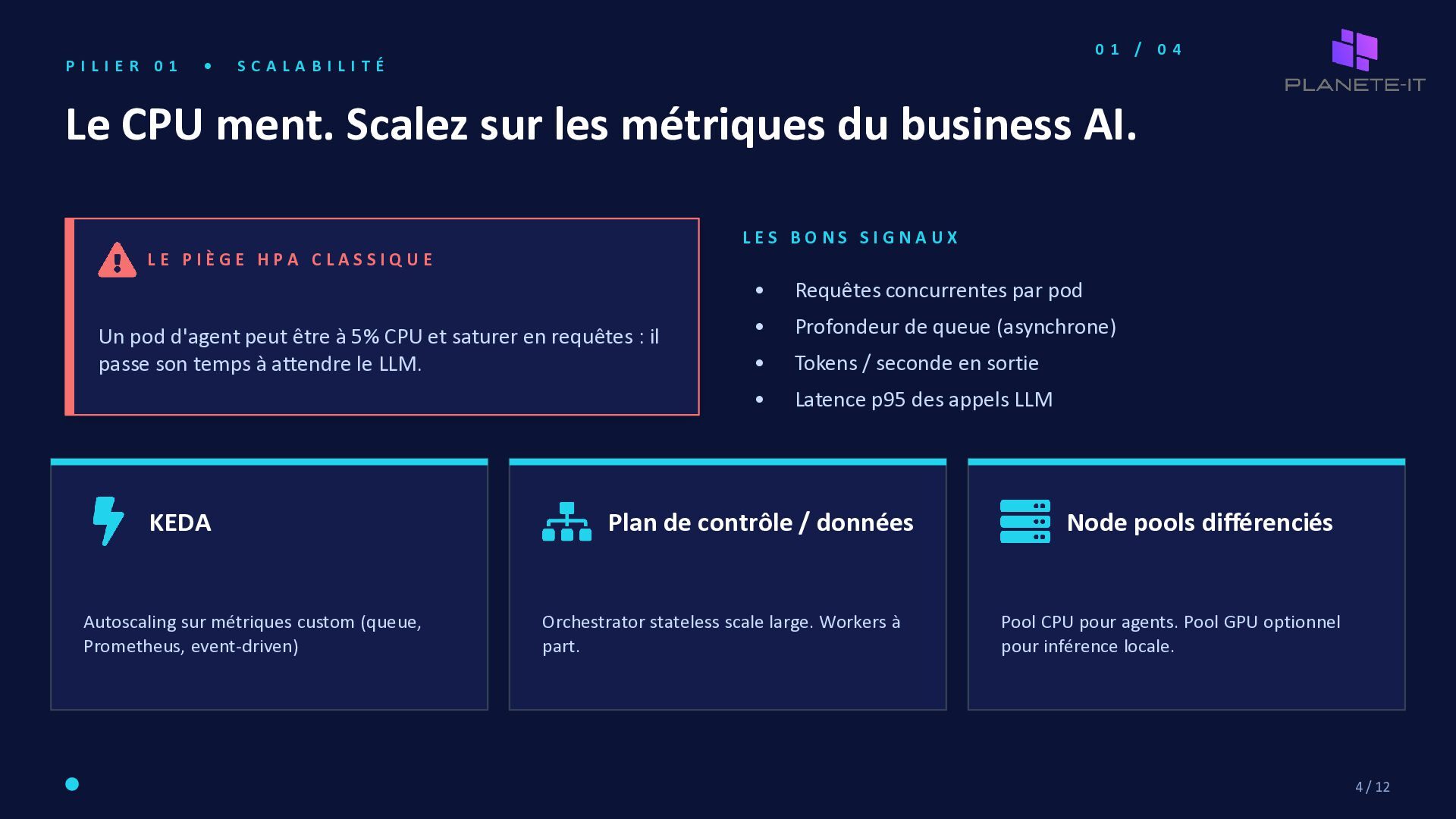
R 0 1 • S C A L A B I L I T É Le CPU ment. Scalez sur les métriques du business AI. L E P I È G E H P A C L A S S I Q U E Un pod d'agent peut être à 5% CPU et saturer en requêtes : il passe son temps à attendre le LLM. L E S B O N S S I G N A U X • Requêtes concurrentes par pod • Profondeur de queue (asynchrone) • Tokens / seconde en sortie • Latence p95 des appels LLM KEDA Autoscaling sur métriques custom (queue, Prometheus, event-driven) Plan de contrôle / données Orchestrator stateless scale large. Workers à part. Node pools différenciés Pool CPU pour agents. Pool GPU optionnel pour inférence locale. 4 / 12
R 0 2 • O B S E R V A B I L I T É Un log ne suffit plus. Il faut la trace du raisonnement. "ERROR 500" ne dit rien sur un agent. Vous devez pouvoir rejouer la chaîne de pensée : prompt → appel LLM → tool call → retry → tool call → réponse finale. L A S T A C K OpenTelemetry Instrumentation agent loop + LLM + tools Application Insights Distributed tracing & dependencies Managed Prometheus Métriques custom (tokens, coût, qualité) Managed Grafana Dashboards AI + drill-down dans traces L E S M É T R I Q U E S A I À E X P O S E R $ / trace Coût par requête agent tokens in/out Par modèle, par tenant tool-call success Taux de réussite des outils latency p95 Par LLM, bout en bout Règle d'or : instrumentez AVANT de déployer. Retrouver une cause racine sur un agent non tracé est impossible. 5 / 12
R 0 3 • R É S I L I E N C E Designer pour l'échec partiel, pas pour le happy path. Timeouts + Budgets Par requête : temps MAX et tokens MAX. Un agent qui boucle coûte de l'argent. Circuit Breakers Par dépendance externe (OpenAI, APIs, vector DB). Istio ou code applicatif. Fallback multi-modèles Azure OpenAI rate-limite ? Bascule vers un modèle secondaire. Retry idempotent Exponential backoff + jitter. Attention aux tool calls non- idempotents. Workload Identity Zéro secret en clair. AKS + Entra + Key Vault. Audit sur chaque appel. L A B O N N E S T R A T É G I E Graceful degradation > Fail closed Désactivez les tools dont les dépendances tombent. Répondez en mode dégradé. Ne faites JAMAIS tomber l'agent complet. DÉMO sur la slide suivante → coupe dépendance → circuit breaker → fallback live dans Grafana 6 / 12
L I E R 0 3 • D É M O On coupe une dépendance. Que se passe-t-il ? 1 État nominal Agent répond avec Azure OpenAI GPT-4. Latence p95 : 2.1s. Circuit breaker : CLOSED. 2 Incident injecté kubectl apply chaos : 100% d'erreurs sur le modèle primaire. 5 échecs consécutifs. 3 Circuit breaker s'ouvre Plus d'appel vers le primaire. Fallback déclenché vers le modèle secondaire. 4 Mode dégradé assumé Agent continue à répondre. Alerte Grafana. SLO respecté. 0 erreur 500 côté client. Observable. Graceful. Reproductible. → Voilà ce que l'infra doit garantir. 7 / 12
R 0 4 • O P S R E A D I N E S S Un changement de prompt = un changement de comportement. GitOps end-to-end Terraform pour AKS. Helm pour les workloads. ArgoCD / Flux pour la livraison. Tout est dans Git, rien n'est cliqué. Progressive delivery Canary obligatoire. Flagger + métriques AI (coût, qualité, latence) comme gates de promotion automatique. Evals en CI Avant merge : batterie d'évaluations sur dataset de référence. Pas de green eval, pas de merge. Qualité = gate comme les tests. FinOps natif Labels de coût par namespace/tenant. Alertes budgétaires via Azure Cost Management. Quotas de tokens par équipe. Security posture : Defender for Containers • Azure Policy • Network Policies • Private Endpoints vers Azure OpenAI 8 / 12
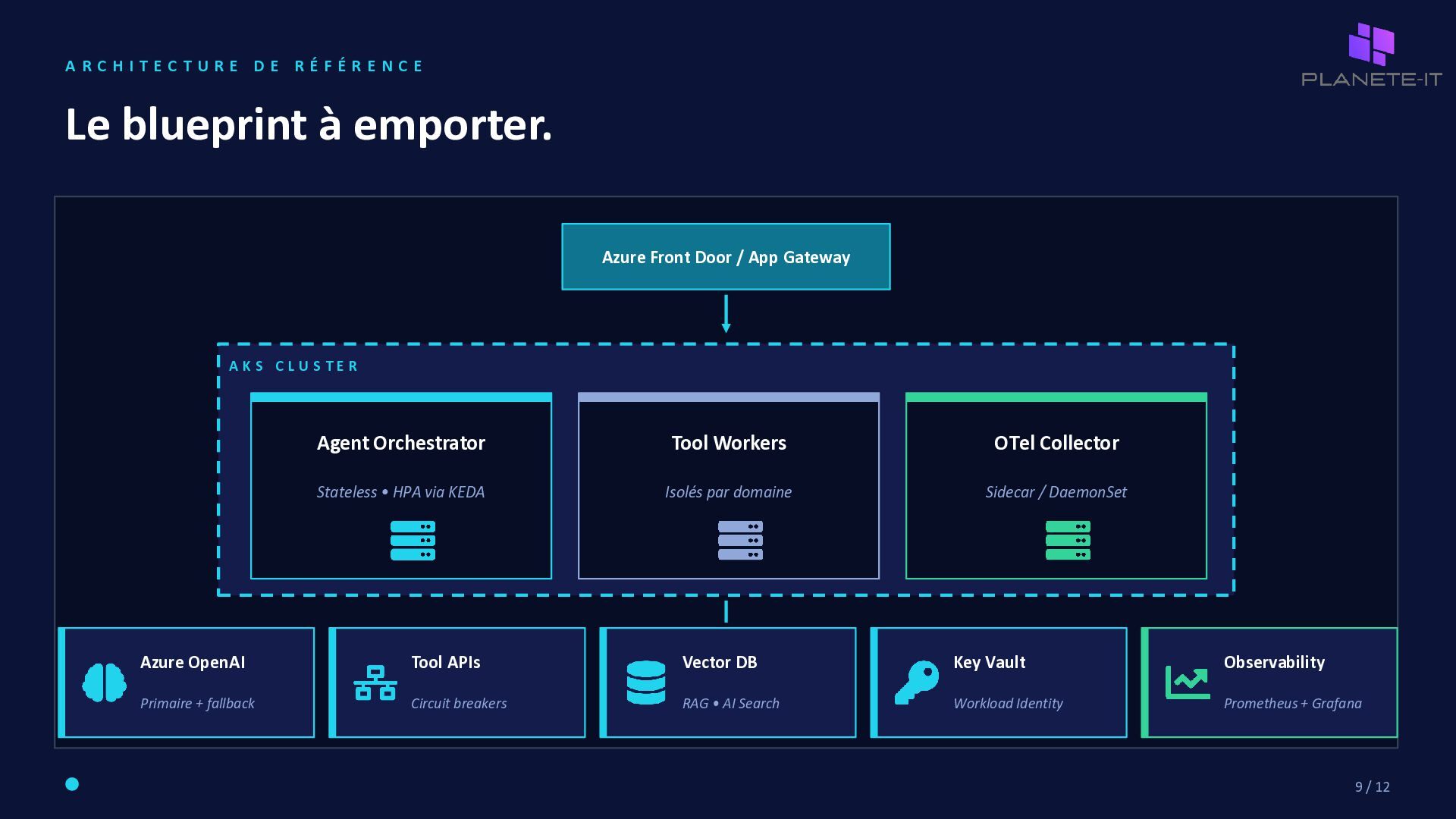
R E D E R É F É R E N C E Le blueprint à emporter. Azure Front Door / App Gateway A K S C L U S T E R Agent Orchestrator Stateless • HPA via KEDA Tool Workers Isolés par domaine OTel Collector Sidecar / DaemonSet Azure OpenAI Primaire + fallback Tool APIs Circuit breakers Vector DB RAG • AI Search Key Vault Workload Identity Observability Prometheus + Grafana 9 / 12
choses à retenir en rentrant. 01 Scalez sur le business AI. Oubliez le CPU. Requêtes concurrentes, tokens/sec, profondeur de queue. 02 Tracez avant de déployer. OpenTelemetry + App Insights + Grafana. Un agent non tracé = un incident non résolvable. 03 Designer pour l'échec partiel. Circuit breakers, fallback multi-modèles, graceful degradation. Fail > fail closed. 04 GitOps + Evals + FinOps dès J1. Pas en rattrapage. Un prompt modifié = un canary. Toujours. Une app IA en prod, c'est 20% de modèle et 80% de plateforme. Construisez la plateforme d'abord. 10 / 12
L U S L O I N Ressources & références. I N F R A S T R U C T U R E • AKS Production Baseline (Microsoft) • KEDA — autoscaling event-driven • Azure OpenAI : réseau, quotas, tenants O B S E R V A B I L I T É & O P S • OpenTelemetry GenAI conventions • Flagger — progressive delivery • Azure Managed Grafana + Prometheus P A T T E R N S A G E N T • Circuit breaker : Polly / Istio • Workload Identity sur AKS • Evals : promptfoo, Azure AI Evaluation Slides, code & démo : github.com/your-handle/build2026-infra-for-ai 11 / 12
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}