Запис: https://www.youtube.com/watch?v=_ms0aQscrgk&list=PLX-Eu7bfT8M_MRzsoi9BWIwXuYegGnykT&index=6
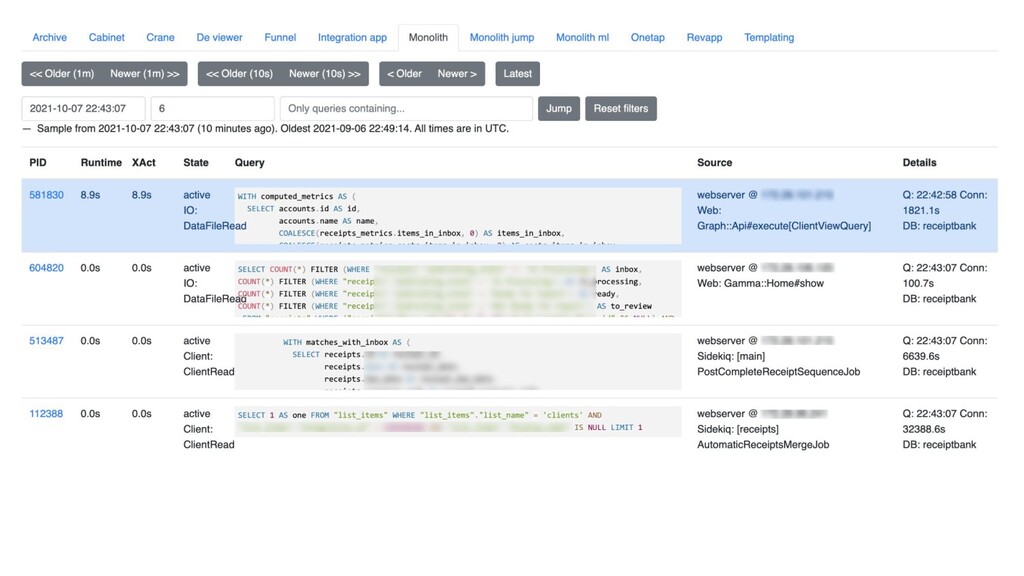
Като ръководител на инфраструктурния екип в Dext, чувствам, че нося лична отговорност както за бързото разрешаване на всеки инцидент в продукция, така и за тяхното предотвратяване (ха-ха, невъзможно). Бил съм на първа линия по време на много инциденти и това ме е научило на много. Ще ви споделя няколко по-интересни и запомнящи се инцидента или проблема от реална продукционна среда и ще ви споделя какви изводи съм си направил от тях. Освен самите случки, които, надявам се, ще бъдат забавни за странична аудитория, "поуките" ще се въртят около какви инструменти за метрики, аларми и дебъгване са ни били особено полезни, какъв процес следваме по време на инцидент и как това ни помага (или пречи), включително и как комуникираме и ескалираме. Ще засегна и някои моменти около устойчиви софтуерни архитектури и размисли около пускане на по-рискови промени в продукция.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Richard I. Cook, MD “[...] accident reviews nearly always note](https://files.speakerdeck.com/presentations/e923b81003c745ba9f1bf822a3c37895/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![“[...] listing human error as a root cause isn’t where](https://files.speakerdeck.com/presentations/e923b81003c745ba9f1bf822a3c37895/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Благодаря! mitio [email protected] @mitio ddimitrov.name](https://files.speakerdeck.com/presentations/e923b81003c745ba9f1bf822a3c37895/slide_67.jpg){kind=link}