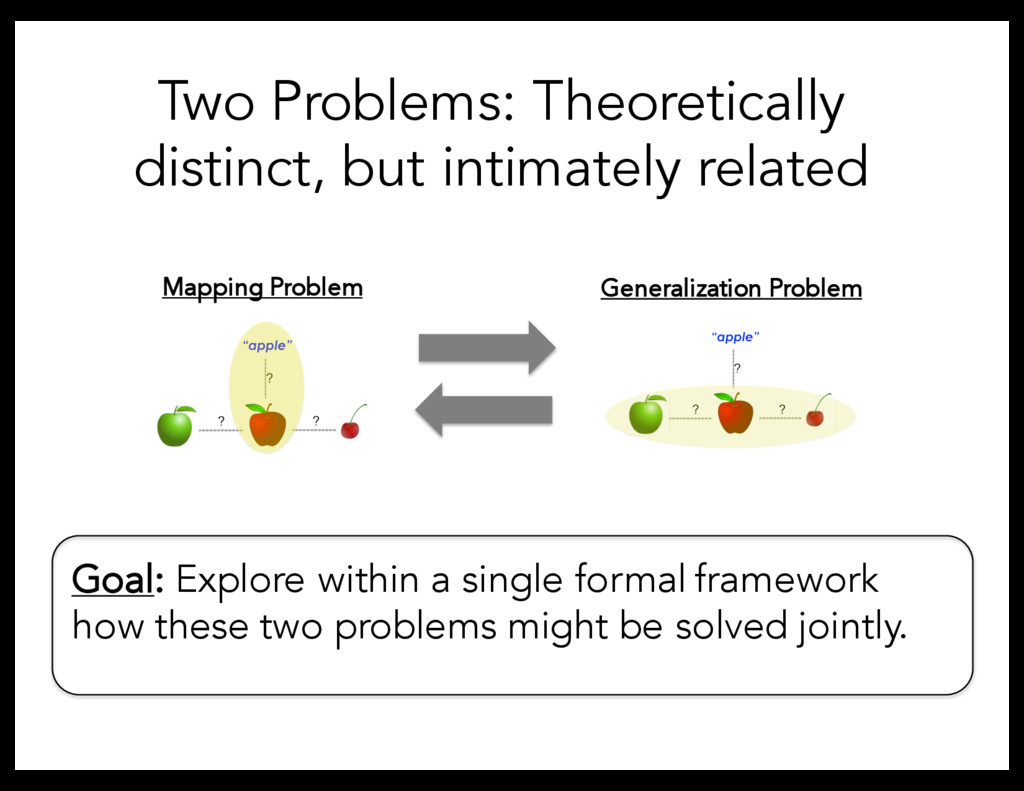
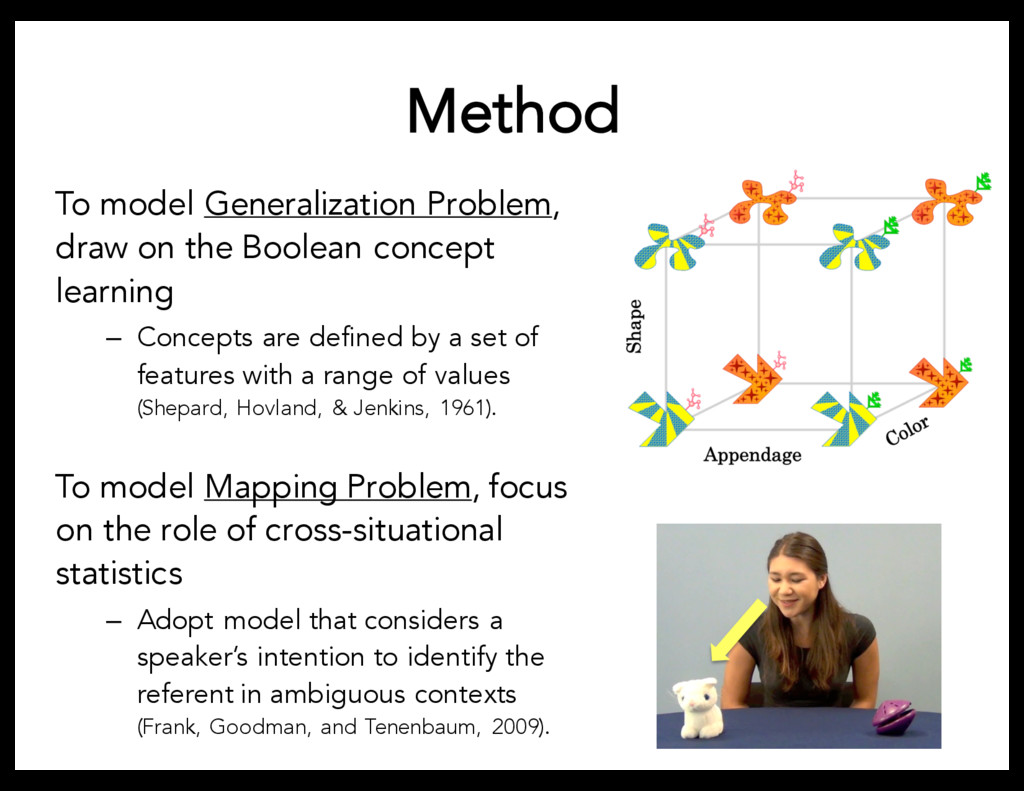
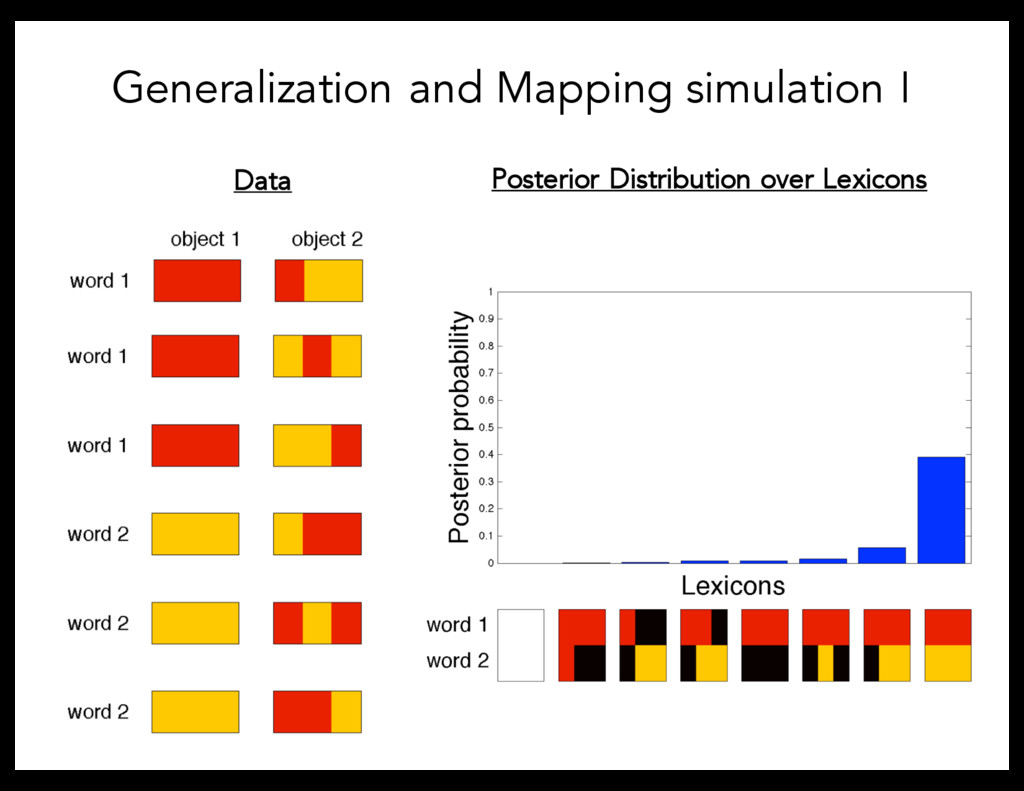
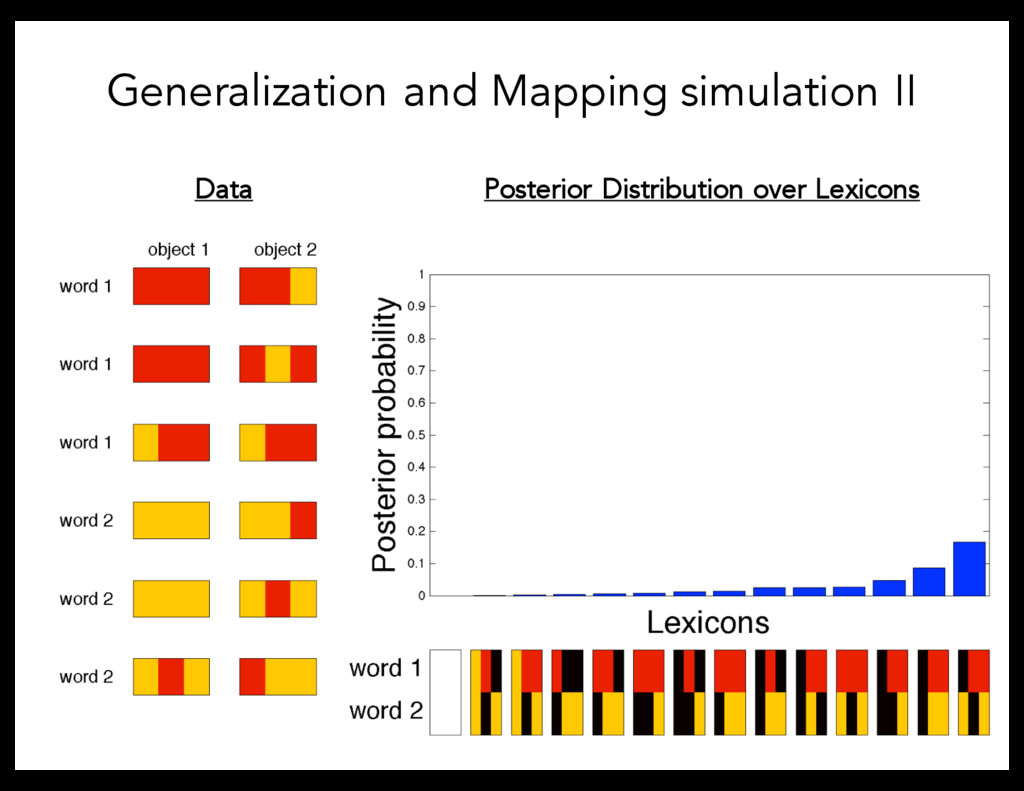
learning – Concepts are defined by a set of features with a range of values (Shepard, Hovland, & Jenkins, 1961). To model Mapping Problem, focus on the role of cross-situational statistics – Adopt model that considers a speaker’s intention to identify the referent in ambiguous contexts (Frank, Goodman, and Tenenbaum, 2009).
of features that define the relevant concept. • Gave subjects ambiguous evidence about the mappings between words and objects – Experiment 1: One situation – Experiment 2: Two situations • Measured subjects’ generalization patterns to other objects given training data • Adults recruited from Amazon Mechanical Turk
1 1 ] These objects could be called dax gren nes: Bet on whether these objects could be called dax gren nes: [1 1 1] [1 1 2] [1 2 1] [2 1 1] [1 2 2] [2 1 2] [2 1 1] [2 2 2]
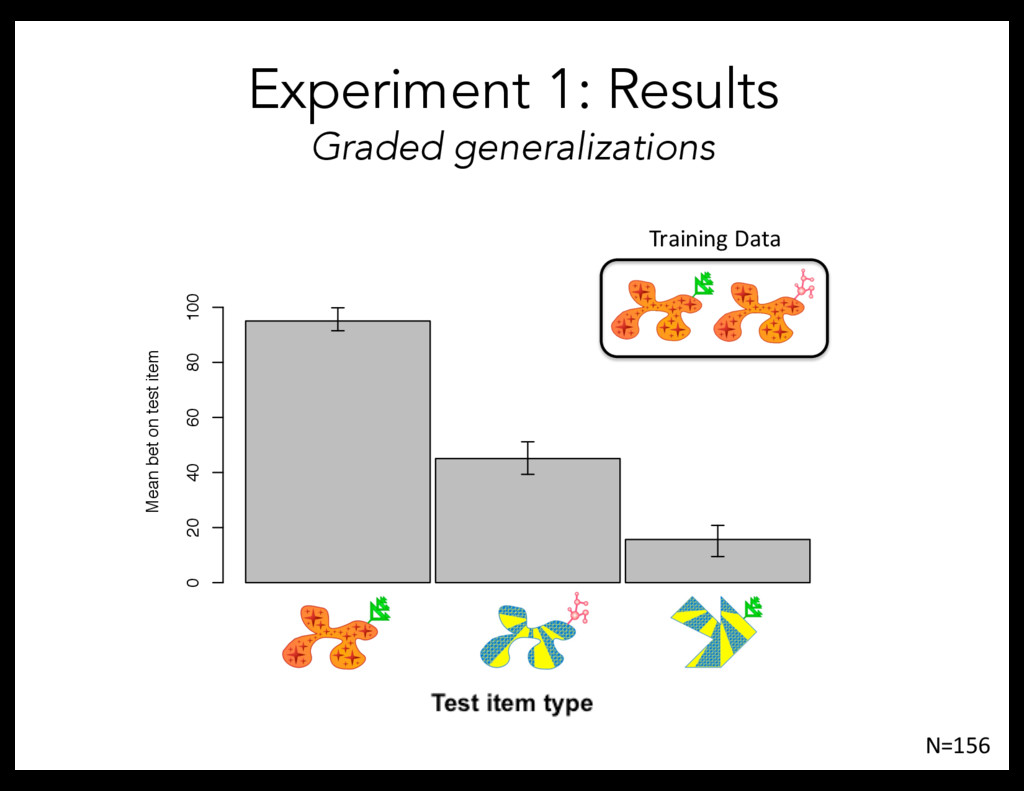
M 0 20 T M 0 20 Training ONEwithBOTH ONEwithONE Training items share 2 features [1 1 1] [1 1 2] Test item type Mean bet on test item 0 20 40 60 80 100 Mean bet on test item 0 20 40 60 80 100 N=156 Training Data
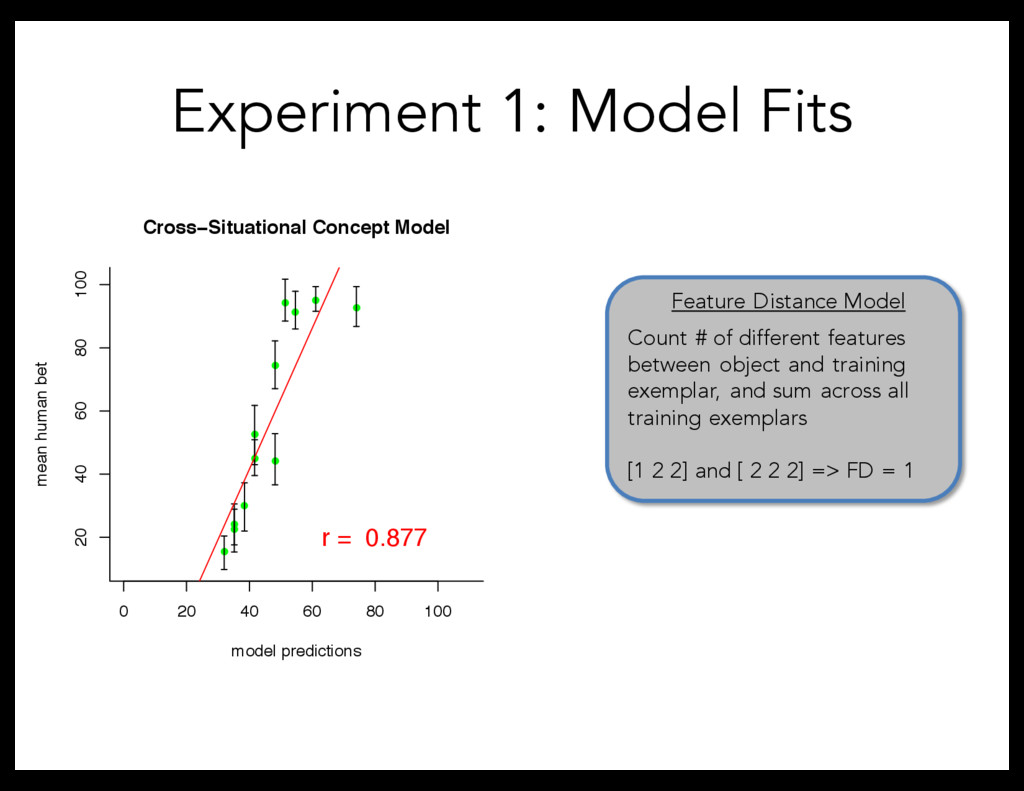
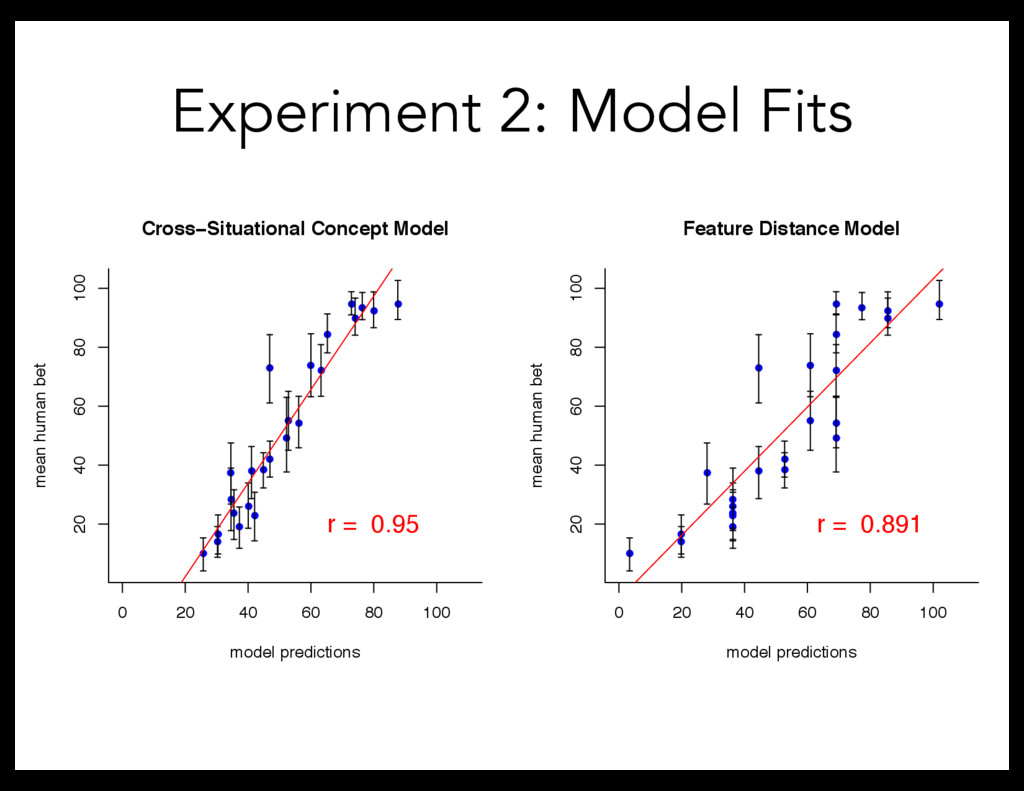
• • 0 20 40 60 80 100 20 40 60 80 100 model predictions mean human bet Cross−Situational Concept Model r = 0.877 • • • • • • • • • • • • 0 20 40 60 80 100 20 40 60 80 100 model predictions mean human bet Feature Distance Model r = 0.822 Experiment 1: Model Fits ` Feature Distance Model Count # of different features between object and training exemplar, and sum across all training exemplars [1 2 2] and [ 2 2 2] => FD = 1
heard dax bren nes. Now suppose you saw these two new objects and heard dax bren nes. [2 2 1] [1 1 1] [2 2 1] [1 1 1] * Manipulated number of features shared within and and across situations One shared feature within situation
heard dax bren nes. Now suppose you saw these two new objects and heard dax bren nes. [1 1 1] [1 1 1] [1 2 2] [1 2 2] * Manipulated number of features shared within and and across situations One shared feature across situations
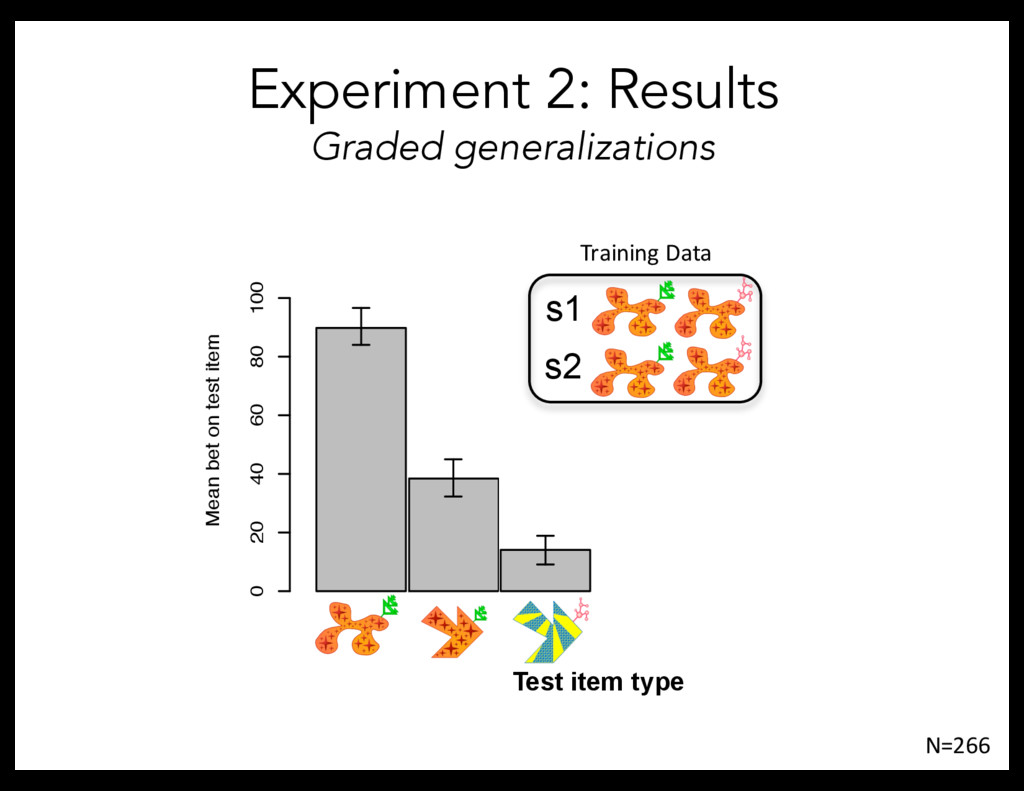
Test item type Mean bet on test item 0 20 40 60 80 100 Test item type 0 ature Confounded within situations: 2 features Test item type Mean bet on test item 0 20 40 60 80 100 Mean bet on test item Test item type 0 0 Confounded within situations: 2 features Test item type Mean bet on test item 0 20 40 60 80 100 Mean bet on test item 0 20 40 60 80 100 s1 s2 Test item type Test item type Experiment 2: Results Graded generalizations N=266 Training Data
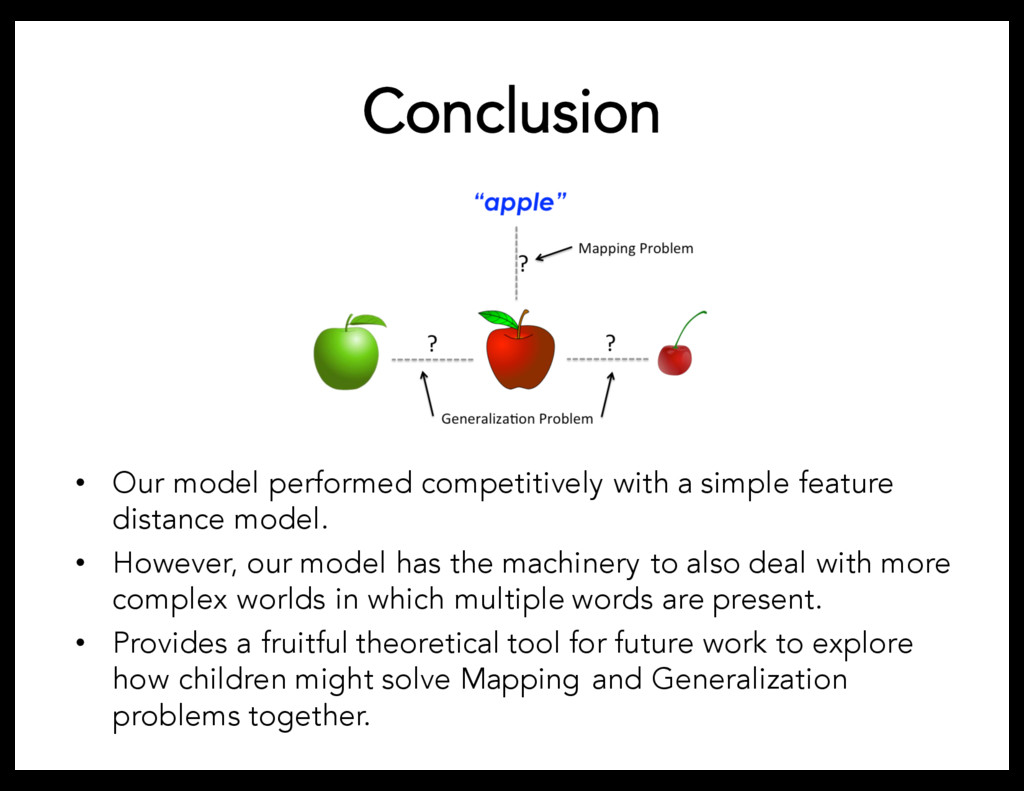
distance model. • However, our model has the machinery to also deal with more complex worlds in which multiple words are present. • Provides a fruitful theoretical tool for future work to explore how children might solve Mapping and Generalization problems together.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Hierarchical Bayesian Model [ 1 2 2 ] “wug” (exact](https://files.speakerdeck.com/presentations/76c1fafb4e1946558e50016ad609b517/slide_6.jpg){kind=link}
{kind=link}
![Experiment 1: Task [ 1 2 2 ] [ 1](https://files.speakerdeck.com/presentations/76c1fafb4e1946558e50016ad609b517/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}