Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
クラウドからエッジまで ~ 1,700台を支える監視設計~
Search
OptFit Corp.
May 14, 2026
Technology
150
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
クラウドからエッジまで ~ 1,700台を支える監視設計~
クラウドネイティブ会議 2026-5/14 ~ 15 (Wed ~ Fri) @ 中日ホール
OptFit Corp.
May 14, 2026
More Decks by OptFit Corp.
See All by OptFit Corp.
AI時代の認知負荷との向き合い方
optfit
0
240
Culture Deck
optfit
0
9.9k
optfit engineer culture deck
optfit
0
10k
NGK2024SスポンサーLT-OPTFIT
optfit
0
80
Other Decks in Technology
See All in Technology
Mastraエージェント、どのクラウドにデプロイする?
minorun365
PRO
2
170
攻撃者がいなくてもAIエージェントはインシデントを起こす
nomizone
0
200
Docker Desktop不要の時代が来る? WSL標準の「wslc」で Linuxコンテナを動かしてみた.
ueponx
0
790
Zoom2Youtube.Claude
kawaguti
PRO
2
460
Foxgloveについて 実際にExtensionを開発して公開するまでの話 / About Foxglove: The Story of Developing and Releasing an Extension
ry0_ka
0
180
“全部コピーしない”ファイルデータの活用 : — FSx for ONTAP × S3 Tables × Icebergで作るメタデータカタログ
yoshiki0705
0
540
ヘルスケア領域における AI 活用と その安全性担保のための取り組み (Leveraging AI in Healthcare and Our Efforts to Ensure Its Safety) - Google I/O Extended Tokyo 2026, July 11, 2026
zettaittenani
0
130
小さいから、全部わかる。— 常駐AI "xangi" のすすめ
sugupoko
0
270
Text-to-SQLをAgentCoreで実現し、生成されるSQLの精度を定量的に評価する
yakumo
2
660
FinOps X 2026 Recap from Engineer Side #JapanFinOps
chacco38
0
270
ローカルLLMとLINE Botの組み合わせ その3 / LINE DC Generative AI Meetup #8
you
PRO
0
120
勉強会企画をアプリで構造化してみた 〜そこで見えた、AIとの付き合い方〜 / I've structured a study group plan using an app.
pauli
0
330
Featured
See All Featured
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
270
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
2
330
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
Rails Girls Zürich Keynote
gr2m
96
14k
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
340
Chrome DevTools: State of the Union 2024 - Debugging React & Beyond
addyosmani
10
1.2k
Beyond borders and beyond the search box: How to win the global "messy middle" with AI-driven SEO
davidcarrasco
3
180
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.5k
Bioeconomy Workshop: Dr. Julius Ecuru, Opportunities for a Bioeconomy in West Africa
akademiya2063
PRO
1
170
Building Applications with DynamoDB
mza
96
7.1k
GitHub's CSS Performance
jonrohan
1033
470k
Transcript
クラウドからエッジまで ~ 1,700台を支える監視設計 ~ クラウドネイティブ会議 2026-5/14 ~ 15 (Wed ~
Fri) @ 中日ホール 株式会社Opt Fit 西 和弥 murasame 上田 昂明
自己紹介 Komei Ueda SRE・基盤改善担当 Kazuya Nishi エンジニア
Opt Fitは名古屋の会社です
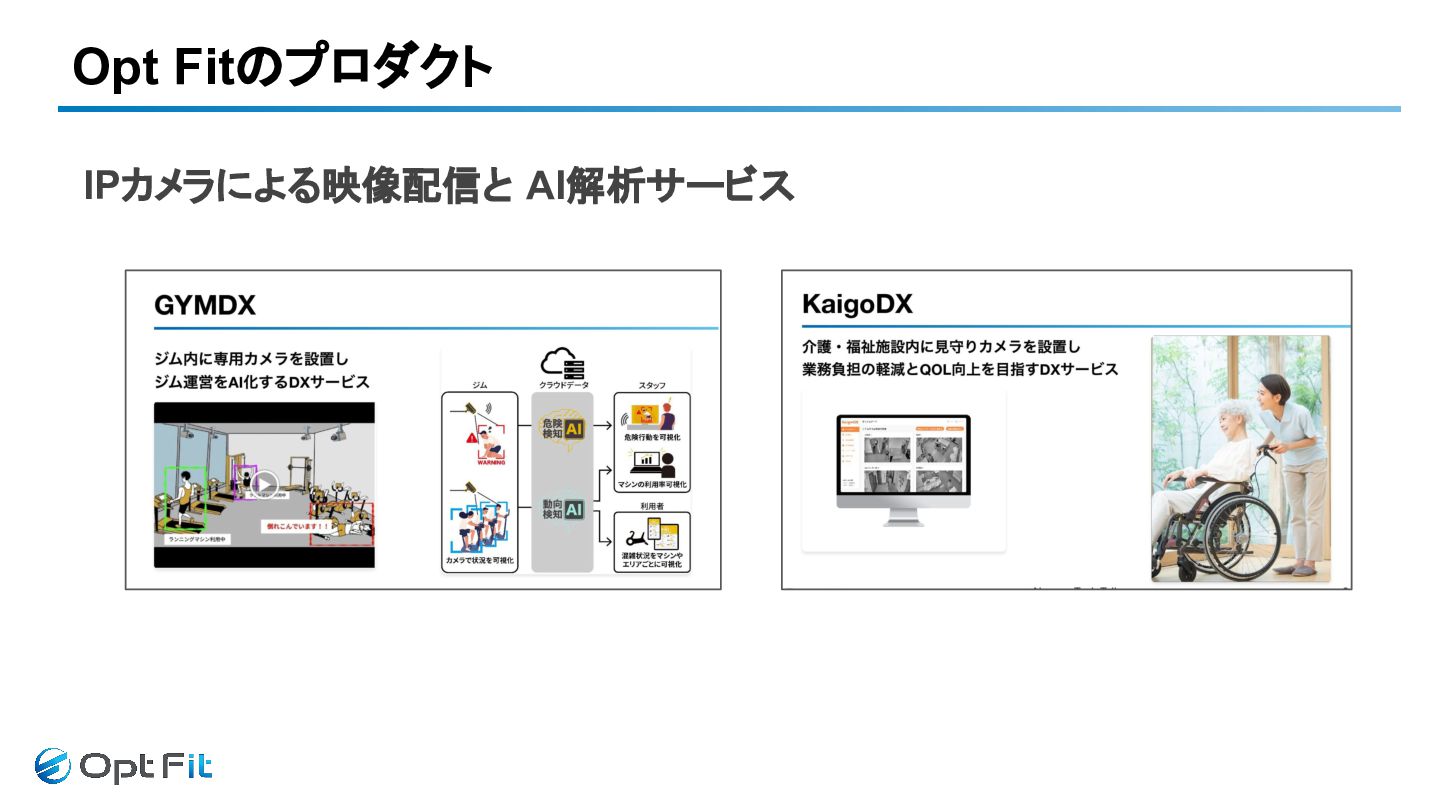
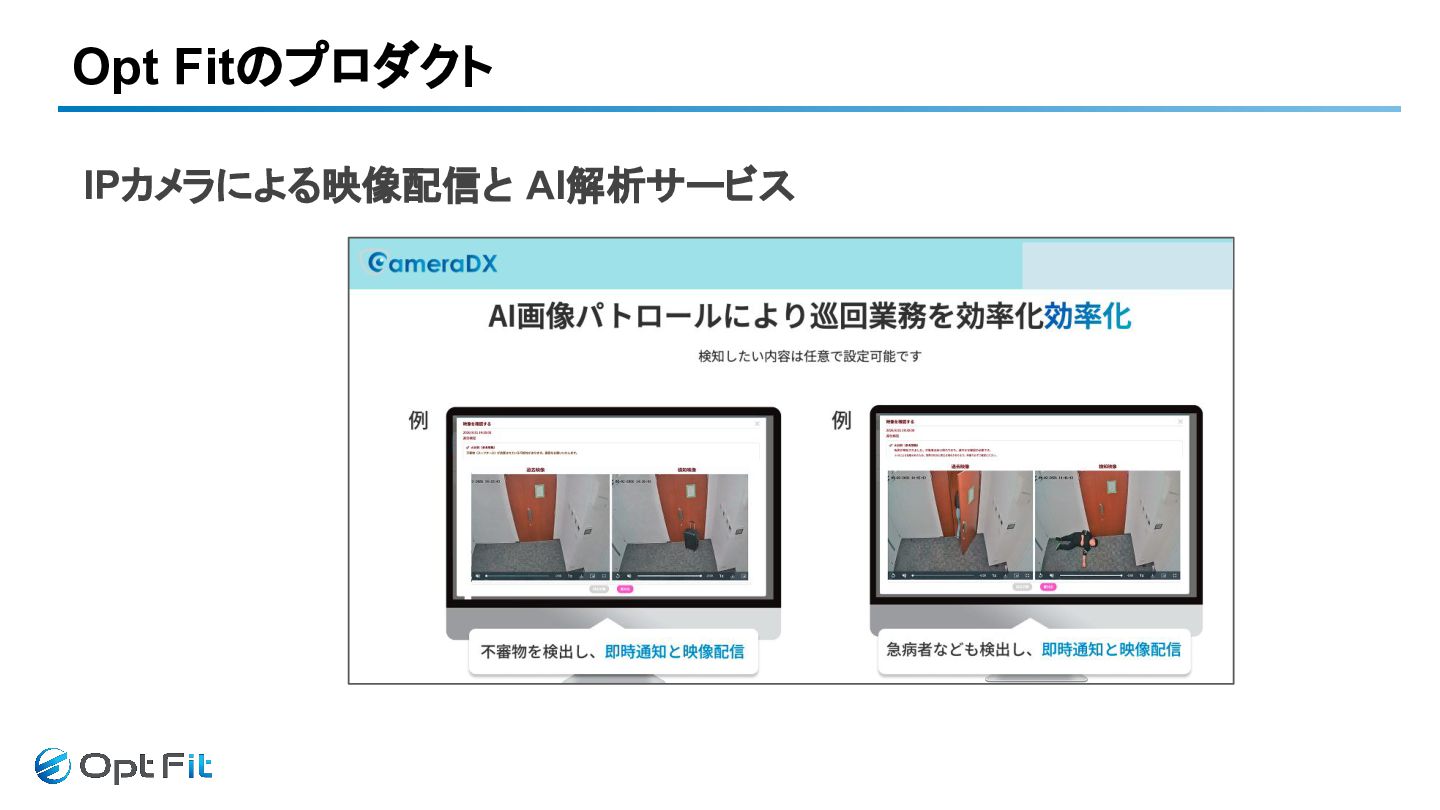
IPカメラによる映像配信と AI解析サービス Opt Fitのプロダクト
IPカメラによる映像配信と AI解析サービス Opt Fitのプロダクト
クラウド × エッジ構成 複数の実行環境で補い合う設計 エッジデバイス - 低コスト/低レイテンシ/限られたリソース - 一部の処理で活用 クラウド
- スケーラブル/耐障害性
エッジデバイスの特徴 冷たくなっている .... いいこと - ローカル処理 → データドロップが少ない - ネットワーク非依存
→ 安定動作 - クラウド送信削減 → 低コスト録画 わるいこと - CPU / メモリ逼迫 → 現場で停止 - 障害対応 → 停止すると現地交換が必要(高コスト) - 多様な設置環境 → 停電やネットワーク不安定リスク
私たちのこれまでの監視と課題
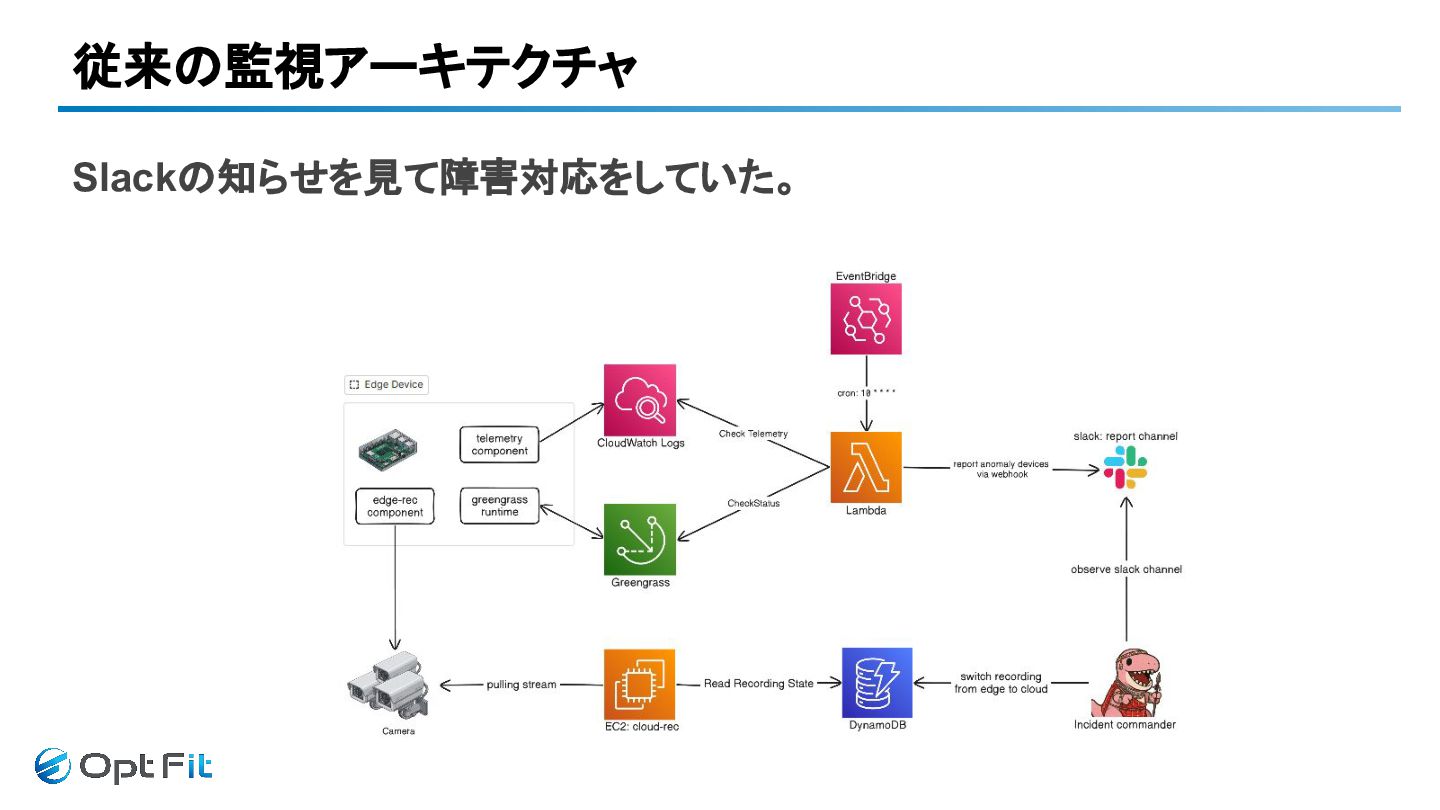
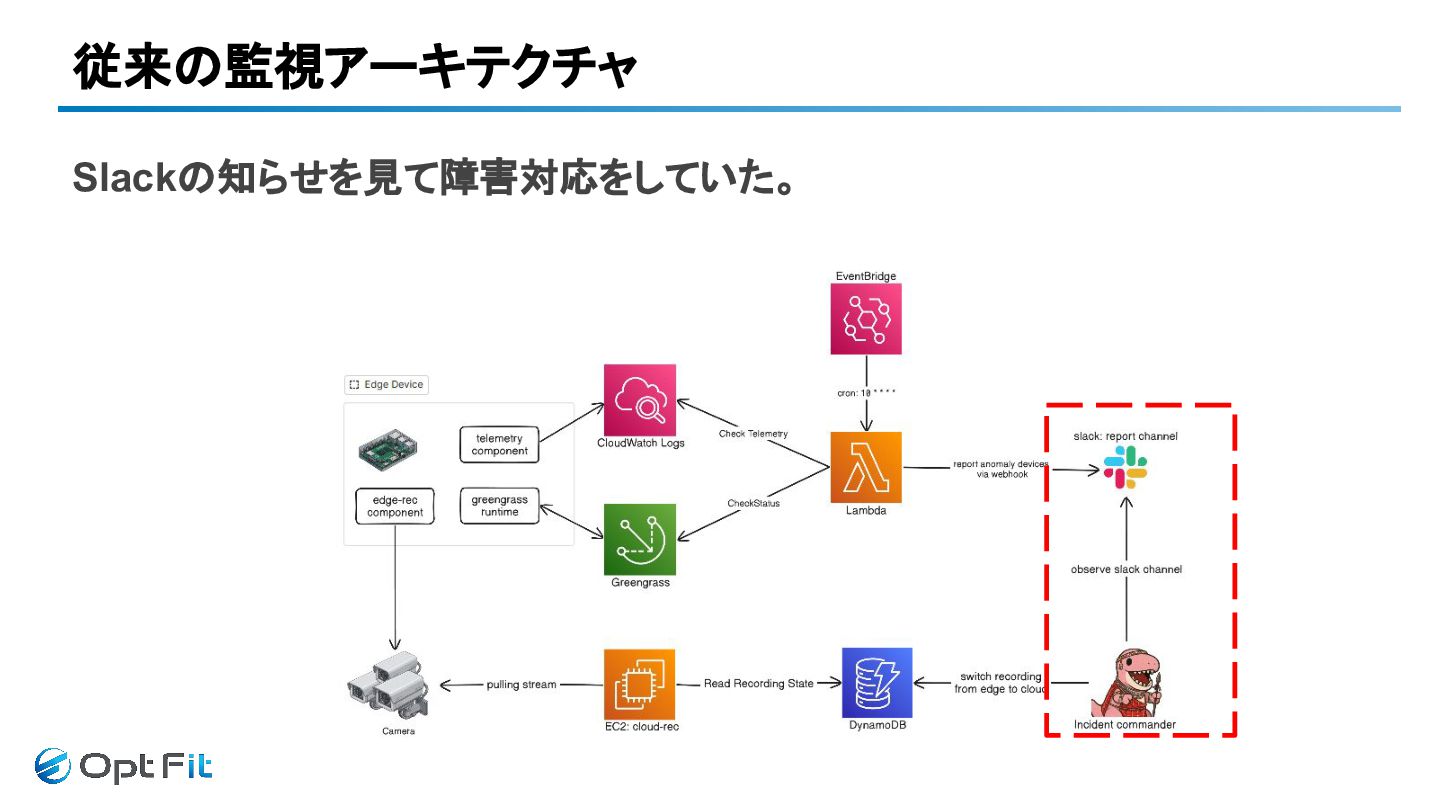
従来の監視アーキテクチャ Slackの知らせを見て障害対応をしていた。
従来の監視アーキテクチャ Slackの知らせを見て障害対応をしていた。
当時の監視の実態 監視ではなく、人力調査の入口のみ - 10分おきにSlack通知 - 問題がなくても通知 (🔇ミュート懸念🔕) - 大雑把な異常通知 -
コンポーネントにエラーあり - 接続不良あり 結果 - ログで解決しなければSSHして原因調査 - デバイス停止してから通知ではリカバリコスト高い
人間プル型運用の限界
当時の運用の実態 - 障害にすぐ気づけない - 担当者は常に気張る必要がある - 対応までに時間がかかる - 一度に大量デバイス障害に耐えられない
当時の運用の実態 - 通知を見て人が判断 - 休日/深夜は対応は苦しい - 映像監視員による 24/365 オンコール -
過去CTOは一晩3回が3週間続いた - リリースにも及び腰 一周回ってハイになった CTO
1,700台規模になると、運用は “設計問題”になる 問題が起きたら人がリカバリしに行く運用は、スケールしない 問題はさまざま - 特定エッジデバイス固有の問題 - 設置環境固有の問題 - 全国分散
- 停電 - ネットワーク品質 結果 - 数十台 → なんとか回る - 数百台 → 運用がつらい - 1,700台 → 完全に破綻
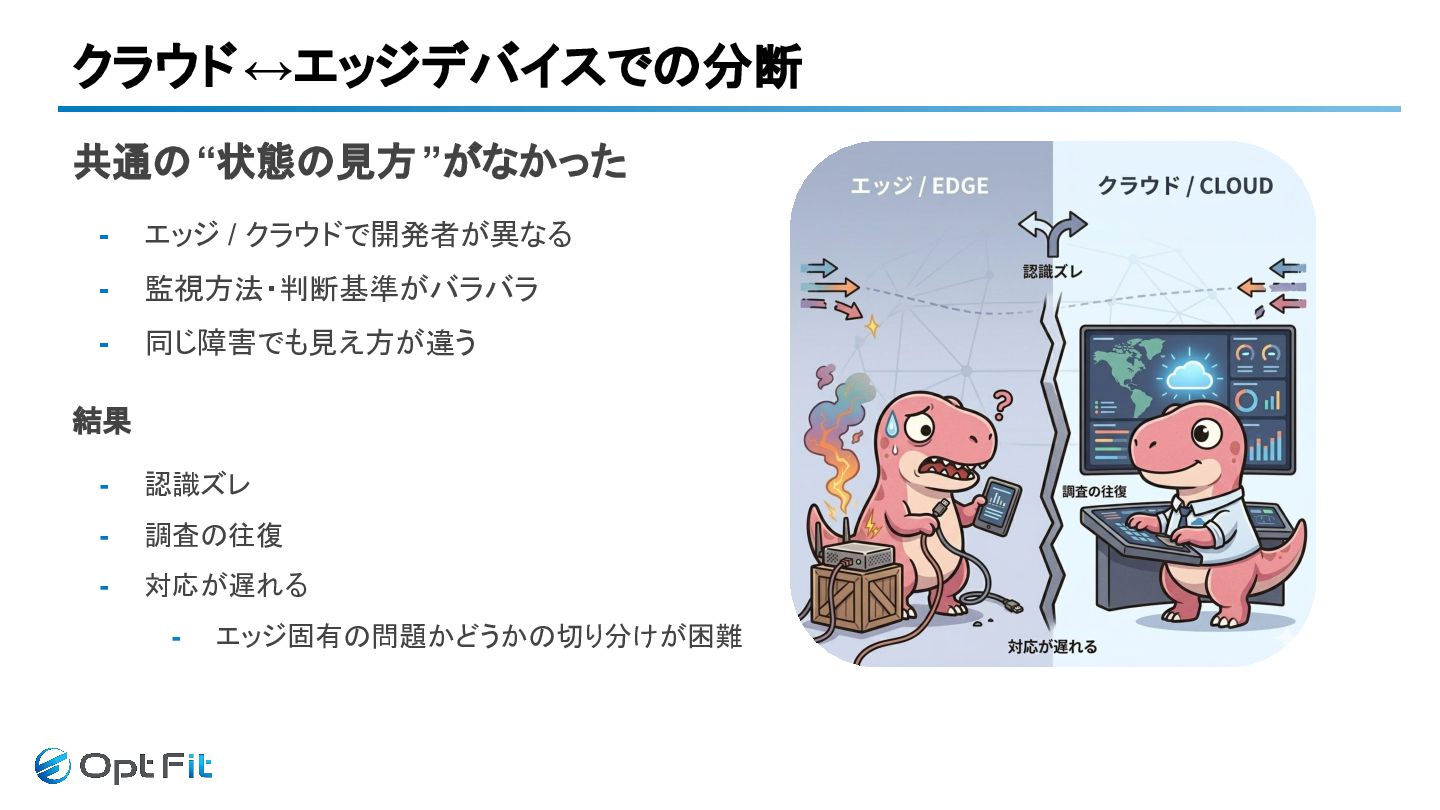
クラウド↔エッジデバイスでの分断 共通の“状態の見方 ”がなかった - エッジ / クラウドで開発者が異なる - 監視方法・判断基準がバラバラ -
同じ障害でも見え方が違う 結果 - 認識ズレ - 調査の往復 - 対応が遅れる - エッジ固有の問題かどうかの切り分けが困難
従来監視の課題まとめ - 10分起きのSlack通知の限界 - 毎回のSSH対応の限界 - デバイス数増加で毎回の原因調査と回復作業の限界 - クラウド↔エッジでシステム状態把握の方法がバラバラ 結果
エッジデバイスの運用が安定せずをコスト削減効果が不十分だった。
方向性は通知ではなく “観測” 人が見に行く監視から、状態が見える監視へ - SSHしなくても状態がわかる - エッジ / クラウド横断で見える -
共通の指標で判断できる - 品質低下の兆候を検知 向かうべき方向 - 既知の問題は対応を自動化 - 対応必要な問題のみ通知
Slackの“監視”からシステムの “観測”へ
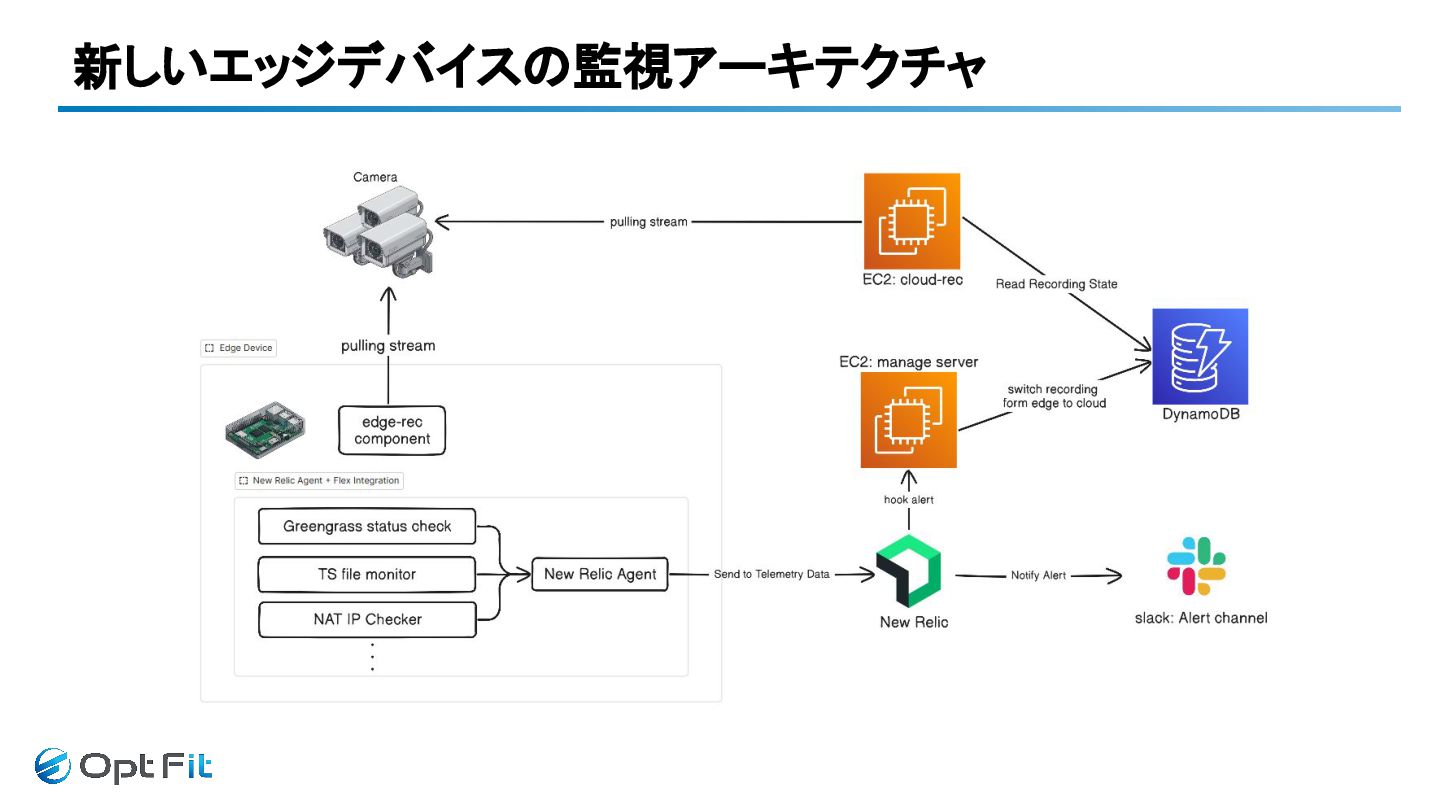
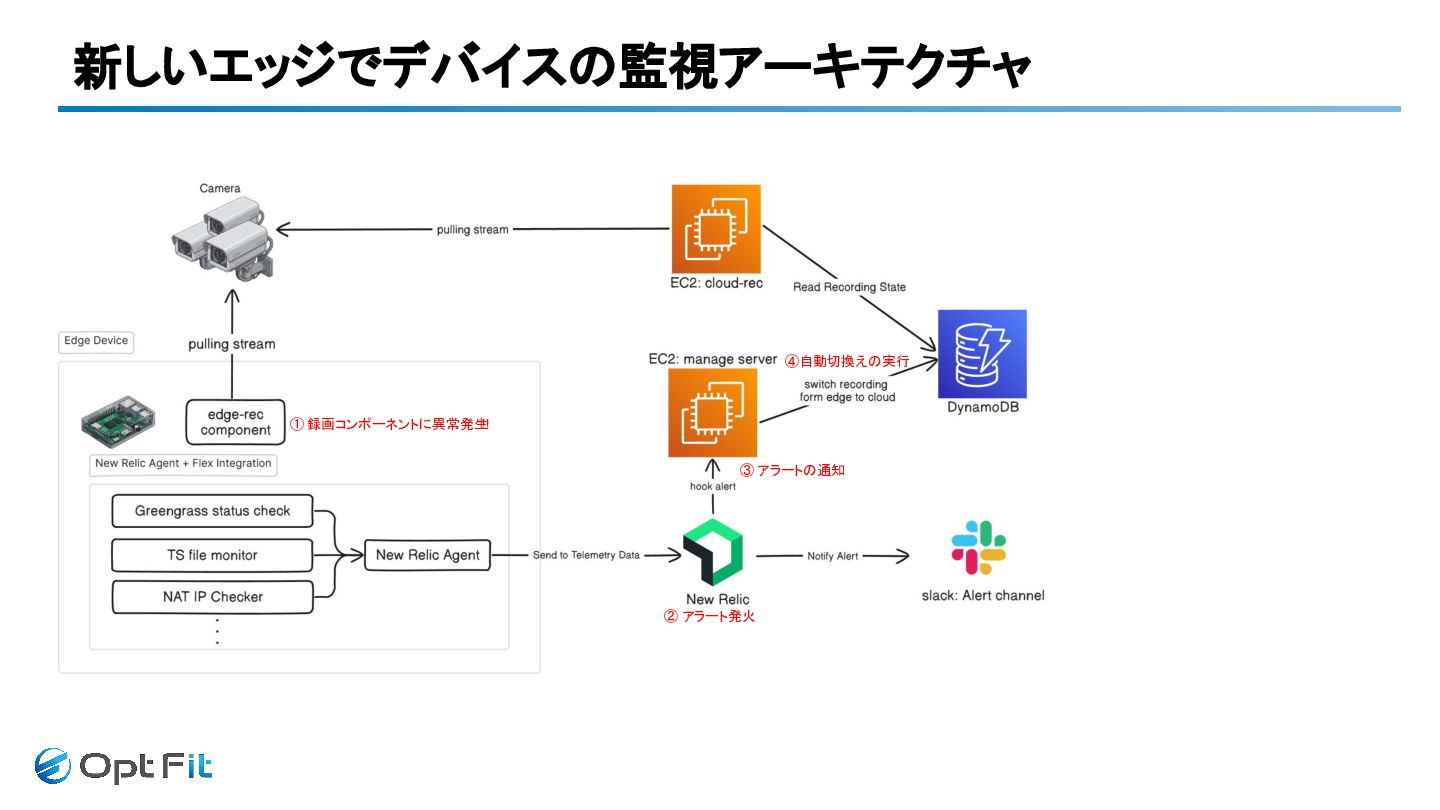
新しいエッジデバイスの監視アーキテクチャ
どうしてNew Relicなのか? 機能面 - カスタムイベントが集約できること - テレメトリデータすべてが共通のI/Fを持っていたこと - Flex Integrationなどのカスタム監視が容易に実装できること
どうしてNew Relicなのか? 機能面 - カスタムイベントが集約できること - テレメトリデータすべてが共通のI/Fを持っていたこと - Flex Integrationなどのカスタム監視が容易に実装できること
コスト面 - 機能を小さく試していくことができること - ホストやサービスがスケールしてもコスト爆発しづらい - 機能を制限せずにコストのコントロールができること - 開発/運用チームが少数精鋭のためユーザ課金でも問題にならなかった。
新しい設計で変わったこと SSH しなくても CPU, Memory, Disk, Networkなどの標準的な監視を実現した - Signal Lostから通信状況やデバイスの状態の悪いテナントがわかるようになった。
まだ温かい ...南無...🙏
新しい設計で変わったこと SSH しなくても CPU, Memory, Disk, Networkなどの標準的な監視を実現した - Signal Lostから通信状況やデバイスの状態の悪いテナントがわかるようになった。
- Diskの空き容量がなくなりSSHできなくなった救えないデバイスがなくなった。 瀕死のデバイス発見ガオ !! (マダイキガアル !!!)
新しい設計で変わったこと 新機能リリース します!!!!!! SSH しなくても CPU, Memory, Disk, Networkなどの標準的な監視を実現した -
Signal Lostから通信状況やデバイスの状態の悪いテナントがわかるようになった。 - Diskの空き容量がなくなりSSHできなくなった救えないデバイスがなくなった。 - リリース前検証を安心して行えるようになった
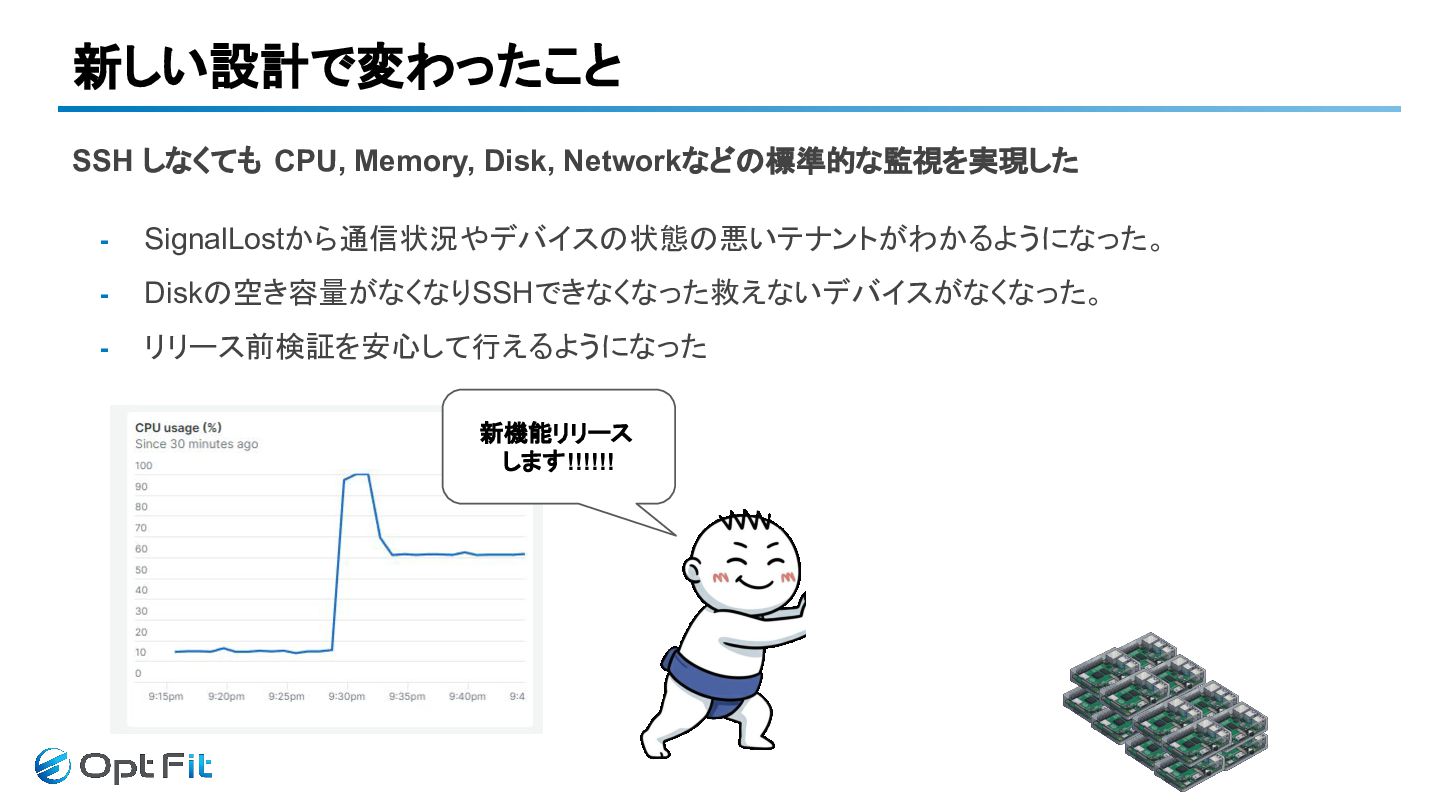
新しい設計で変わったこと 新機能リリース します!!!!!! SSH しなくても CPU, Memory, Disk, Networkなどの標準的な監視を実現した -
SignalLostから通信状況やデバイスの状態の悪いテナントがわかるようになった。 - Diskの空き容量がなくなりSSHできなくなった救えないデバイスがなくなった。 - リリース前検証を安心して行えるようになった
新しい設計で変わったこと ちょっ と待て い! 新機能リリース します!!!!!! SSH しなくても CPU, Memory,
Disk, Networkなどの標準的な監視を実現した - SignalLostから通信状況やデバイスの状態の悪いテナントがわかるようになった。 - Diskの空き容量がなくなりSSHできなくなった救えないデバイスがなくなった。 - リリース前検証を安心して行えるようになった
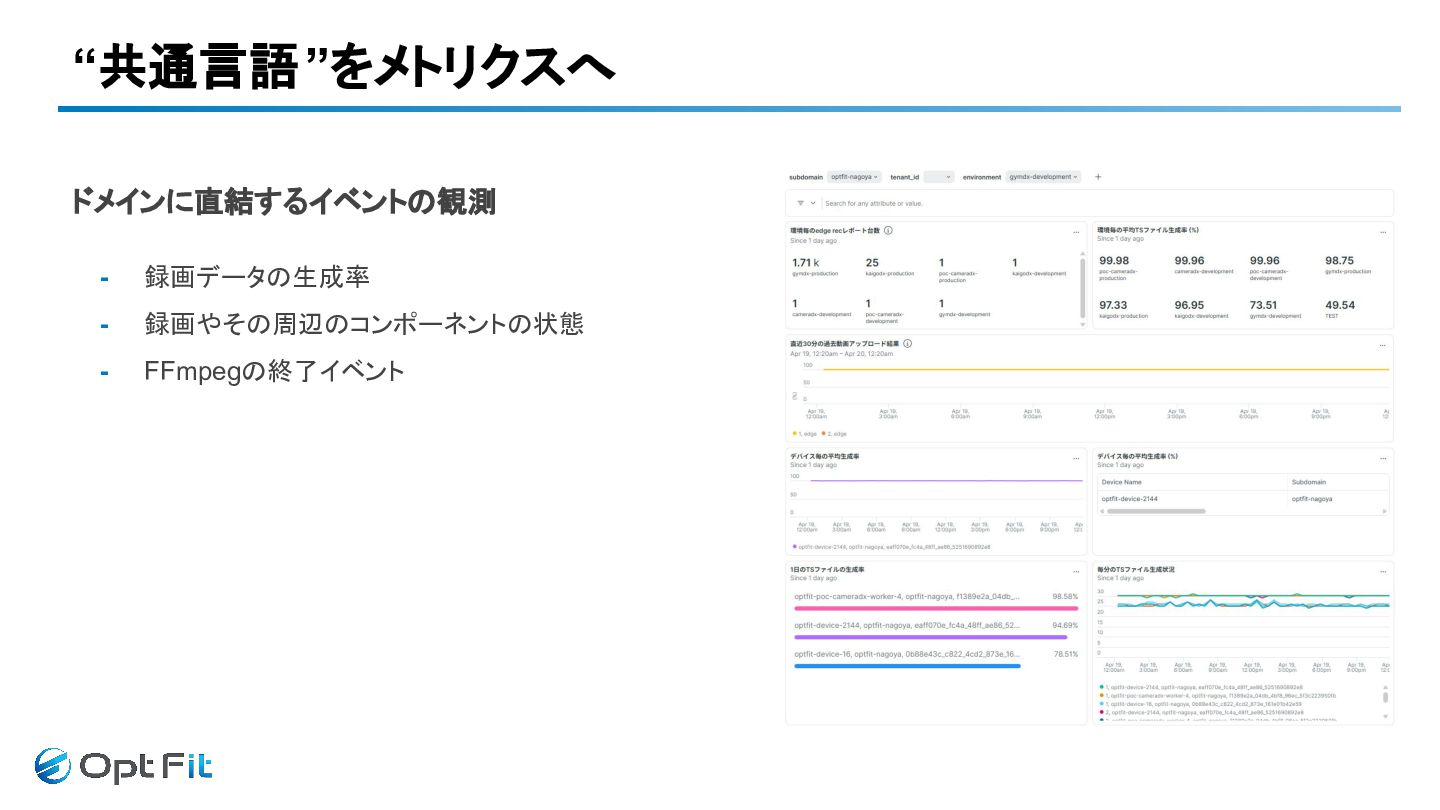
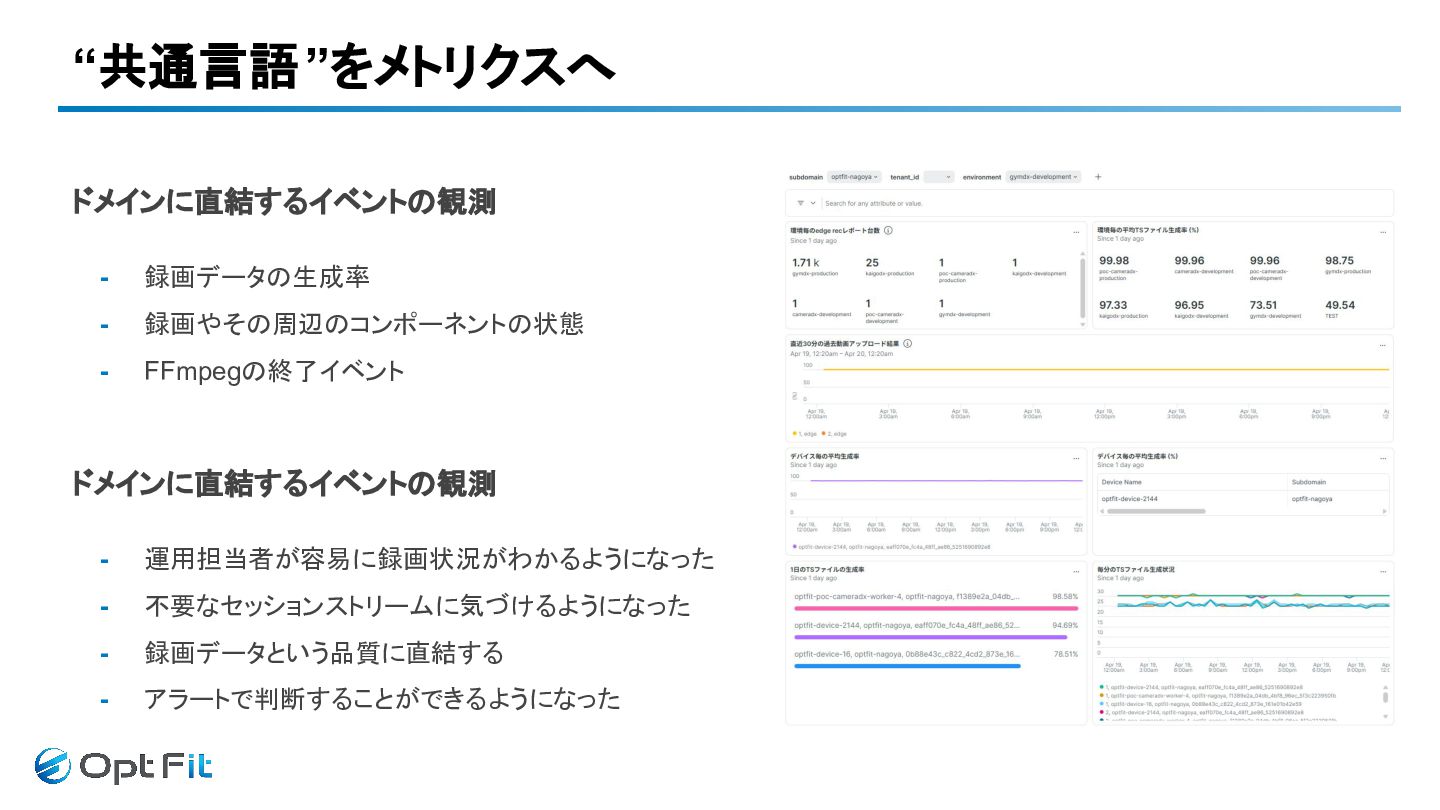
“共通言語”をメトリクスへ ドメインに直結するイベントの観測 - 録画データの生成率 - 録画やその周辺のコンポーネントの状態 - FFmpegの終了イベント
“共通言語”をメトリクスへ ドメインに直結するイベントの観測 - 録画データの生成率 - 録画やその周辺のコンポーネントの状態 - FFmpegの終了イベント ドメインに直結するイベントの観測 -
運用担当者が容易に録画状況がわかるようになった - 不要なセッションストリームに気づけるようになった - 録画データという品質に直結する - アラートで判断することができるようになった
夜間対応を減らすという設計へ
完璧な原因分析に頼らない 今まででは問題のあるデバイスに対し SSHをして原因調査を行ってから対処していた - 何が原因なのか? - Noisy Neighbor ? Network
issue? camera issue? - 人手の対応は 大規模障害にはつらい (スケールもしない) - 神スクリプトを作る始末... ログなどのテレメトリデータがNew Relicで分析できるようになった今、 原因調査や対応を自動化することにできた。
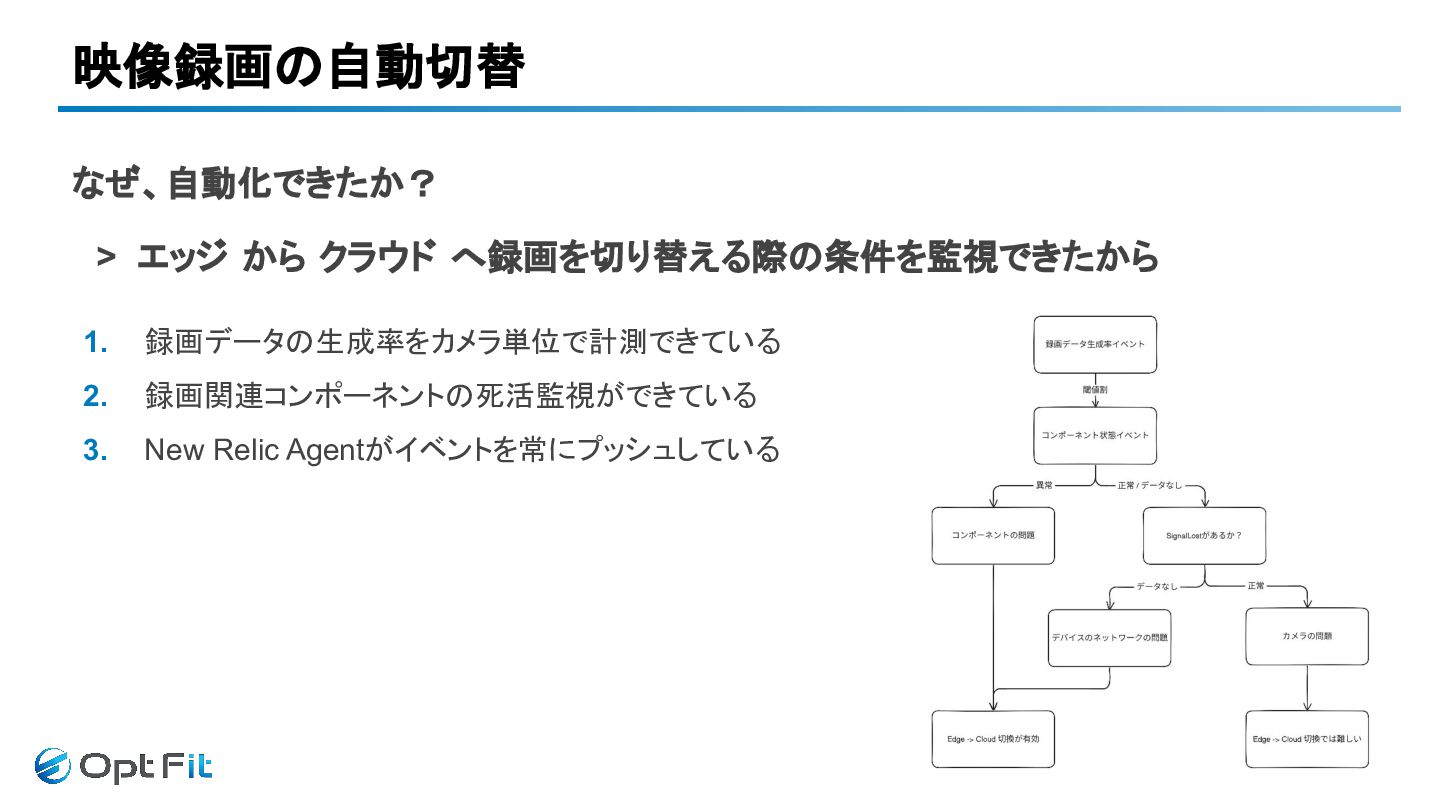
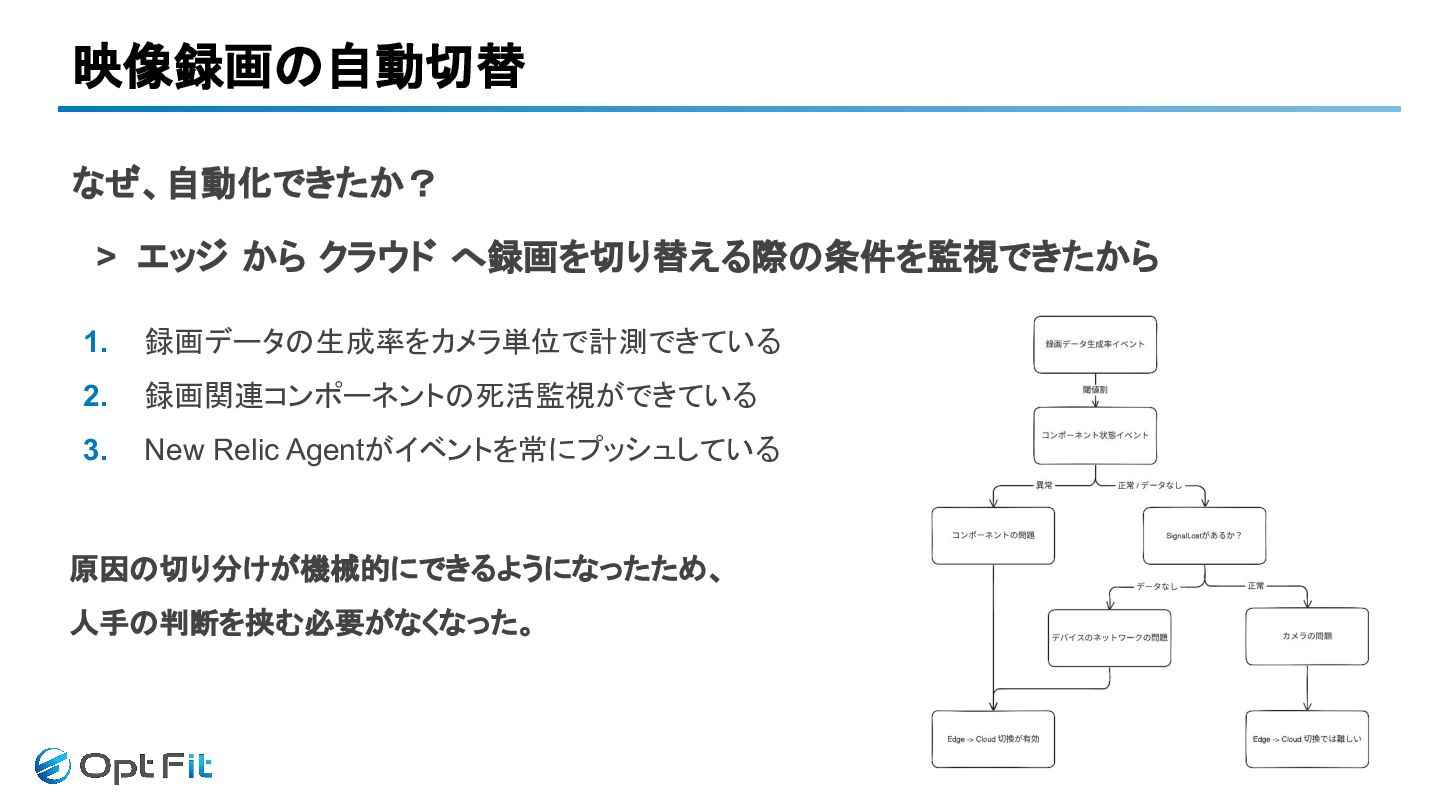
映像録画の自動切替 なぜ、自動化できたか? > エッジ から クラウド へ録画を切り替える際の条件を監視できたから
映像録画の自動切替 なぜ、自動化できたか? > エッジ から クラウド へ録画を切り替える際の条件を監視できたから 1. 録画データの生成率をカメラ単位で計測できている 2.
録画関連コンポーネントの死活監視ができている 3. New Relic Agentがイベントを常にプッシュしている
映像録画の自動切替 なぜ、自動化できたか? > エッジ から クラウド へ録画を切り替える際の条件を監視できたから 1. 録画データの生成率をカメラ単位で計測できている 2.
録画関連コンポーネントの死活監視ができている 3. New Relic Agentがイベントを常にプッシュしている 原因の切り分けが機械的にできるようになったため、 人手の判断を挟む必要がなくなった。
新しいエッジでデバイスの監視アーキテクチャ ① 録画コンポーネントに異常発生 !! ② アラート発火 ③ アラートの通知 ④自動切換えの実行
自動復旧によって変わった > 深夜 3時に特定テナントのデバイスが死亡 ...
自動復旧によって変わった > 深夜 3時に特定テナントのデバイスが死亡 ... Before : - エンジニアが朝3時にたたき起こされる -
Slackを確認 → 死亡を発見 - AWS コンソールから調査を開始、セキュアトンネルで SSHを行って実際のデバイスの状態を確認 - 手動でクラウド録画に移行 - (クラウドでも録画できない場合は手動で顧客連絡 )
自動復旧によって変わった > 深夜 3時に特定テナントのデバイスが死亡 ... After : - アラート 発火 → 切り替え自動実行
- (クラウドでも録画できない場合は自動で顧客連絡 ) Before : - エンジニアが朝3時にたたき起こされる - Slackを確認 → 死亡を発見 - AWS コンソールから調査を開始、セキュアトンネルで SSHを行って実際のデバイスの状態を確認 - 手動でクラウド録画に移行 - (クラウドでも録画できない場合は手動で顧客連絡 )
システム観測から開発運用が変わった Before After 通知数 20 万件 ~ / 月 ~
300件 / 月 MTTD (Mean Time To Detect ) ~ 12時間 ~ 5分 MTTC (Mean Time To Clue) ※ 20分 ~ 1時間 (すべて手動) ~ 10分 ※ https://www.splunk.com/ja_jp/blog/devops/key-metrics-for-devops-teams-dora-and-mttx.html
システム観測から開発運用が変わった - 1,700台以上のエッジデバイスを少人数で安定運用 - 夜間はぐっすり寝られるようになった。 - リリース頻度も爆上! Before After 通知数
20 万件 ~ / 月 ~ 300件 / 月 MTTD (Mean Time To Detect ) ~ 12時間 ~ 5分 MTTC (Mean Time To Clue) ※ 20分 ~ 1時間 (すべて手動) ~ 10分 ※ https://www.splunk.com/ja_jp/blog/devops/key-metrics-for-devops-teams-dora-and-mttx.html
まとめ 1. 不安定故に可観測性は最優先 - 静かに死んでも気づけるように - 死ぬ前のシグナルを逃さないように
まとめ 1. 不安定故に可観測性は最優先 - 静かに死んでも気づけるように - 死ぬ前のシグナルを逃さないように 2. システム間の共通言語は設計を容易にする -
動作環境にかかわらず、同じ指標で品質を語れる
まとめ 1. 不安定故に可観測性は最優先 - 静かに死んでも気づけるように - 死ぬ前のシグナルを逃さないように 2. システム間の共通言語は設計を容易にする -
動作環境にかかわらず、同じ指標で品質を語れる 3. 自動化で安眠は保たれた - エッジ関連のオンコールは激減 - 気持ちの良い朝を毎日迎えられるようになった。
宣伝!!
ZennやSpeaker Deckにて情報発信中 !! 興味あれば是非 Speaker Deck (過去登壇資料) Zenn (テックブログ)
一緒に働く仲間を募集しています !! 元気のいい人が大好きです - IoT開発エンジニア - ソフトウェアエンジニア - 機械学習エンジニア 応募タノム
~
👋おわり
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}