Sooner or later, all complex systems will fail. It's not a matter of "if", it's a matter of "when". There will always be something that can -- and will -- go wrong, especially with today's distributed systems. Accept it and focus on the things you can control: creating a quality service that is resilient to failure.
Building resilient systems requires experience with failure. Waiting for things to break is not an option. We should rather inject failures proactively in a controlled way to gain confidence that our production systems can withstand those failures. In this talk, Mathias is going to show you how to apply this idea to the wonderful world of containers.
(Talk given at ContainerDays 2017: http://www.containerdays.io/)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
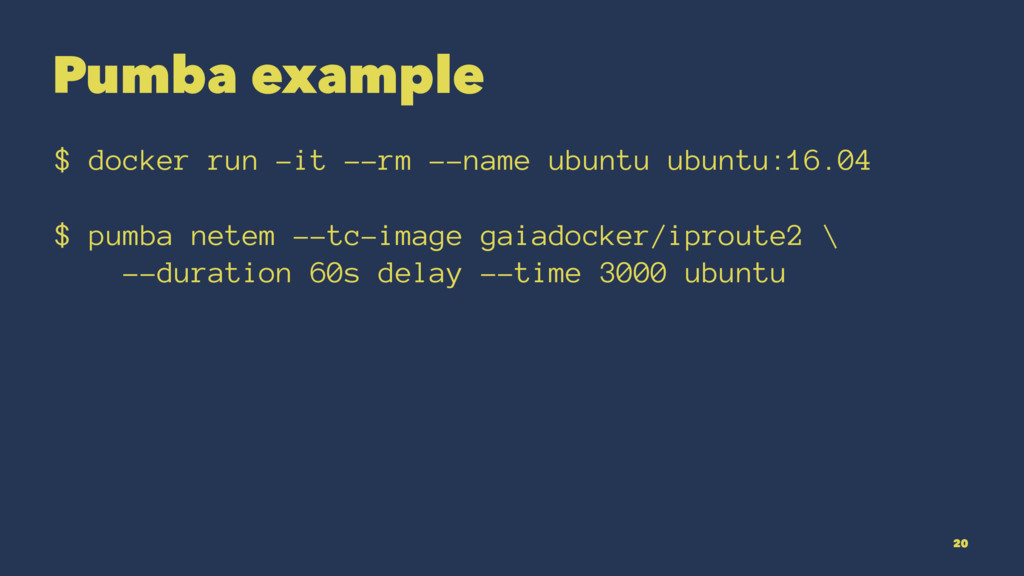{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}