Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介_2_日本語語義曖昧性解消のための訓練データの自動拡張
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
MIKAMI-YUKI
May 18, 2015
Education
600
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
文献紹介_2_日本語語義曖昧性解消のための訓練データの自動拡張
MIKAMI-YUKI
May 18, 2015
More Decks by MIKAMI-YUKI
See All by MIKAMI-YUKI
2016年_年次大会_発表資料
mikamiy
0
140
文献紹介_10_意味的類似性と多義解消を用いた文書検索手法
mikamiy
0
350
文献紹介_9_コーパスに基づく動詞の多義解消
mikamiy
0
140
文献紹介_8_単語単位による日本語言語モデルの検討
mikamiy
0
100
文献紹介_7_自動獲得した未知語の読み・文脈情報による仮名漢字変換
mikamiy
0
120
文献紹介_6_複数の言語的特徴を用いた日本語述部の同義判定
mikamiy
0
120
文献紹介_5_マイクロブログにおける感情・コミュニケーション・動作タイプの推定に基づく顔文字の推薦
mikamiy
0
160
文献紹介_4_結合価パターンを用いた仮名漢字変換候補の選択
mikamiy
0
420
文献紹介_3_絵本のテキストを対象とした形態素解析
mikamiy
1
430
Other Decks in Education
See All in Education
プログラミング言語において文字列を複数行にわたって だらだらと記載するアレ
sapi_kawahara
0
180
「答えを出す」より「わかる」をつくる
kzkmaeda
1
230
吉祥寺.pmは1つじゃない — 複数イベント並走運営の12年 —
magnolia
0
1.3k
2026年度春学期 統計学 第9回 確からしさを記述する ー 確率 (2026. 5. 28)
akiraasano
PRO
0
150
[2026前期火5] 論理学(京都大学文学部 前期 第14回)「計算は、証明ではない——ハルシネーションを三層ハーモニーで診る」
yatabe
0
110
生成AI時代の情報発信
molmolken
0
140
Course Review - Lecture 13 - Next Generation User Interfaces (4018166FNR)
signer
PRO
0
2.3k
JAWS-UG初心者支部#81 GWにEduJAWSと何か作ろうもくもく会!
otsuki
0
150
Throw Yourself In! - How I've learned English and What I'm Facing
georgeorge
1
190
Course Review - Lecture 13 - Information Visualisation (4019538FNR)
signer
PRO
1
2.7k
Where Data Meets Storytelling
georgesinnott
0
130
自己紹介 / who-am-i
yasulab
6
7k
Featured
See All Featured
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
So, you think you're a good person
axbom
PRO
2
2.1k
Embracing the Ebb and Flow
colly
88
5.1k
Un-Boring Meetings
codingconduct
0
350
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.3k
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.4k
Noah Learner - AI + Me: how we built a GSC Bulk Export data pipeline
techseoconnect
PRO
0
220
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
1.2k
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
190
How to build a perfect <img>
jonoalderson
1
5.8k
The #1 spot is gone: here's how to win anyway
tamaranovitovic
3
1.1k
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.6k
Transcript
長岡技術科学大学 B4 三上侑城 文献紹介 2015年5月19日 日本語語義曖昧性解消の ための訓練データの自動拡張 自然言語処理研究室 1
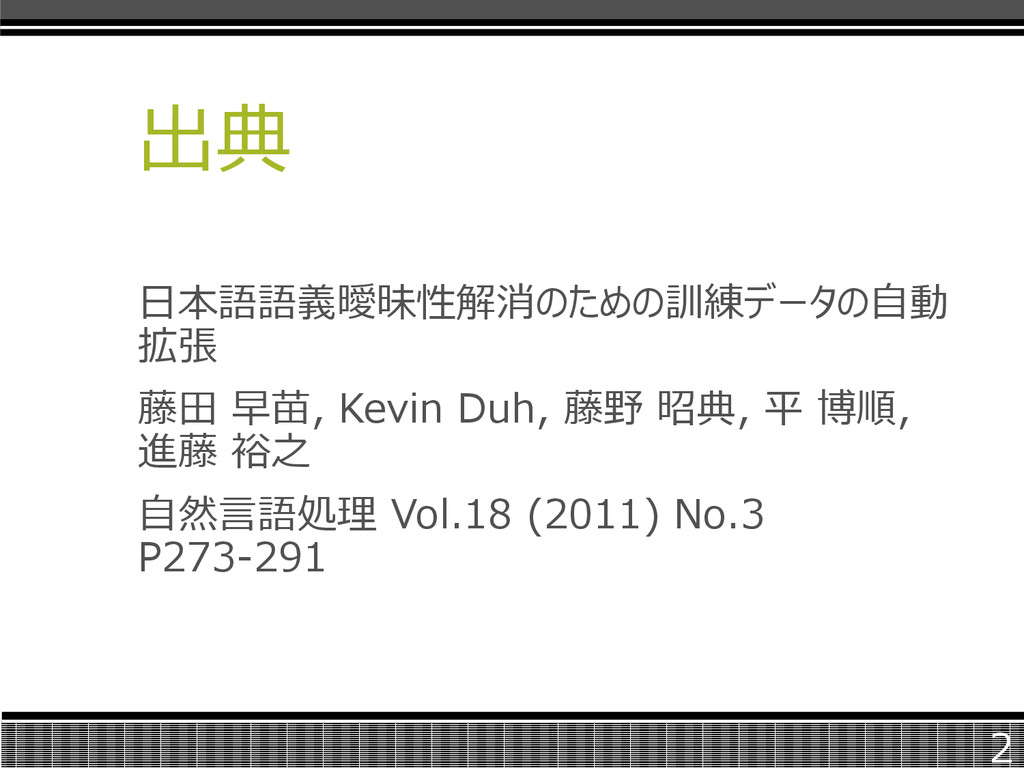
出典 日本語語義曖昧性解消のための訓練データの自動 拡張 藤田 早苗, Kevin Duh, 藤野 昭典, 平
博順, 進藤 裕之 自然言語処理 Vol.18 (2011) No.3 P273-291 2
概要 様々なコーパスを利用して、訓練データ の自動拡張を試みた。 訓練データの自動取得により79.5%の 精度を得ることが出来た。 更に、追加する訓練データの上限を制 御したところ、最高80.0%の精度が得ら れた。 3
語義曖昧性解消(WSD) 様々な手法が提案されてきたが、一般に 教師あり学習法による精度が高い。 そこで本稿でも教師あり学習法をベース として実験を行った。 4
語義曖昧性解消(WSD) 配布された訓練データは各対象語につき 50例ずつしかなく、未知語義も存在する。 このような未知語義は、訓練データのみ を用いた学習では推測できない。 本稿では、訓練データの自動取得による 精度向上を試みた。 5
訓練データの自動取得 定義文中から比較的抽出しやすい例文 に着目し、例文を用いた訓練データの獲 得を行う。 また、既存のコーパスの利用も考える。 6
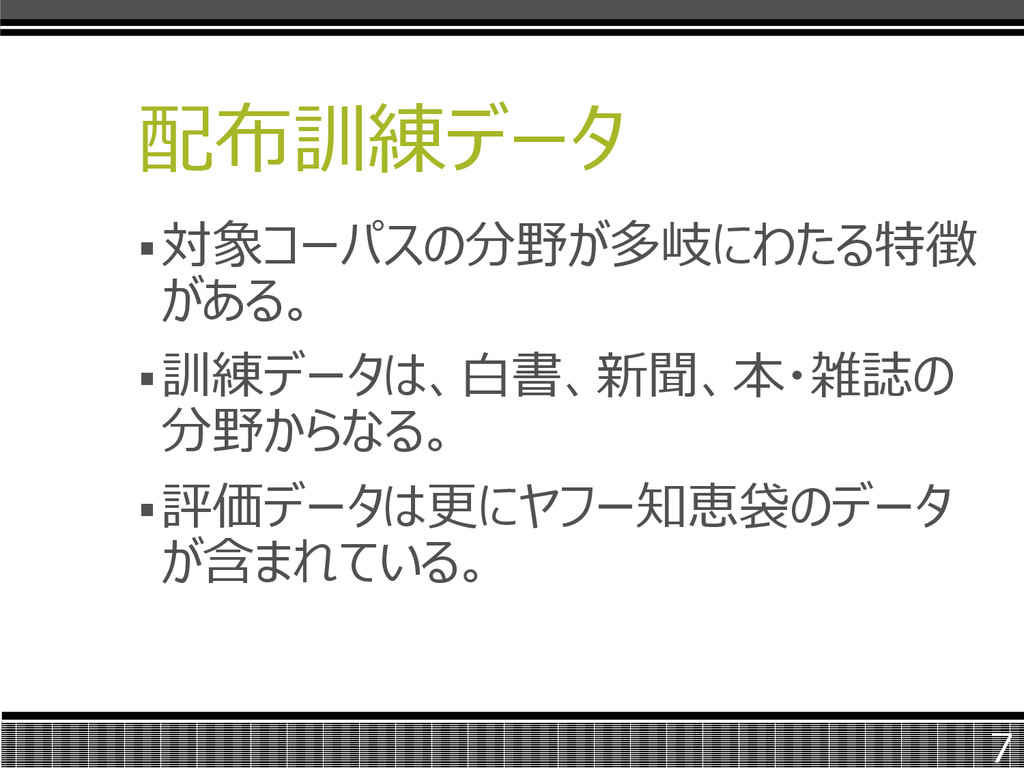
配布訓練データ 対象コーパスの分野が多岐にわたる特徴 がある。 訓練データは、白書、新聞、本・雑誌の 分野からなる。 評価データは更にヤフー知恵袋のデータ が含まれている。 7
配布訓練データ 本データには岩波国語辞典の語義を元 に語義IDが付与されている。 岩波国語辞典に定義されていない新語 義も付与されており、それらを推定するこ とも課題の一つ。 対象語は50語で、辞典に定義された語 義数は219となった。 8
岩波国語辞典の例 9
訓練データの例 10
岩波国語辞典の例文 例文を抽出するには、「」で囲まれた部分 を抽出し、“ー”の部分を見出し語にする。 こうして抽出した例文は形態素解析器 MecabのUniDicバージョンで解析する。 11
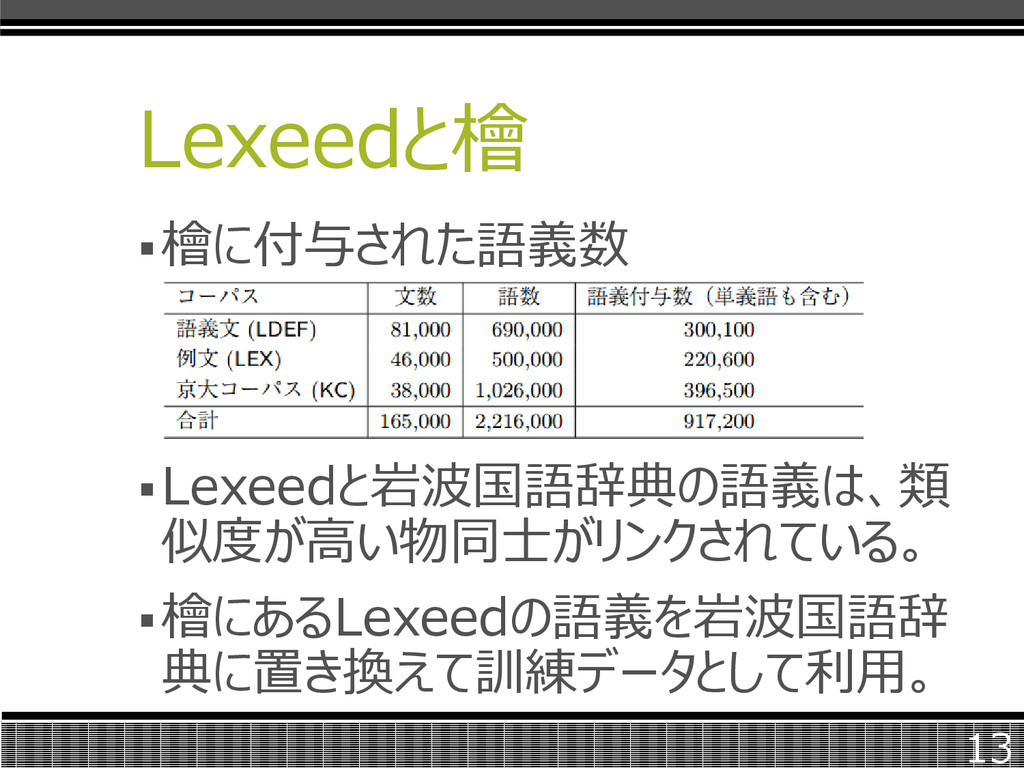
Lexeedと檜 言語資源として、更に基本語意味データ ベース「Lexeed」及び、センスバンク 「檜」を利用する。 Lexeedは日本人に最も馴染み深い 28270語が収録された辞書である。 Lexeedによって語義付与されたセンスバ ンクが「檜」である。 12
Lexeedと檜 檜に付与された語義数 Lexeedと岩波国語辞典の語義は、類 似度が高い物同士がリンクされている。 檜にあるLexeedの語義を岩波国語辞 典に置き換えて訓練データとして利用。 13
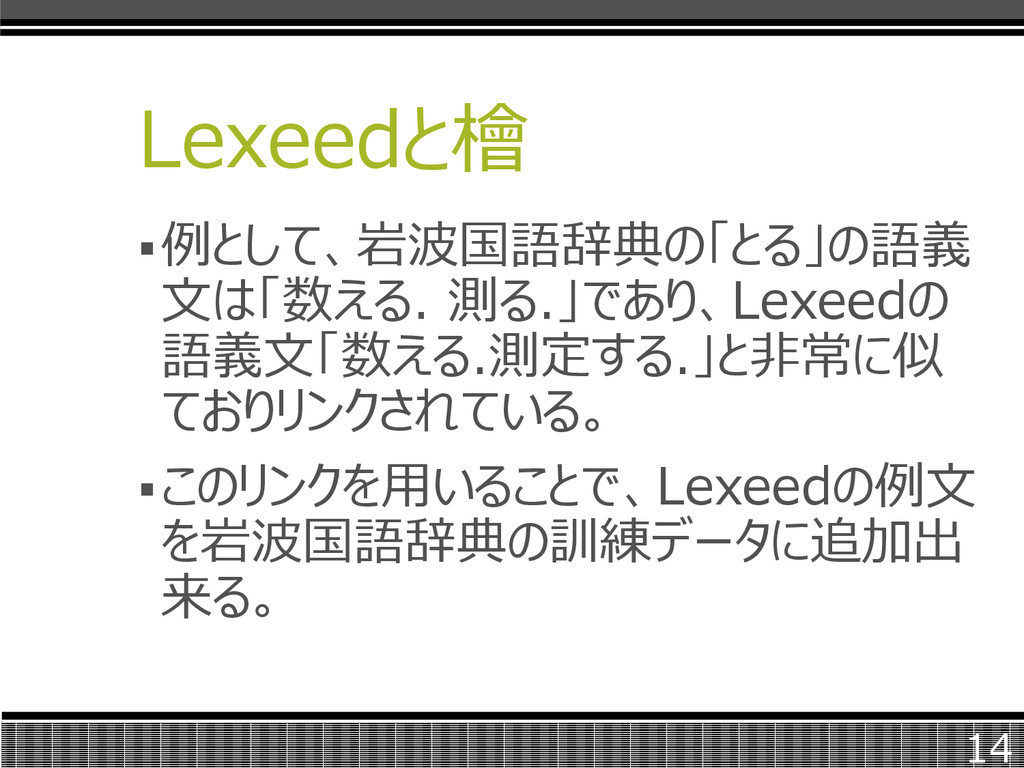
Lexeedと檜 例として、岩波国語辞典の「とる」の語義 文は「数える. 測る.」であり、Lexeedの 語義文「数える.測定する.」と非常に似 ておりリンクされている。 このリンクを用いることで、Lexeedの例文 を岩波国語辞典の訓練データに追加出 来る。 14
現代日本語書き言葉均衡コーパス 現代日本書き言葉均衡コーパス (BCCWJ)のデータから岩波国語辞典の 例文を利用し、訓練データを獲得する。 例文を完全に含む文を抽出し、形態素 解析を行い、該当する例文の語義IDを 付与する。 (例:「にとって」を含む文章) 15
未知語義数 辞書に定義された全語義は219語義だ が、評価データに出現する語義は、新語 義を除くと142語義となった。 16
獲得データサイズ 17
実験 学習器には最大エントロピーモデルを使 用した。これはSVMより精度が良かった ためである。 文章単位でトピック分類を行った。 18
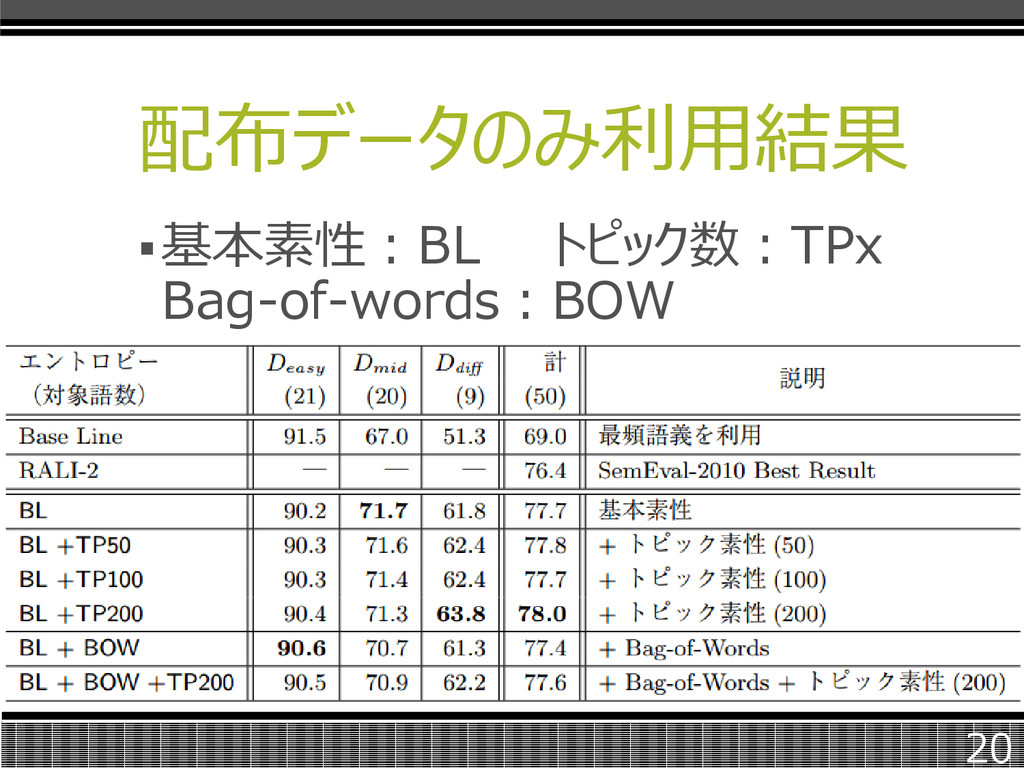
配布データのみ利用結果 対象語を難易度毎に分けて傾向を分析 した。高難易度:diff、中難易度:mid 低難易度:easy 19
配布データのみ利用結果 基本素性:BL トピック数:TPx Bag-of-words:BOW 20
自動取得も利用した結果 白書:OW , 本・雑誌:PB ヤフー知恵袋:OC 現代日本書き言葉均衡コーパス :BCCWJ 日本経済新聞:NIK , 毎日新:MAI
語義文:LD , 例文:LEX 京大コーパス:KC 21
自動取得も利用した結果 22
自動取得も利用した結果 難易度別に傾向が異なることがわかる。 低難易度の場合は、訓練データを追加 すると精度が低下傾向にある。しかし、 高難易度では精度が上昇傾向になる。 23
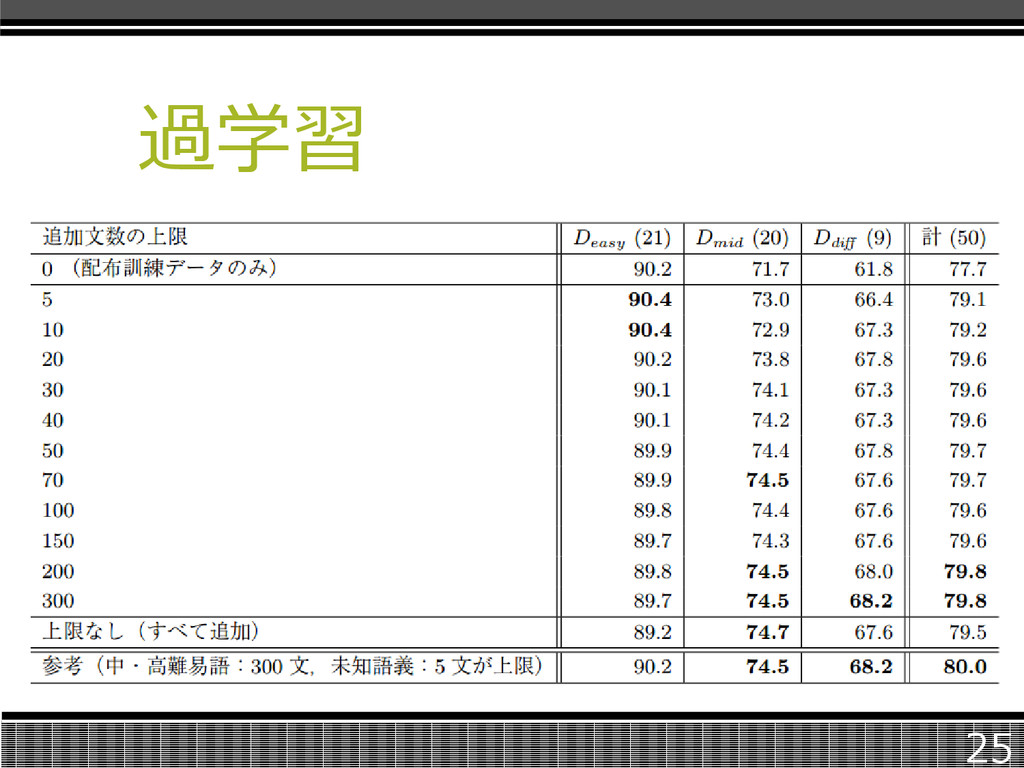
過学習 今までは各コーパスを可能な限り追加し て学習したが、過学習していないか調べ るために、追加する文字と精度の関連を 調べた。 24
過学習 25
過学習 難易度によって精度の上下がある。 低難易度では訓練データを追加するほど 精度が減少するが、高難易度では、訓 練データを追加するほど精度が向上した。 中・高難易度のものだけに上限を付けた 場合には全体精度が80%を超えた。 26
まとめ 訓練データの自動拡張によって語義曖昧 性解消の精度向上方法について述べた。 自動的に訓練データに追加し、精度向 上に寄与できることを示した。 難易度に基づいて分析した結果、低難 易度では訓練データを追加せず、中・高 難易度では追加した方が良い事が分った。 27
ご視聴ありがとうございました 28
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}