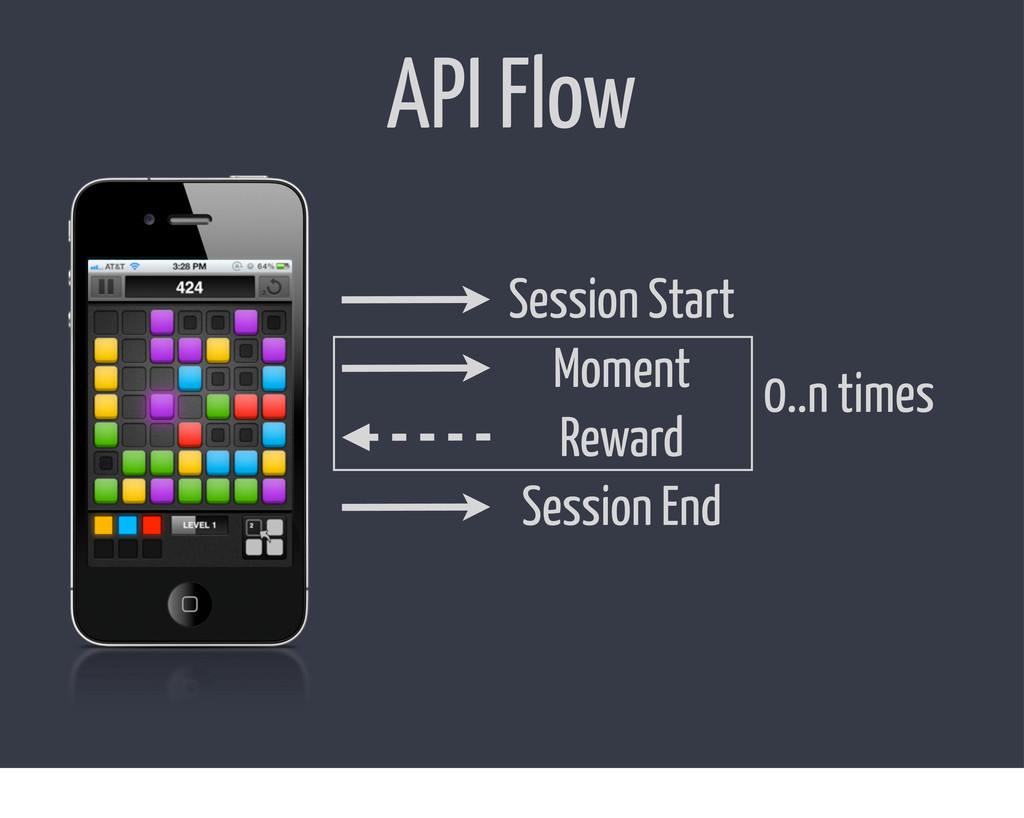
This talk goes over how we scaled one part of our technology stack at Kiip over the last 18 months, and how we ended up on Riak for this specific use case.
of atomic updates per second. * Hit limit w/ global write lock. * Solution: Aggregate over 10 seconds, send small bursts of updates, resulting in lower lock % on average. Solution: Aggregate over 10 seconds.
Y today/last week/this month/in all time?” * Touches lots of data * Requires lots of index space * Not cachable * MongoDB just... slow. Solution: Bloom filters. Solution: Bloom filters!
MongoDB’s write throughput limit. Solution: Use two distinct MongoDB clusters for disjunct datasets to avoid global write lock. One for analytics (heavy writes). One for everything else. Solution: Two clusters (lol global write lock)
because we’re pretty operationally frugal and the data was growing very fast. ETL = Extract/Transform/Load, archive data to S3, remove from main DB. Solution: ETL, Reap old data.
longer than 24 hours to extract, limited by MongoDB read throughput. We decided to let it break and continue reaping data. Solved in the future by continuous ETL solution separate from our main DB. Solution: Punted, solved by custom solution
talked with Basho developers. * Confident 100% in Basho team before even using product. * Meetups showed real world usage at scale + dev & ops happiness.
add a new node adds more I/O pressure for handoff. * Add new nodes early. * Hard to know when just beginning. Watch your FSM latencies carefully. Scaling at the red line is painful.
so don’t use for live requests. JS VMs take a lot of RAM, limited quantity, you can run out very quickly. Riak currently doesn’t handle this well, but they’re working on it.
bullshit. Really bad for Ops people on the road (MiFis, international, etc.). Otherwise great. Basho is aware of the problem. Requires low-latency connection
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}