Moving from the Iron Age to the Cloud Age in computing is supposed to save us money yet many migrations seem to cost more in the long run and result in infrastructures as complex to manage as what we had before. This is often the result of the so called “lift & shift” approach many take – it’s a short term win that doesn’t address why you wanted to move to the cloud in the first place.
The Cloud Age affords us the opportunity not to treat our infrastructure as something special, instead as something disposable. By applying the practices of continuous integration and delivery to our infrastructure and configuration management we can built truly scalable infrastructures to host our application’s wildest dreams.
In this talk we will look at the tools and processes that can be adopted to truly make use of the possibilities of the Cloud.
![Mike Fowler ([email protected]) FLOSS UK Spring 2017 The Disposable Infrastructure](https://files.speakerdeck.com/presentations/9003d9b7ea194b6e85a97b95986c0b80/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
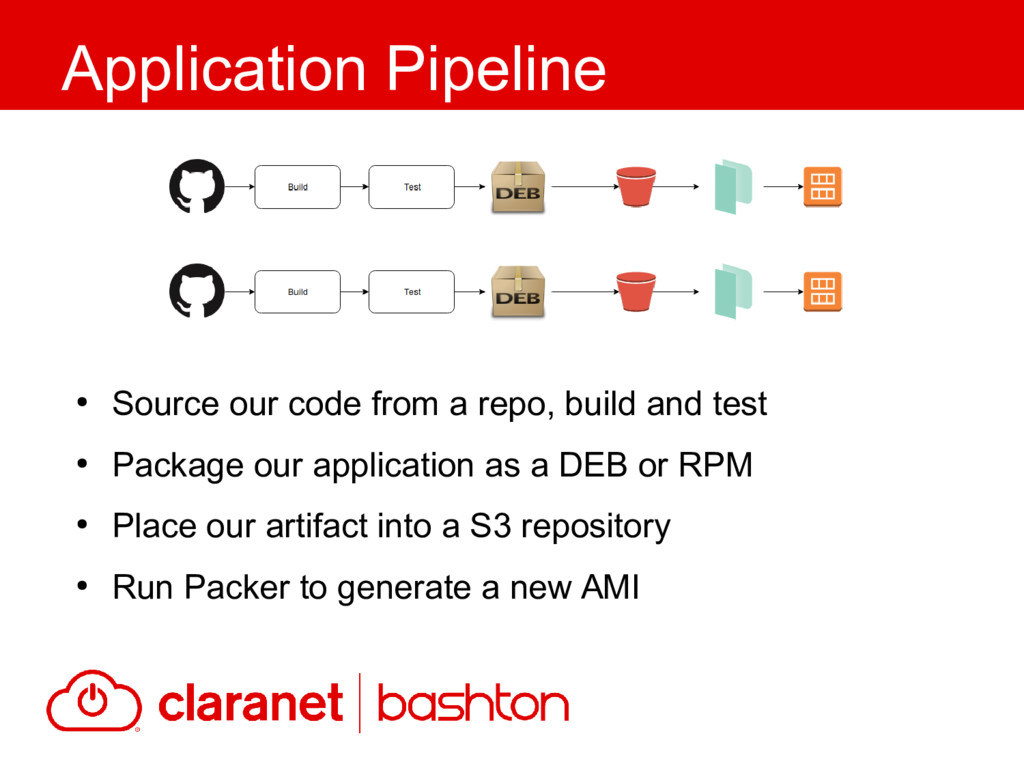{kind=link}
{kind=link}
{kind=link}
{kind=link}
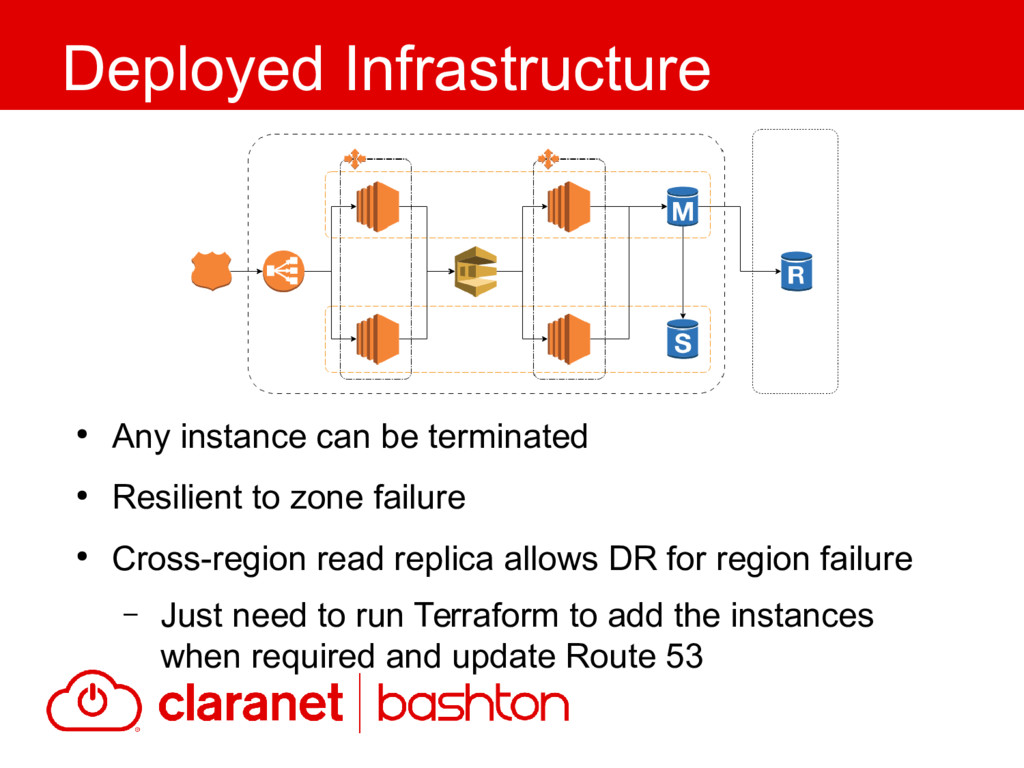{kind=link}
{kind=link}
{kind=link}