Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介_9_コーパスに基づく動詞の多義解消
Search
MIKAMI-YUKI
December 24, 2015
Education
140
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
文献紹介_9_コーパスに基づく動詞の多義解消
MIKAMI-YUKI
December 24, 2015
More Decks by MIKAMI-YUKI
See All by MIKAMI-YUKI
2016年_年次大会_発表資料
mikamiy
0
140
文献紹介_10_意味的類似性と多義解消を用いた文書検索手法
mikamiy
0
350
文献紹介_8_単語単位による日本語言語モデルの検討
mikamiy
0
100
文献紹介_7_自動獲得した未知語の読み・文脈情報による仮名漢字変換
mikamiy
0
120
文献紹介_6_複数の言語的特徴を用いた日本語述部の同義判定
mikamiy
0
120
文献紹介_5_マイクロブログにおける感情・コミュニケーション・動作タイプの推定に基づく顔文字の推薦
mikamiy
0
160
文献紹介_4_結合価パターンを用いた仮名漢字変換候補の選択
mikamiy
0
420
文献紹介_3_絵本のテキストを対象とした形態素解析
mikamiy
1
430
文献紹介_2_日本語語義曖昧性解消のための訓練データの自動拡張
mikamiy
0
600
Other Decks in Education
See All in Education
プログラミング言語において文字列を複数行にわたって だらだらと記載するアレ
sapi_kawahara
0
180
モブ社員がモブエンジニアを名乗って得られたこと_20260413
masakiokuda
4
560
勾配ブースティングと決定木の話 / gradient boosting and decision trees
kaityo256
PRO
7
1.7k
Implicit and Cross-Device Interaction - Lecture 10 - Next Generation User Interfaces (4018166FNR)
signer
PRO
2
2.3k
教育現場から見た Ruby on Rails
yasslab
PRO
0
210
[2026前期火5] 論理学(京都大学文学部 前期 第6回)「かつとまたはの規則」
yatabe
0
430
AI時代に、 なぜ英語を勉強するのか
empelt
0
130
Catecismo 26 #2 - Do Credo; Introdução ao 1º artigo
cm_manaus
0
160
[2026前期火5] 論理学(京都大学文学部 前期 第12回)「証明を走らせる:カリー・ハワード対応」
yatabe
0
210
LinkedIn
matleenalaakso
0
4.4k
면접관 눈에 띄는 데이터 분석 포트폴리오 만드는 법 | 2026년 5월 세미나
datarian
0
900
[2026前期火5] 論理学(京都大学文学部 前期 第8回)「正規化定理の証明」
yatabe
0
240
Featured
See All Featured
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
360
Faster Mobile Websites
deanohume
310
32k
The SEO Collaboration Effect
kristinabergwall1
1
510
The Cult of Friendly URLs
andyhume
79
6.9k
Agile Actions for Facilitating Distributed Teams - ADO2019
mkilby
0
220
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
470
Building Flexible Design Systems
yeseniaperezcruz
330
40k
Groundhog Day: Seeking Process in Gaming for Health
codingconduct
0
250
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
Agile that works and the tools we love
rasmusluckow
331
22k
Gemini Prompt Engineering: Practical Techniques for Tangible AI Outcomes
mfonobong
2
460
Everyday Curiosity
cassininazir
0
260
Transcript
長岡技術科学大学 B4 三上侑城 文献紹介 2015年12月24日 コーパスに基づく動詞の 多義解消 自然言語処理研究室 1
出典 コーパスに基づく動詞の多義解消 福本 文代, 辻井 潤一 自然言語処理 Vol. 4 (1997)
No. 2 P21-39 2
概要 言語処理における問題の一つに、言語 に関する様々な曖昧性の問題がある。 動詞の語義情報を利用し、文中に含ま れる多義語の曖昧性を解消する。 本手法では71.1%の正解率が得られた。 3
情報の抽出 意味的に近い動詞は同じ名詞と共起し て出現する。 s1,s1’ においてtakeとbuyはstakeと 共起して現れ、ほぼ同じ意味をもつ。 4
情報の抽出 s1,s2両方に表れるtakeは多義語であ り、動詞buy, spendと共起して表れる 名詞stake, timeと特徴付けができる。 多義語の動詞を含む文において、意味 を特徴づける名詞があれば、動詞の意 味を同定することができる。 5
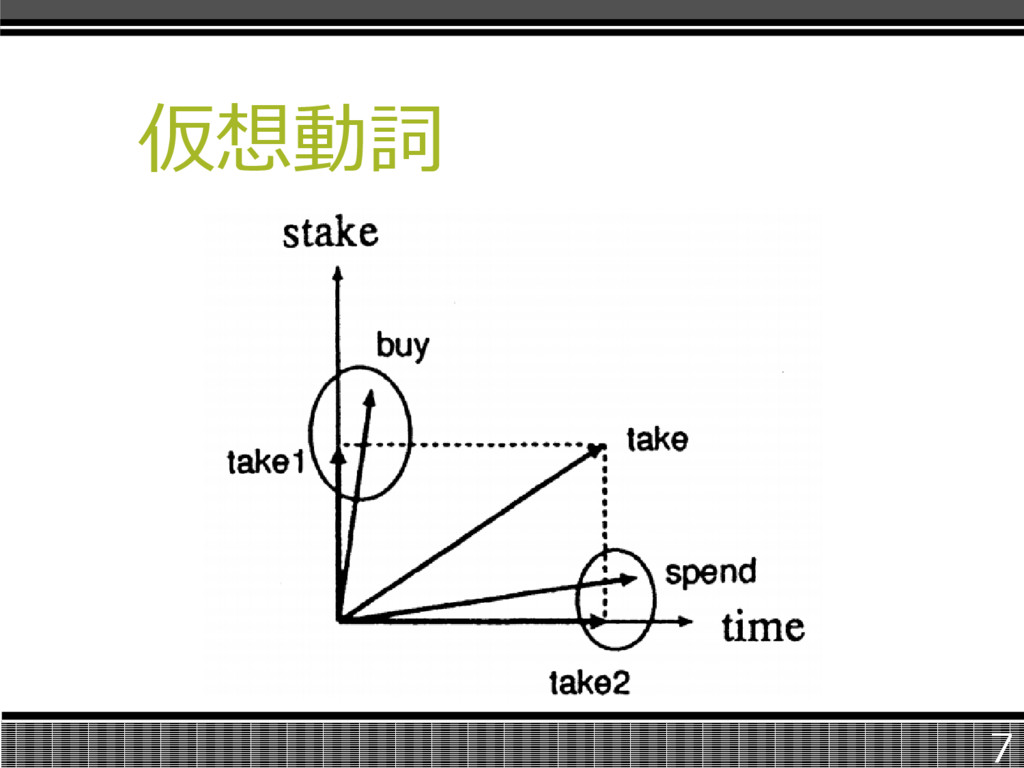
仮想動詞 多義語の意味を特徴づける名詞の集合 を抽出する。 多義語に対し、一つ一つの意味に対応 させた要素(仮想動詞ベクトル)に分解し、 クラスタを生成。 6
仮想動詞 7
クラスタリング手法 手法として、overlappingクラスタリング アルゴリズムを使用した。 手法として例えば、takeがbuyとspend の意味を持つかどうかを判断するために、 {take1, buy}と{take2,spend}の偏 差を比較して決定する。 8
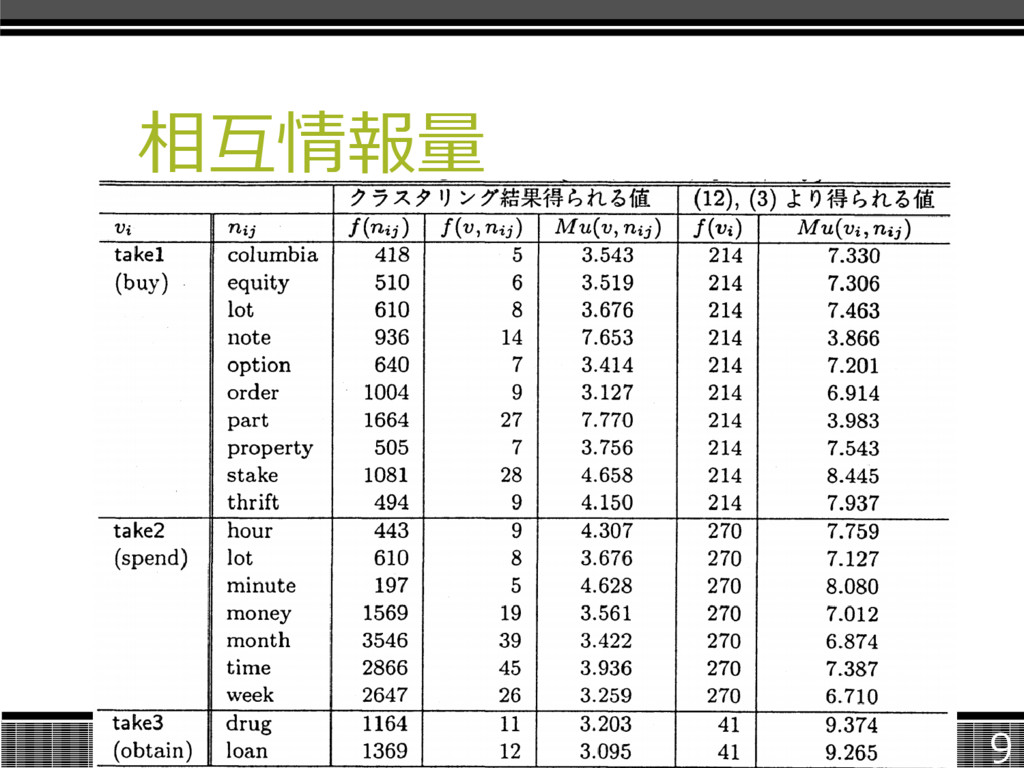
相互情報量 9
相互情報量 クラスタリングの結果から得られたこのテー ブルをpvnテーブルと呼ぶ。 複数の集合に属する名詞は、相互情報 量が一番大きい値の仮想動詞とする。 10
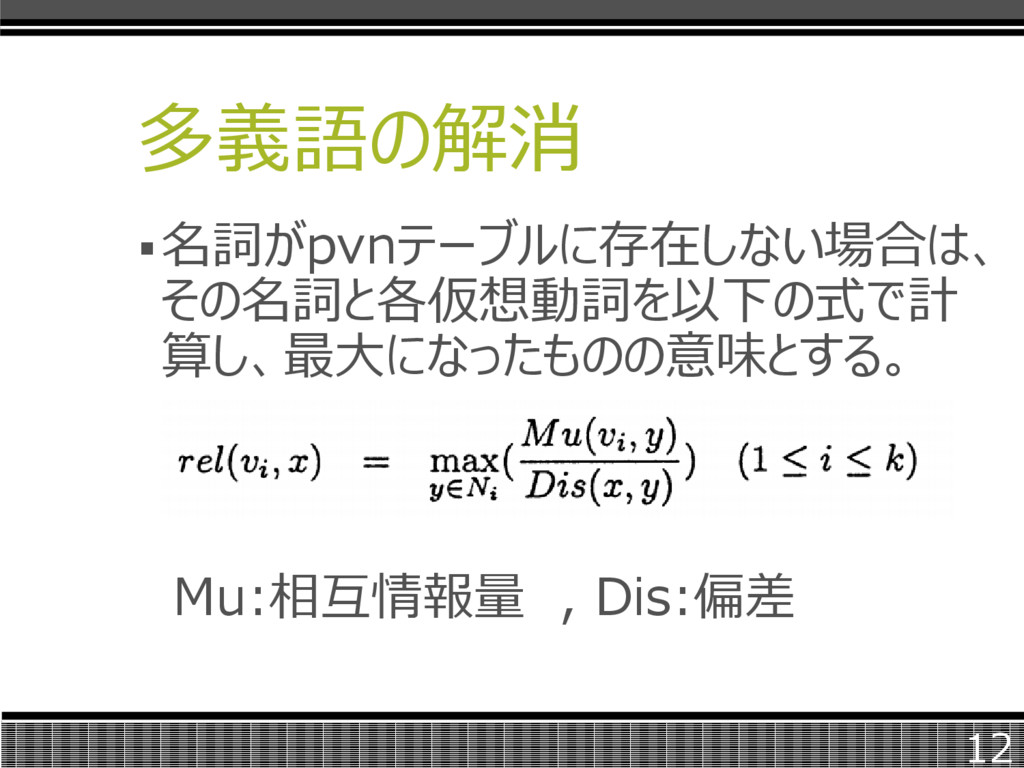
多義語の解消 多義語の後方5字以内に出現する名 詞がpvnテーブルに存在するときに、その 仮想動詞の意味とする。 2つ以上存在する場合は、相互情報量 が一番高いものをその意味とする。 11
多義語の解消 名詞がpvnテーブルに存在しない場合は、 その名詞と各仮想動詞を以下の式で計 算し、最大になったものの意味とする。 Mu:相互情報量 , Dis:偏差 12
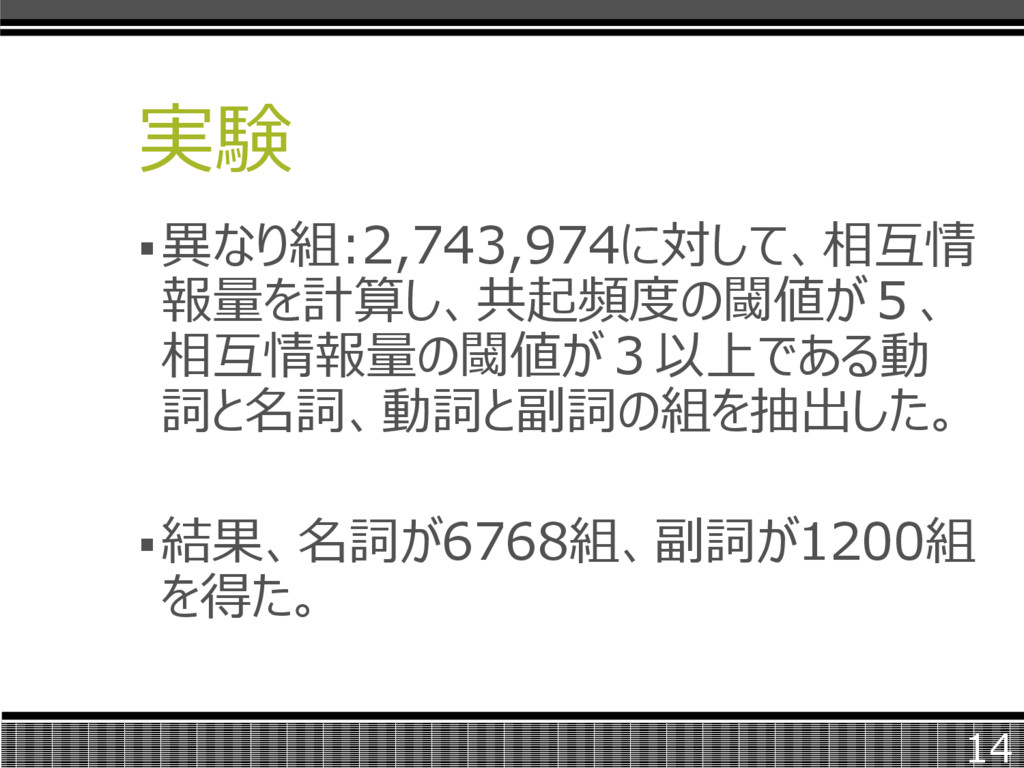
実験 コーパスはタグ付けされたWall Street Journal(182,992文)を使用した。 そこから動詞と名詞の組を5,940,193 組(異なり組:2,743,974)を取得した。 13
実験 異なり組:2,743,974に対して、相互情 報量を計算し、共起頻度の閾値が5、 相互情報量の閾値が3以上である動 詞と名詞、動詞と副詞の組を抽出した。 結果、名詞が6768組、副詞が1200組 を得た。 14
実験 実験にはその中から、14種類の多義語 を用い、テスト文として、各多義語に対し てランダムに100文、合計1,400文を抽 出した。 この中で、人間が一意に決定できないも のは除き、1,226文を対象に実験を行っ た。 15
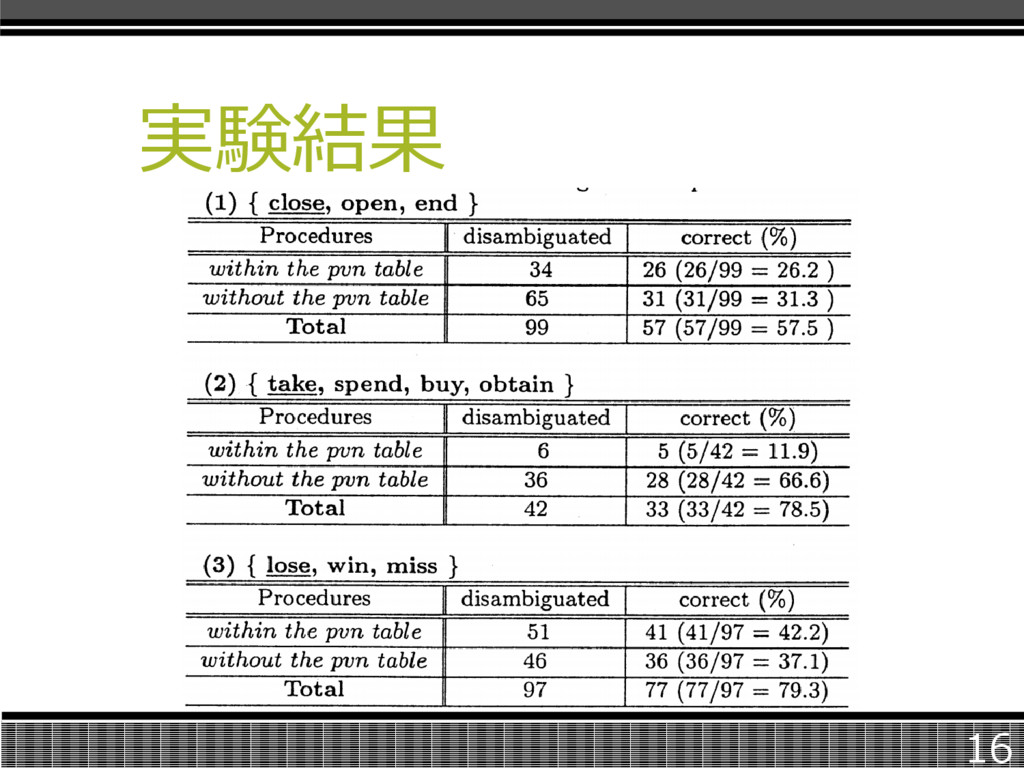
実験結果 16
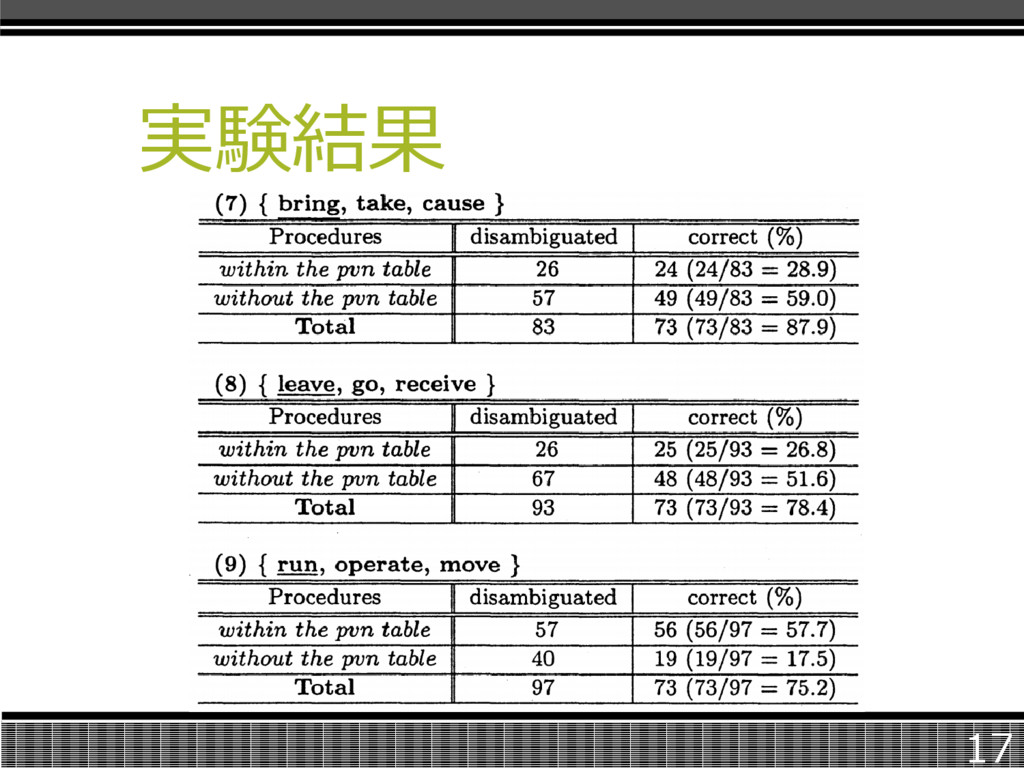
実験結果 17
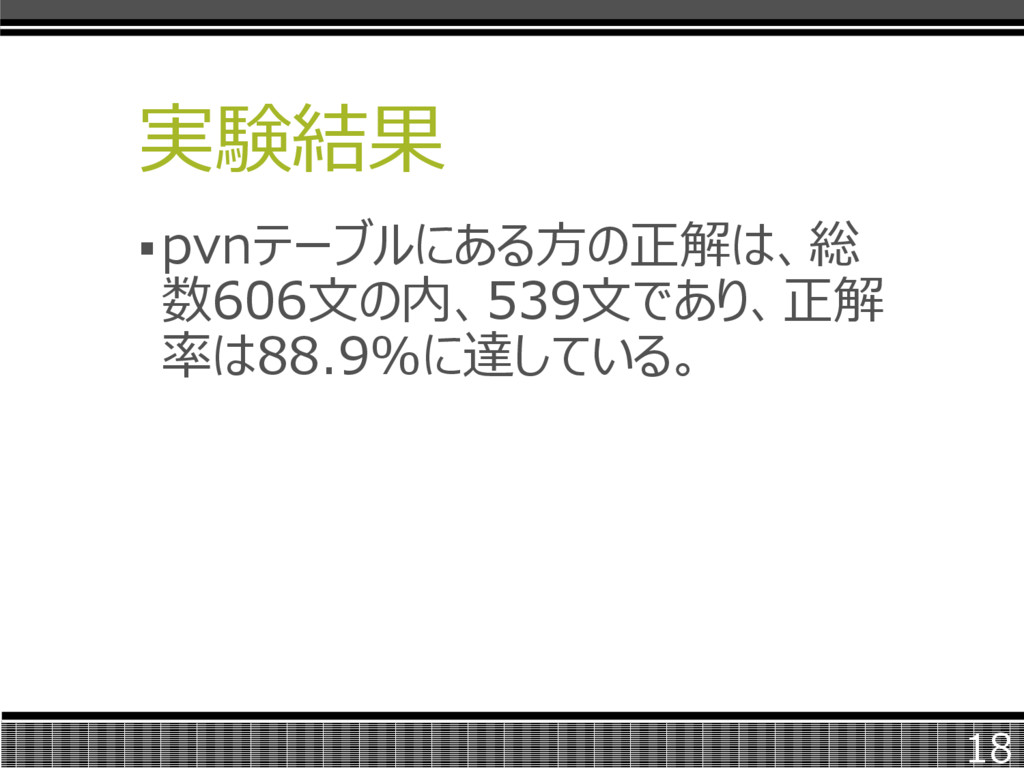
実験結果 18 pvnテーブルにある方の正解は、総 数606文の内、539文であり、正解 率は88.9%に達している。
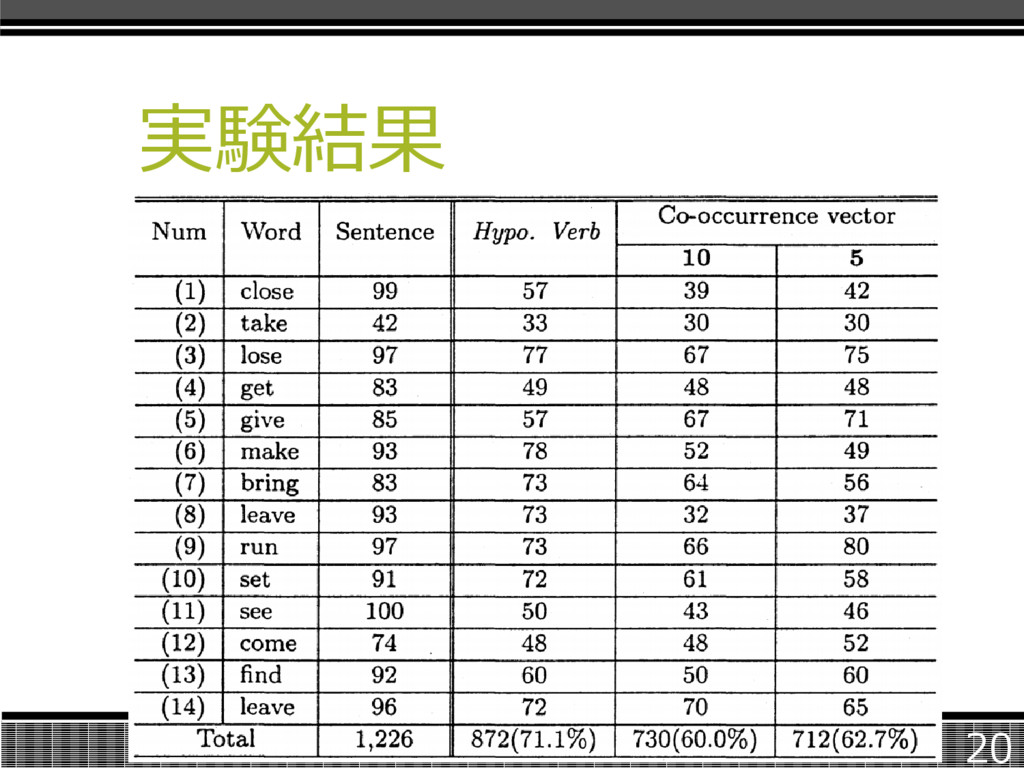
実験(他手法との比較) 既存の手法であった、文脈ベクトルを用 いた名詞の多義解消手法を動詞に適 用した結果と比較した。 文脈サイズ(対象語の前後何語を文脈 としたか)には5語と10語を用いた。 19
実験結果 20
まとめ コーパスから抽出した動詞の語義情報を 利用し、曖昧性を解消する手法を提案。 14種類の多義語動詞1226文に対し、 71.1%の正解率が得られた。 pvnテーブルにあるもののみの場合では 88.9%の正解率が得られた。 21
ご視聴ありがとうございました 22
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}