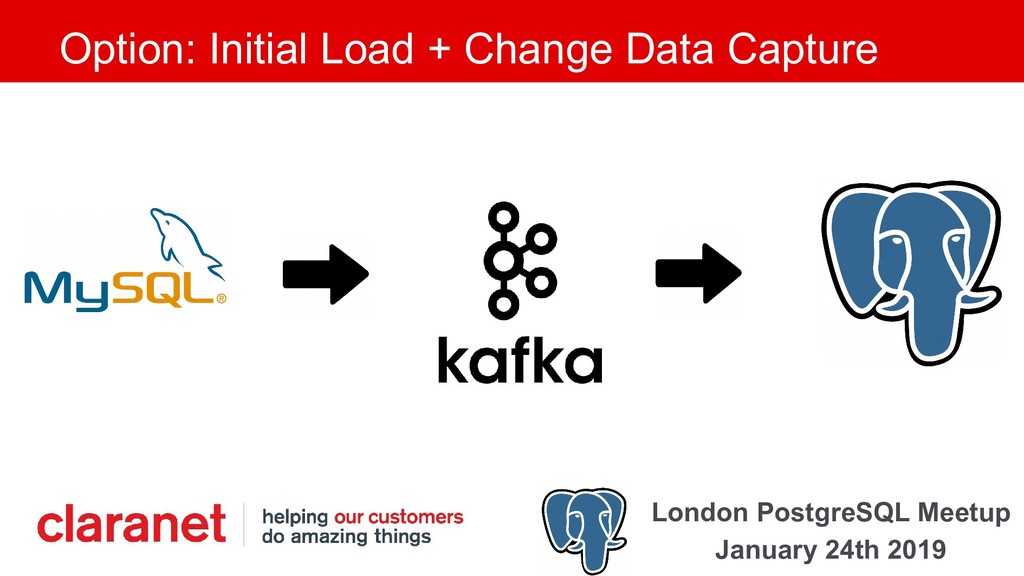
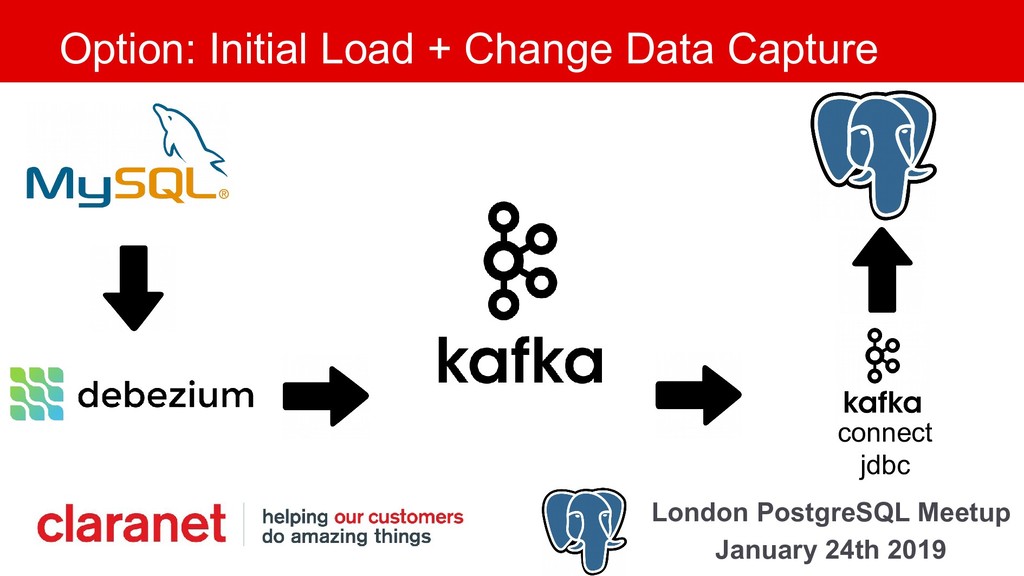
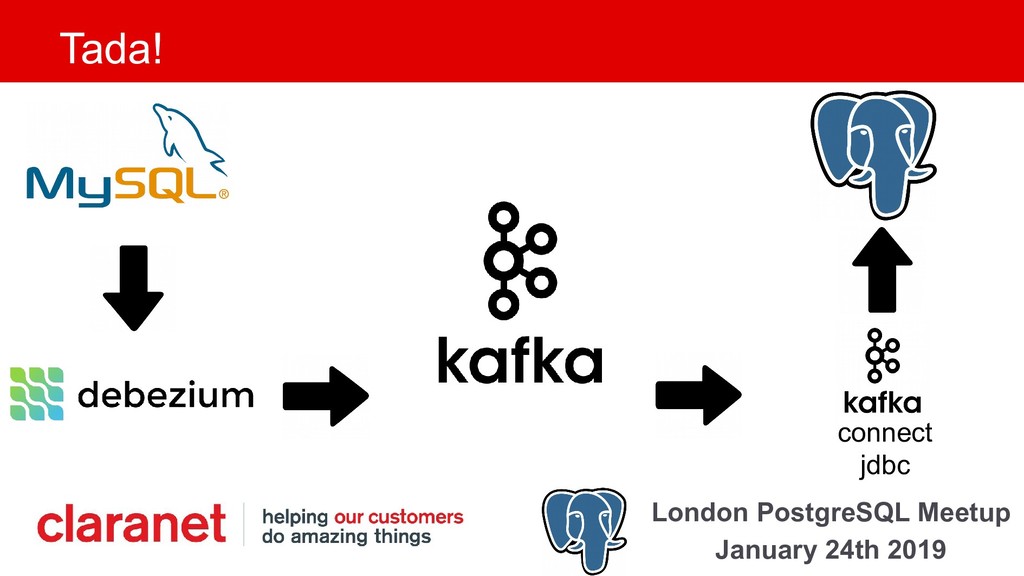
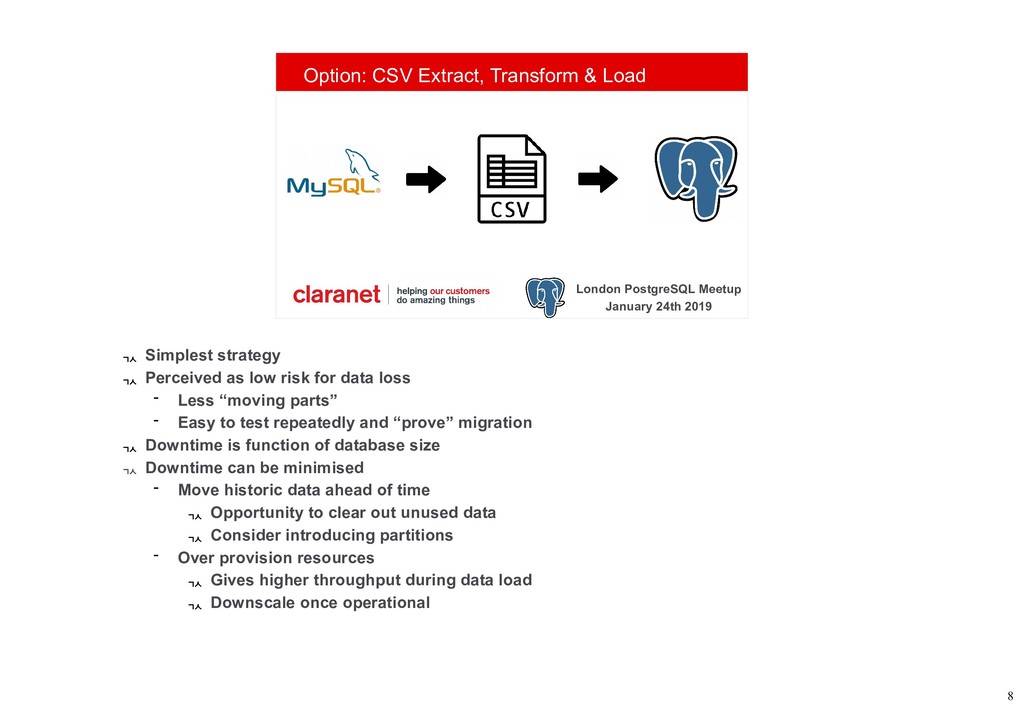
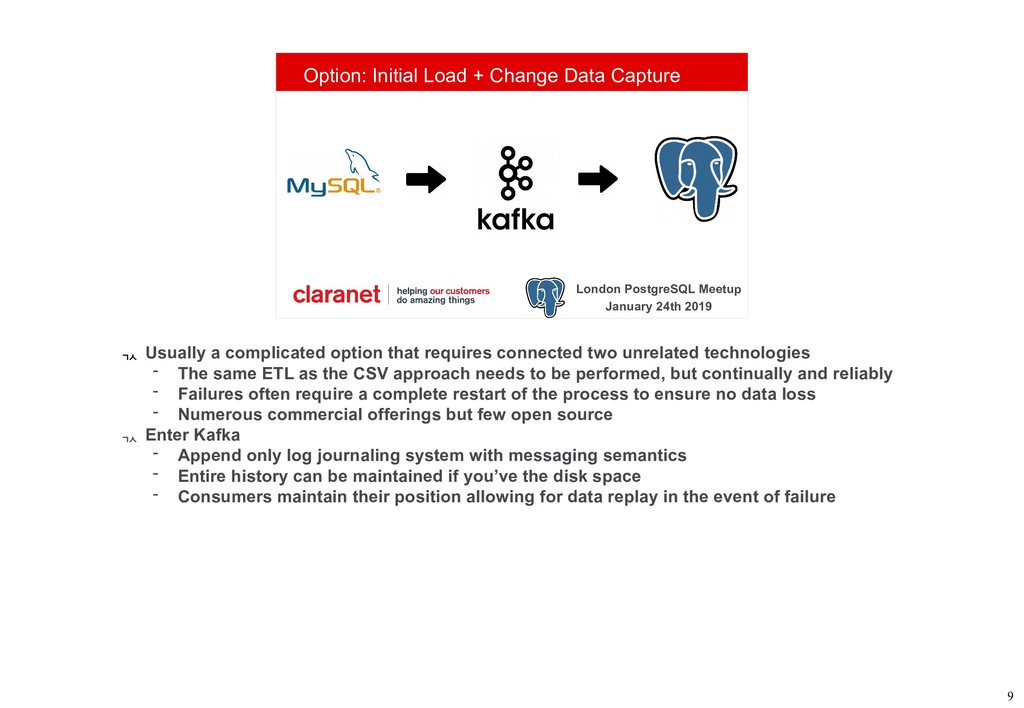
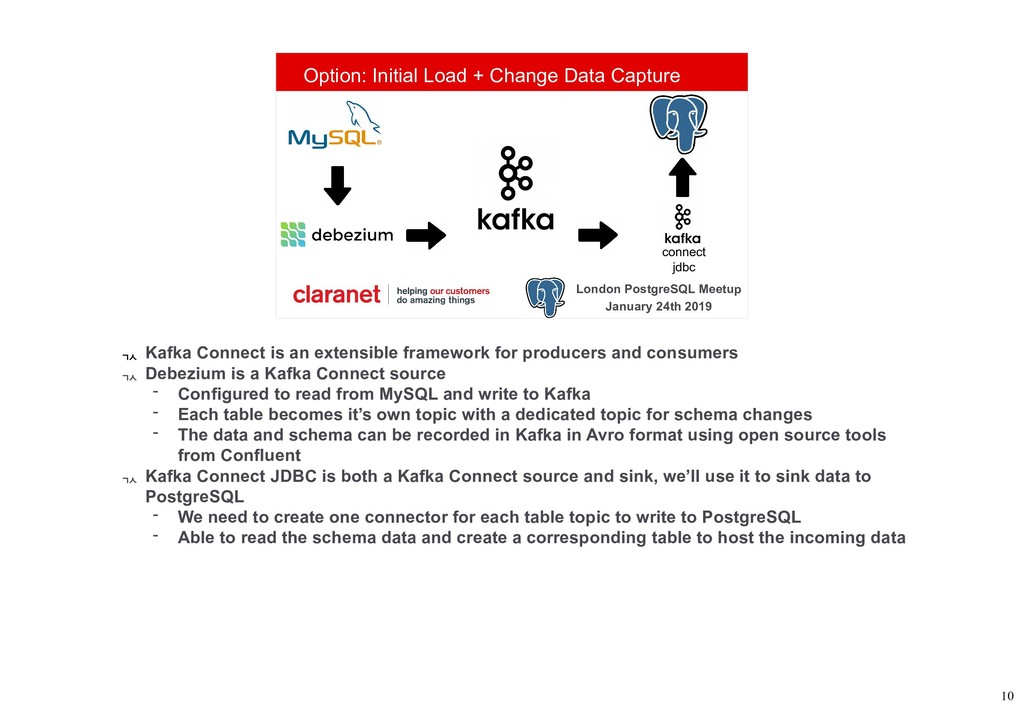
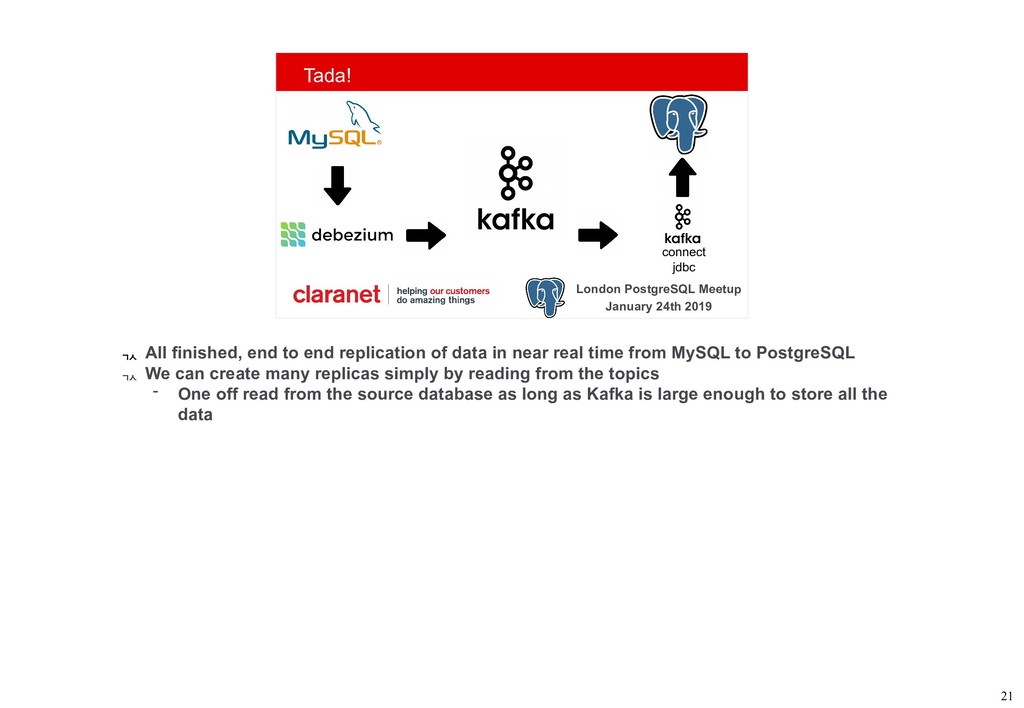
Debezium is a Kafka Connect plugin that performs Change Data Capture from your database into Kafka. This talk demonstrates how this can be leveraged to move your data from one database platform such as MySQL to PostgreSQL. A working example is available on GitHub (github.com/gh-mlfowler/debezium-demo).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Mike Fowler www.mlfowler.com Questions ? mlfowler mlfowler_ github.com/gh-mlfowler/debezium-demo [email protected]](https://files.speakerdeck.com/presentations/d6c967a779e64c7a92e4d3d2ef65990c/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Mike Fowler www.mlfowler.com Questions ? mlfowler mlfowler_ github.com/gh-mlfowler/debezium-demo [email protected]](https://files.speakerdeck.com/presentations/d6c967a779e64c7a92e4d3d2ef65990c/slide_46.jpg){kind=link}
{kind=link}