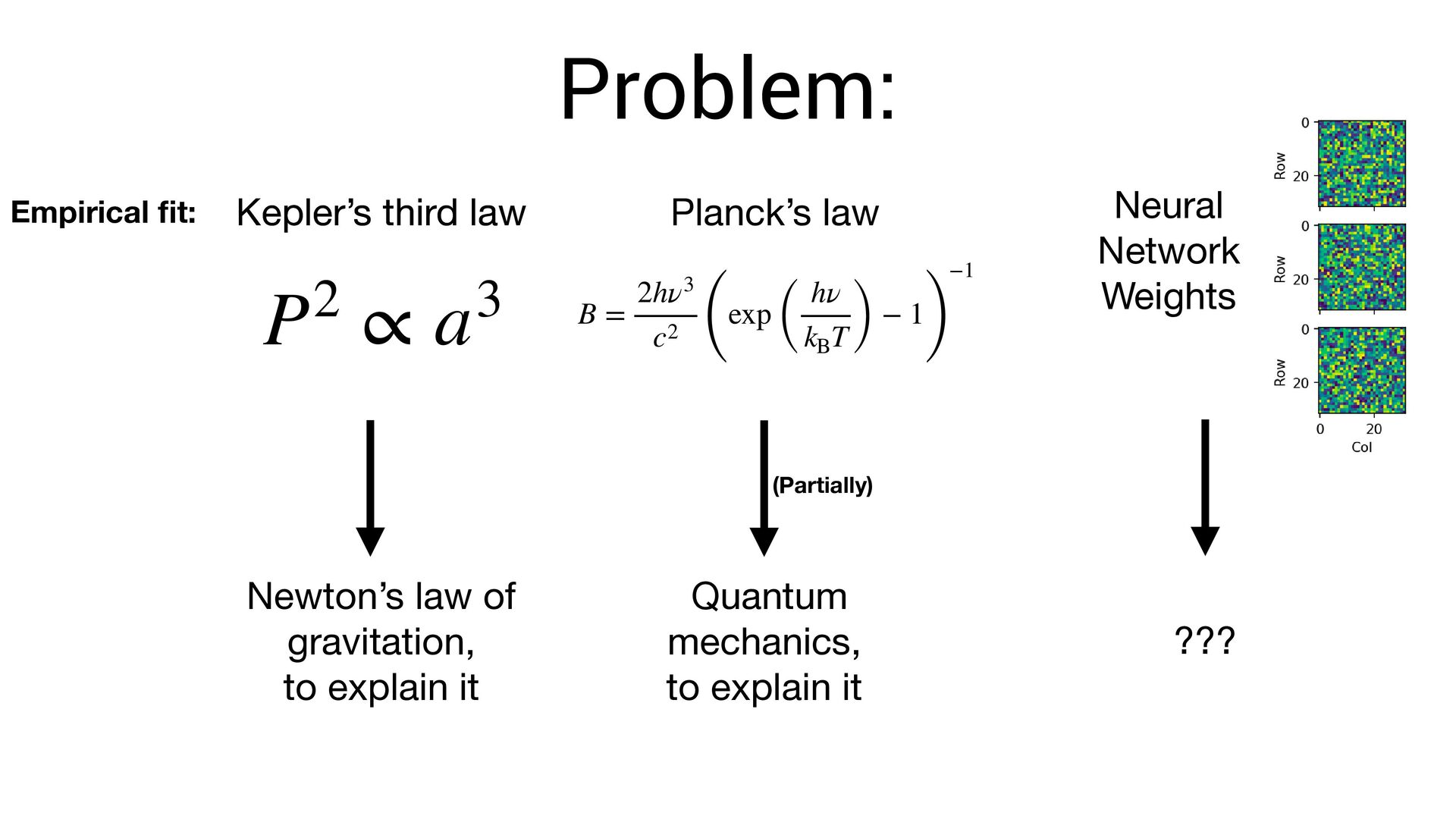
to explain it Kepler’s third law Planck’s law B = 2hν3 c2 ( exp ( hν kB T) − 1 ) −1 Empirical fi t: Quantum mechanics, to explain it (Partially) Problem:
to explain it Kepler’s third law Planck’s law B = 2hν3 c2 ( exp ( hν kB T) − 1 ) −1 Empirical fi t: Neural Network Weights Quantum mechanics, to explain it (Partially) Problem:
to explain it Kepler’s third law Planck’s law B = 2hν3 c2 ( exp ( hν kB T) − 1 ) −1 Empirical fi t: Neural Network Weights ??? Quantum mechanics, to explain it (Partially) Problem:
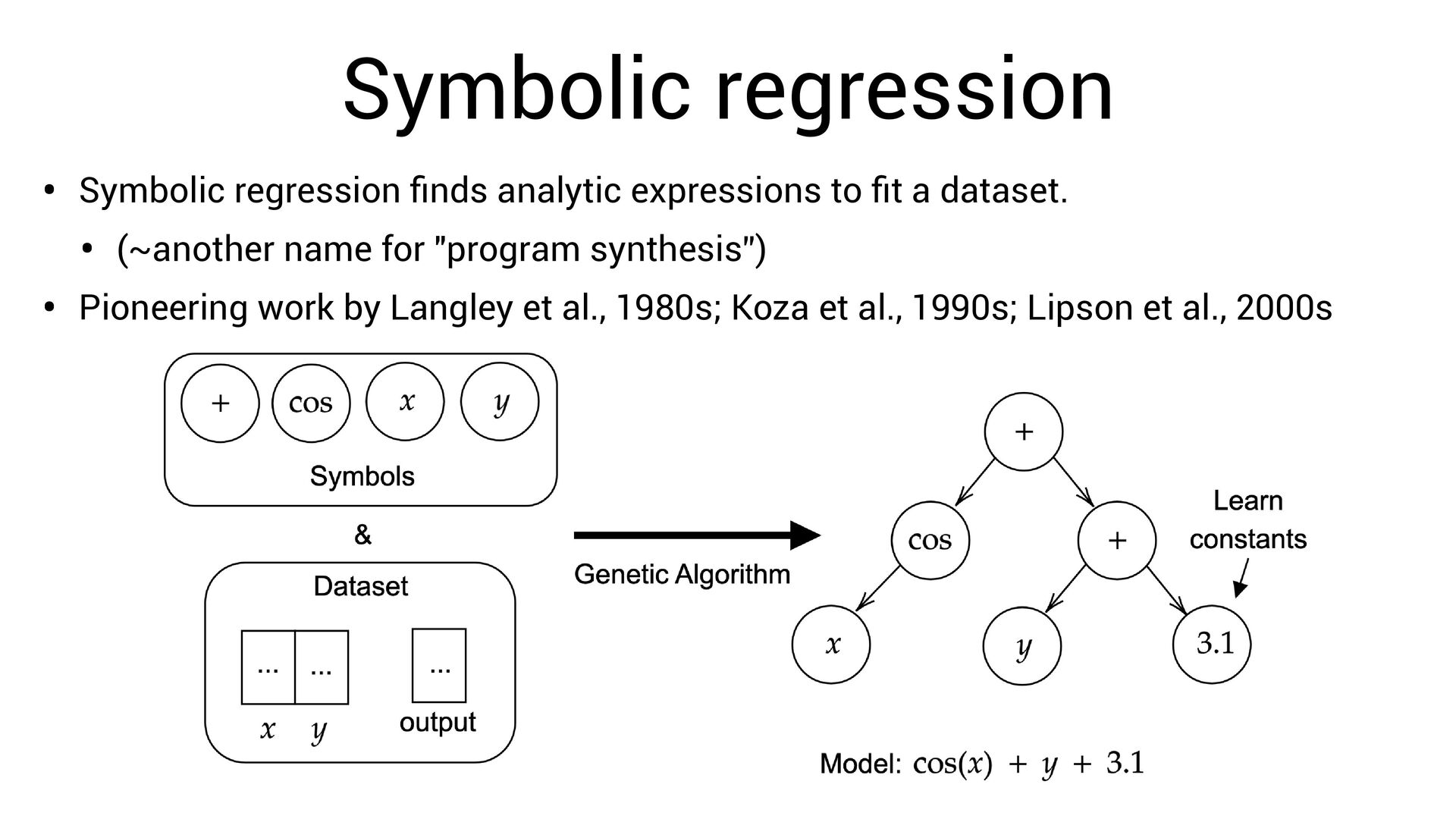
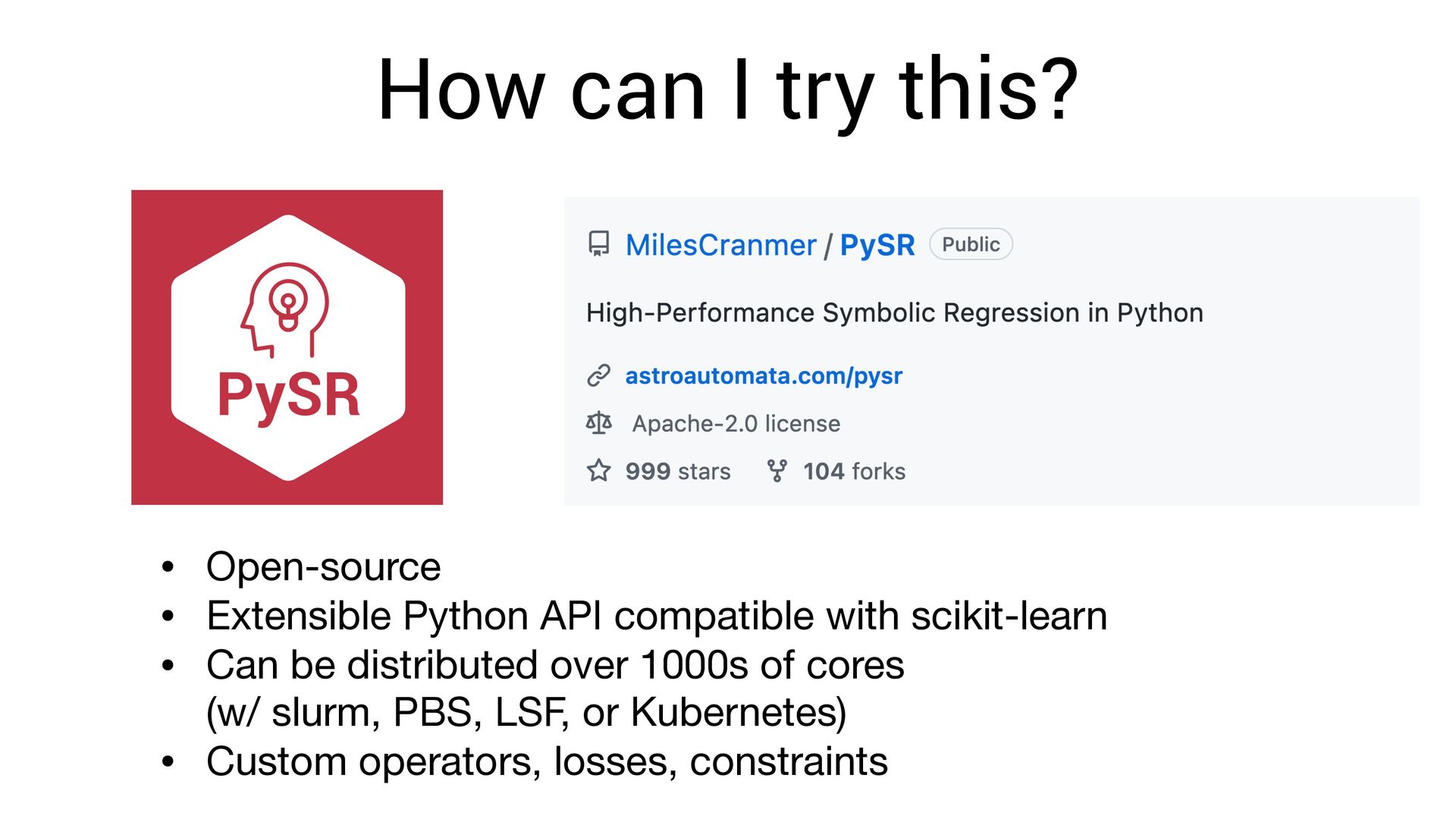
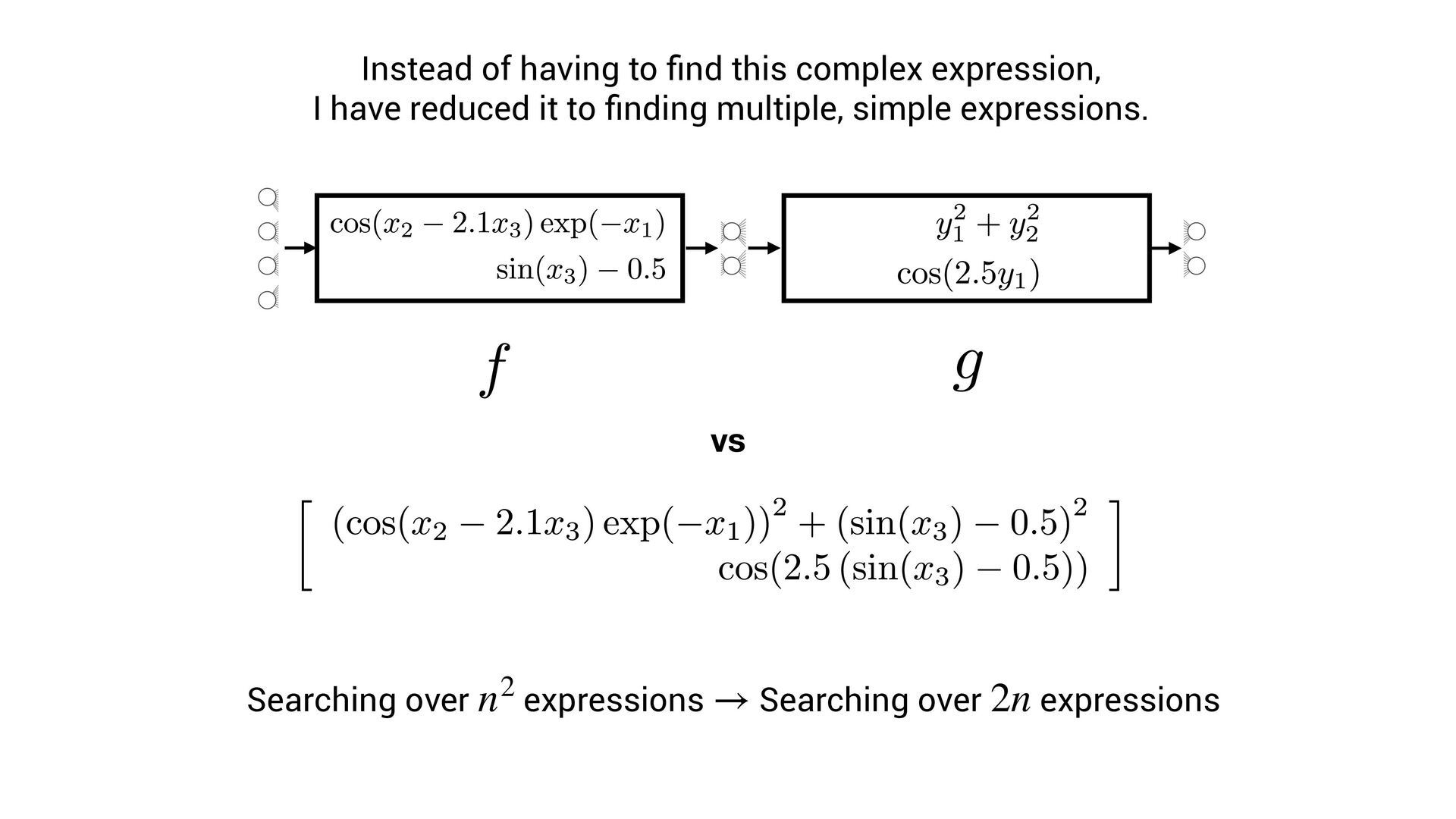
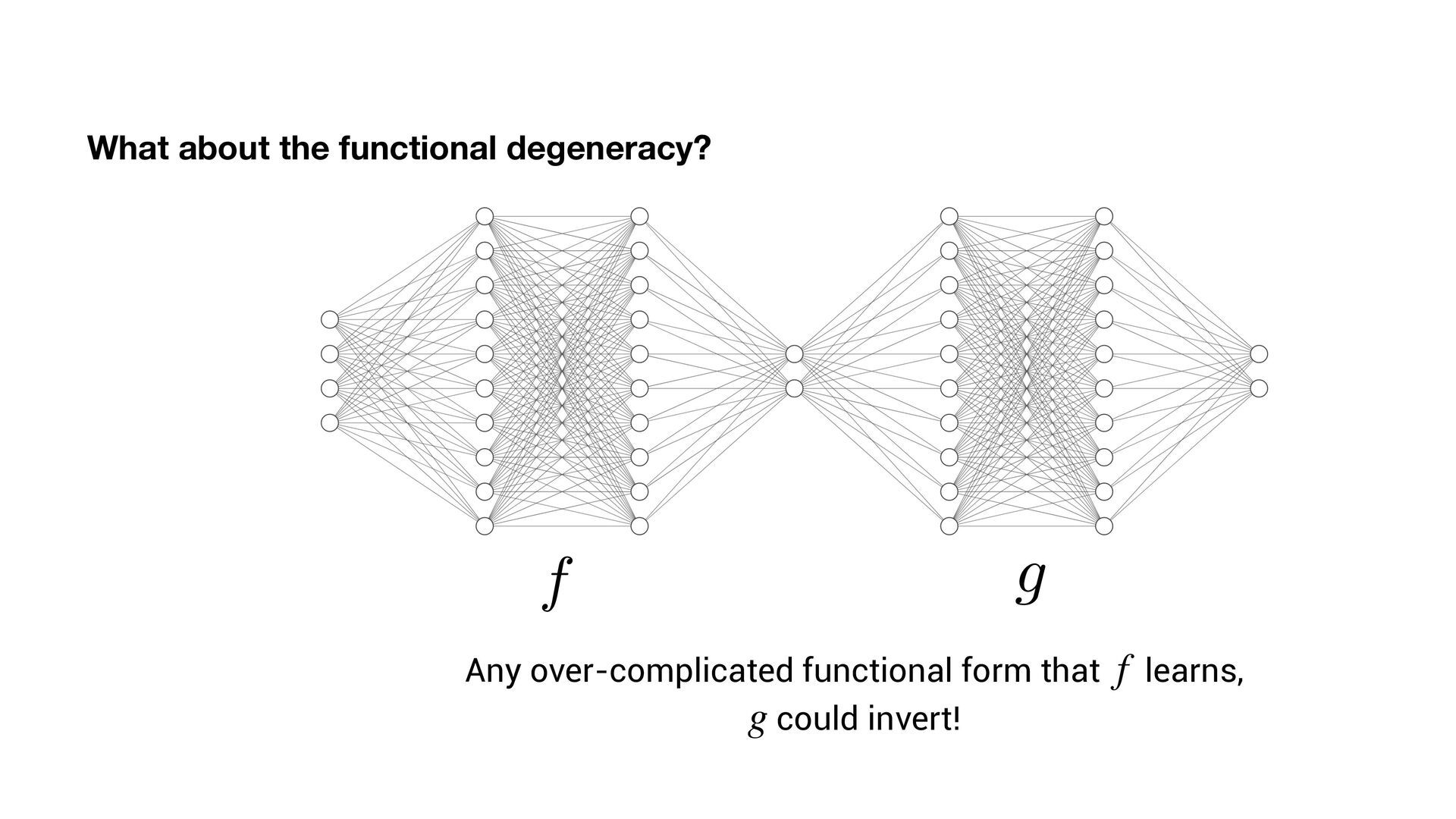
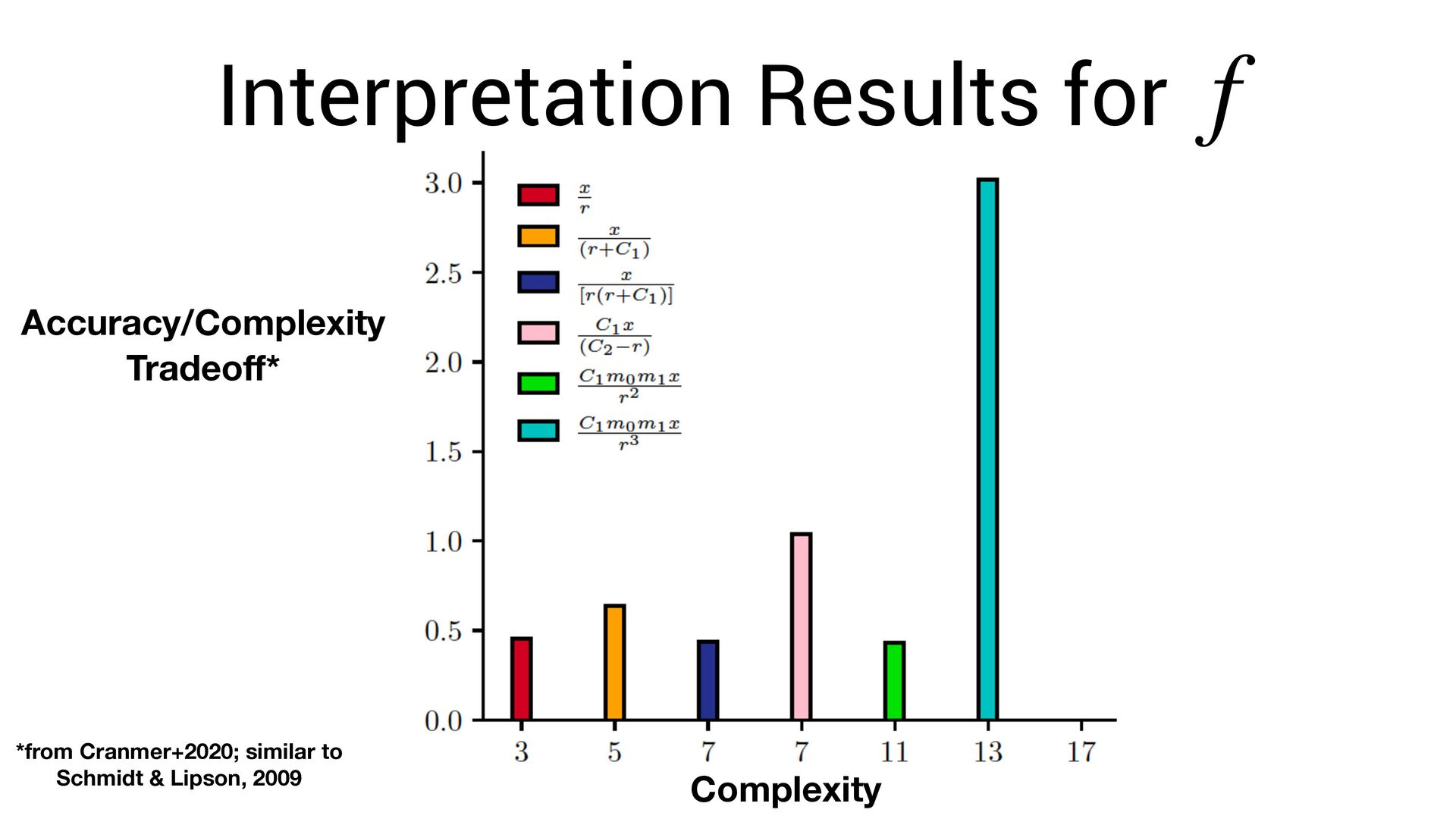
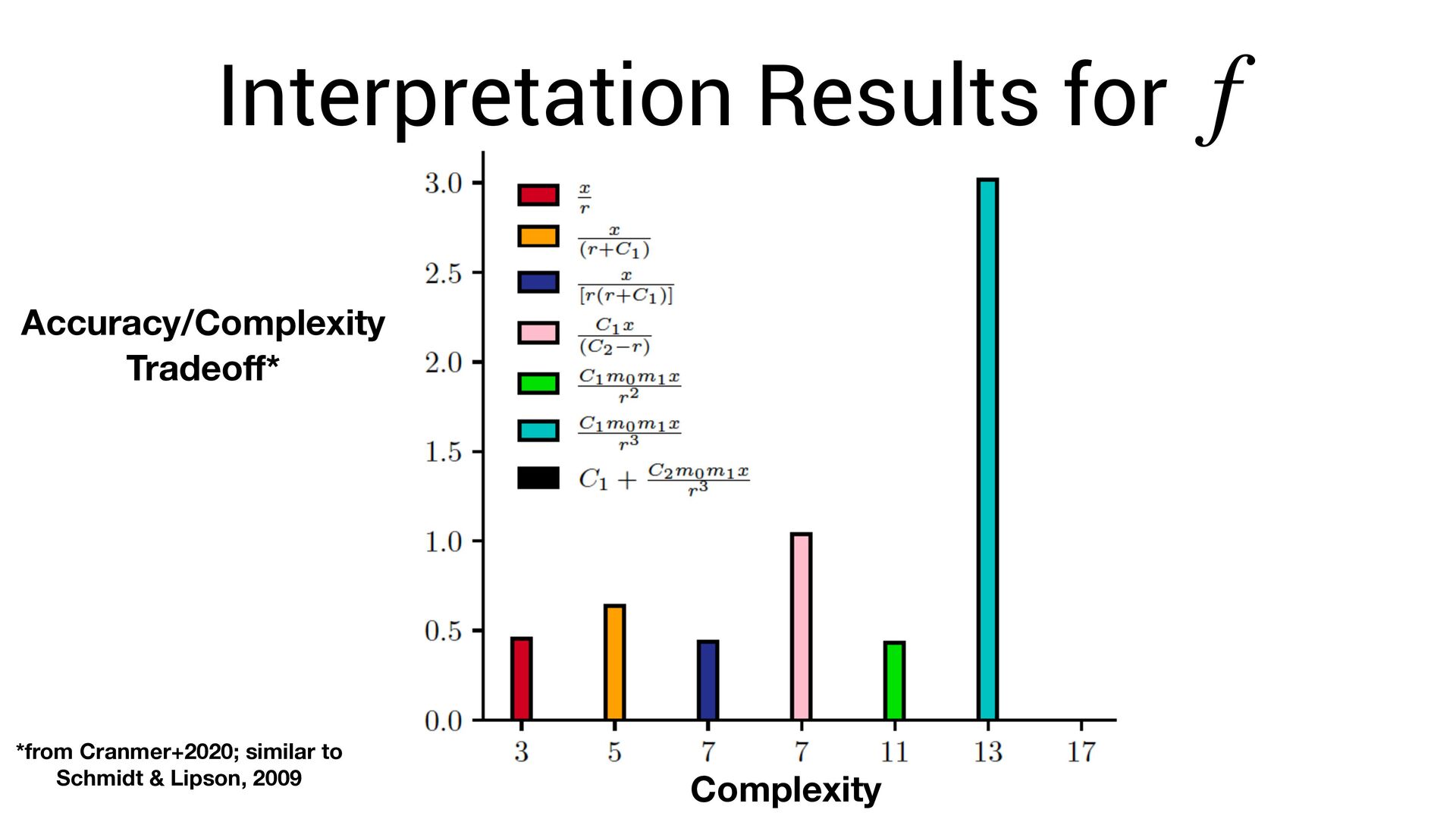
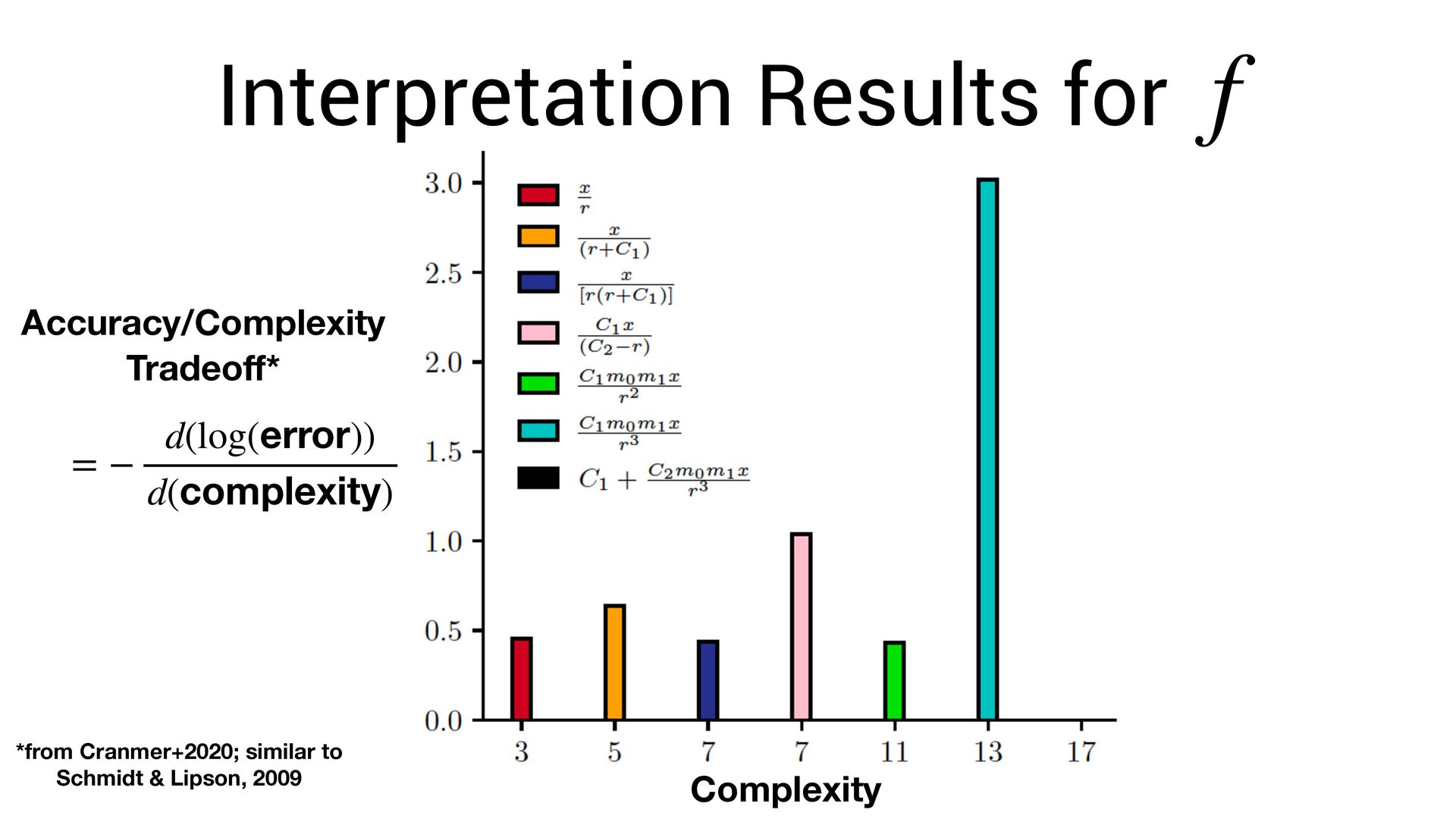
scale terribly with expression complexity. • One must search over: • (permutations of operators) x (permutations of variables + possible constants) • But, we know that neural networks can ef fi ciently fi nd very complex functions!
scale terribly with expression complexity. • One must search over: • (permutations of operators) x (permutations of variables + possible constants) • But, we know that neural networks can ef fi ciently fi nd very complex functions! • Can we exploit this?
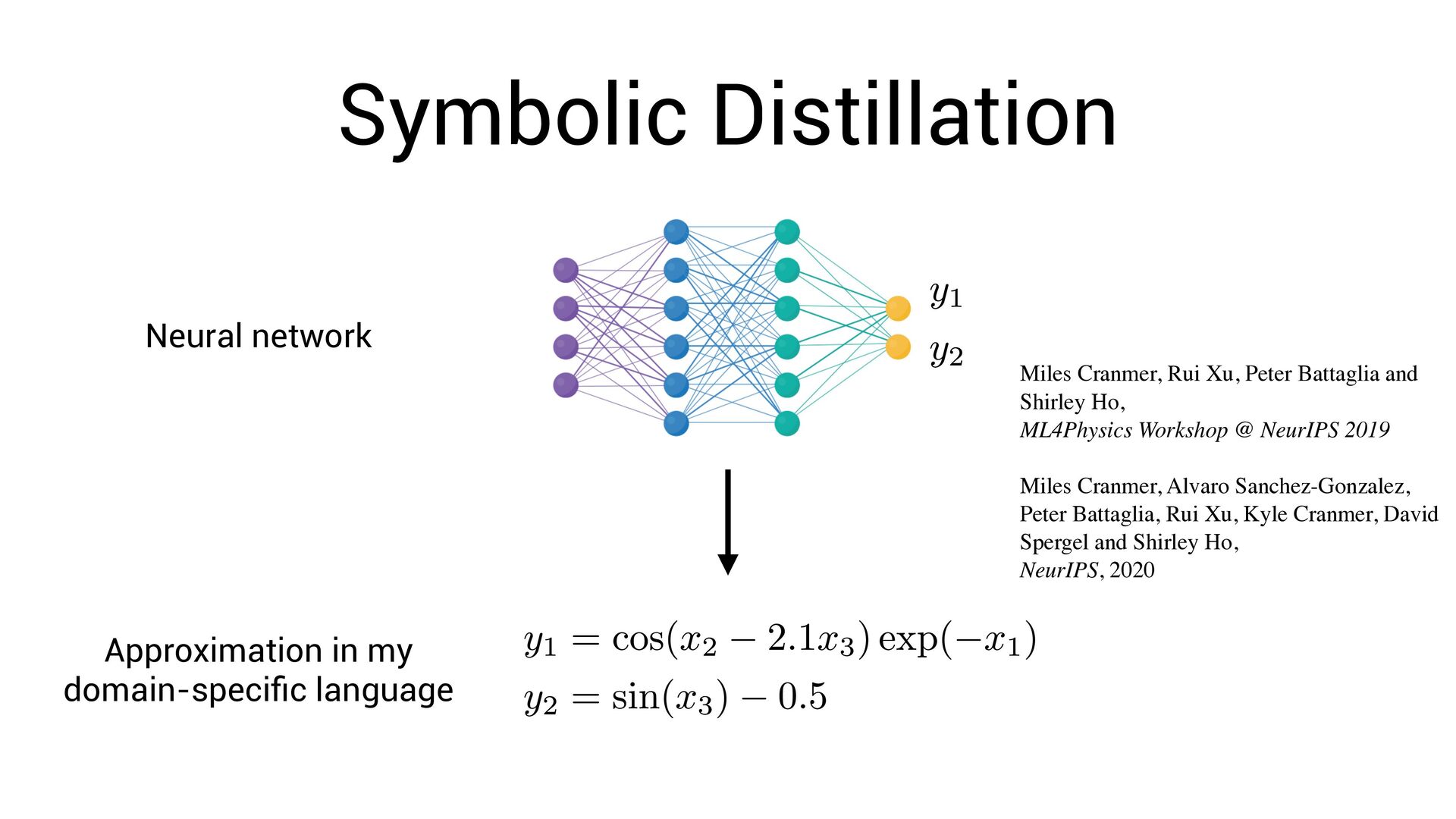
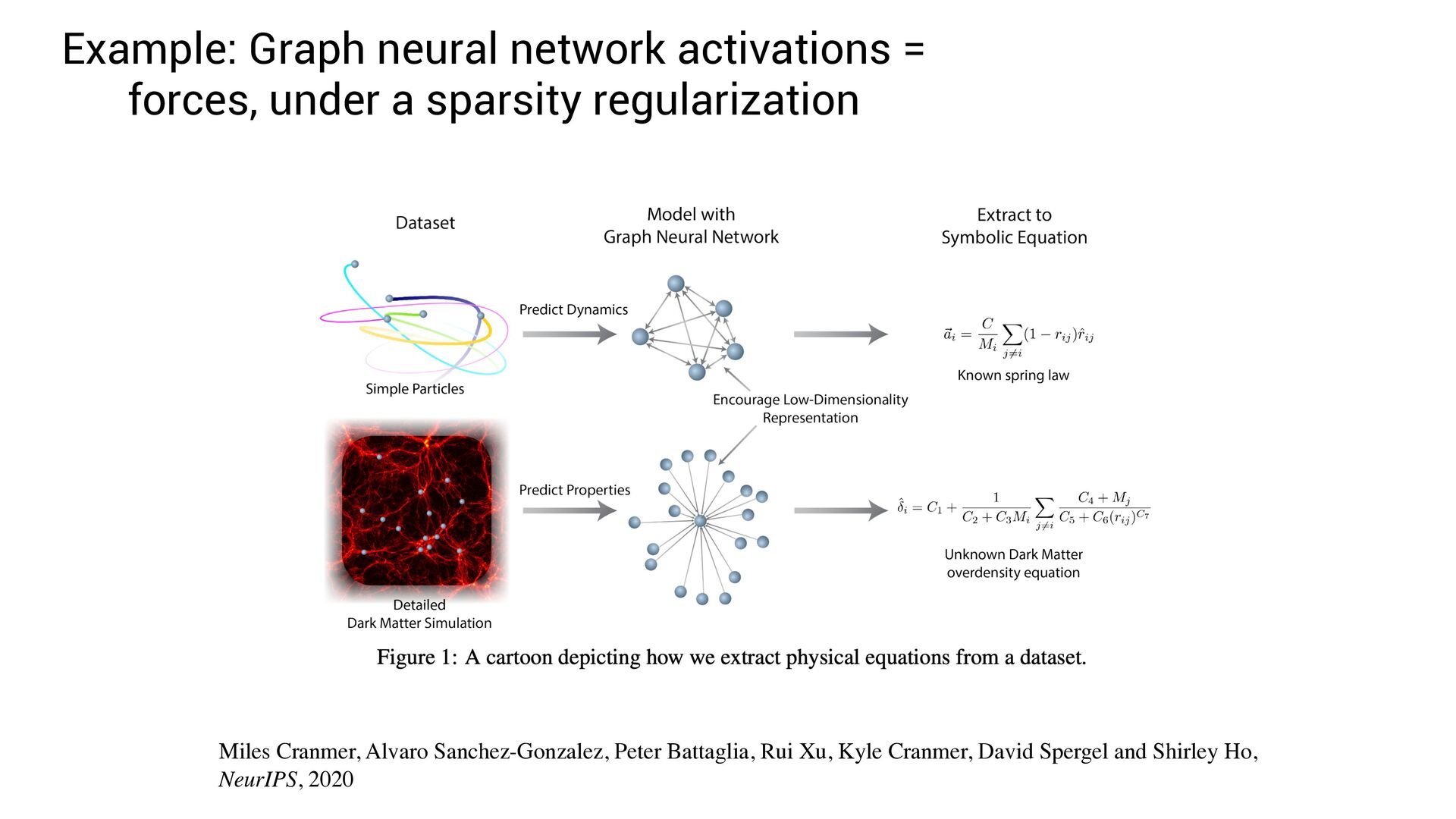
language Miles Cranmer, Rui Xu, Peter Battaglia and Shirley Ho, ML4Physics Workshop @ NeurIPS 2019 Miles Cranmer, Alvaro Sanchez-Gonzalez, Peter Battaglia, Rui Xu, Kyle Cranmer, David Spergel and Shirley Ho, NeurIPS, 2020
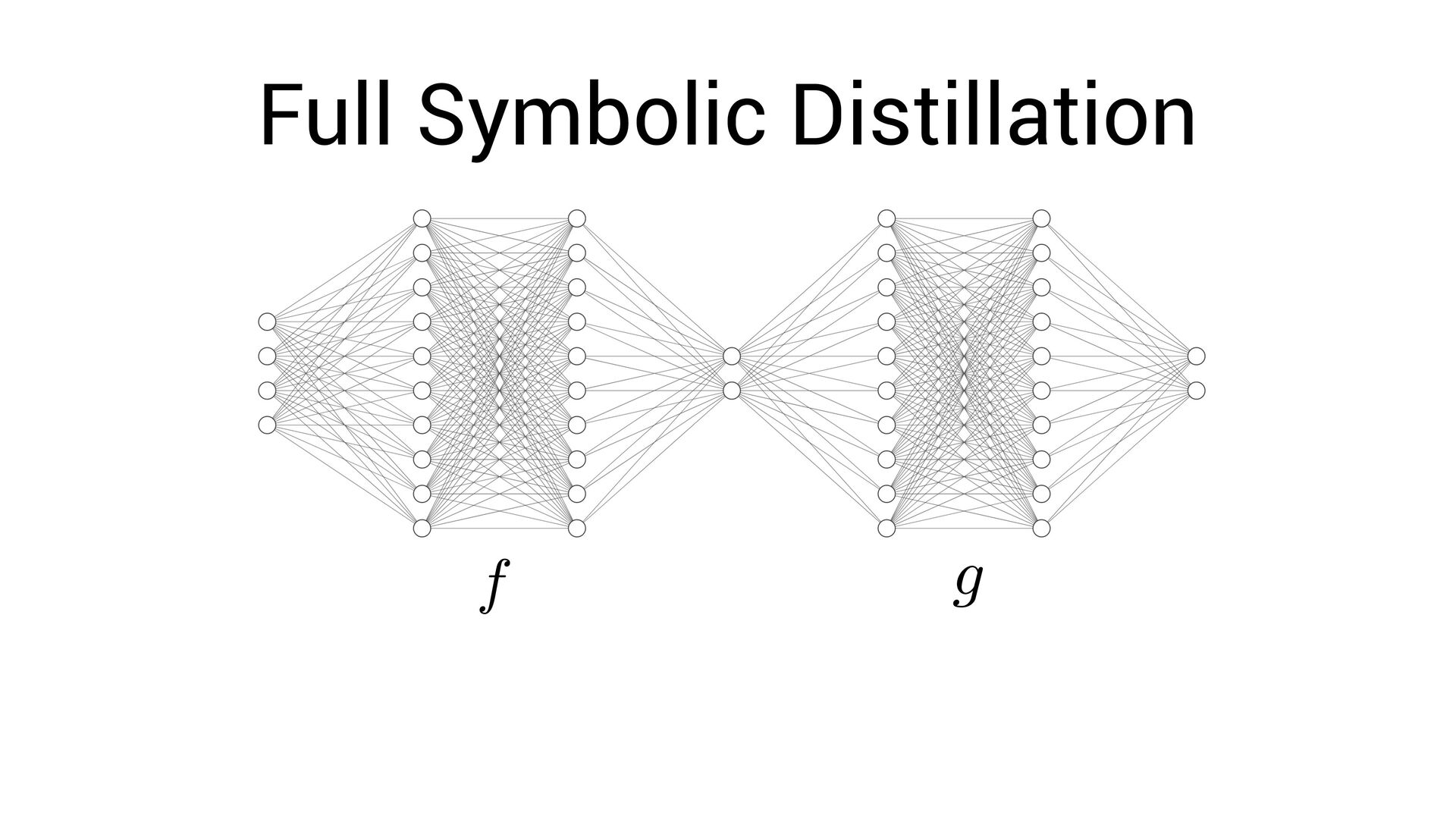
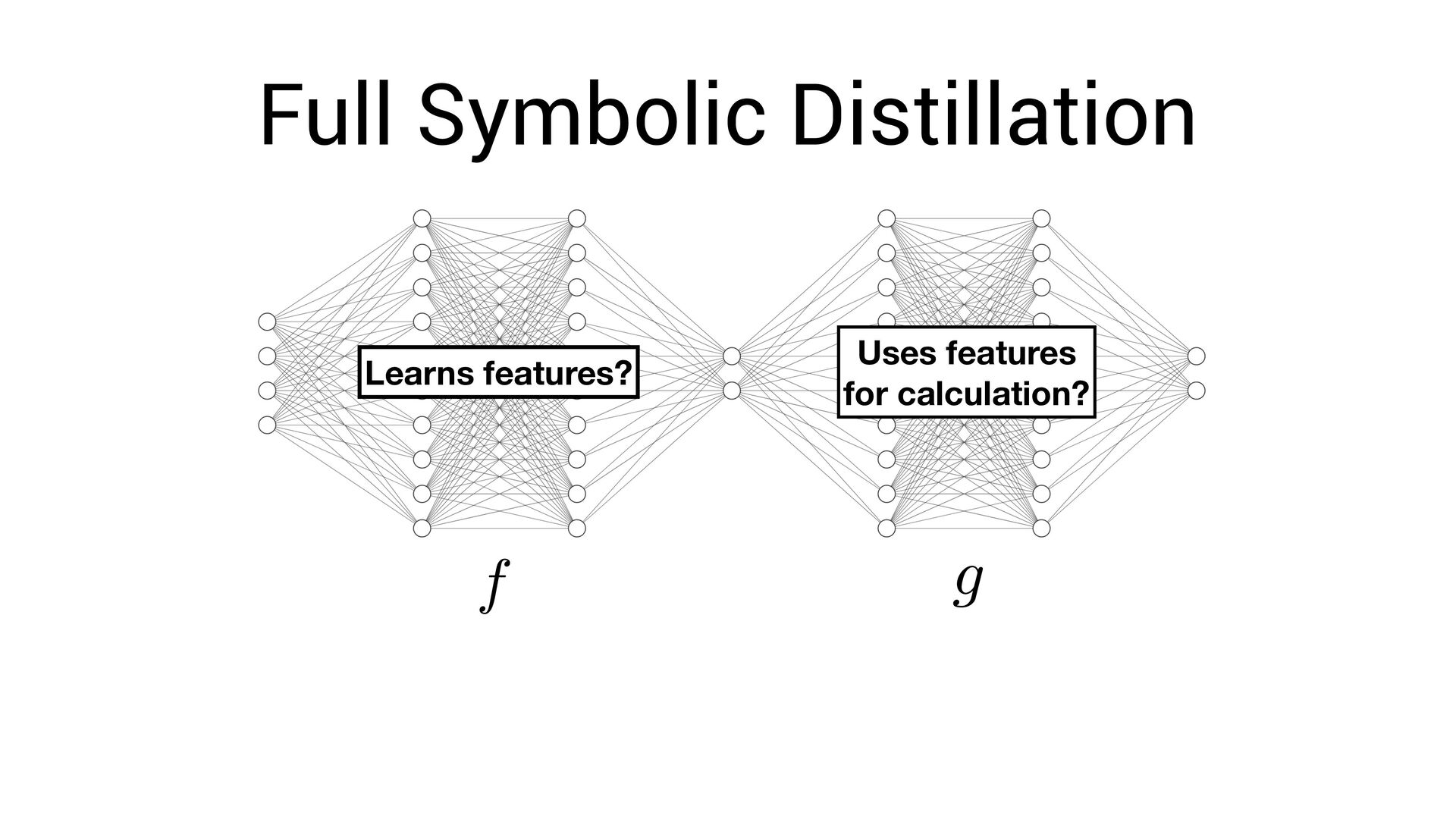
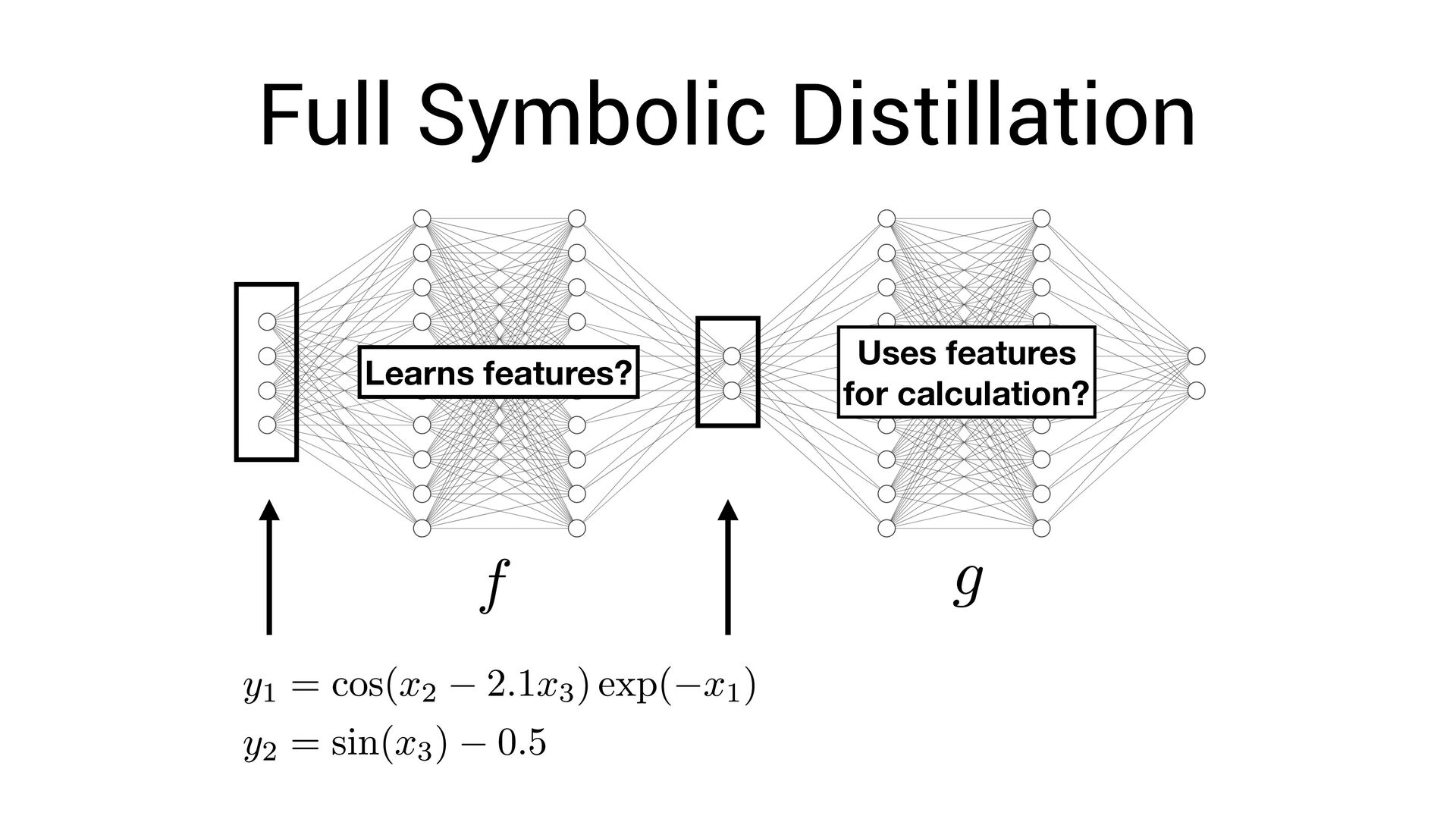
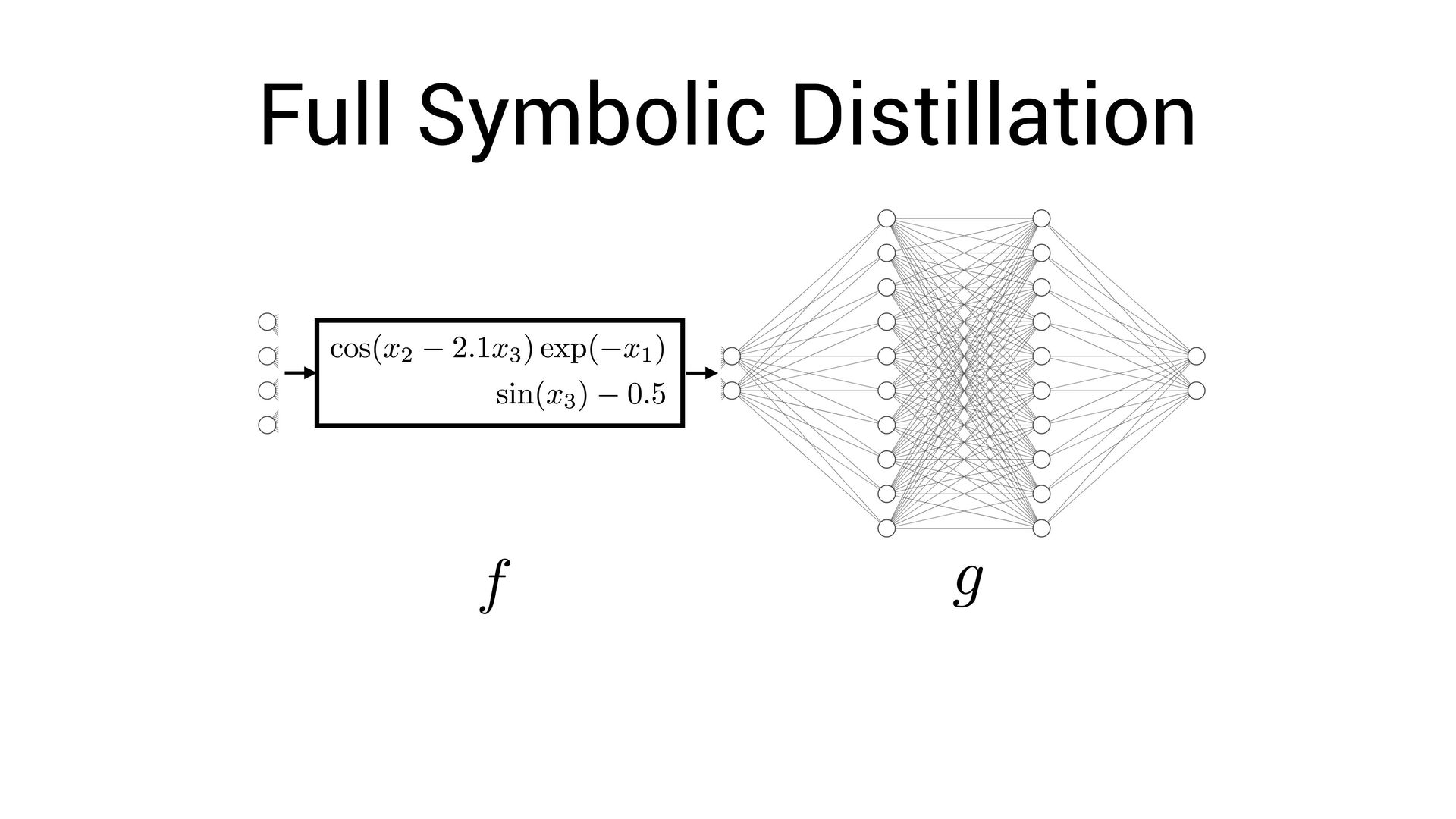
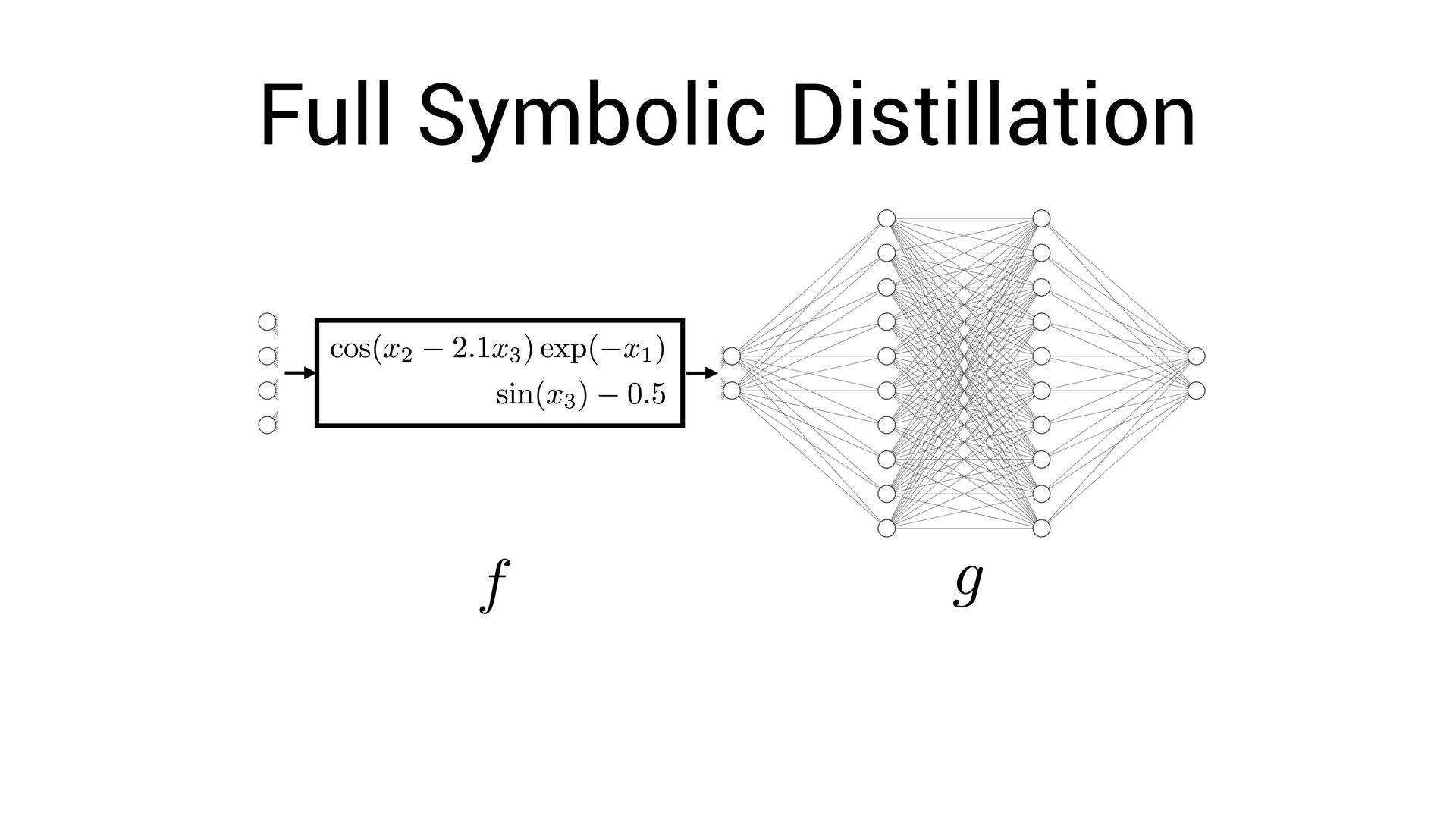
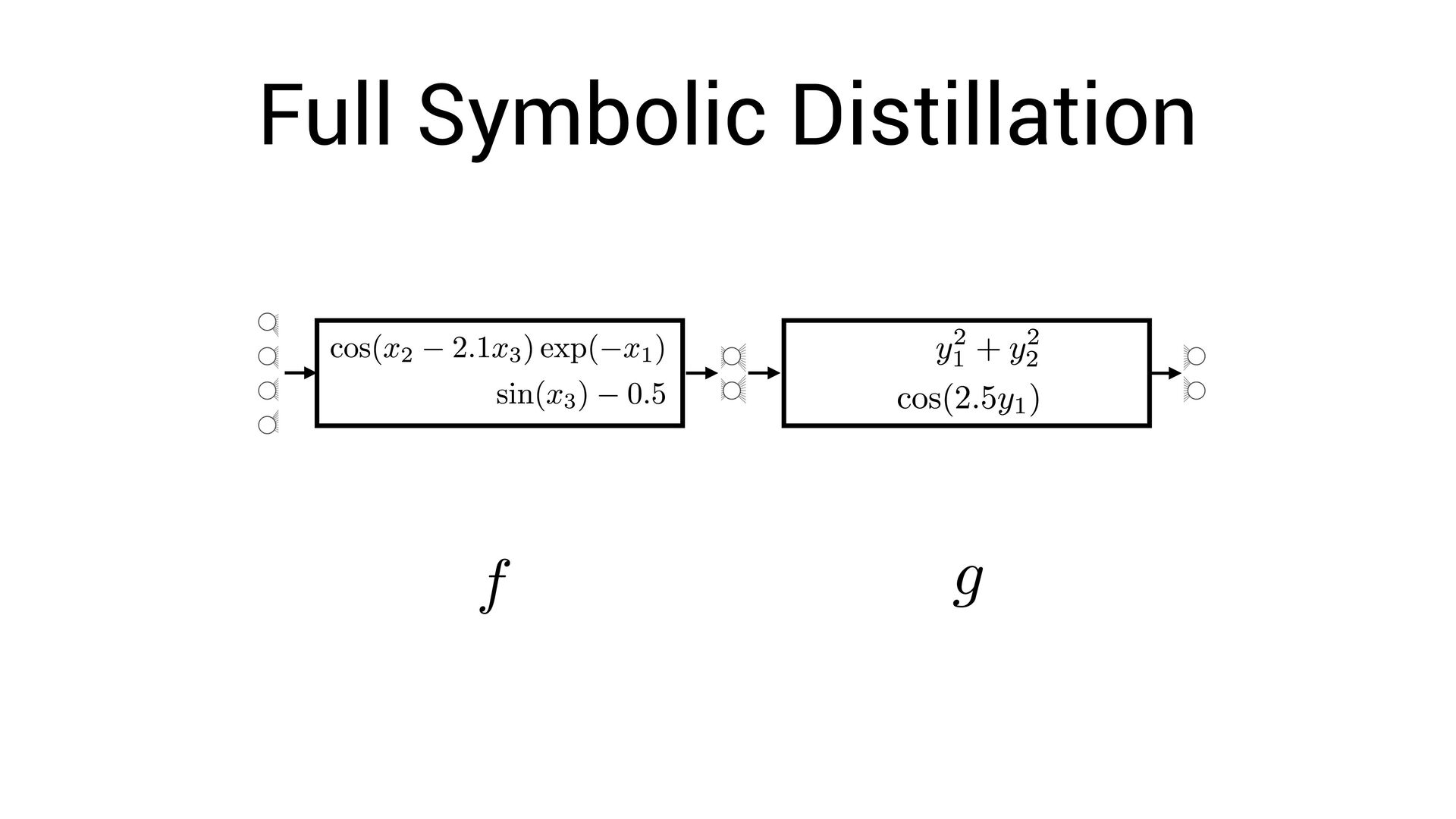
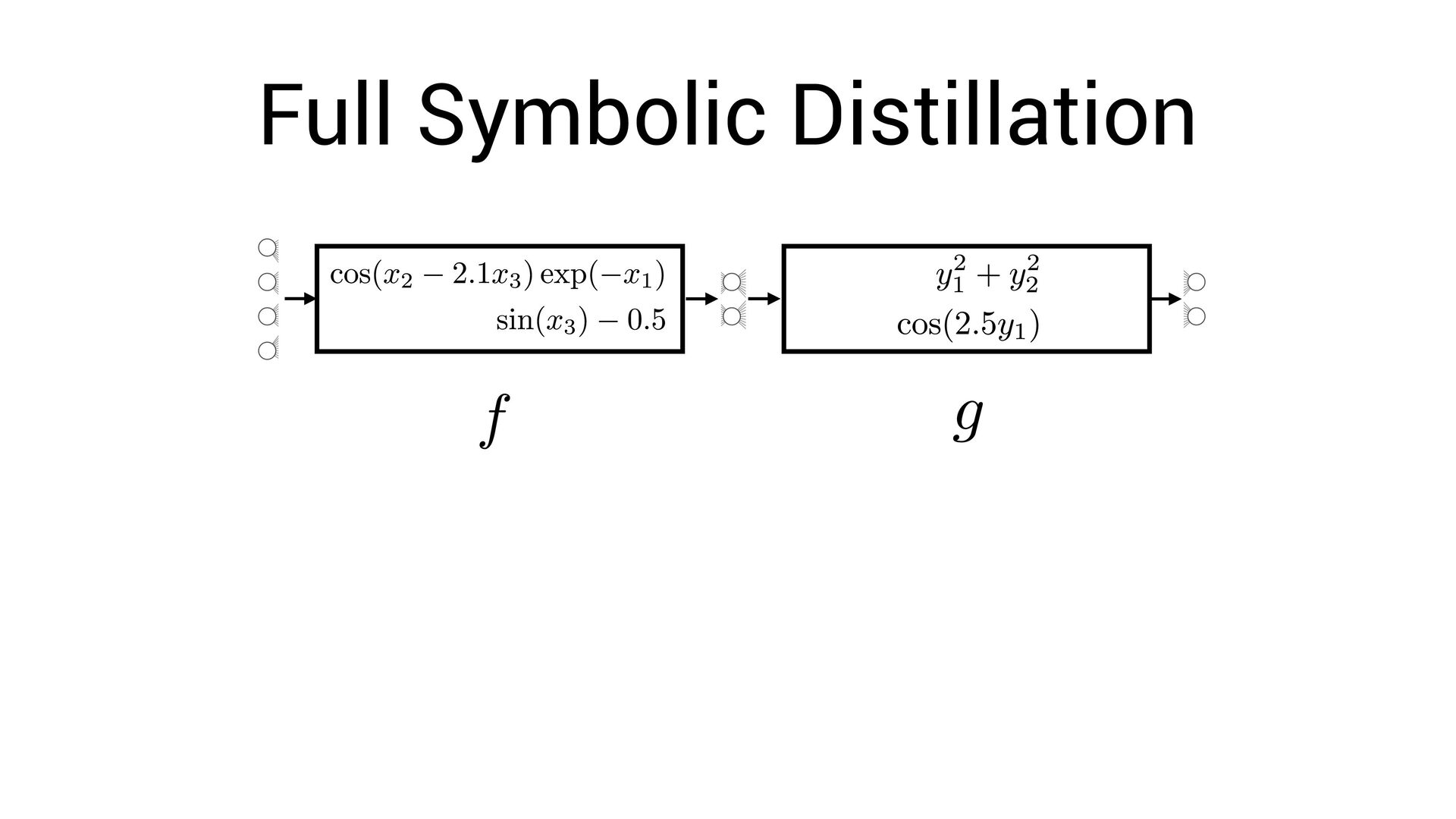
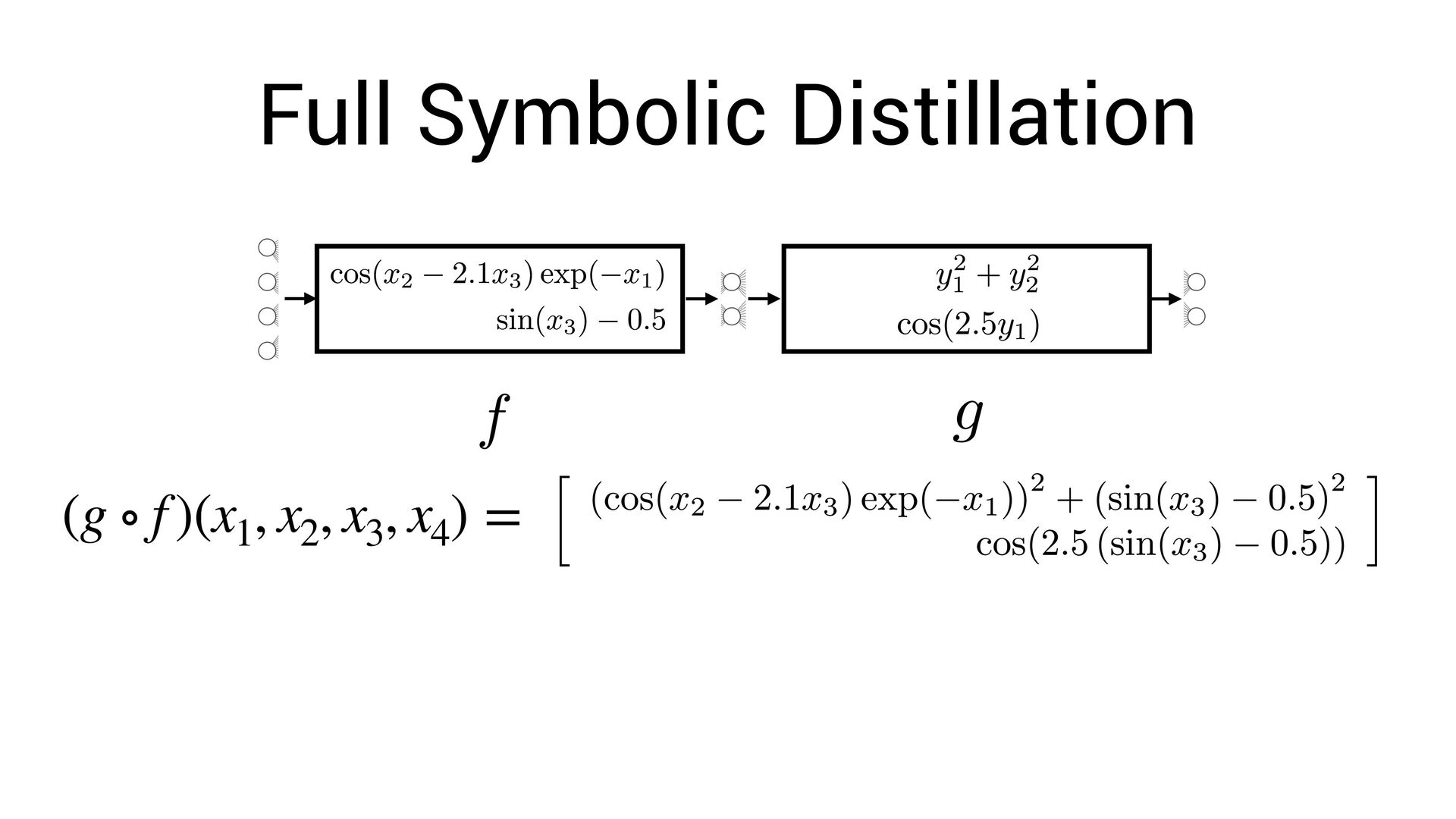
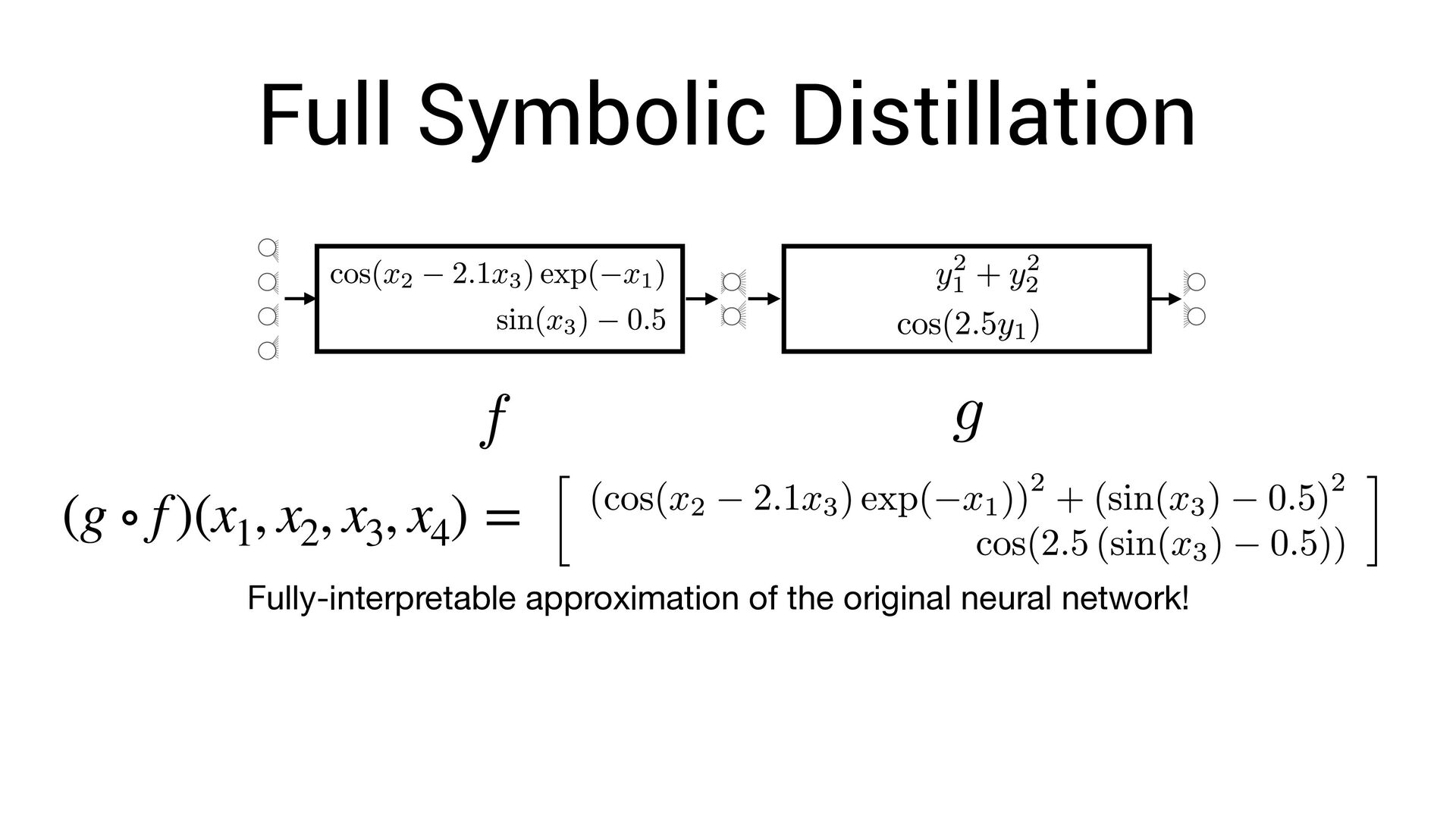
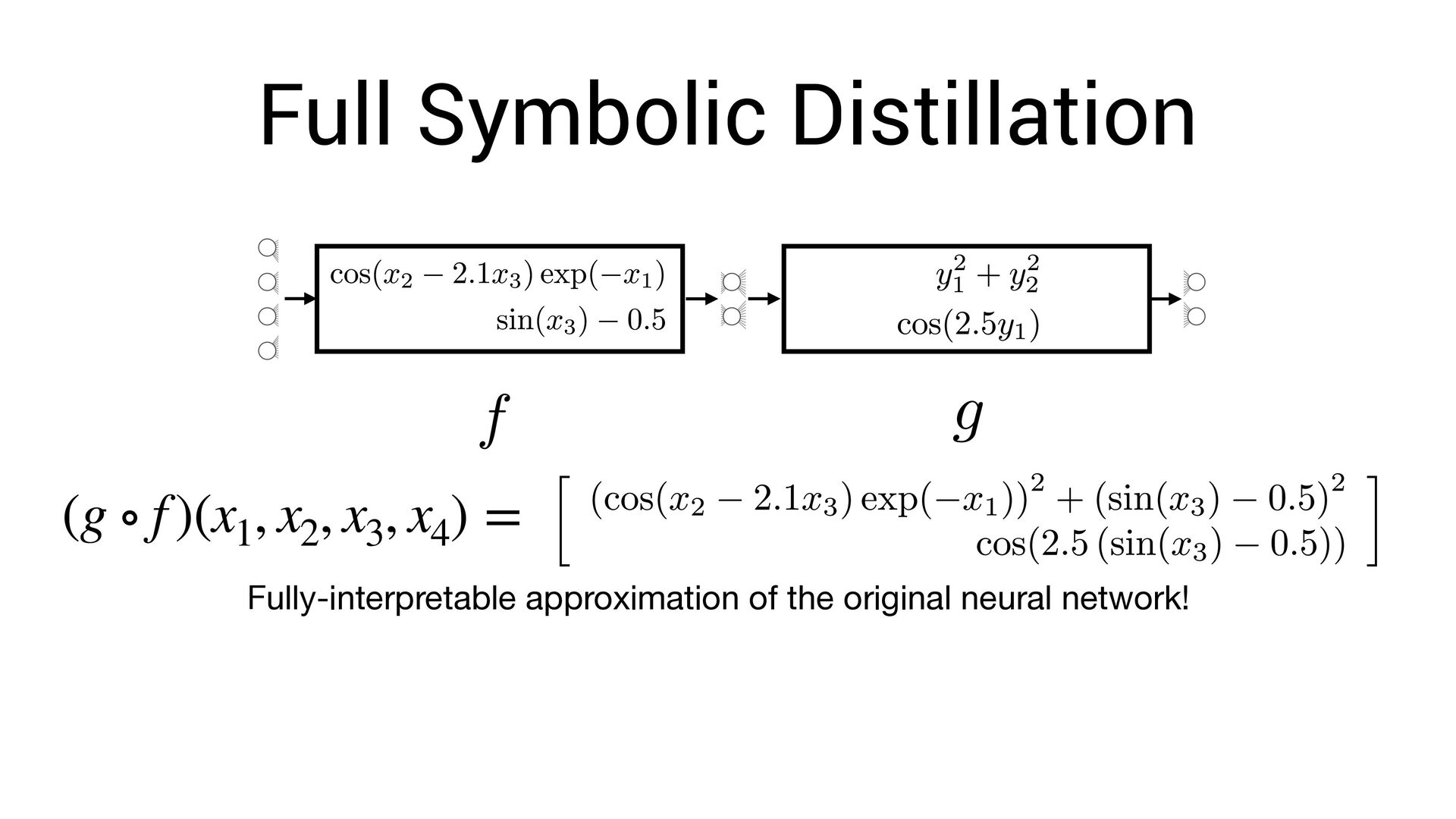
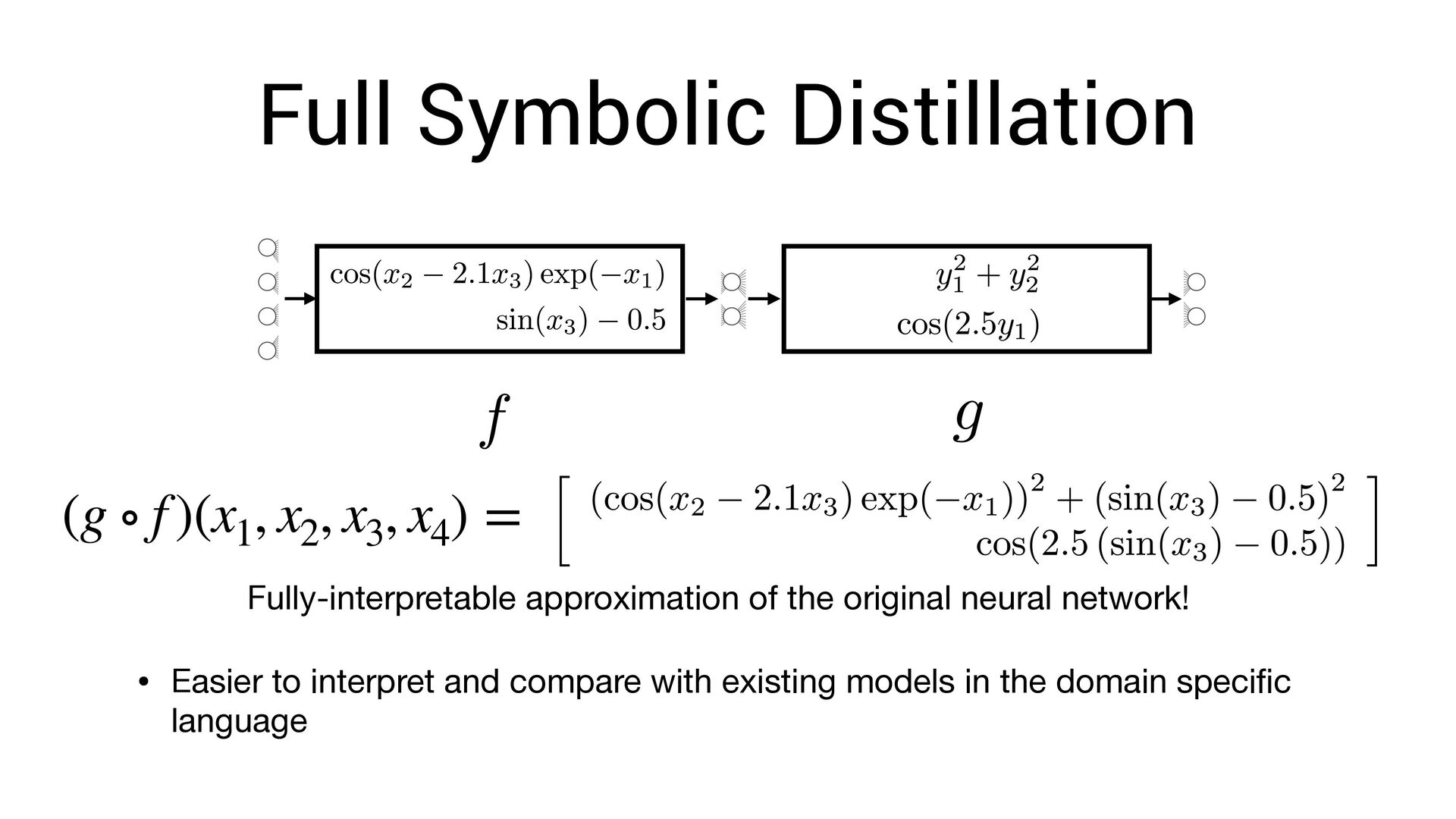
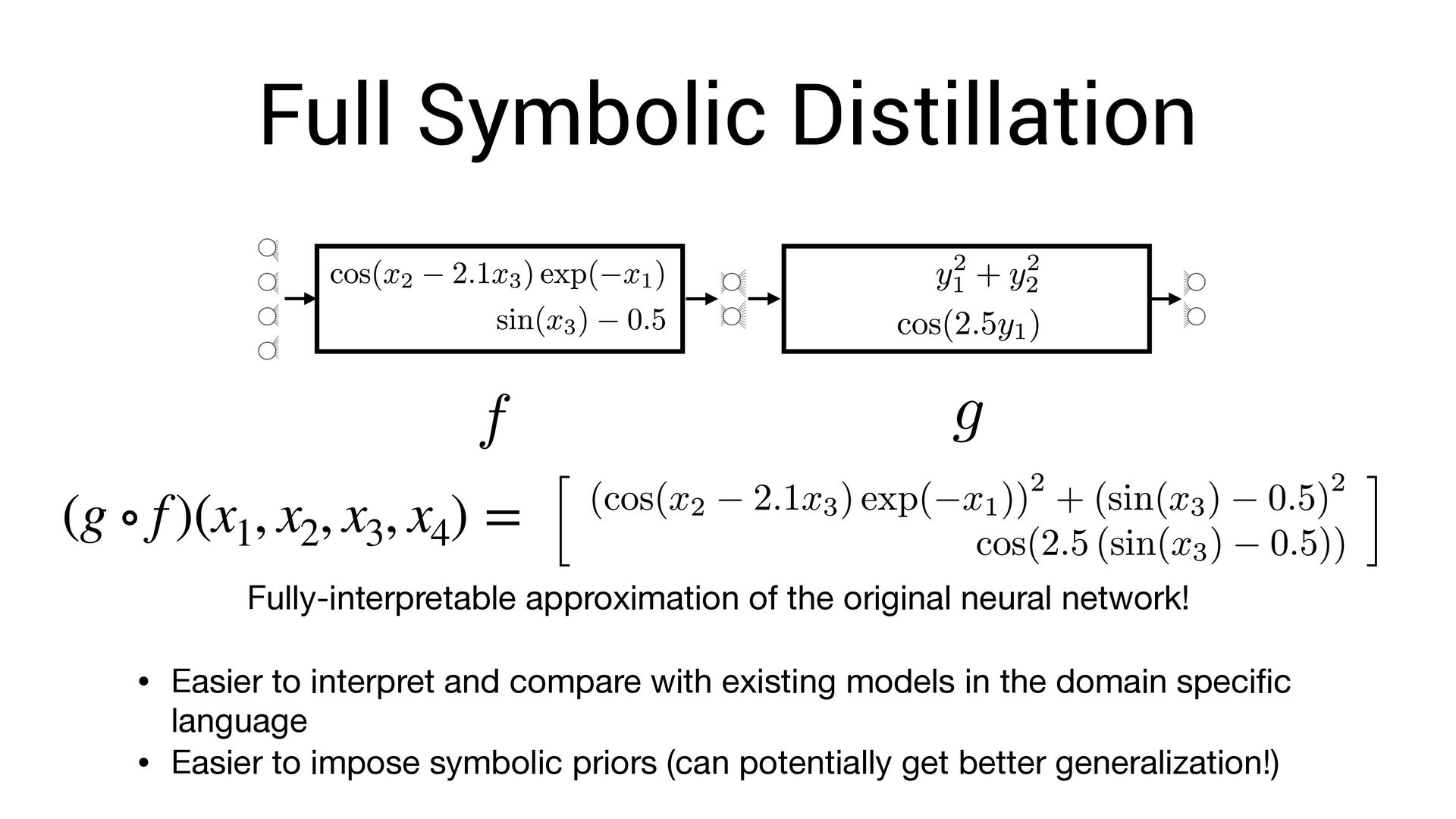
, x4 ) = Fully-interpretable approximation of the original neural network! • Easier to interpret and compare with existing models in the domain speci fi c language
, x4 ) = Fully-interpretable approximation of the original neural network! • Easier to interpret and compare with existing models in the domain speci fi c language • Easier to impose symbolic priors (can potentially get better generalization!)
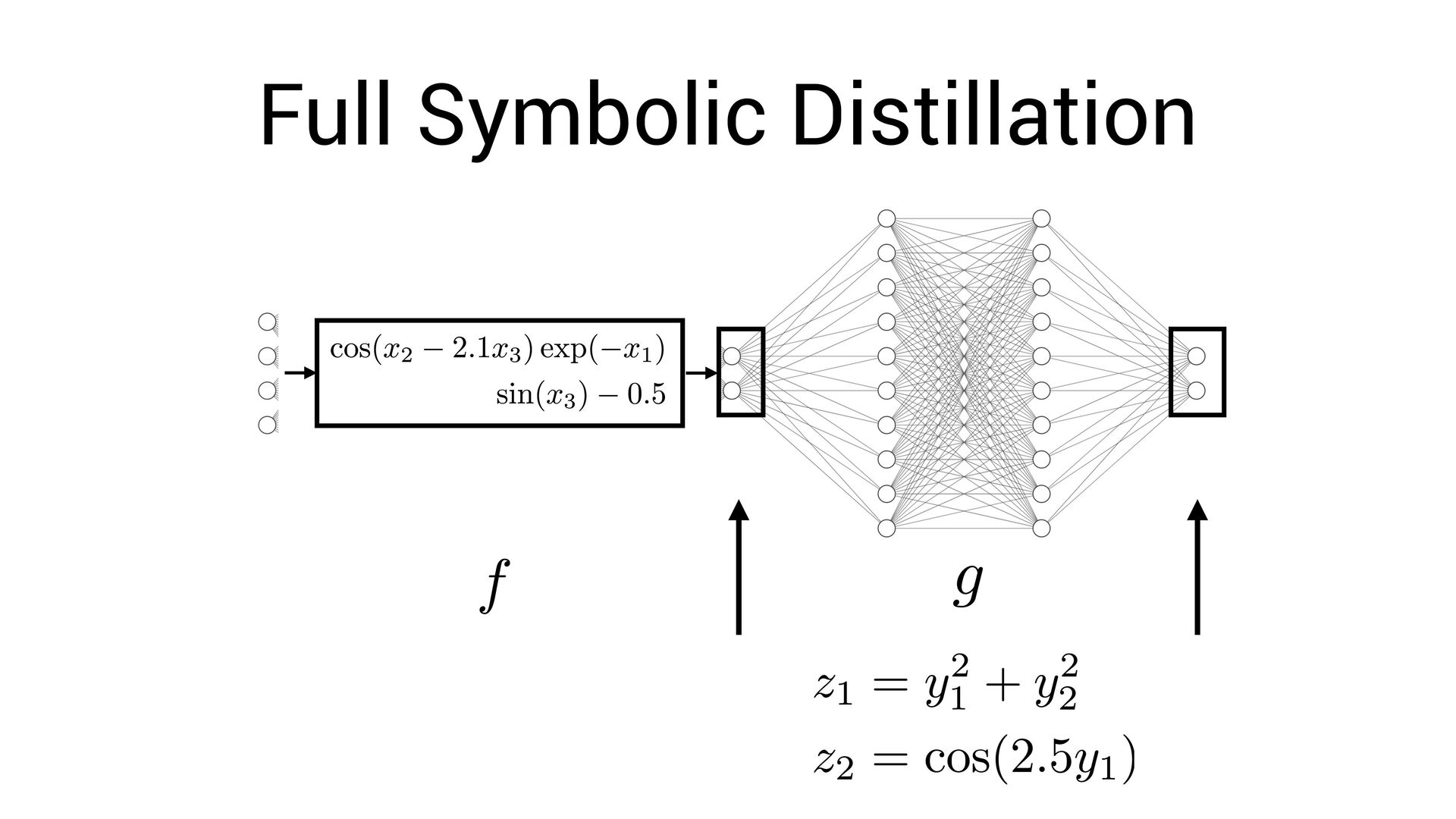
• Sparsity on latent space ( fewer equations, fewer variables) ⇒ • (Also see related work of Sebastian Wetzel & Roger Melko; and Steve Brunton & Nathan Kutz!)
• Sparsity on latent space ( fewer equations, fewer variables) ⇒ • (Also see related work of Sebastian Wetzel & Roger Melko; and Steve Brunton & Nathan Kutz!) • Smoothness penalty (try to encourage expression-like behavior)
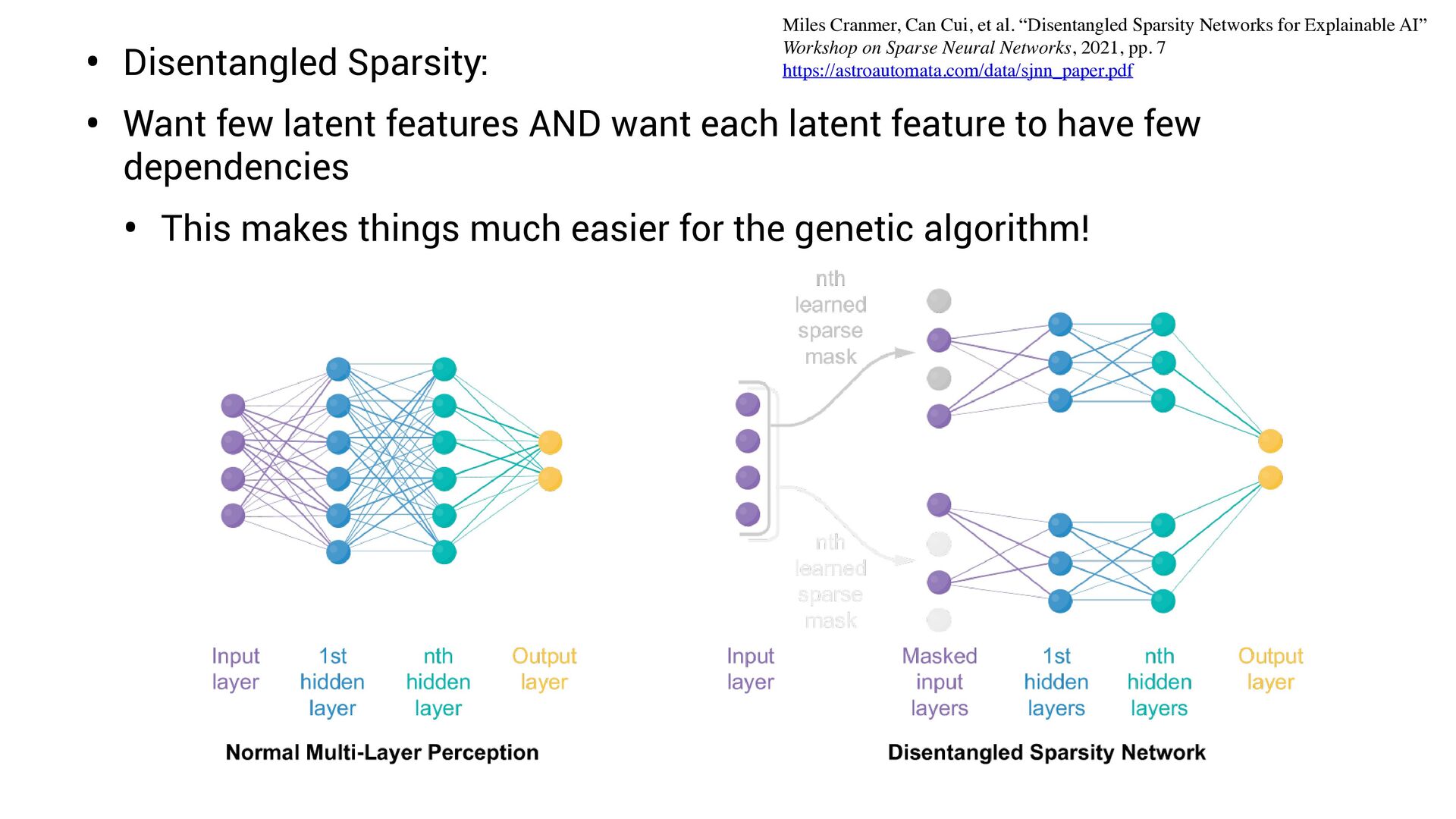
• Sparsity on latent space ( fewer equations, fewer variables) ⇒ • (Also see related work of Sebastian Wetzel & Roger Melko; and Steve Brunton & Nathan Kutz!) • Smoothness penalty (try to encourage expression-like behavior) • “Disentangled sparsity”
each latent feature to have few dependencies Miles Cranmer, Can Cui, et al. “Disentangled Sparsity Networks for Explainable AI” Workshop on Sparse Neural Networks, 2021, pp. 7 https://astroautomata.com/data/sjnn_paper.pdf
each latent feature to have few dependencies • This makes things much easier for the genetic algorithm! Miles Cranmer, Can Cui, et al. “Disentangled Sparsity Networks for Explainable AI” Workshop on Sparse Neural Networks, 2021, pp. 7 https://astroautomata.com/data/sjnn_paper.pdf
each latent feature to have few dependencies • This makes things much easier for the genetic algorithm! Miles Cranmer, Can Cui, et al. “Disentangled Sparsity Networks for Explainable AI” Workshop on Sparse Neural Networks, 2021, pp. 7 https://astroautomata.com/data/sjnn_paper.pdf
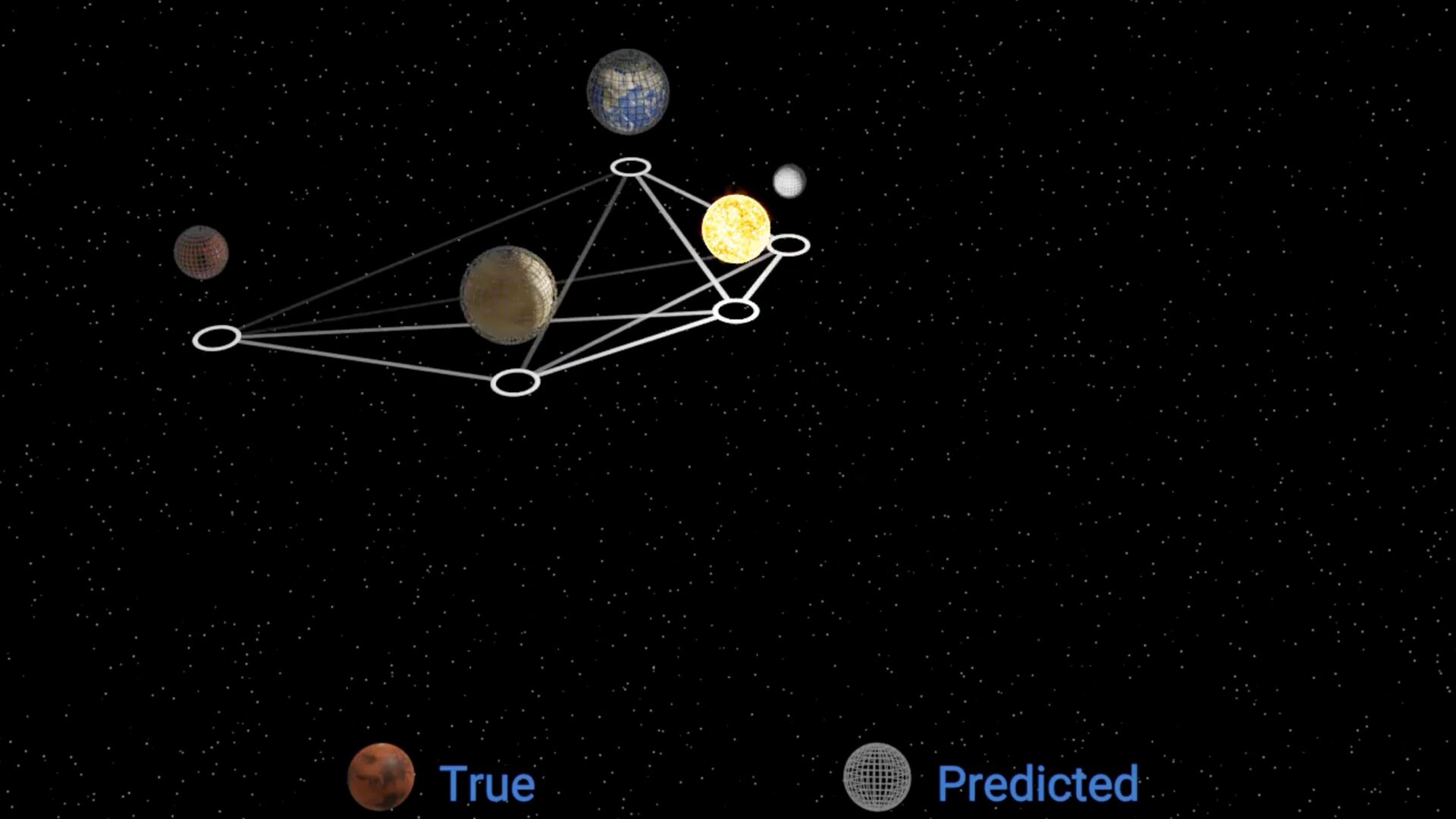
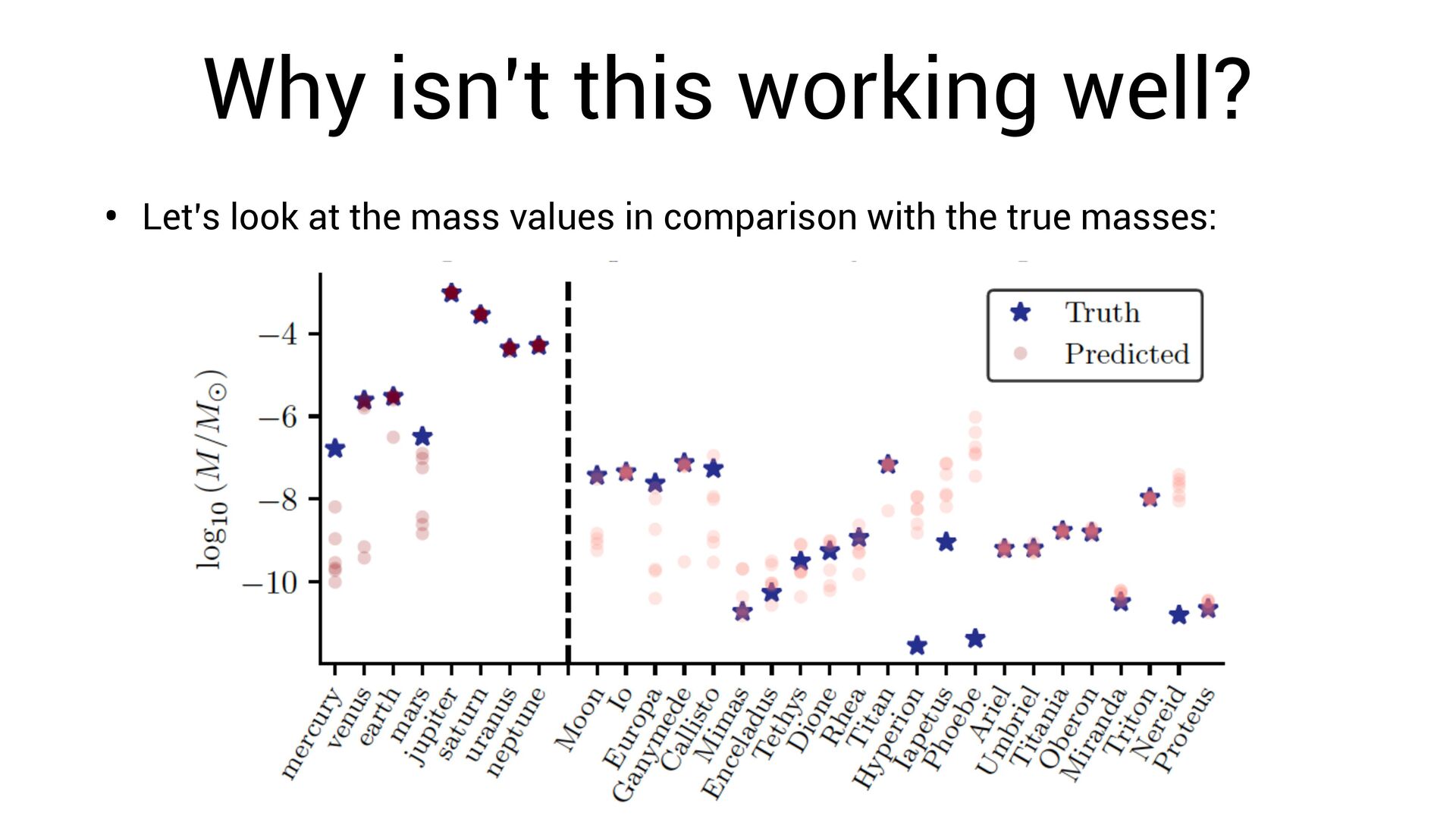
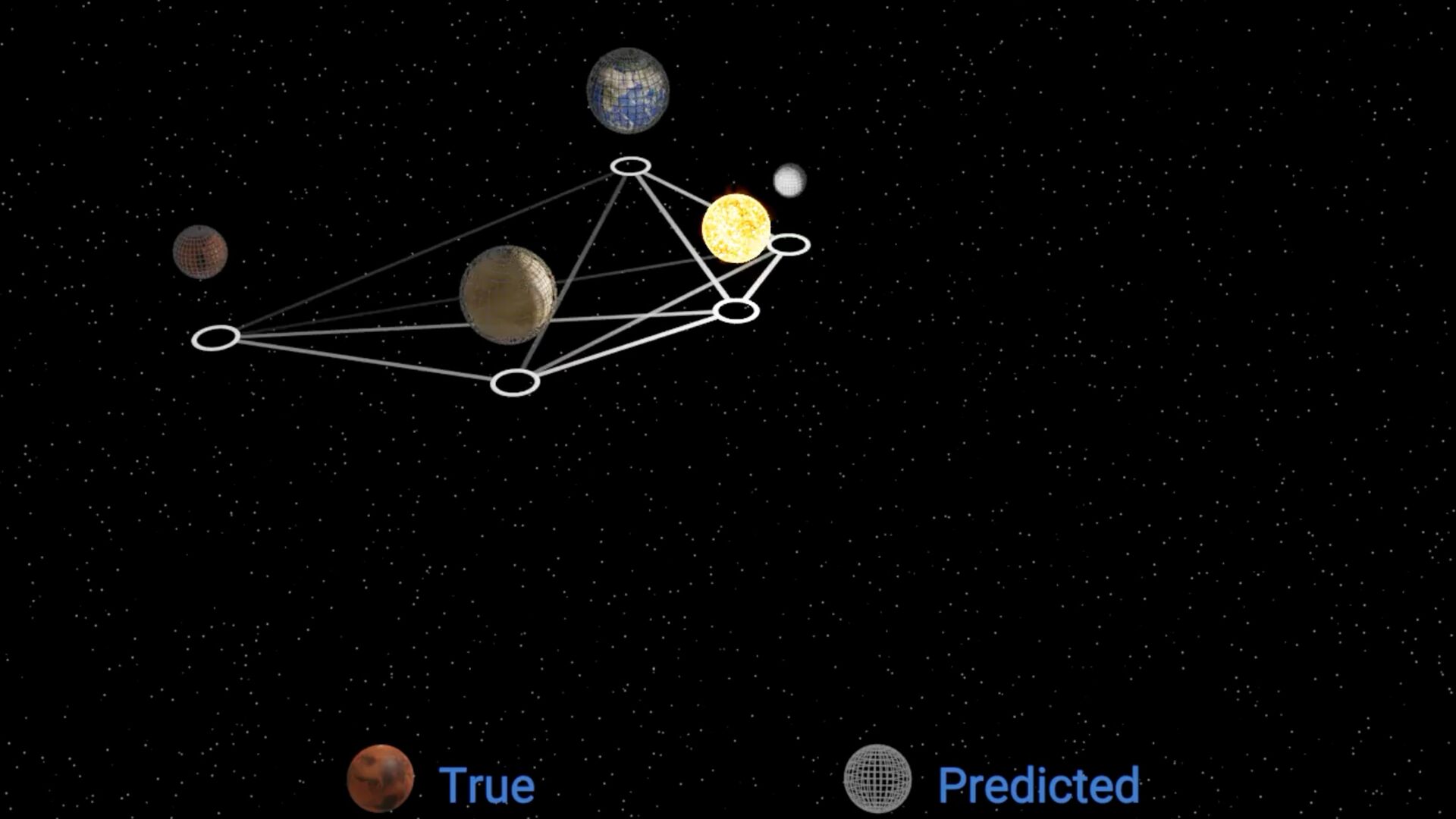
Niall Jeffrey, Miles Cranmer, Shirley Ho, Peter Battaglia Example: Discovering Orbital Mechanics Can we learn Newton’s law of gravity simply by observing the solar system? Unknown masses, and unknown dynamical model.
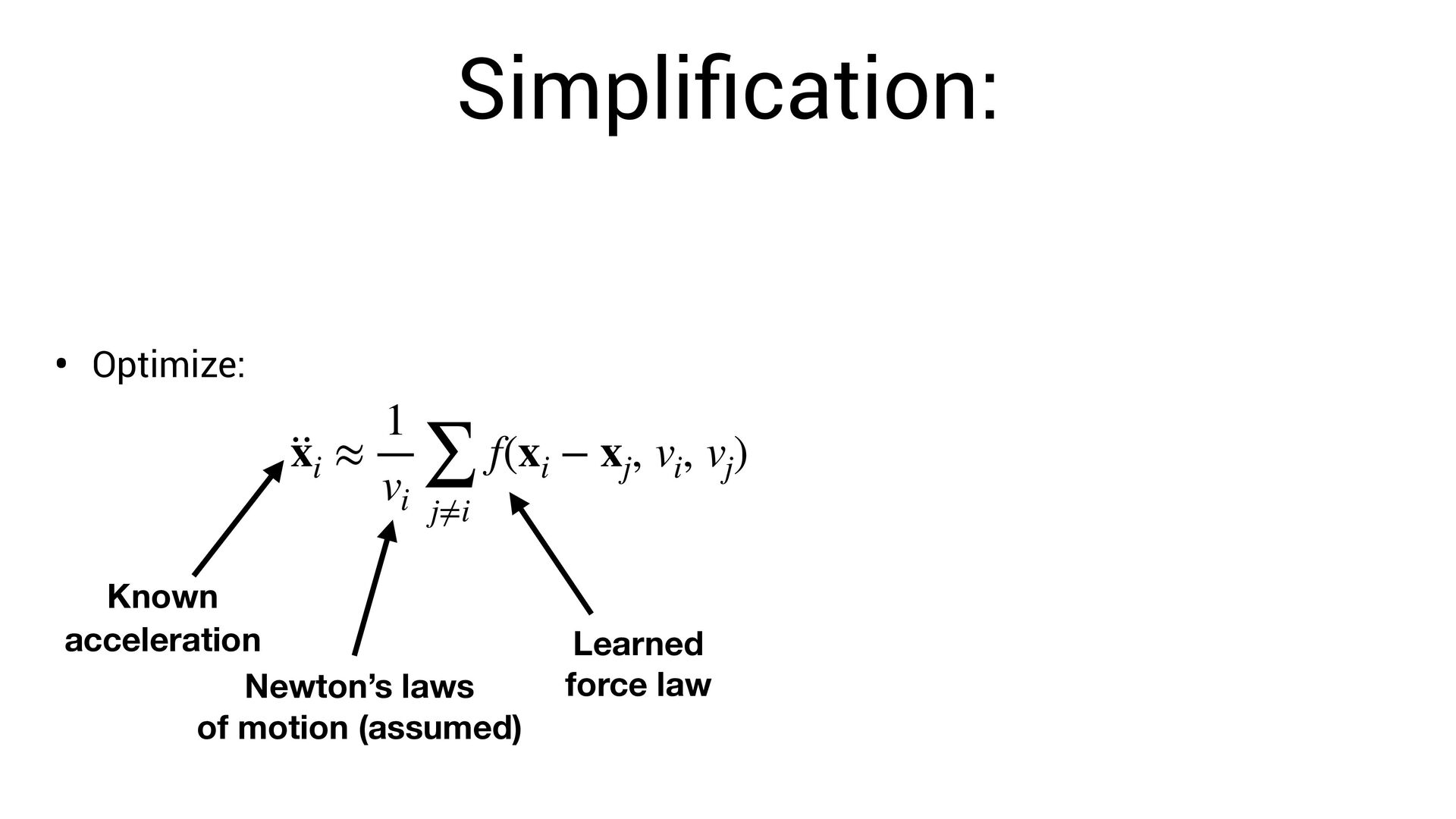
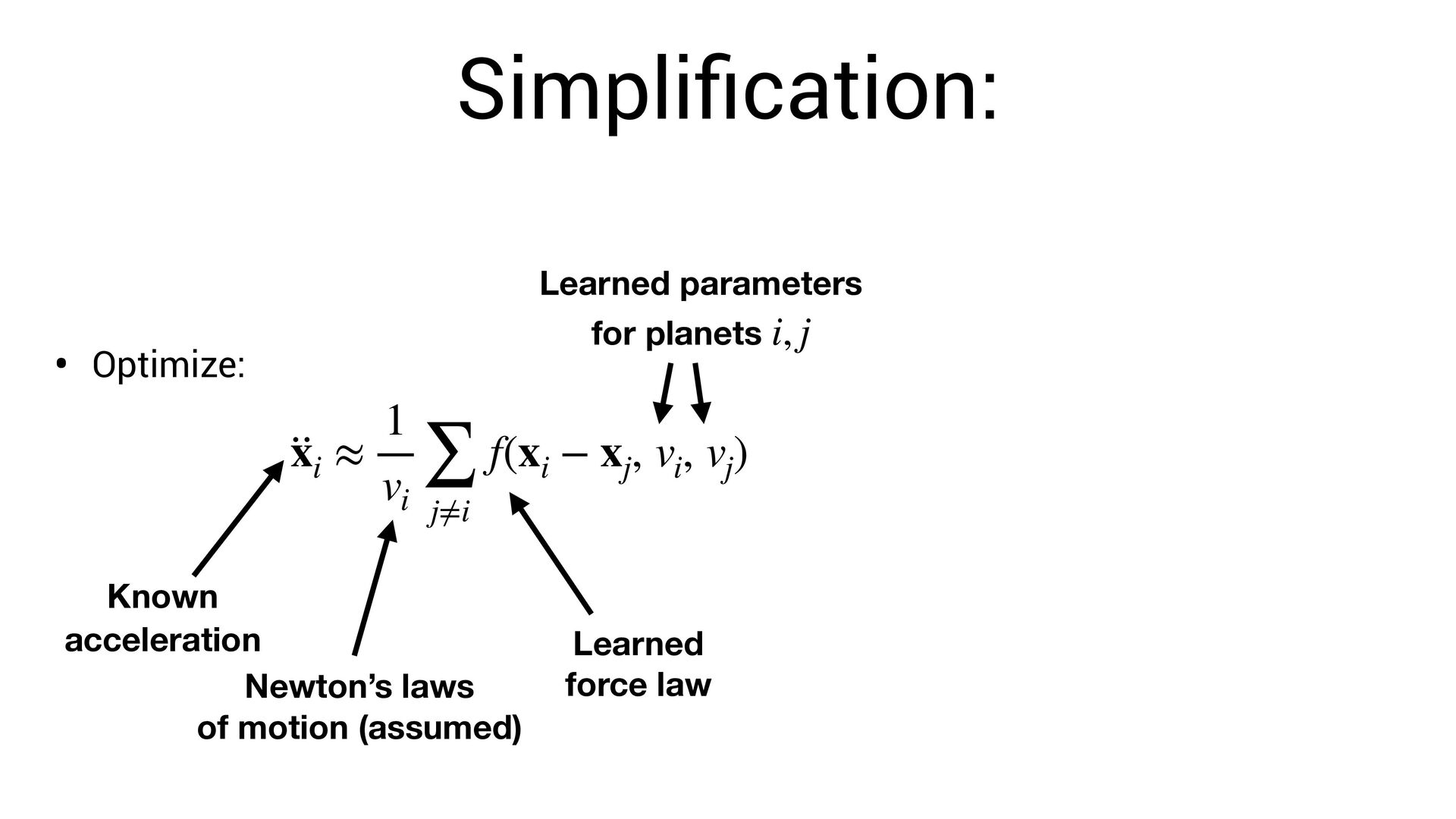
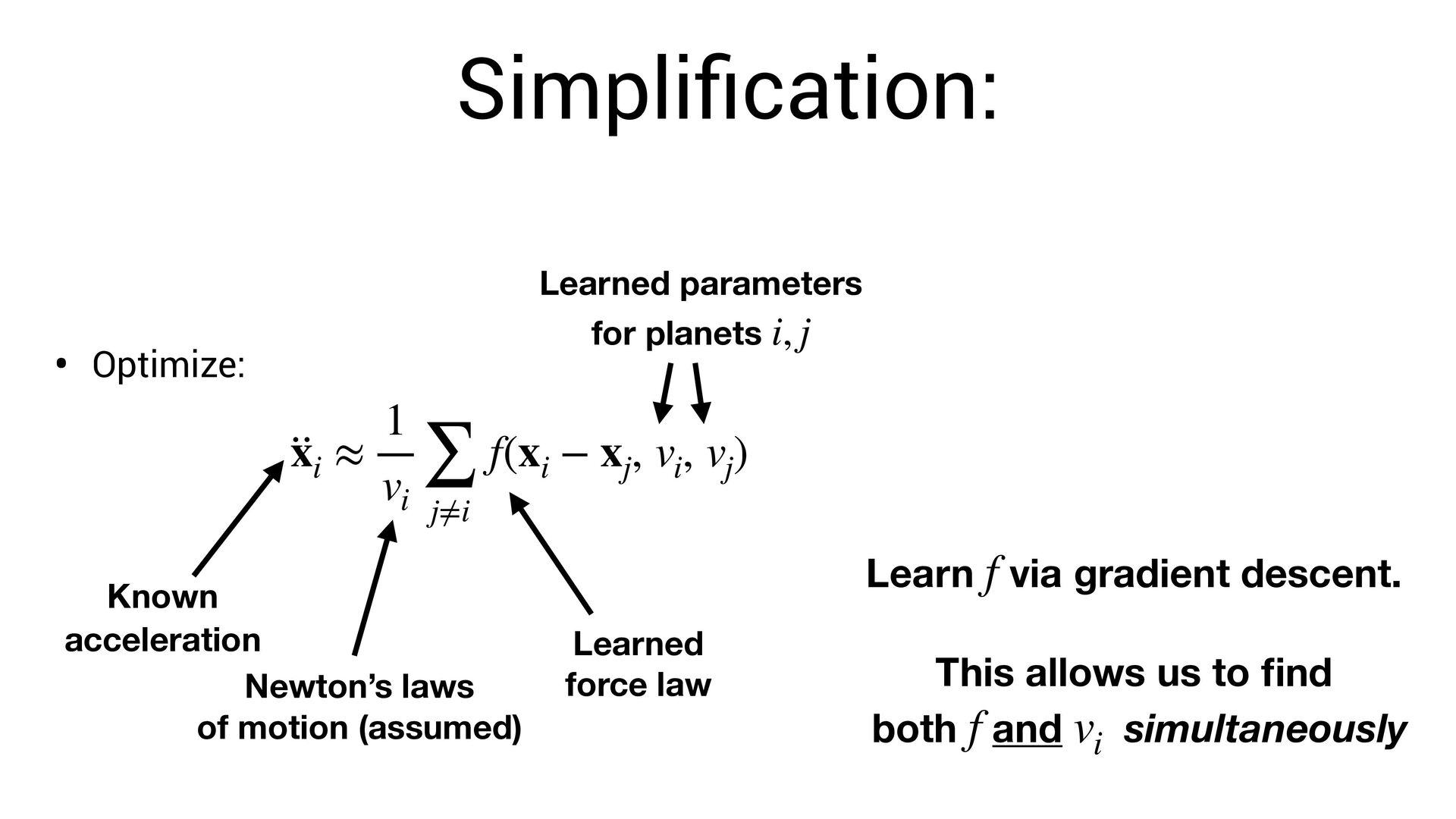
position for each planet • Known acceleration for each planet • Unknown parameter for each planet • Unknown force t xi ∈ ℝ3 ·· xi ∈ ℝ3 vi ∈ ℝ f(xi − xj , vi , vj )
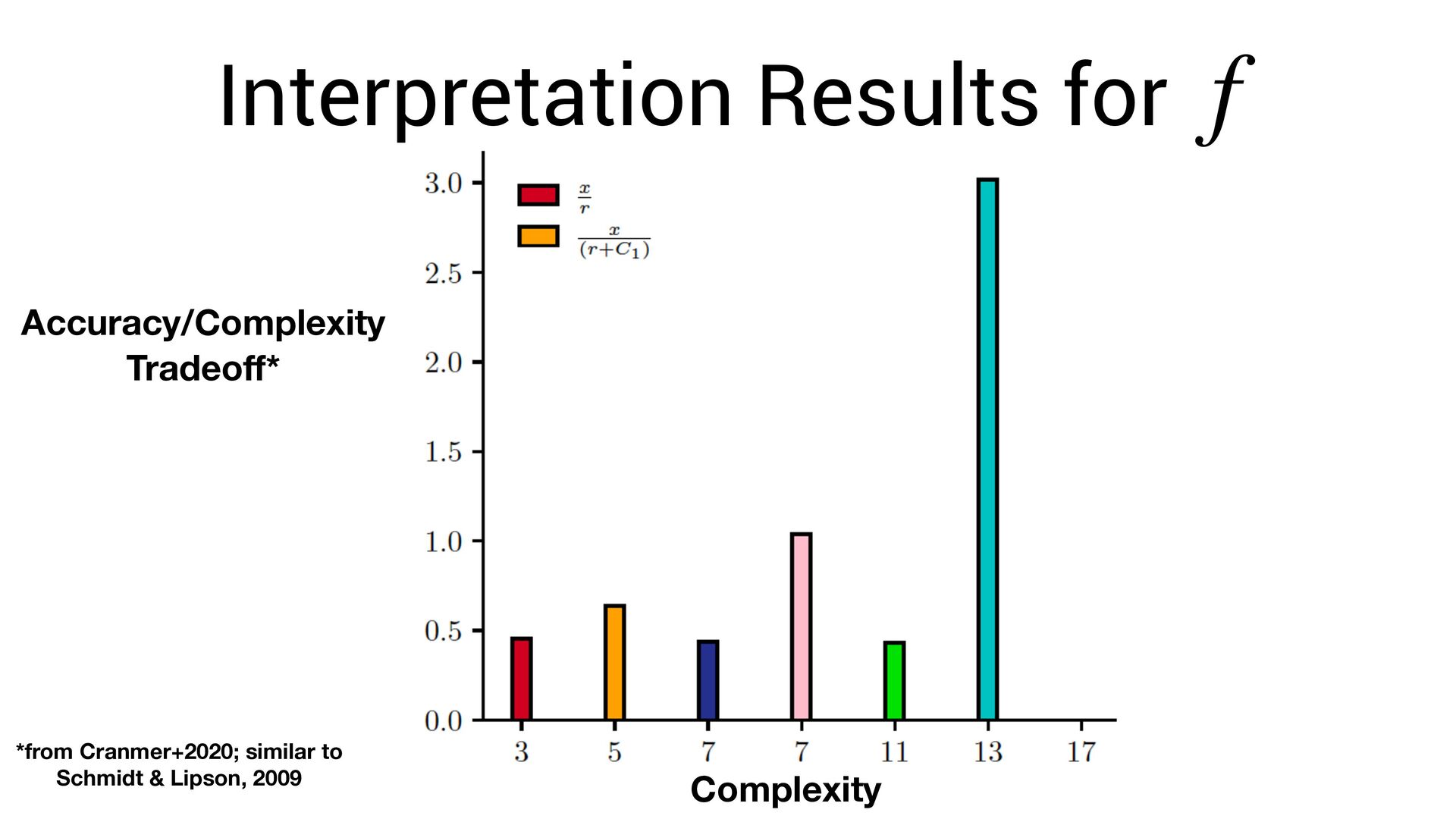
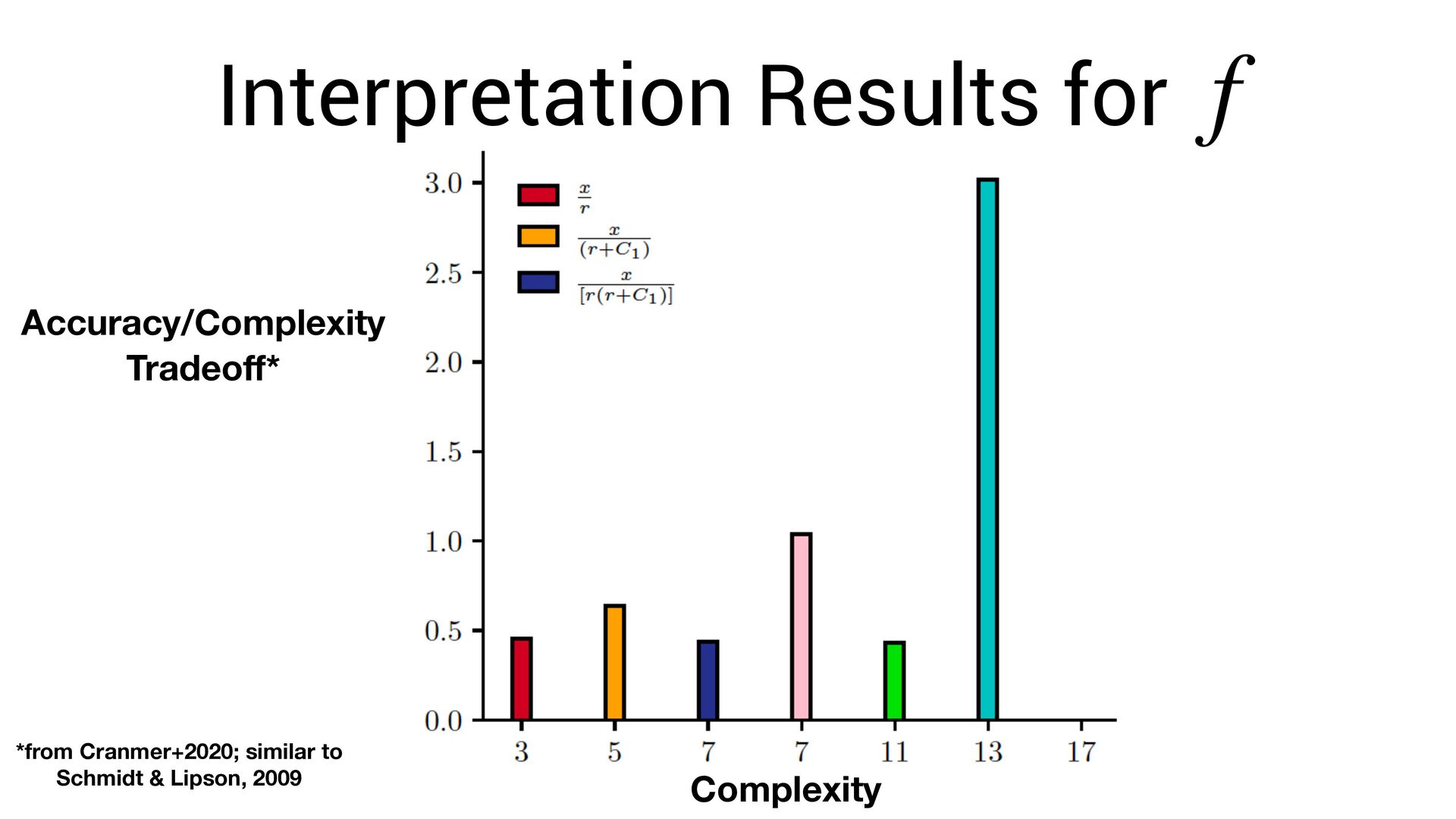
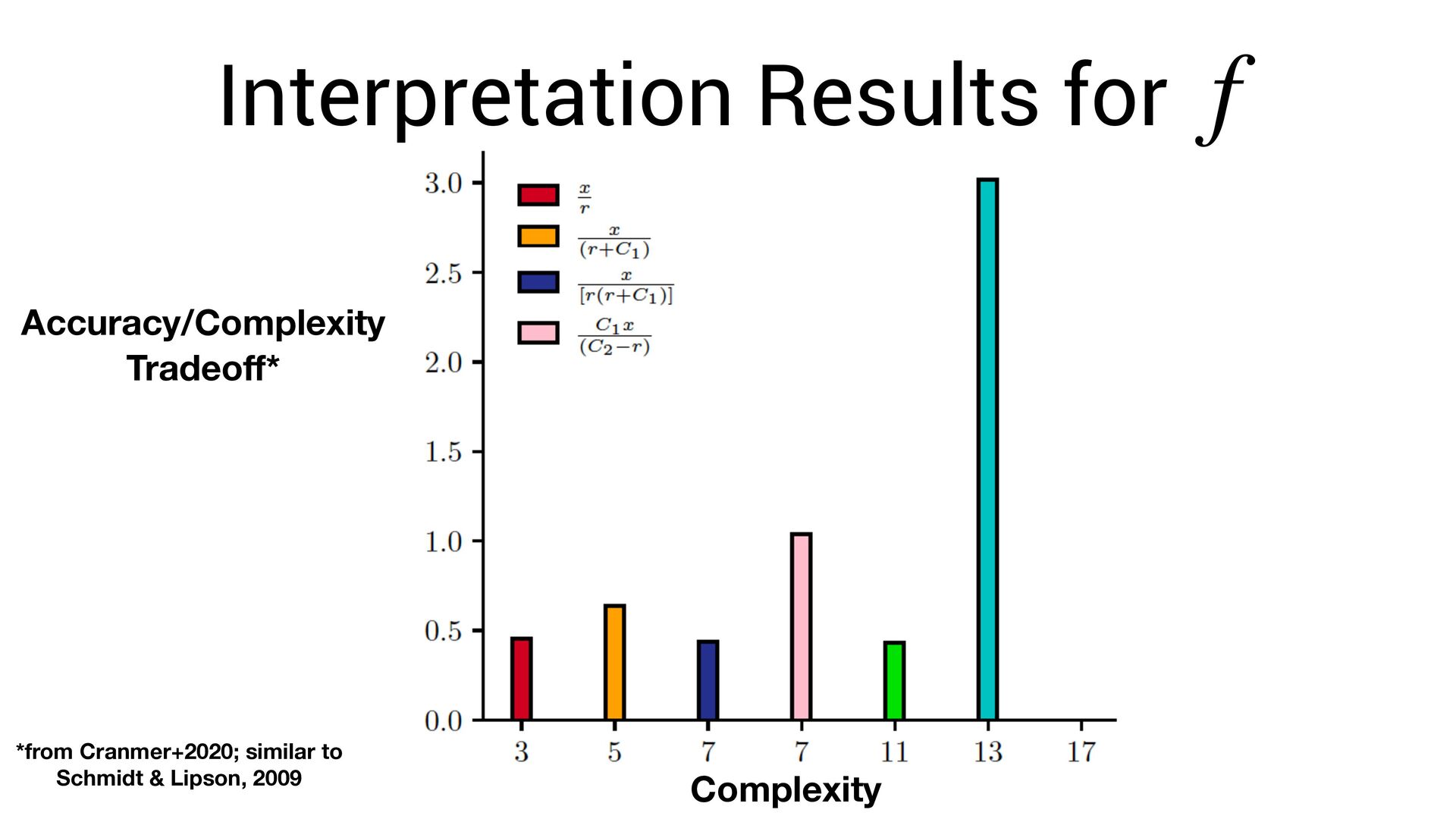
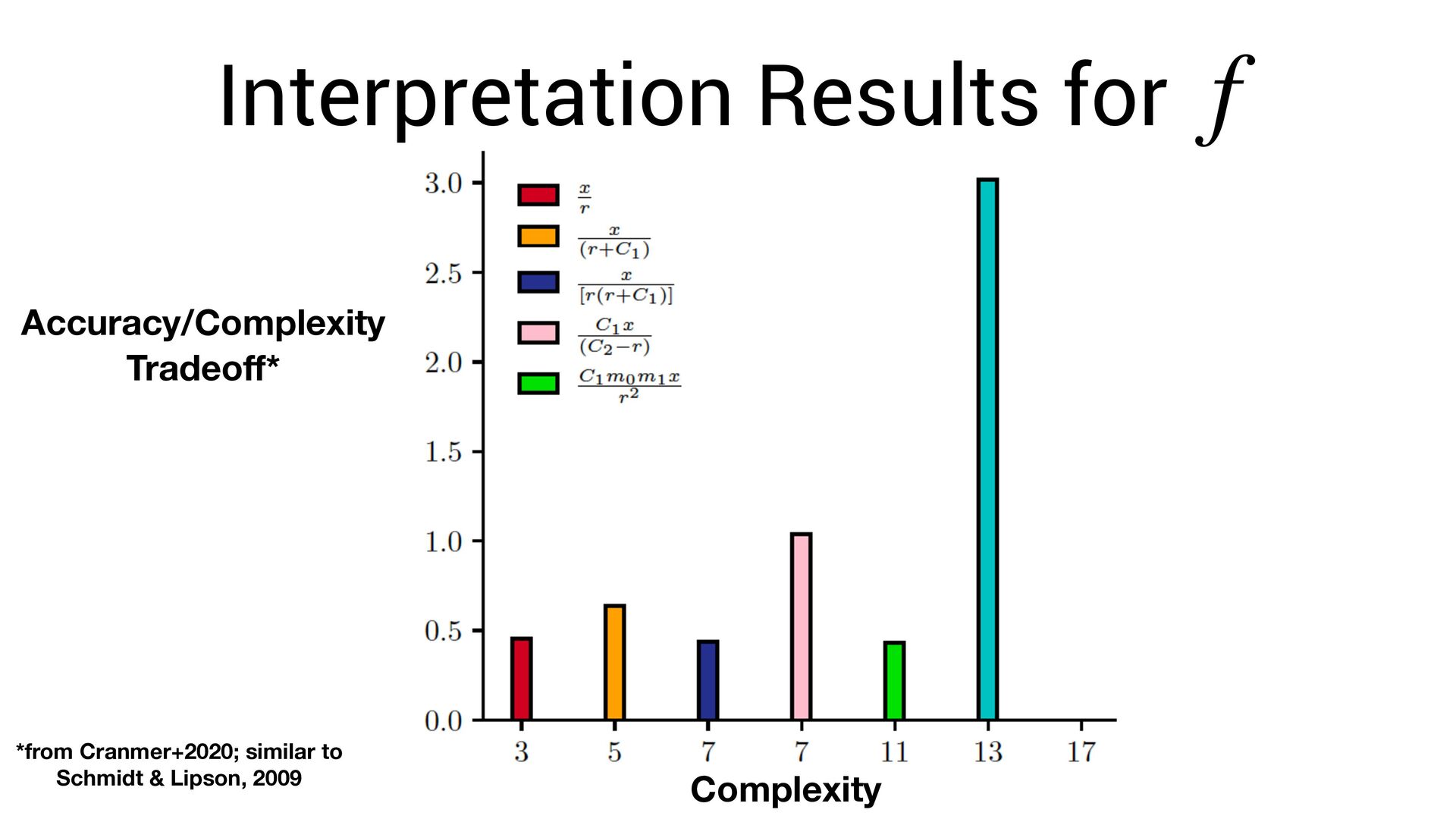
∑ j≠i f(xi − xj , vi , vj ) Known acceleration Learned force law Learned parameters for planets i, j Newton’s laws of motion (assumed) Learn via gradient descent. This allows us to fi nd both and simultaneously f f vi
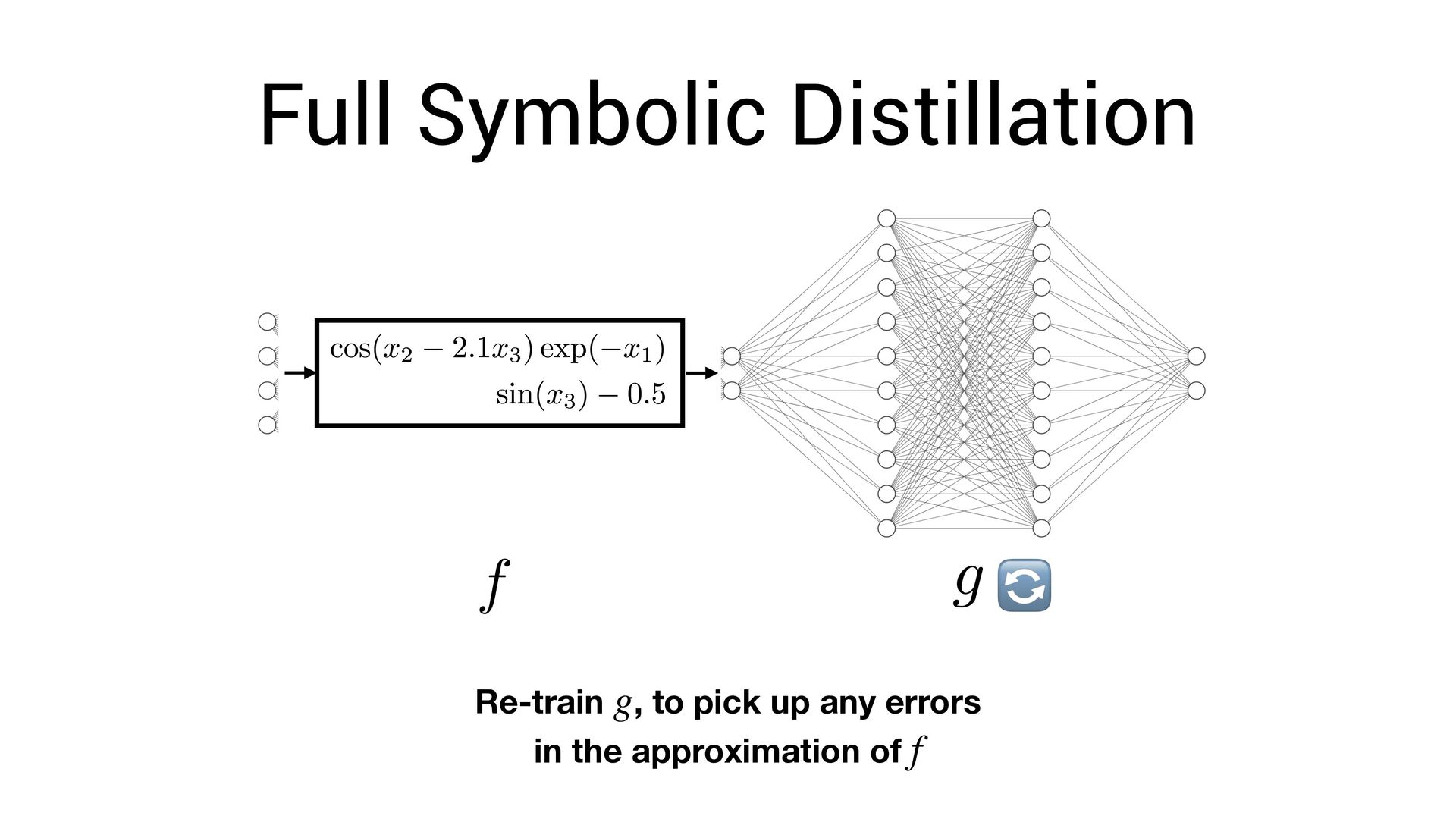
neural network. vi • The symbolic formula is not a *perfect* approximation of the network. • Thus: we need to re-optimize for the symbolic function ! vi f
(ICLR 2022) Kimberly Stachenfeld, Drummond B. Fielding, Dmitrii Kochkov, Miles Cranmer, Tobias Pfaff, Jonathan Godwin, Can Cui, Shirley Ho, Peter Battaglia, Alvaro Sanchez- Gonzalez Example:
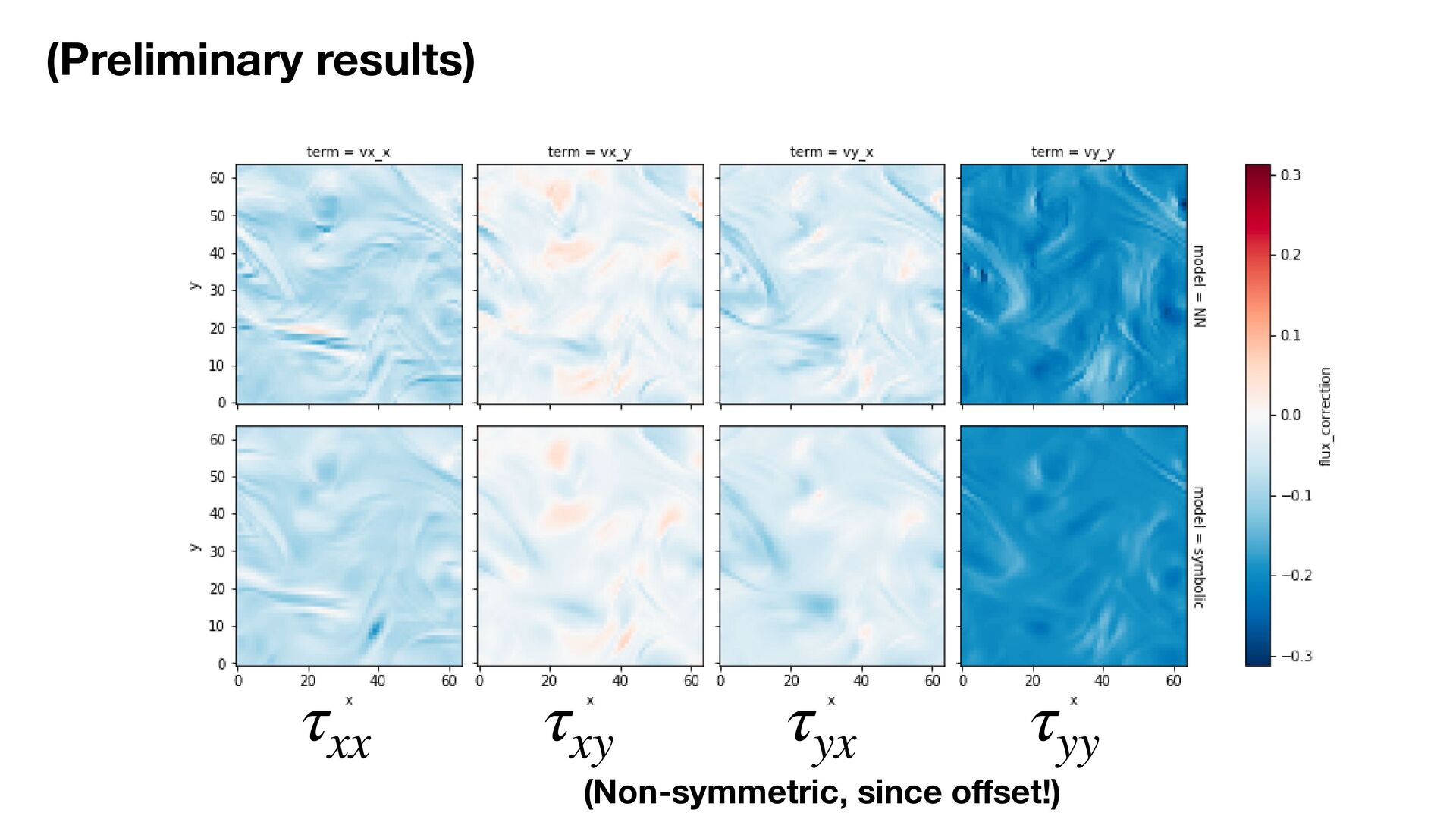
(ICLR 2022) Kimberly Stachenfeld, Drummond B. Fielding, Dmitrii Kochkov, Miles Cranmer, Tobias Pfaff, Jonathan Godwin, Can Cui, Shirley Ho, Peter Battaglia, Alvaro Sanchez- Gonzalez Example: Trained to reproduce turbulence simulations at lower resolution:
(ICLR 2022) Kimberly Stachenfeld, Drummond B. Fielding, Dmitrii Kochkov, Miles Cranmer, Tobias Pfaff, Jonathan Godwin, Can Cui, Shirley Ho, Peter Battaglia, Alvaro Sanchez- Gonzalez 1000x speedup: Example: Trained to reproduce turbulence simulations at lower resolution:
(ICLR 2022) Kimberly Stachenfeld, Drummond B. Fielding, Dmitrii Kochkov, Miles Cranmer, Tobias Pfaff, Jonathan Godwin, Can Cui, Shirley Ho, Peter Battaglia, Alvaro Sanchez- Gonzalez 1000x speedup: How did the model actually achieve this? Example: Trained to reproduce turbulence simulations at lower resolution:
models into a domain speci fi c language • Can do this for expressions/programs using PySR • Exciting future applications in understanding turbulence, and other physical systems
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}