Presented at MongoDC 2012
A short interactive session, working through 3 problem scenarios, and the possible diagnosis methods, and root cause analysis.
• Client read timeout set • Connection closed/discarded • Symptom not cause • Server connection exceptions • Match timing of client timeouts • Symptom not cause
• Load testing would have found this early • MongoDB depends on the OS a lot • Connect the dots from disproportionate effects • Using blockdev, be aware of layering!
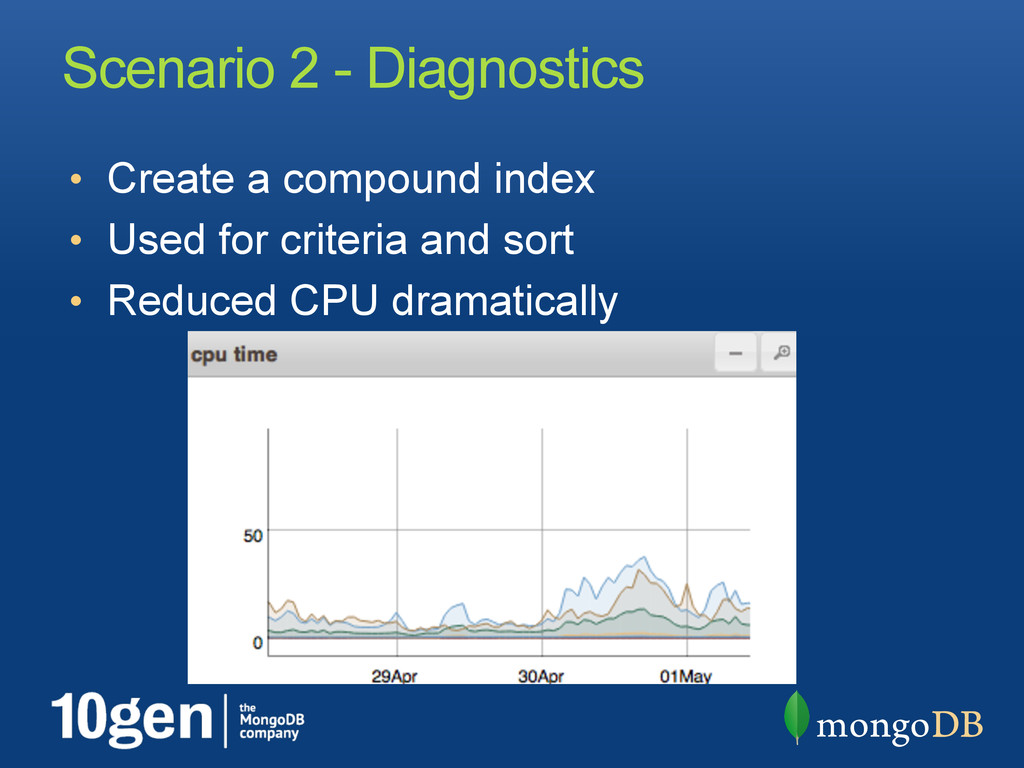
app code, generate metrics • Run .explain() • Database Profiler • Plan/test rollouts • Rolling upgrade for Replica Sets • Generate indexes on Secondaries first • Use DNS, not IPs
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}