Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介_8_単語単位による日本語言語モデルの検討
Search
MIKAMI-YUKI
November 26, 2015
Education
100
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
文献紹介_8_単語単位による日本語言語モデルの検討
MIKAMI-YUKI
November 26, 2015
More Decks by MIKAMI-YUKI
See All by MIKAMI-YUKI
2016年_年次大会_発表資料
mikamiy
0
140
文献紹介_10_意味的類似性と多義解消を用いた文書検索手法
mikamiy
0
350
文献紹介_9_コーパスに基づく動詞の多義解消
mikamiy
0
140
文献紹介_7_自動獲得した未知語の読み・文脈情報による仮名漢字変換
mikamiy
0
120
文献紹介_6_複数の言語的特徴を用いた日本語述部の同義判定
mikamiy
0
120
文献紹介_5_マイクロブログにおける感情・コミュニケーション・動作タイプの推定に基づく顔文字の推薦
mikamiy
0
160
文献紹介_4_結合価パターンを用いた仮名漢字変換候補の選択
mikamiy
0
420
文献紹介_3_絵本のテキストを対象とした形態素解析
mikamiy
1
430
文献紹介_2_日本語語義曖昧性解消のための訓練データの自動拡張
mikamiy
0
600
Other Decks in Education
See All in Education
Case Studies and Future Research - Lecture 12 - Next Generation User Interfaces (4018166FNR)
signer
PRO
0
200
Course Review - Lecture 13 - Information Visualisation (4019538FNR)
signer
PRO
1
2.7k
2026年度春学期 統計学 第5回 分布をまとめるー記述統計量(平均・分散など) (2026. 5. 7)
akiraasano
PRO
0
210
Laura Wilson - The Quarterly PR Pivot
laurawilsonbseo1
1
370
DECADE_ゴルフ_コースマネジメント完全ガイド.pdf
ozekinote
0
120
データマネジメント試験対策教材1〜データマネジメント基礎〜
yoshimura_datam
1
470
Lectura 1 (PIT : Python Basico)
robintux
0
380
Catecismo 26 #1 - Aula inaugural
cm_manaus
0
210
[2026前期火5] 論理学(京都大学文学部 前期 第14回)「計算は、証明ではない——ハルシネーションを三層ハーモニーで診る」
yatabe
0
110
The Art & Science of Elearning
tmiket
1
240
新しいJavaを学んで・使っていこう! / osd26do
gishi_yama
0
180
【デザイナー就活講座】 デザイナー就活市場・企業探し・ポートフォリオのポイント
koheihasebe
0
280
Featured
See All Featured
The MySQL Ecosystem @ GitHub 2015
samlambert
251
13k
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
64
56k
Large-scale JavaScript Application Architecture
addyosmani
515
110k
Between Models and Reality
mayunak
4
370
sira's awesome portfolio website redesign presentation
elsirapls
0
300
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
Heart Work Chapter 1 - Part 1
lfama
PRO
8
36k
4 Signs Your Business is Dying
shpigford
187
22k
Docker and Python
trallard
47
4k
CSS Pre-Processors: Stylus, Less & Sass
bermonpainter
360
30k
Ten Tips & Tricks for a 🌱 transition
stuffmc
0
150
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.6k
Transcript
長岡技術科学大学 B4 三上侑城 文献紹介 2015年11月26日 単語単位による日本語 言語モデルの検討 自然言語処理研究室 1
出典 単語単位による日本語言語モデルの検討 伊東 伸泰, 西村 雅史 荻野 紫穂, 山崎 一考
自然言語処理 Vol. 6 (1999) No. 2 P9-27 2
概要 形態素は必ずしも人が認知している単 語単位や発音単位と一致しない。 人が潜在意識的にもつ単語単位の分 割モデルの言語モデルについて考察した。 約4万語で94~98%がカバーでき、形 態素に比べ12~19%語は少なくなった。 3
趣旨 音声認識を実現する際に、どのように認 識単位を採用するか問題となる。 従来では形態素を単位としてきたが、問 題点がいくつかある。 ・複合名詞などが1つの単語として登録 ・長い認識単位のほうが識別しやすい 4
単語単位への分割 日本語を分割して発声する場合、分割 点は安定している点・不安定な点がある。 発音単位では、安定的に「行って」だが、 「器」は分割されるかが不安定。 そこで人がある位置で「分割」される確率 を形態素レベルでモデル化する。 5
単語単位への分割 人手で分割したテキストと、形態素解析 したテキストを照合し、分割確率を得る。 その結果を用いることで、人が分割した 傾向を持ったテキストを容易に得られる。 6
単語単位への分割 7
文法の対応 近年、現代語書き言葉以外の表現に、 会話風の表現(口語体)を扱う試みが増 加してきた。 そこで、本研究では対応として、新聞など に限らず、パソコン通信の投稿テキストを 使用し、口語体を取得した。 8
複合名詞の分割 形態素解析辞書には、複合語が一語 扱いで登録されている事が多い。 しかし、単語分割モデル構築のための形 態素解析には短単語に分割されていた ほうが良い。 9
複合名詞の分割 そこで、複合語の中でも特に多い複合名 詞を分割対象にした。 2ヶ月分の新聞記事を形態素解析して、 一定以上の頻度で出現する3文字以 上の名詞を人手で分割した。 10
分割確率の推定 分割ルールとその確率を推定するために、 17人の被験者により、新聞5ヶ月分、日 本語用例集(26k文)、パソコン通信 (9.5k文)を分割する作業を行った。 11
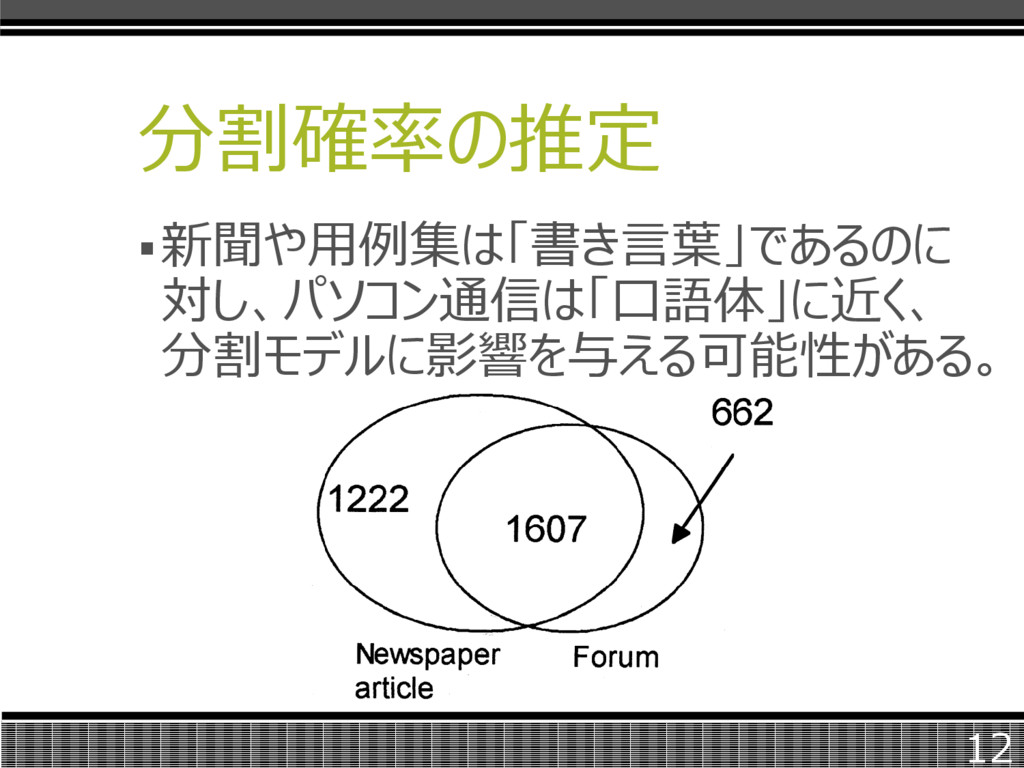
分割確率の推定 新聞や用例集は「書き言葉」であるのに 対し、パソコン通信は「口語体」に近く、 分割モデルに影響を与える可能性がある。 12
分割確率の推定 パソコン通信のみから得られた中で、出現 頻度の高いもの 明らかに口語体特有の言い回しに伴う遷 移が抽出された。 13
分割確率の推定 両方の確率木に共通して出現している 1607個については、分割確率の相関係 数を求めたところ0.980となり、共通する ノードはほとんど同じである。 これらのモデルに基づき、形態素解析され たテキストを分割・統合した。 14
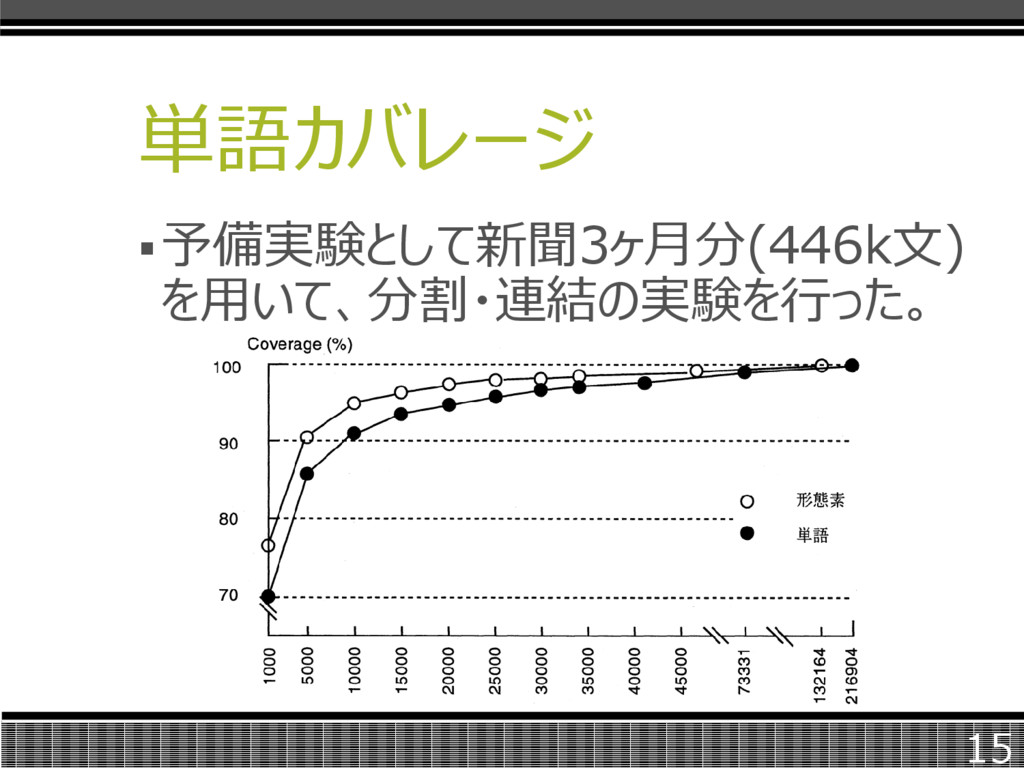
単語カバレージ 予備実験として新聞3ヶ月分(446k文) を用いて、分割・連結の実験を行った。 15
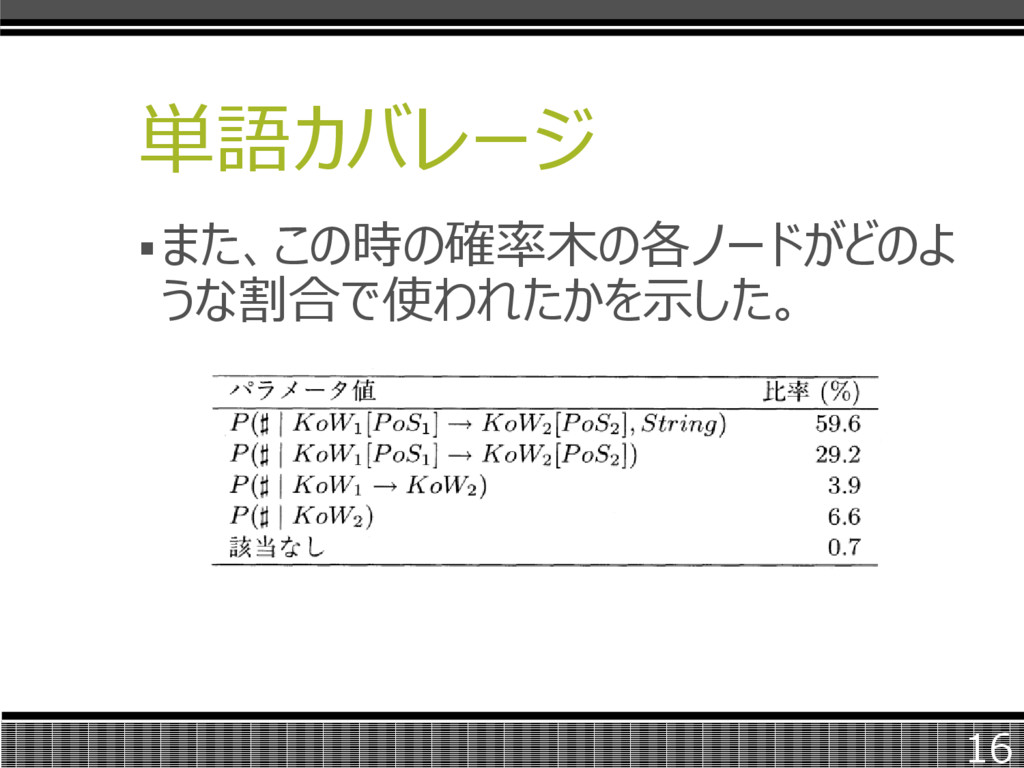
単語カバレージ また、この時の確率木の各ノードがどのよ うな割合で使われたかを示した。 16
コーパスの前処理 コーパスは日経新聞、産経新聞、毎日 新聞、EDRコーパス、パソコン通信 前処理として以下のことを行った。 ・数字をすべて桁付きの漢数字に変換 (例)23.45→「二十」「三」「・」「四」 ・絵文字や引用を除く (例)記号文字や「>>(引用)」など 17
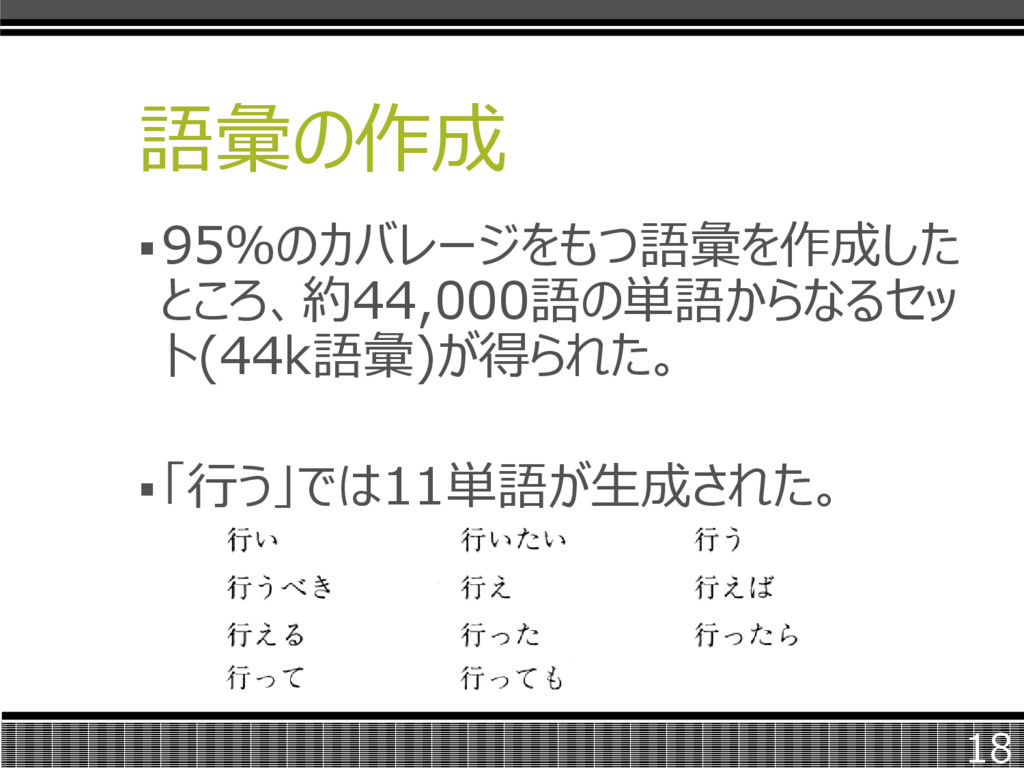
語彙の作成 95%のカバレージをもつ語彙を作成した ところ、約44,000語の単語からなるセッ ト(44k語彙)が得られた。 「行う」では11単語が生成された。 18
学習コーパス文の選択 学習コーパスに適さないものが含まれてお り、以下の条件の文は採用しないことに した。 ・2単語以下で構成される文 ・文の単語数に対する記号が一定以上 ・ 〃 に対する未知語が一定以上 19
学習コーパス文の選択 これらの選定を行った結果の各文の数を ソース別に示す。 20
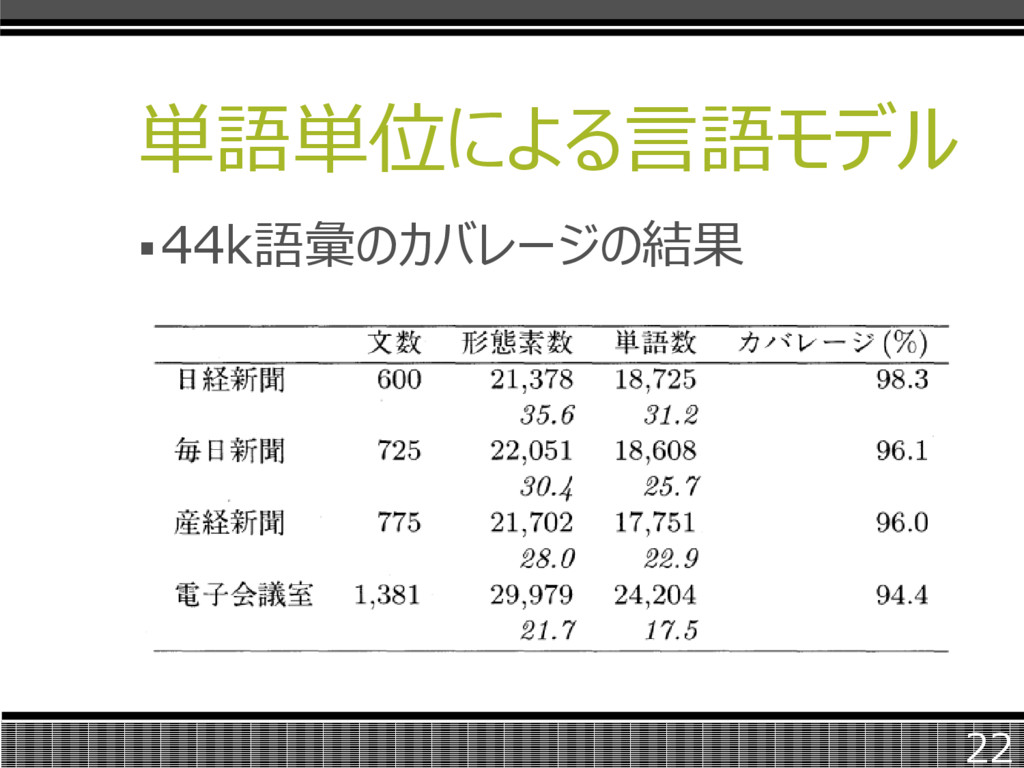
単語単位による言語モデル 特にパソコン通信に関して、表記揺れ (「コンピューター」と「コンピュータ」)が多数 存在したため、読みを元に約1800のリス トを作成した。 テストデータとして、新聞3種類、パソコン 通信のテキストを別に用意し、被験者 (先ほどと異なる人)が分割を行った。 21
単語単位による言語モデル 44k語彙のカバレージの結果 22
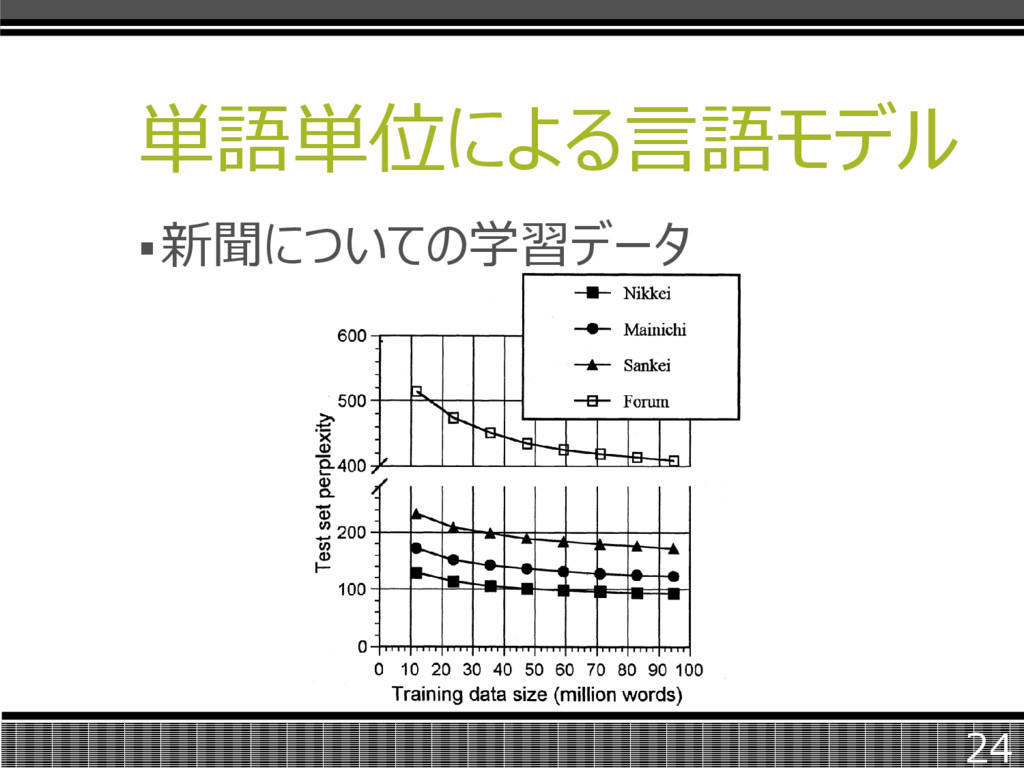
単語単位による言語モデル 新聞およびパソコン通信の学習データを 文単位で8個に分割したサブセットを作 成した。 各サブセットをさらに95%と5%の比で分 割し、前者をN-gramカウントに用いた。 23
単語単位による言語モデル 新聞についての学習データ 24
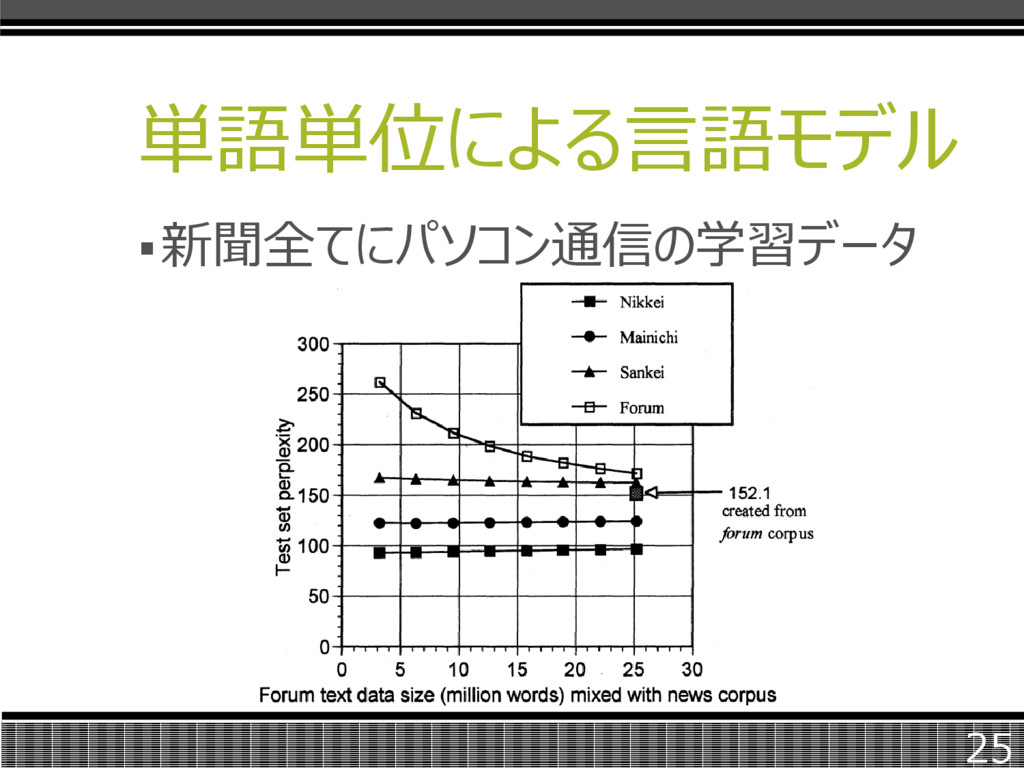
単語単位による言語モデル 新聞全てにパソコン通信の学習データ 25
まとめ 人が単語と意識する単位は約44kで 94~98%程度のカバレージが得られた。 形態素に比べて、1文あたりの要素数が 12~19%程度減少した。 新聞及びパソコン通信データを混合させ た言語モデルは双方に対応可能であった。 26
ご視聴ありがとうございました 27
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}