Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介_7_自動獲得した未知語の読み・文脈情報による仮名漢字変換
Search
MIKAMI-YUKI
October 29, 2015
Education
120
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
文献紹介_7_自動獲得した未知語の読み・文脈情報による仮名漢字変換
MIKAMI-YUKI
October 29, 2015
More Decks by MIKAMI-YUKI
See All by MIKAMI-YUKI
2016年_年次大会_発表資料
mikamiy
0
140
文献紹介_10_意味的類似性と多義解消を用いた文書検索手法
mikamiy
0
350
文献紹介_9_コーパスに基づく動詞の多義解消
mikamiy
0
140
文献紹介_8_単語単位による日本語言語モデルの検討
mikamiy
0
100
文献紹介_6_複数の言語的特徴を用いた日本語述部の同義判定
mikamiy
0
120
文献紹介_5_マイクロブログにおける感情・コミュニケーション・動作タイプの推定に基づく顔文字の推薦
mikamiy
0
160
文献紹介_4_結合価パターンを用いた仮名漢字変換候補の選択
mikamiy
0
420
文献紹介_3_絵本のテキストを対象とした形態素解析
mikamiy
1
430
文献紹介_2_日本語語義曖昧性解消のための訓練データの自動拡張
mikamiy
0
600
Other Decks in Education
See All in Education
2026年度春学期 統計学 第8回(オンデマンド配信回) 演習(1)・問題に対する答案の書き方 (2026. 5. 21)
akiraasano
PRO
0
150
2026年度春学期 統計学 第7回 データの関係を知る(2)ー 回帰と決定係数 (2026. 5. 21)
akiraasano
PRO
0
230
Throw Yourself In! - How I've learned English and What I'm Facing
georgeorge
1
190
Soluciones al examen de Geografía 2026. JUNIO (Convocatoria Ordinaria)
juanmartin2026
1
6.5k
モブ社員がモブエンジニアを名乗って得られたこと_20260413
masakiokuda
4
560
Examen de Selectividad. Geografía julio 2026 (Convocatoria Extraordinaria). UCLM
juanmartin2026
1
9.4k
Visionary Initiative: Materials-Positive Society — Evolving “Things,” empowering a positive society | Science Tokyo
sciencetokyo
PRO
0
140
Data Management and Analytics Specialisation
signer
PRO
0
1.9k
輻射安全管理系統2.0暨輻防e++學園平台說明會
aecrp
0
1.8k
AI時代に、 なぜ英語を勉強するのか
empelt
0
130
生成AI時代の情報発信
molmolken
0
140
!コスパよくインターンに受かる方法!
ruribou
1
300
Featured
See All Featured
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
Being A Developer After 40
akosma
91
590k
Become a Pro
speakerdeck
PRO
31
6k
Color Theory Basics | Prateek | Gurzu
gurzu
0
390
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
220
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
1
410
Unsuck your backbone
ammeep
672
58k
Abbi's Birthday
coloredviolet
3
8.7k
Believing is Seeing
oripsolob
1
170
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
620
From π to Pie charts
rasagy
0
240
Transcript
長岡技術科学大学 B4 三上侑城 文献紹介 2015年10月29日 自動獲得した未知語の読み・ 文脈情報による仮名漢字変換 自然言語処理研究室 1
出典 自動獲得した未知語の読み・ 文脈情報による仮名漢字変換 笹田 鉄郎, 森 信介, 河原 達也 自然言語処理
Vol. 17 (2010) No. 4 P131-153 2
概要 内容の類似したテキストと音声から未知 語の読み・文脈情報を取得し、仮名漢 字変換の精度向上に利用する。 実験では、取得した未知語の読み・文 脈情報を学習コーパスに用いたことで、 精度が向上することを確認した。 3
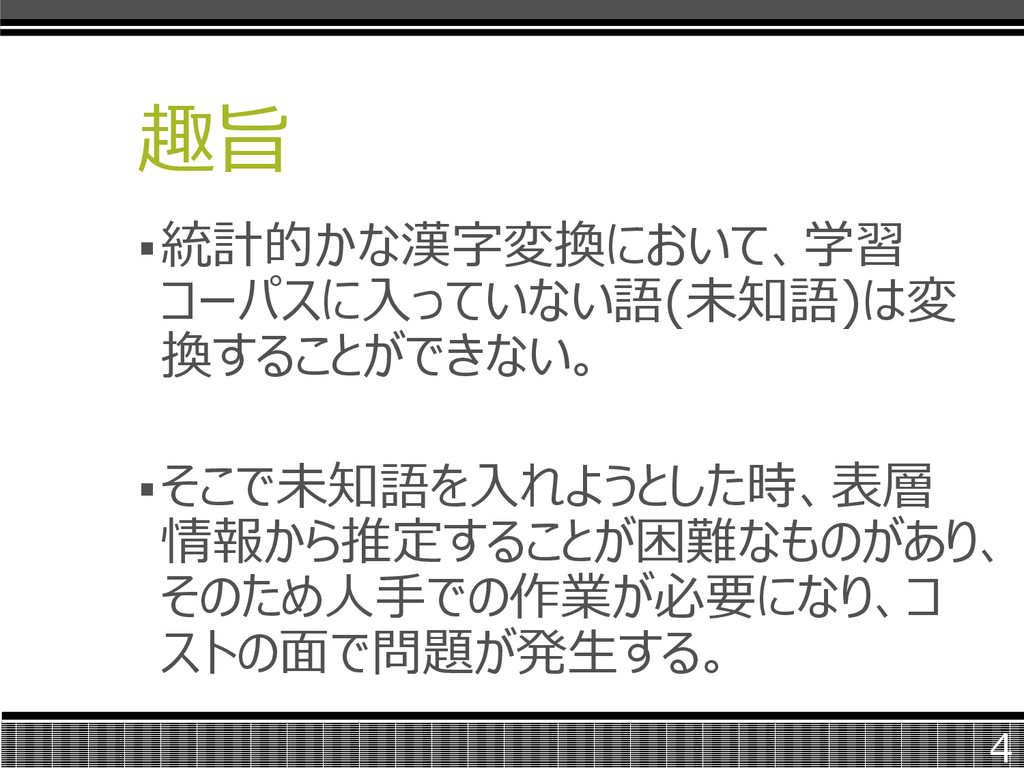
趣旨 統計的かな漢字変換において、学習 コーパスに入っていない語(未知語)は変 換することができない。 そこで未知語を入れようとした時、表層 情報から推定することが困難なものがあり、 そのため人手での作業が必要になり、コ ストの面で問題が発生する。 4
趣旨 そこで本論文では、テキストと内容の類 似した音声を認識することで、未知語の 読み・文脈情報を単語とその読みの組と して自動獲得させ、統計的かな漢字変 換の精度向上を目指した。 5
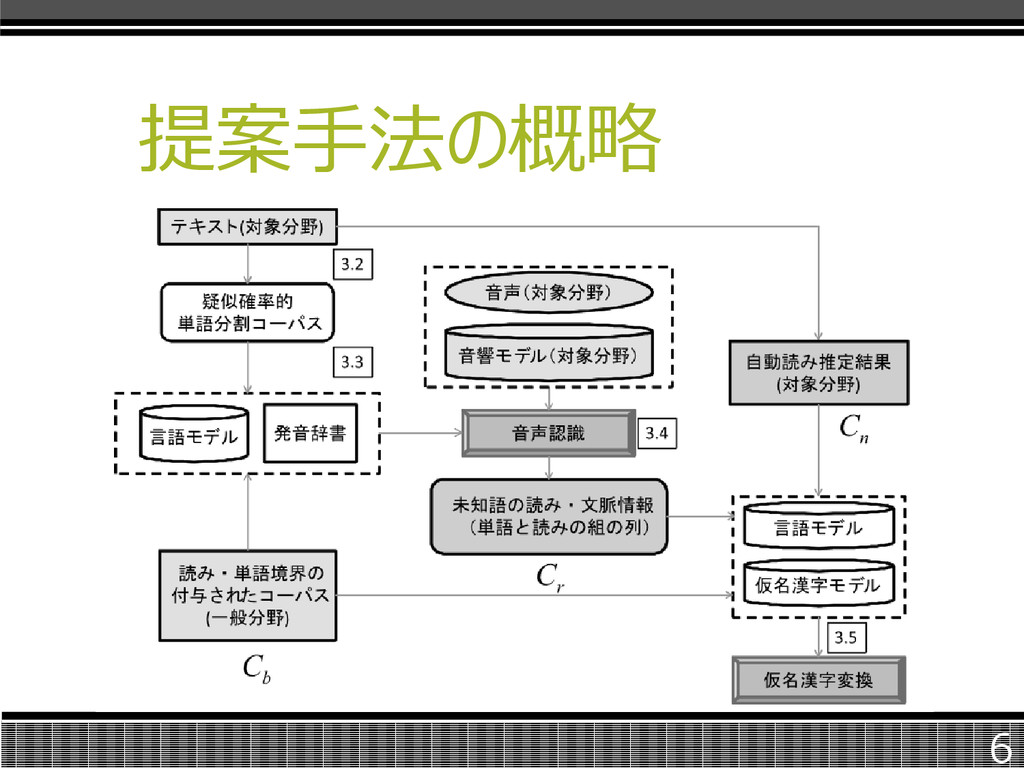
提案手法の概略 6
未知語候補の抽出 擬似確率的単語分割コーパスは、同様 の文であっても単語境界に揺れが存在 するため未知語の分割誤りを抑制可能。 揺れがあるため、低頻度の文字列は単 語として適切ではないものが多く、出現 頻度でしきい値を設定した。 7
未知語候補の抽出 単語分割コーパスから単語境界確率を 付与する。 単語境界確率を乱数を比較し、擬似確 率単語分割コーパスを作成。 8
言語モデルと発音辞書 音声認識システムを用いて未知語候補 を正しいよみとともに認識するには言語モ デルと発音辞書が必要。 言語モデルは擬似確率的単語分割コー パスを一般の単語分割コーパスに追懐す ることで構築する。 9
言語モデルと発音辞書 発音は複数の候補を用意し、その中から 推定していく。 n-gramモデルより単語表記から読みの 生成確率を計算する。 10
言語モデルと発音辞書 「守屋」の正しい読みは「モリヤ」であるが、 確率Pはここでは最大になっていない。 そのため、確率上位L個を候補とする。L は組み合わせの生成確率によって決まる。 11
文脈情報の獲得 信頼度を用いて単語の文脈上の妥当性 を判定する。 対象分野のテキストと同様の話題を扱っ た音声、音響モデルを用意し、先ほど得 られたデータを用いて音声認識を行った。 12
文脈情報の獲得 音声認識結果のうち、単語信頼度が CM以上単語を抽出し、連続する単語と その読みの列を形成する。 13
モデル構築 かな漢字変換のモデル性能を改善するに は、対象分野の学習コーパスを大量に用 意することが重要である。 文脈情報の獲得で得られた、未知語を 含む単語と読みの列をモデルに反映させ ることで、変換精度向上を目指す。 14
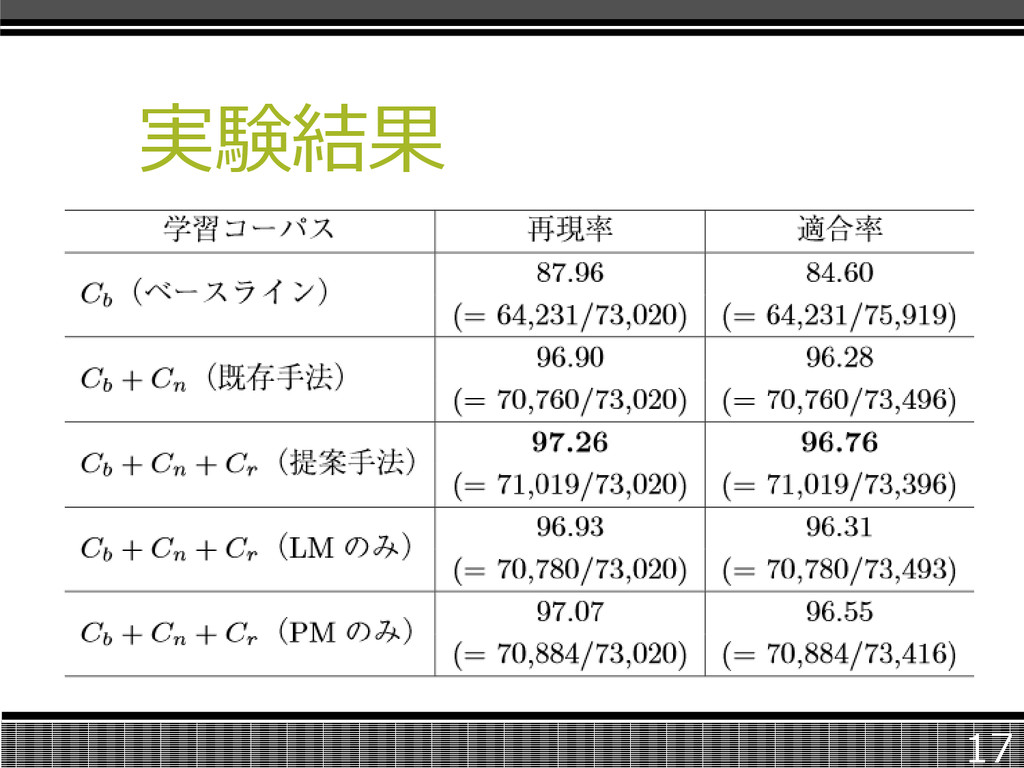
実験 実験は、一般分野のコーパスCb、対象 分野のテキストの自動読み推定結果Cn、 音声認識結果Crを用いた。 コーパスを以下のように組み合わせた。 15
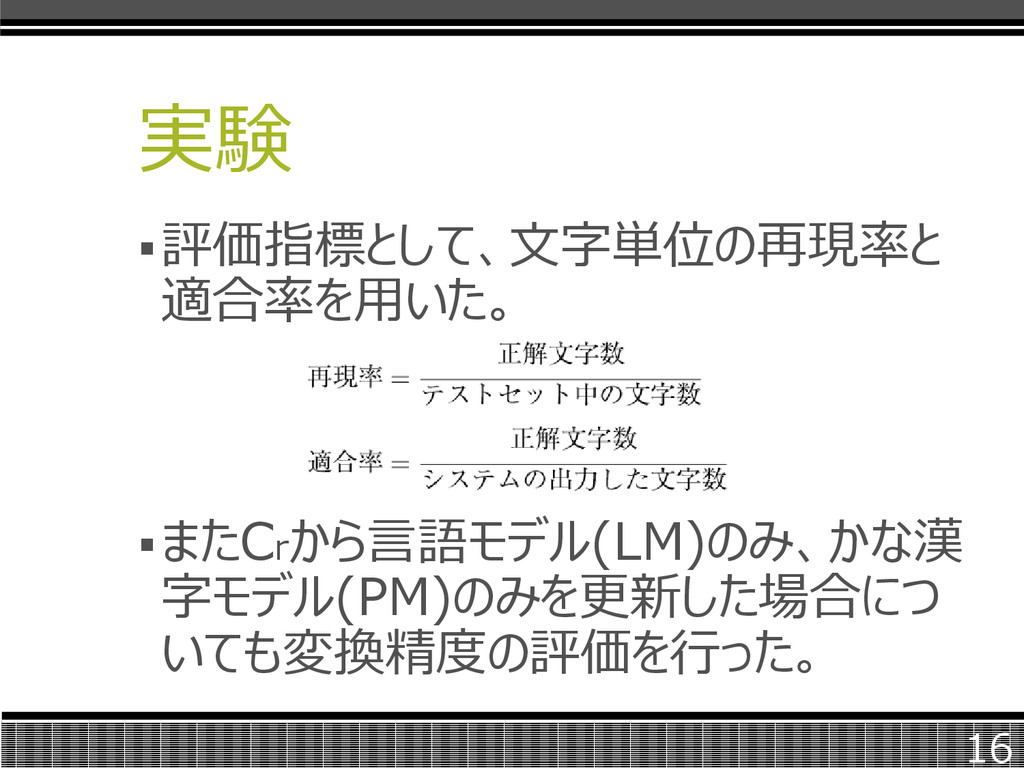
実験 評価指標として、文字単位の再現率と 適合率を用いた。 またCrから言語モデル(LM)のみ、かな漢 字モデル(PM)のみを更新した場合につ いても変換精度の評価を行った。 16
実験結果 17
まとめ テキストと音声から未知語の読み・文脈 情報を単語と読みの組として自動取得し、 統計的かな漢字変換の精度向上に利 用する手法を提案した。 音声認識から得られる単語と読みの組の 列を学習コーパスにすることで、システム 全体の精度が向上することを確認した。 18
ご視聴ありがとうございました 19
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}